深度学习-Pytorch:项目标准流程【构建、保存、加载神经网络模型;数据集构建器Dataset、数据加载器DataLoader(线性回归案例、手写数字识别案例)】
1、拿到文本,分词,清晰数据(去掉停用词语);
2、建立word2index、index2word表
3、准备好预训练好的word embedding
4、做好DataSet / Dataloader
5、建立模型
6、配置好参数
7、开始训练
8、测评
9、保存模型
一、Pytorch构建基础的模型
1. Pytorch构建模型常用API
在前一部分,我们自己实现了通过torch的相关方法完成反向传播和参数更新,在pytorch中预设了一些更加灵活简单的对象,让我们来构造模型、定义损失,优化损失等
那么接下来,我们一起来了解一下其中常用的API
1.1 nn.Module
nn.Modul 是torch.nn提供的一个类,是pytorch中我们自定义网络的一个基类,在这个类中定义了很多有用的方法,让我们在继承这个类定义网络的时候非常简单
当我们自定义网络的时候,有两个方法需要特别注意:
__init__需要调用super方法,继承父类的属性和方法,然后定义模型中的各个组件。farward方法必须实现,用来定义我们的网络的向前计算的过程。
用前面的y = wx+b的模型举例如下:
from torch import nn
class Lr(nn.Module):
def __init__(self):
super(Lr, self).__init__() #继承父类init的参数
self.linear = nn.Linear(in_features=1, out_features=1) # 相当于 y = wx+b
def forward(self, x):
out = self.linear(x)
return out
注意:
nn.Linear为torch预定义好的线性模型,也被称为全链接层,传入的参数为输入的数量,输出的数量(in_features, out_features),是不算(batch_size的列数)nn.Module定义了__call__方法,实现的就是调用forward方法,即Lr的实例,能够直接被传入参数调用,实际上调用的是forward方法并传入参数
# 实例化模型
model = Lr()
# 传入数据,计算结果
predict = model(x)
1.2 优化器类
优化器(optimizer),可以理解为torch为我们封装的用来进行更新参数的方法,比如常见的随机梯度下降(stochastic gradient descent,SGD)
优化器类都是由torch.optim提供的,例如
torch.optim.SGD(参数,学习率)torch.optim.Adam(参数,学习率)
注意:
- 参数可以使用
model.parameters()来获取,获取模型中所有requires_grad=True的参数 - 优化类的使用方法
- 实例化
- 所有参数的梯度,将其值置为0
- 反向传播计算梯度
- 更新参数值
示例如下:
optimizer = optim.SGD(model.parameters(), lr=1e-3) #1. 实例化
optimizer.zero_grad() #2. 梯度置为0
loss.backward() #3. 计算梯度
optimizer.step() #4. 更新参数的值
1.3 损失函数
前面的例子是一个回归问题,torch中也预测了很多损失函数
- 均方误差:
nn.MSELoss(),常用于回归问题 - 交叉熵损失:
nn.CrossEntropyLoss(),常用于分类问题 - 使用带权损失计算交叉熵损失:F.nll_loss(predict_y, target_y) <==> − ∑ Y l o g ( p ) -\sum Ylog(p) −∑Ylog(p)
使用方法:
model = Lr() #1. 实例化模型
criterion = nn.MSELoss() #2. 实例化损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) #3. 实例化优化器类
for i in range(100):
y_predict = model(x_true) #4. 向前计算预测值
loss = criterion(y_true,y_predict) #5. 调用损失函数传入真实值和预测值,得到损失结果
optimizer.zero_grad() #5. 当前循环参数梯度置为0
loss.backward() #6. 计算梯度
optimizer.step() #7. 更新参数的值
1.4 准确率的计算
- 获取概率最大值的位置索引作为预测值
- 预测值与真实值判断相等,结果取均值
2、训练完整过程
2.1 训练过程
- 实例化模型:class MyModule(nn.Module)
- 实例化损失函数:criterion = nn.MSELoss()
- 实例化优化器:optimizer = optim.SGD(model.parameters(), lr=1e-3)
- 进入训练循环
- 梯度置为0:optimizer.zero_grad()
- 调用模型得到预测值:y_predict = model(x)
- 调用loss = criterion(y_true,y_predict)计算函数,得到损失值
- 进行梯度计算:loss.backward()
- 更新梯度:optimizer.step()
2.2 线性回归完整代码
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
