学习FPGA之三:FPGA与人工智能
在人工智能时代,AI的算法不断推陈出新,对于硬件的算力和灵活度要求很高。FPGA的灵活性刚好符合AI的特性。
通过FPGA,可以快速开始定制化运算的研究和设计,因为是使用FPGA,所以,可以保证开发软硬件平台的兼容,如果要获得更高性能,就定制ASIC芯片,如果ASIC过于昂贵,或者硬件产品的需求量不足,也可以继续使用FPGA。等到应用规模扩大到合适时机,再转换为定制化芯片,以提高稳定性,降低功耗和平均成本。
下面,用一个比较成功的项目,来说明一下FPGA在AI领域的应用。
一:微软脑波项目
之前我们了解过微软的Catapult 平台,它为微软积累了丰富的FPGA开发,部署,运维的相关经验和人才,利用Catapult平台进行AI应用的加速,就成了合理而自然的下一步。
在Catapult 平台的第三阶段,成功的构建了遍布全球的FPGA资源池,并对资源池中的FPGA硬件资源进行灵活的分配和使用。并且,FPGA在资源池中已经成功和CPU解藕,可以直接连接数据中心,无需CPU做转发。
FPGA有低延时,高带宽的效果,很适合传统深度学习模型的运算。我们把DNN模型分解成若干小部分,每个小部分映射到单个FPGA上实现,然后各部分再通过高速数据中心网络互联,这样,即保证了性能要求,也保持了模型完整性。这就是微软脑波项目的起因。
1.1 脑波项目的系统架构
脑波项目的主要目标,是利用Catapult的大规模FPGA基础设施,为没有硬件设计经验的用户提供深度神经网络的自动部署和硬件加速,同时满足系统和模型的实时性和低成本的要求。
为了实现这个目标,脑波项目提出了一个完整的软硬件解决方案,主要包含以下三点:
1: 对已训练的DNN(深度神经网络)模型根据资源和需求进行自动区域划分的工具链;
2: 对划分好的子模型进行FPGA和CPU映射的系统架构;
3: 在FPGA上实现并优化的NPU(神经网络处理器)软核和指令集。
下图是详细的计算流程图:
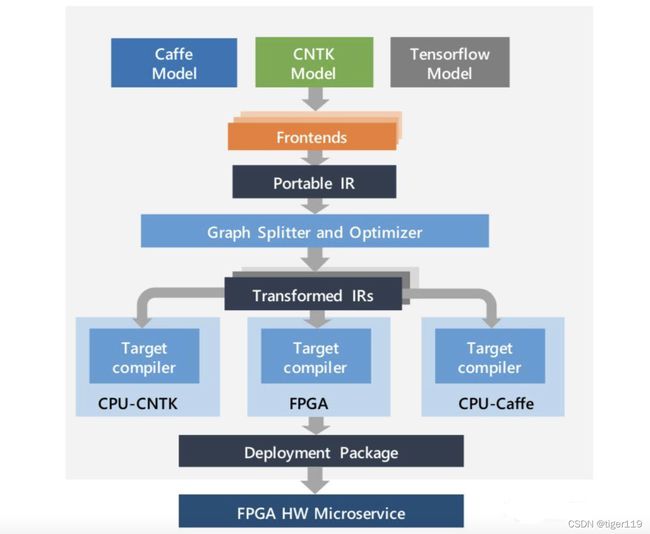
对于一个训练好的DNN模型,工具会首先将其表示为计算流图的形式,称为这个模型的“中间表示”(Intermediate Representation – IR)。
IR表示完成后,工具会继续将整张大图分解成若干小图,使得每个小图都可以完整映射到单个FPGA上实现。对于模型中可能存在的不适合在FPGA上实现的运算和操作,则可以映射到与FPGA相连的CPU上实现。这样就实现了基于Catapult架构的DNN异构加速系统。
在FPGA上进行具体的逻辑实现时,为了解决前文提到的“低延时”与“高带宽”两个关键性需求,脑波项目采用了两种主要的技术措施。
首先,完全弃用了板级DDR内存,全部数据存储都通过片上高速RAM完成。相比其他方案,不管使用ASIC还是FPGA,这一点对于单一芯片的方案都是不可能实现的。
