机器学习的练功方式(七)——决策树
文章目录
-
- 致谢
- 7 决策树
-
- 7.1 认识决策树
- 7.2 决策树原理
- 7.3 信息论
-
- 7.3.1 信息熵
-
- 7.3.1.1 熵
- 7.3.1.2 信息
- 7.3.1.3 信息熵
- 7.3.2 信息增益
- 7.4 决策树实现
- 7.5 决策图
- 7.6 后话
致谢
信息熵是什么? - 知乎 (zhihu.com)
没有免费午餐定理_百度百科 (baidu.com)
7 决策树
决策树(decision tree)是功能强大而且相当受欢迎的分类和预测算法。其属于有监督学习的一种,以树状图为基础。决策树分为预测决策树和回归决策树。其使用一系列的if-then语句来作为决策方法。在下面的讲解时,我们优先讲解分类决策树。
7.1 认识决策树
我们用下面的一个例子来讲明决策树的分类原理。
我们根据每个用户的年龄、工作情况、有无自己房子和信贷情况来判断银行是否允许该用户贷款。
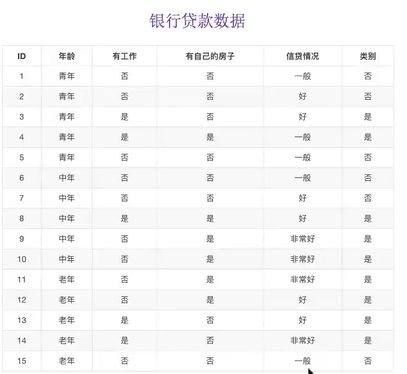
如果我们先看房子的情况、再看工作情况,那我们可以很快地判断出是否可以给该用户贷款;而如果先看年龄,信贷情况,工作这三个特征,那么判断的速度就要慢很多。决策树致力于在这些顺序中找出一个最快的顺序,并以该顺序迅速分类。
从上面的叙述中我们可以总结出:我们可以把决策树看成是一个if-then规则的集合。在决策树的每条路径中,我们可以构建对应的规则决定特征选取的先后,而叶结点则对应该规则的结论。
7.2 决策树原理
我们再引入一个例子:我们现在有一个招生办公室获取的关于学生的两项数据,也就是他们在一场考试中的考试成绩(test)和等级(grades)。我们将这些同学的数据画在散点图上,蓝点同学表示可以被录取,而红点同学表示不可以被录取,如下图所示:
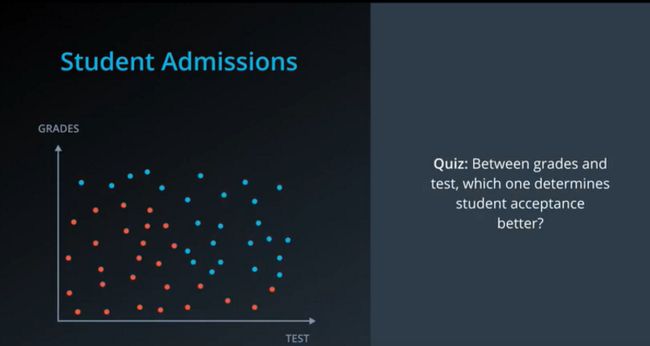
在这里我们提问,在成绩和等级之间,哪一项对学生的录取与否更具决定性?
这个问题实际上我们很难回答,但是我们可以用一条横线来划分。如果是Grades比较重要,那我们就用一条横线试图一次性将红蓝点分开。
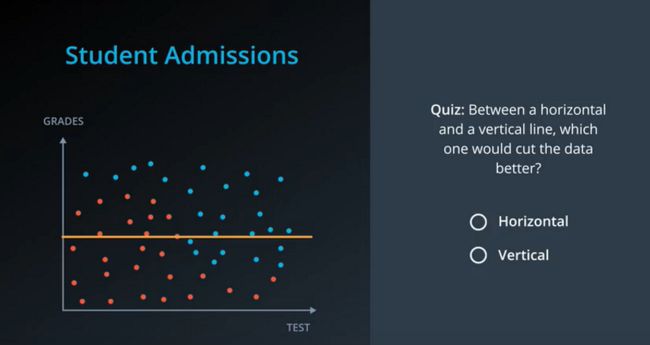
我们把这种在特征空间中根据某个特征来划分类别的方式叫做特征选择。体现在这个例子中,其中考试成绩为横坐标,等级为纵坐标,那么问题就变成了,在横坐标和纵坐标中,哪一项能更好地分割数据。
如果像上图一样划一道横坐标线,那么确实可以分类一部分,但是效果不是很好。有七个蓝点跑到红点群这边过来了。
如果是Test比较重要,那我们就用一条竖线试图一次性划分红蓝点。
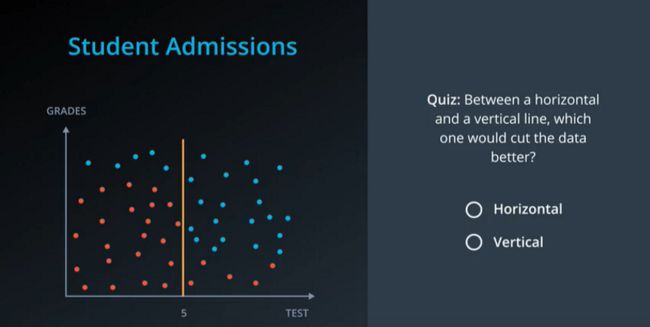
当竖线移到5的位置时,我们发现此时分类效果最好,只有5个点不能被分类出来。这也就意味着,分离这些数据的最佳特征是考试成绩。
我们可以把上述过程用一个决策树来表示,决策树由节点和有向边组成,内部节点表示一个特征或者属性,叶子节点表示一个分类。使用决策树进行分类时,将实例分配到叶节点的类中,该叶节点所属的类就是该节点的分类。
此刻我们开始构建决策树的第一个步骤,特征选择。
特征选择就是选取有较强分类能力的特征。如果利用某些特征进行分类的结果和随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。分类能力通过信息增益(ID3)或者信息增益比来刻画。
选择特征的标准就是找出局部最优特征作为判断进行切分,取决于切分后节点数据集合中类别的有序程度(纯度),划分后的分区数据越纯,切分规则就越合适,衡量节点数据集合的纯度有:熵、基尼系数和方差。熵和基尼系数都是针对分类的,方差是针对回归的。
上面的这段话话可能信息量太大,如果你听不懂没关系我们下面会继续谈到他。我们回到我们的例子继续看,如果我们不能一次性就把两类学生分出来,那么我们分两次呢?