# 1. 定义数据
x = torch.rand([50,1])
y = x*3 + 0.8
#2 .定义模型
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = nn.Linear(in_features=1, out_features=1) # 相当于 y = wx+b
def forward(self, x):
out = self.linear(x)
return out
# 2. 实例化模型,loss,和优化器
model = Lr()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
#3. 训练模型
for i in range(30000):
out = model(x) #3.1 获取预测值
loss = criterion(y,out) #3.2 计算损失
optimizer.zero_grad() #3.3 梯度归零
loss.backward() #3.4 计算梯度
optimizer.step() # 3.5 更新梯度
if (i+1) % 20 == 0:
print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data))
#4. 模型评估
model.eval() #设置模型为评估模式,即预测模式
predict = model(x)
predict = predict.data.numpy()
plt.scatter(x.data.numpy(),y.data.numpy(),c="r")
plt.plot(x.data.numpy(),predict)
plt.show()
输出如下:
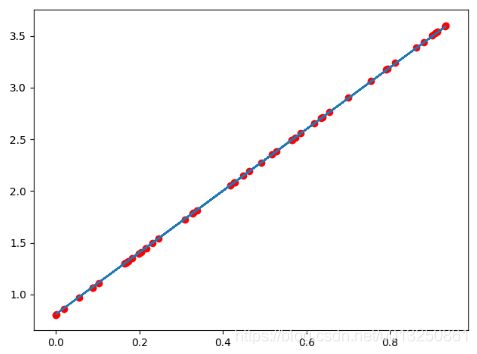
注意:
model.eval()表示设置模型为评估模式,即预测模式
model.train(mode=True) 表示设置模型为训练模式
在当前的线性回归中,上述并无区别
但是在其他的一些模型中,训练的参数和预测的参数会不相同,到时候就需要具体告诉程序我们是在进行训练还是预测,比如模型中存在Dropout,BatchNorm的时候
二、在GPU上运行代码
当模型太大,或者参数太多的情况下,为了加快训练速度,经常会使用GPU来进行训练
此时我们的代码需要稍作调整:
-
判断GPU是否可用
torch.cuda.is_available()torch.device("cuda:0" if torch.cuda.is_available() else "cpu") >>device(type='cuda', index=0) #使用gpu >>device(type='cpu') #使用cpu -
把模型参数和input数据转化为cuda的支持类型
model.to(device)自定义tensor.to(device)model.to(device) x_true.to(device)
-
在GPU上计算结果也为cuda的数据类型,需要转化为numpy或者torch的cpu的tensor类型
predict = predict.cpu().detach().numpy()detach()的效果和data的相似,但是detach()是深拷贝,data是取值,是浅拷贝
修改之后的代码如下:
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
import time
# 1. 定义数据
x = torch.rand([50,1])
y = x*3 + 0.8
#2 .定义模型
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
out = self.linear(x)
return out
# 2. 实例化模型,loss,和优化器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.to(device)
y = y.to(device) # 此步骤可以省略【y是由x计算得出,所以y的位置默认与x一致】
model = Lr().to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
#3. 训练模型
for i in range(300):
out = model(x)
loss = criterion(y,out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 20 == 0:
print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data))
#4. 模型评估
model.eval() #
predict = model(x)
predict = predict.cpu().detach().numpy() #转化为numpy数组
plt.scatter(x.cpu().data.numpy(),y.cpu().data.numpy(),c="r")
plt.plot(x.cpu().data.numpy(),predict,)
plt.show()
三、数据加载
1. 模型中使用数据加载器的目的
在前面的线性回归模型中,我们使用的数据很少,所以直接把全部数据放到模型中去使用。
但是在深度学习中,数据量通常是都非常多,非常大的,如此大量的数据,不可能一次性的在模型中进行向前的计算和反向传播,经常我们会对整个数据进行随机的打乱顺序,把数据处理成一个个的batch,同时还会对数据进行预处理。