在脑波项目所使用的英特尔Stratix 10 FPGA上,有着11721个512x40b的SRAM模块,相当于30MB的片上内存容量,以及在600MHz运行频率下35Tbps的等效带宽。这30MB片上内存对于DNN应用是完全不够的,但正是基于Catapult的超大规模FPGA的低延时互联,才使得在单一FPGA上十分有限的片上RAM能够组成看似“无限”的资源池,并极大的突破了困扰DNN加速应用已久的内存带宽限制。
第二,脑波项目采用了自定义的窄精度数据位宽。这个其实也是DNN加速领域的常见方法。项目提出了8~9位的浮点数表达方式,称为ms-fp8和ms-fp9。与相同精度的定点数表达方式相比,这种表达需要的逻辑资源数量大致相同,但能够表达更广的动态范围和更高的精度。
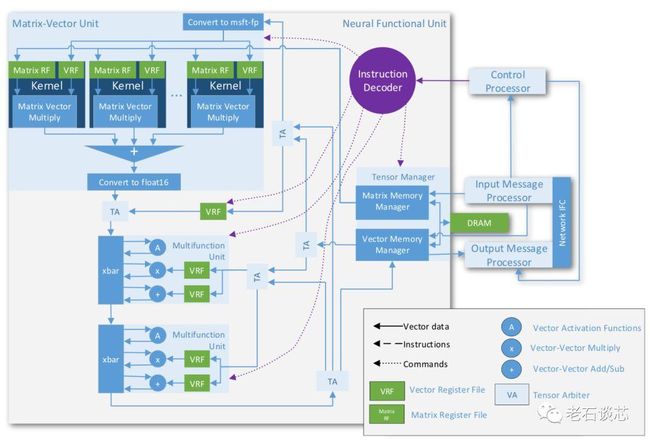
脑波项目的核心单元,是一款在FPGA上实现的软核NPU,及其对应的NPU指令集。这个软核NPU实质上是在高性能与高灵活性之间的一种折中。从宏观上看,DNN的硬件实现可以使用诸如CPU、GPU、FPGA或者ASIC等多种方式实现。在前文中讲过,CPU有着最高的灵活性,但性能不尽如人意;ASIC方案与之相反。而FPGA能够在性能和灵活性之间达到良好的平衡。
脑波NPU的架构图如下所示,NPU的核心是一个进行矩阵向量乘的算术单元MVU。它针对FPGA的底层硬件结构进行了深度优化,并采用了上文提到的“片上内存”和“低精度”的方法进一步提高系统性能。
NPU的最主要特点之一是采用了“超级SIMD”的指令集架构,这与GPU的SIMD指令集类似,但是NPU的一条指令可以生成超过一百万个运算,等效于在英特尔Stratix 10 FPGA上实现每个时钟周期13万次运算。
脑波项目的性能是不错的,脑波NPU在不同FPGA上的性能可看出,它与标准的NPU方案性能相当。脑波项目还对微软的必应搜索中的TP1和DeepScan两个DNN模型做了加速试验,由于必应对实时性要求高,如果用CPU实现,势必要对模型参数的规模做裁剪,从而影响结果精度,相比之下,使用脑波方案可以实现超10倍的规模,同时获得10倍的延时缩减。

脑波项目充分利用了微软遍布全球数据中心的FPGA基础架构,使用FPGA解决了AI应用中“低延时”和“高带宽”两大痛点,并成功构建了基于软核NPU和自定义指令集的实时AI系统。
脑波项目的成功实践,再一次为业界使用FPGA作为AI加速器提供了崭新的思路和借鉴。我们可以相信,在人工智能时代,FPGA必将在更多应用领域得到更加广泛的使用。
二:FPGA与深度神经网络的近似算法
在深度学习中,训练模型和在线推断是两个重要阶段。训练过程,分有监督和无监督事情(这个不是我们的重点),而在线推断实际上已经涉及到硬件的选型。一般有三种选型:
CPU方案:这是较为常用的方案。在学习芯片之前,我只知道这个。
GPU方案:英伟达推出了适合在线推断场景的专用GPU。
FPGA方案:一些公有云厂商推出了基于FPGA在线推断的云服务(为什么用FPGA方案,之前我写的笔记中已多次说明,因为需要推断计算的场景太多,数据中心,基站,自动驾驶汽车,摄像头……),另外一些有实力的AI厂商也在自研FPGA方案。