所以,接下来我们来学习pytorch中的数据加载的方法
2. 数据集类
2.1 Dataset基类介绍
在torch中提供了数据集的基类torch.utils.data.Dataset,继承这个基类,我们能够非常快速的实现对数据的加载。
torch.utils.data.Dataset的源码如下:
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
可知:我们需要在自定义的数据集类中继承Dataset类,同时还需要实现两个方法:
__len__方法,能够实现通过全局的len()方法获取其中的元素个数__getitem__方法,通过初始化的参数获取数据。能够通过传入索引或数据路径的方式获取数据,例如通过dataset[i]获取其中的第i条数据
2.2 数据加载案例
下面通过一个例子来看看如何使用Dataset来加载数据
数据来源:http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
数据介绍:SMS Spam Collection是用于骚扰短信识别的经典数据集,完全来自真实短信内容,包括4831条正常短信和747条骚扰短信。正常短信和骚扰短信保存在一个文本文件中。 每行完整记录一条短信内容,每行开头通过ham和spam标识正常短信和骚扰短信
数据实例:

实现如下:
from torch.utils.data import Dataset,DataLoader
import pandas as pd
data_path = r"data\SMSSpamCollection"
class CifarDataset(Dataset):
def __init__(self): # 初始化参数
lines = open(data_path,"r")
lines_array = [[line[:4].strip(),line[4:].strip()] for line in lines] #对数据进行处理,前4个为label,后面的为短信内容
self.df = pd.DataFrame(lines_array,columns=["label","sms"]) #转化为dataFrame
def __getitem__(self, index): # 通过初始化的参数获取数据
single_item = self.df.iloc[index,:]
return single_item.values[0],single_item.values[1]
def __len__(self):
return self.df.shape[0]
之后对Dataset进行实例化,可以跌倒获取其中的数据
d = CifarDataset()
for i in range(len(d)):
print(i,d[i])
输出如下:
....
5571 ('ham', 'Pity, * was in mood for that. So...any other suggestions?')
5572 ('ham', "The guy did some bitching but I acted like i'd be interested in buying something else next week and he gave it to us for free")
5573 ('ham', 'Rofl. Its true to its name')
3. 迭代数据集
使用上述的方法能够进行数据的读取,但是其中还有很多内容没有实现:
- 批处理数据(Batching the data)
- 打乱数据(Shuffling the data)
- 使用多线程
multiprocessing并行加载数据。 - 如果最后一个batch的数据量不足设置的batch_size,可以选择放弃最后一个batch的数据(drop_last=True)
在pytorch中torch.utils.data.DataLoader提供了上述的所用方法
DataLoader的使用方法示例:
from torch.utils.data import DataLoader
dataset = CifarDataset()
data_loader = DataLoader(dataset=dataset,batch_size=10,shuffle=True,num_workers=2)
#遍历,获取其中的每个batch的结果
for index, (label, context) in enumerate(data_loader):
print(index,label,context)
print("*"*100)
其中参数含义:
- dataset:提前定义的dataset的实例
- batch_size:传入数据的batch的大小,常用128,256等等
- shuffle:bool类型,表示是否在每次获取数据的时候提前打乱数据
num_workers:加载数据的线程数
数据迭代器的返回结果如下:
555 ('spam', 'ham', 'spam', 'ham', 'ham', 'ham', 'ham', 'spam', 'ham', 'ham') ('URGENT! We are trying to contact U. Todays draw shows that you have won a £800 prize GUARANTEED. Call 09050003091 from....", 'swhrt how u dey,hope ur ok, tot about u 2day.love n miss.take care.')
***********************************************************************************
556 ('ham', 'ham', 'ham', 'ham', 'ham', 'ham', 'ham', 'ham', 'ham', 'spam') ('He telling not to tell any one. If so treat for me hi hi hi', 'Did u got that persons story', "Don kn....1000 cash prize or a prize worth £5000')
注意:
len(dataset) = 数据集的样本数len(dataloader) = math.ceil(样本数/batch_size) 即向上取整
4 pytorch自带的数据集
pytorch中自带的数据集由两个上层api提供,分别是torchvision和torchtext
其中:
torchvision提供了对图片数据处理相关的api和数据- 数据位置:
torchvision.datasets,例如:torchvision.datasets.MNIST(手写数字图片数据)
- 数据位置:
torchtext提供了对文本数据处理相关的API和数据- 数据位置:
torchtext.datasets,例如:torchtext.datasets.IMDB(电影评论文本数据)
- 数据位置:
下面我们以Mnist手写数字为例,来看看pytorch如何加载其中自带的数据集
使用方法和之前一样:
- 准备好Dataset实例
- 把dataset交给dataloder 打乱顺序,组成batch
4.1 torchversion.datasets
torchversoin.datasets中的数据集类(比如torchvision.datasets.MNIST),都是继承自Dataset
意味着:直接对torchvision.datasets.MNIST进行实例化就可以得到Dataset的实例
但是MNIST API中的参数需要注意一下:
torchvision.datasets.MNIST(root='/files/', train=True, download=True, transform=)
root参数表示数据存放的位置train:bool类型,表示是使用训练集的数据还是测试集的数据download:bool类型,表示是否需要下载数据到root目录transform:实现的对图片的处理函数
4.2 MNIST数据集的介绍
数据集的原始地址:http://yann.lecun.com/exdb/mnist/
MNIST是由Yann LeCun等人提供的免费的图像识别的数据集,其中包括60000个训练样本和10000个测试样本,其中图拍了的尺寸已经进行的标准化的处理,都是黑白的图像,大小为28X28
执行代码,下载数据,观察数据类型:
import torchvision
dataset = torchvision.datasets.MNIST(root="./data",train=True,download=True,transform=None)
print(dataset[0])
下载的数据如下:
代码输出结果如下:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Processing...
Done!
(<PIL.Image.Image image mode=L size=28x28 at 0x18D303B9C18>, tensor(5))
可以其中数据集返回了两条数据,可以猜测为图片的数据和目标值
返回值的第0个为Image类型,可以调用show() 方法打开,发现为手写数字5
import torchvision
dataset = torchvision.datasets.MNIST(root="./data",train=True,download=True,transform=None)
print(dataset[0])
img = dataset[0][0]
img.show() #打开图片
图片如下:
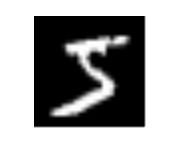
由上可知:返回值为(图片,目标值),这个结果也可以通过观察源码得到
四、使用Pytorch实现手写数字识别
1. 思路和流程分析
流程:
- 准备数据,这些需要准备DataLoader
- 构建模型,这里可以使用torch构造一个深层的神经网络
- 模型的训练
- 模型的保存,保存模型,后续持续使用
- 模型的评估,使用测试集,观察模型的好坏
2. 准备训练集和测试集
准备数据集的方法前面已经讲过,但是通过前面的内容可知,调用MNIST返回的结果中图形数据是一个Image对象,需要对其进行处理
为了进行数据的处理,接下来学习torchvision.transfroms的方法
2.1 torchvision.transforms的图形数据处理方法
2.1.1 torchvision.transforms.ToTensor
把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W]
其中(H,W,C)意思为(高,宽,通道数),黑白图片的通道数只有1,其中每个像素点的取值为[0,255],彩色图片的通道数为(R,G,B),每个通道的每个像素点的取值为[0,255],三个通道的颜色相互叠加,形成了各种颜色
示例如下:
from torchvision import transforms
import numpy as np
data = np.random.randint(0, 255, size=12)
img = data.reshape(2,2,3)
print(img.shape)
img_tensor = transforms.ToTensor()(img) # 转换成tensor
print(img_tensor)
print(img_tensor.shape)
输出如下:
shape:(2, 2, 3)
img_tensor:tensor([[[215, 171],
[ 34, 12]],
[[229, 87],
[ 15, 237]],
[[ 10, 55],
[ 72, 204]]], dtype=torch.int32)
new shape:torch.Size([3, 2, 2])
注意:
transforms.ToTensor对象中有__call__方法,所以可以对其示例能够传入数据获取结果