GPU有强大的并行浮点运算能力,但是高密度的浮点运算势必对系统的能效,实时性,以及数据的存储移动造成很大的压力。越来越多的研究表明,在深度神经网络中采用近似化的方法,可以几乎不损失推断精度的情况下,极大提升系统性能。使用低精度定点数代替浮点数,网络剪枝,网络结构优化,压缩等算法,可以完成近似化,而GPU并不适合这种方法,FPGA和ASIC在定制化硬件时,可以实现DNN的近似化方法。在赛灵思的ACAP器件上,集成了专门的AI推断计算的加速引擎。
如何使用低精度定点数代替浮点数,如何完成网络剪枝,如何做到深度压缩,并不是本文重点,只需要知道FPGA可以完成这些动作,所以,结合这些技术的实现,FPGA可以很好的完成硬件加速。
三:FPGA公司在AI时代的布局
3.1: 赛灵思
之前已经提过,2018年,新CEO上任就把方向调整为数据中心方向,推出ACAP的下一代计算平台。实际上就是在FPGA上集成了AI加速器,2018年,赛灵思收购了中国的AI芯片的初创公司——深鉴科技,这个公司的创始人韩松就是上节所述的网络剪枝和深度压缩的发明人。
2019年,赛灵思发布了Vitis设计软件,其中包含了专门针对AI应用的面向软件的开发框架和库文件,并提供了一些预先训练和优化过的AI模型。包括上面提到的深度压缩,量化,剪枝等技术,包括深鉴公司的DNNDK开发框架,也被整合成Vitis的AI优化器。
3.2: 英特尔
和赛灵思相比,英特尔的FPGA业务只占它业务量很小一部分。由于错过了移动时代的前车之鉴,英特尔不能再错过 AI 数据中心这个重要方向。再加上,英伟达的GPU已经有很强的垄断地位。各大互联网公司也在自主研发深度学习的加速芯片,所以,英特尔一直也在发力。
英特尔收购了多家AI芯片的初创公司,
3.3: Achronix
这是唯一一家可以和两在巨头一较高下的FPGA公司。
2019年5月发布了Speedster7t的FPGA产品,主打高速网络传输,机器学习加速。它针对AI计算做了充分的优化。最多能集成300Mb的片上内存,和英特尔的高端产品Stratix10近似。另外,这款FPGA基于台积台的7nm工艺制造,与赛灵思的ACAP相同,与英特尔的Agilex系列相比,也有很强的竟争力。在芯片架构上,与赛灵思的ACAP类似,采用横向和纵向的2D片上网络。
四:FPGA在AI时代的发展方向
FPGA的方向之一,是集成越来越多的AI相关资源。
如何提高易用性和工具的支持,是另一个需要关注的。让AI工程师掌FPGA的编程和开发是不现实的,因此,如何对现有人工智能的IP进行封装和复用,是一个焦点。
两个FPGA公司都支持OpenCL(高层次开发语言),但是,OpenCL的设计移植性并不好,因此,英特尔还发布于基于OpenVINO的开发套件,它专门针对深度学习的边缘计算场景。
FPGA在AI领域的应用逐步扩展到网络边缘和端点,如:智能安防,视频采集和处理,自动驾驶,机器人。