2.1.2 torchvision.transforms.Normalize(mean, std)
给定均值:mean,shape和图片的通道数相同(指的是每个通道的均值),方差:std,和图片的通道数相同(指的是每个通道的方差),将会把Tensor规范化处理。
即:Normalized_image=(image-mean)/std。
例如:
from torchvision import transforms
import numpy as np
import torchvision
data = np.random.randint(0, 255, size=12)
img = data.reshape(2,2,3)
img = transforms.ToTensor()(img) # 转换成tensor
print(img)
print("*"*100)
norm_img = transforms.Normalize((10,10,10), (1,1,1))(img) #进行规范化处理
print(norm_img)
输出如下:
tensor([[[177, 223],
[ 71, 182]],
[[153, 120],
[173, 33]],
[[162, 233],
[194, 73]]], dtype=torch.int32)
***************************************************************************************
tensor([[[167, 213],
[ 61, 172]],
[[143, 110],
[163, 23]],
[[152, 223],
[184, 63]]], dtype=torch.int32)
注意:在sklearn中,默认上式中的std和mean为数据每列的std和mean,sklearn会在标准化之前算出每一列的std和mean。
但是在api:Normalize中并没有帮我们计算,所以我们需要手动计算
-
当mean为全部数据的均值,std为全部数据的std的时候,才是进行了标准化。
-
如果mean(x)不是全部数据的mean的时候,std(y)也不是的时候,Normalize后的数据分布满足下面的关系
n e w _ m e a n = m e a n − x y , m e a n 为 原 数 据 的 均 值 , x 为 传 入 的 均 值 x n e w _ s t d = s t d y , y 为 传 入 的 标 准 差 y \begin{aligned} &new\_mean = \frac{mean-x}{y}&, mean为原数据的均值,x为传入的均值x \\ &new\_std = \frac{std}{y} &,y为传入的标准差y\\ \end{aligned} new_mean=ymean−xnew_std=ystd,mean为原数据的均值,x为传入的均值x,y为传入的标准差y
2.1.3 torchvision.transforms.Compose(transforms)
将多个transform组合起来使用。
例如
transforms.Compose([
torchvision.transforms.ToTensor(), #先转化为Tensor
torchvision.transforms.Normalize(mean,std) #在进行正则化
])
2.2 准备MNIST数据集的Dataset和DataLoader
准备训练集
import torchvision
#准备数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
#因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
dataset = torchvision.datasets.MNIST('/data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
#准备数据迭代器
train_dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=True)
准备测试集
import torchvision
#准备数据集,其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化
#因为MNIST只有一个通道(黑白图片),所以元组中只有一个值
dataset = torchvision.datasets.MNIST('/data', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
#准备数据迭代器
train_dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=True)
3. 构建模型
补充:全连接层:当前一层的神经元和前一层的神经元相互链接,其核心操作就是 y = w x y = wx y=wx,即矩阵的乘法,实现对前一层的数据的变换
模型的构建使用了一个三层的神经网络,其中包括两个全连接层和一个输出层,第一个全连接层会经过激活函数的处理,将处理后的结果交给下一个全连接层,进行变换后输出结果
那么在这个模型中有两个地方需要注意:
- 激活函数如何使用
- 每一层数据的形状
- 模型的损失函数
3.1 激活函数的使用
前面介绍了激活函数的作用,常用的激活函数为Relu激活函数,他的使用非常简单
Relu激活函数由import torch.nn.functional as F提供,F.relu(x)即可对x进行处理
例如:
In [30]: b
Out[30]: tensor([-2, -1, 0, 1, 2])
In [31]: import torch.nn.functional as F
In [32]: F.relu(b)
Out[32]: tensor([0, 0, 0, 1, 2])
3.2 模型中数据的形状(【添加形状变化图形】)
- 原始输入数据为的形状:
[batch_size,1,28,28] - 进行形状的修改:
[batch_size,28*28],(全连接层是在进行矩阵的乘法操作) - 第一个全连接层的输出形状:
[batch_size,28],这里的28是个人设定的,你也可以设置为别的 - 激活函数不会修改数据的形状
- 第二个全连接层的输出形状:
[batch_size,10],因为手写数字有10个类别
构建模型的代码如下:
import torch
from torch import nn
import torch.nn.functional as F
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet,self).__init__()
self.fc1 = nn.Linear(28*28*1,28) #定义Linear的输入和输出的形状
self.fc2 = nn.Linear(28,10) #定义Linear的输入和输出的形状
def forward(self,x):
x = x.view(-1,28*28*1) #对数据形状变形,-1表示该位置根据后面的形状自动调整
x = self.fc1(x) #[batch_size,28]
x = F.relu(x) #[batch_size,28]
x = self.fc2(x) #[batch_size,10]
可以发现:pytorch在构建模型的时候形状上并不会考虑batch_size
3.3 模型的损失函数
首先,我们需要明确,当前我们手写字体识别的问题是一个多分类的问题,所谓多分类对比的是之前学习的2分类
回顾之前的课程,我们在逻辑回归中,我们使用sigmoid进行计算对数似然损失,来定义我们的2分类的损失。
-
在2分类中我们有正类和负类,正类的概率为 P ( x ) = 1 1 + e − x = e x 1 + e x P(x) = \frac{1}{1+e^{-x}} = \frac{e^x}{1+e^x} P(x)=1+e−x1=1+exex,那么负类的概率为 1 − P ( x ) 1-P(x) 1−P(x)
-
将这个结果进行计算对数似然损失 − ∑ y l o g ( P ( x ) ) -\sum y log(P(x)) −∑ylog(P(x))就可以得到最终的损失
那么在多分类的过程中我们应该怎么做呢?
-
多分类和2分类中唯一的区别是我们不能够再使用sigmoid函数来计算当前样本属于某个类别的概率,而应该使用softmax函数。
-
softmax和sigmoid的区别在于我们需要去计算样本属于每个类别的概率,需要计算多次,而sigmoid只需要计算一次
softmax的公式如下:
σ ( z ) j = e z j ∑ k = 1 K e z K , j = 1 ⋯ k \sigma(z)_j = \frac{e^{z_j}}{\sum^K_{k=1}e^{z_K}} ,j=1 \cdots k σ(z)j=∑k=1KezKezj,j=1⋯k
例如下图:

假如softmax之前的输出结果是2.3, 4.1, 5.6,那么经过softmax之后的结果是多少呢?
Y 1 = e 2.3 e 2.3 + e 4.1 + e 5.6 Y 2 = e 4.1 e 2.3 + e 4.1 + e 5.6 Y 3 = e 5.6 e 2.3 + e 4.1 + e 5.6 Y1 = \frac{e^{2.3}}{e^{2.3}+e^{4.1}+e^{5.6}} \\ Y2 = \frac{e^{4.1}}{e^{2.3}+e^{4.1}+e^{5.6}} \\ Y3 = \frac{e^{5.6}}{e^{2.3}+e^{4.1}+e^{5.6}} \\ Y1=e2.3+e4.1+e5.6e2.3Y2=e2.3+e4.1+e5.6e4.1Y3=e2.3+e4.1+e5.6e5.6
对于这个softmax输出的结果,是在[0,1]区间,我们可以把它当做概率
和前面2分类的损失一样,多分类的损失只需要再把这个结果进行对数似然损失的计算即可
即:
J = − ∑ Y l o g ( P ) , 其 中 P = e z j ∑ k = 1 K e z K , Y 表 示 真 实 值 \begin{aligned} & J = -\sum Y log(P) &, 其中 P = \frac{e^{z_j}}{\sum^K_{k=1}e^{z_K}} ,Y表示真实值 \end{aligned} J=−∑Ylog(P),其中P=∑k=1KezKezj,Y表示真实值
最后,会计算每个样本的损失,即上式的平均值
我们把softmax概率传入对数似然损失得到的损失函数称为交叉熵损失
在pytorch中有两种方法实现交叉熵损失
-
criterion = nn.CrossEntropyLoss() loss = criterion(input,target) -
#1. 对输出值计算softmax和取对数 output = F.log_softmax(x,dim=-1) #2. 使用torch中带权损失 loss = F.nll_loss(output,target)
带权损失定义为: l n = − ∑ w i x i l_n = -\sum w_{i} x_{i} ln=−∑wixi,其实就是把 l o g ( P ) log(P) log(P)作为 x i x_i xi,把真实值Y作为权重
4. 模型的训练
训练的流程:
- 实例化模型,设置模型为训练模式
- 实例化优化器类,实例化损失函数
- 获取,遍历dataloader
- 梯度置为0
- 进行向前计算
- 计算损失
- 反向传播
- 更新参数
mnist_net = MnistNet()
optimizer = optim.Adam(mnist_net.parameters(),lr= 0.001)
def train(epoch):
mode = True
mnist_net.train(mode=mode) #模型设置为训练模型
train_dataloader = get_dataloader(train=mode) #获取训练数据集
for idx,(data,target) in enumerate(train_dataloader):
optimizer.zero_grad() #梯度置为0
output = mnist_net(data) #进行向前计算
loss = F.nll_loss(output,target) #带权损失
loss.backward() #进行反向传播,计算梯度
optimizer.step() #参数更新
if idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, idx * len(data), len(train_dataloader.dataset),
100. * idx / len(train_dataloader), loss.item()))
5. 模型的保存和加载
5.1 模型的保存
保存模型的后缀(.pt)随便写,便于识别即可
torch.save(mnist_net.state_dict(),"model/mnist_net.pt") #保存模型参数
torch.save(optimizer.state_dict(), 'results/mnist_optimizer.pt') #保存优化器参数
5.2 模型的加载
mnist_net.load_state_dict(torch.load("model/mnist_net.pt"))
optimizer.load_state_dict(torch.load("results/mnist_optimizer.pt"))
6. 模型的评估
评估的过程和训练的过程相似,但是:
- 不需要计算梯度
- 需要收集损失和准确率,用来计算平均损失和平均准确率
- 损失的计算和训练时候损失的计算方法相同
- 准确率的计算:
- 模型的输出为[batch_size,10]的形状
- 其中最大值的位置就是其预测的目标值(预测值进行过sotfmax后为概率,sotfmax中分母都是相同的,分子越大,概率越大)
- 最大值的位置获取的方法可以使用
torch.max,返回最大值和最大值的位置 - 返回最大值的位置后,和真实值(
[batch_size])进行对比,相同表示预测成功
def test():
test_loss = 0
correct = 0
mnist_net.eval() #设置模型为评估模式
test_dataloader = get_dataloader(train=False) #获取评估数据集
with torch.no_grad(): #不计算其梯度
for data, target in test_dataloader:
output = mnist_net(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1] #获取最大值的位置,[batch_size,1]
correct += pred.eq(target.data.view_as(pred)).sum() #预测准备样本数累加
test_loss /= len(test_dataloader.dataset) #计算平均损失
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(test_dataloader.dataset),
100. * correct / len(test_dataloader.dataset)))
7. 手写数字识别(完整代码):
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
import torchvision
from tqdm import tqdm
import numpy as np
train_batch_size = 64
test_batch_size = 1000
img_size = 28
def get_dataloader(train=True):
assert isinstance(train, bool), "train 必须是bool类型"
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.1307,), (0.3081,)), ]) # 其中0.1307,0.3081为MNIST数据的均值和标准差,这样操作能够对其进行标准化【因为MNIST只有一个通道(黑白图片),所以元组中只有一个值】
dataset = torchvision.datasets.MNIST('./data', train=train, download=True, transform=transform) # 准备数据集
batch_size = train_batch_size if train else test_batch_size
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True) # 准备数据迭代器
return dataloader
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.fc1 = nn.Linear(in_features=28 * 28 * 1, out_features=28)
self.fc2 = nn.Linear(in_features=28, out_features=10)
def forward(self, x):
x = x.view(-1, 28 * 28 * 1)
x = self.fc1(x) # [batch_size,28 * 28 * 1] >>> [batch_size,28]
x = F.relu(x) # [batch_size,28] >>> [batch_size,28]
x = self.fc2(x) # [batch_size,28] >>> [batch_size,10]
out = F.log_softmax(x, dim=-1)
return out # return x
mnist_net = MnistNet()
optimizer = optim.Adam(mnist_net.parameters(), lr=0.001)
# criterion = nn.CrossEntropyLoss() # CrossEntropyLoss = softmax + log + NLLLoss
criterion = nn.NLLLoss()
train_loss_list = []
train_count_list = []
def train(epoch):
mode = True
mnist_net.train(mode=mode)
train_dataloader = get_dataloader(train=mode)
bar = tqdm(enumerate(train_dataloader), total=len(train_dataloader))
print("\ntrain---->len(train_dataloader.dataset) = {0}".format(len(train_dataloader.dataset)))
print("train---->len(train_dataloader) = {0}".format(len(train_dataloader)))
total_loss = []
for idx, (data, target) in bar:
# target_one_hot = F.one_hot(target) # One-Hot编码,共有10类 [batch_size] => [batch_size,10]
optimizer.zero_grad() # 每次循环都归零(因为默认每个参数的grad每次计算后是进行累加的)
output = mnist_net(data) # torch.Size([64, 10])
loss = criterion(output, target) # 似然损失 NLLLoss():1D target tensor expected, multi-target not supported
loss.backward()
total_loss.append(loss.item())
optimizer.step()
if idx % 10 == 0:
# print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, idx * len(data), len(train_dataloader.dataset), 100. * idx / len(train_dataloader), loss.item()))
bar.set_description('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, idx * len(data), len(train_dataloader.dataset), 100. * idx / len(train_dataloader), np.mean(total_loss)))
train_loss_list.append(loss.item())
train_count_list.append(idx * train_batch_size + (epoch - 1) * len(train_dataloader))
torch.save(mnist_net.state_dict(), "./model/mnist_net.pkl")
torch.save(optimizer.state_dict(), './results/mnist_optimizer.pkl')
def test(epoch):
test_loss = 0
correct = 0
mnist_net.eval()
test_dataloader = get_dataloader(train=False)
with torch.no_grad():
for data, target in test_dataloader:
output = mnist_net(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1] # 获取最大值的位置,[batch_size,1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_dataloader.dataset)
print('\nTest Epoch: {}: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(epoch, test_loss, correct, len(test_dataloader.dataset), 100. * correct / len(test_dataloader.dataset)))
if __name__ == '__main__':
for i in range(5): # 模型训练5轮
train(i)
test(i)
打印结果:
train---->len(train_dataloader.dataset) = 60000
train---->len(train_dataloader) = 938
Train Epoch: 0 [59520/60000 (99%)] Loss: 0.371781: 100%|██████████| 938/938 [00:08<00:00, 105.64it/s]
Test Epoch: 0: Avg. loss: 0.2308, Accuracy: 9330/10000 (93.30%)
Train Epoch: 1 [0/60000 (0%)] Loss: 0.269116: 0%| | 0/938 [00:00<?, ?it/s]
train---->len(train_dataloader.dataset) = 60000
train---->len(train_dataloader) = 938
Train Epoch: 1 [59520/60000 (99%)] Loss: 0.209807: 100%|██████████| 938/938 [00:09<00:00, 97.48it/s]
Test Epoch: 1: Avg. loss: 0.1888, Accuracy: 9438/10000 (94.38%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.164207: 0%| | 0/938 [00:00<?, ?it/s]
train---->len(train_dataloader.dataset) = 60000
train---->len(train_dataloader) = 938
Train Epoch: 2 [59520/60000 (99%)] Loss: 0.169802: 100%|██████████| 938/938 [00:09<00:00, 103.80it/s]
Test Epoch: 2: Avg. loss: 0.1676, Accuracy: 9491/10000 (94.91%)
train---->len(train_dataloader.dataset) = 60000
train---->len(train_dataloader) = 938
Train Epoch: 3 [59520/60000 (99%)] Loss: 0.147357: 100%|██████████| 938/938 [00:09<00:00, 98.43it/s]
Test Epoch: 3: Avg. loss: 0.1546, Accuracy: 9563/10000 (95.63%)
train---->len(train_dataloader.dataset) = 60000
train---->len(train_dataloader) = 938
Train Epoch: 4 [59520/60000 (99%)] Loss: 0.131380: 100%|██████████| 938/938 [00:09<00:00, 98.10it/s]
Test Epoch: 4: Avg. loss: 0.1401, Accuracy: 9594/10000 (95.94%)
Process finished with exit code 0