明显地,我们第一次分类考试成绩是最佳特征,而第二次分类考试等级为最佳特征。
经过上面的叙述我们可以知道这么一件事:我们构建决策树是将所有的训练样本都放于根节点。然后我们根据一个最优特征将所有训练样本分割成若干个子集,确保各个子集有最好的分类效果。如果分类效果已经达到我们的目的,那我们直接构建叶结点,并且将子集划分到对应的叶结点中。如果分类效果没有达到我们的目的,则对该子集继续划分。
7.3 信息论
决策树根据不同的分类依据可以分为不同的决策树,常见的决策树有ID3(信息增益)、C4.5(信息增益比)、CART(基尼系数)。在下面的小节中,我会着重介绍分类依据的原理,让我们接着看下去吧!
7.3.1 信息熵
7.3.1.1 熵
熵是一个物理学概念,第一次初见可能是在高中物理课本的热力学那一部分。但是在信息学中,熵就是另外一个意思了。别急,让我们接着往下看。
我们来看下面关于液态水结构的三张图。由于冰中的粒子活动空间较小,其结构比较坚固,粒子大多数都固定不动,液态水的结构坚固程度次之,粒子有一定的活动空间,而水蒸气的结构则处于另外一个极端,一个粒子的去向有多种可能性,可经常移动。

说白了熵其实就是描述粒子的无序性,冰很有序很稳定,所以熵最小。
7.3.1.2 信息
让我们来看看信息是什么。假如现在小明说了一句话:我今年19岁。那么这句话已经表明了小明今年19岁,所以我们说小明的话是一条信息。假设在小明说完之后,小刚说了一句:小明明年就20岁了。那么这完全是一个废话,它在之前确定的信息的基础上又重复了一遍,所以我们说小刚的话不是信息。
从上面的例子揭示了一件事。信息是不能重复的。
现在小明又说了一句话:我可能有女朋友。这就意味着情况多变,小明有可能有女朋友也有可能没女朋友;换而言之,小明这句话信息量很大,不确定性很多。
从上面的例子揭示了一件事,信息量的大小和不确定性有关。
现在我们需要思考一个问题:信息是否可被量化?在这里我直接告诉你结论,信息是可以被量化的,量化的大小就是用信息熵。从上面的例子来看,消除熵意味着获取信息。
7.3.1.3 信息熵
信息熵的公式怎么推断呢?
- 我觉得信息熵肯定不是一个负数。不然说句话就反偷别人的信息,那别人都懵逼了不是?你说句话把我银行卡密码的信息给偷了。
- 信息应该和不确定性有关,如果可能的结果越大,则信息就越多。
我们来看下面一个例子:
熵可以用概率来解释。一些桶里装了小球,不同的桶中装了不同的球。如果现在要我们猜想这些球是怎么摆放的,那么第一个桶里毋庸置疑的肯定是四个红。
在第二个桶中装了三红一蓝,这就意味着要我们摆放有多种可能,根据我们上面提到的,这个桶中的信息熵就比较大了。同样地,第三个桶包含的信息熵比第二个桶还要大。

当我们把球作放回抽取,则每次抽取都是独立重复事件,也就是说,我们抽到在第一个桶抽到四个红球的概率是1,当我们在第二个桶抽三红一蓝的概率,这时候是大约百分之十,在第三个桶抽二红二蓝的概率大约是百分之六。如下图所示:

然而,这些结果可能会因为我们的两个问题而感到费解。
第一,假如我们有一千个球,那么我们得到一千个球的积,这个积总位于零和一之间,有可能非常小5;第二就是,稍微如果改变其中一个因素,可能就会对最后的积产生极大的影响,如上面第一个桶抽到四颗红球概率为1,而第二个桶抽三红一篮概率却突然变为0.105。
为此,我们需要更可控的因素。还有什么比积更好呢?
答案是和,但是我们如何将积的运算转为和的运算呢?答案是对数,因为积的对数等于各自对数之和。
基于信息理论与概率统计,我们采用底数为2或用底数为e(自然对数)的对数函数。而又由于前面提到的防止信息熵变负,而在这里我们的P<=1,对数为负,所以我们在前面填个负号。
在此,我们正式给出信息熵的公式,其用于度量随机变量的不确定性:
H ( X ) = − ∑ i = 1 n P ( x i ) l o g b P ( x i ) H(X)= -\sum^n_{i=1}P(x_i)log_bP(x_i) H(X)=−i=1∑nP(xi)logbP(xi)
其单位为比特。我们看看小球的例子怎么应用这个公式,如下图所示:

掌握了公式了,让我们试着解决7.1例子中的熵问题。
假如我们要求这个数据中的总熵,设训练数据集为D,则 H ( D ) = − ( 6 15 ∗ l o g 2 6 15 + 9 15 ∗ l o g 2 9 15 ) = 0.971 H(D) = -(\frac{6}{15}*log_2{\frac{6}{15}}+\frac{9}{15}*log_2\frac{9}{15}) = 0.971 H(D)=−(156∗log2156+159∗log2159)=0.971。其中 6 15 \frac{6}{15} 156为不可以贷款的用户概率, 9 15 \frac{9}{15} 159为可以贷款的用户概率。
7.3.2 信息增益
信息增益就没法用朴素的例子讲了,我们直接给出简短定义:特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)于特征A给定条件下D的信息条件熵H(D|A)之差,即公式为: g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A) = H(D) - H(D|A) g(D,A)=H(D)−H(D∣A)。
可能讲到这里大家都会很懵,我们为什么要讲信息增益,我们不是要对某一个关键特征动手来尽可能地划分数据吗?实际上,信息增益刻画的是由于特征A而使得对数据集D的分类的不确定性减少的程度,当不确定性程度最大化,则信息增益最大化,则分类后的数据确定性高,分类较完美。所以我们的目的是构建决策树选择信息增益大的特征来划分数据集。
H ( D ) H(D) H(D)我们是知道怎么求的,那 H ( D ∣ A ) H(D|A) H(D∣A),也就是所谓的条件熵怎么求。
在这里我们给出条件熵的公式:
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ D H ( D i ) H(D|A) = \sum^n_{i=1} \frac{|D_i|}{D} H(D_i) H(D∣A)=i=1∑nD∣Di∣H(Di)
拿上例的银行贷款作说明。当我们以A1、A2、A3、A4代表年龄、工作、房子有无情况、贷款情况,然后计算对应的条件概率,在通过这些计算信息增益,最终选择信息增益大的对应那个特征即为关键特征。然后按照我们在7.2讲的方法那样循环即可。
7.4 决策树实现
说完了原理,我们来看一下如何实现一个决策树。
sklearn.tree.DecisionTreeClassifier(criterion = ‘gini’, splitter = ‘best’, max_depth = None,random_state = None)
- criterion:默认是’gini’(基尼)系数,你也可以改成其他判别依据
- splitter:指定切分方式,'best’为选择最优切分,'random’为随机切分
- max_depth:树的深度大小
- random_state:随机数种子
我们来使用上述的API来实现我们的鸢尾花分类吧!
# 导入模块
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def load_data():
"""获取数据集"""
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=4)
return x_train, x_test, y_train, y_test
def decision_iris():
"""决策树算法"""
# 1 获取数据集
x_train, x_test, y_train, y_test = load_data()
# 2 预估器实例化
estimator = DecisionTreeClassifier(criterion="entropy")
# 3 训练数据集
estimator.fit(x_train, y_train)
# 4 模型评估
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
decision_iris()
7.5 决策图
当训练完一颗决策树时,我们是可以通过tree包下的方法来对决策的整个树状过程进行打印输出的。其方法如下所示:
sklearn.tree.export_graphviz((estimator, out_file=“iris_tree.dot”, feature_names=iris.feature_names))
- estimator:预估器
- out_file:输入文件,后缀名必须得为dot
- feature_name:指定输出的特征名
需要注意的是,通过输出后的文件为dot字符文件,如果想要转成可视化,需要用到Graphviz工具。
这里要求安装Graphviz程序。Graphviz是贝尔实验室开发的一个开源的工具包,用于绘制结构化的图形网络,支持多种格式输出,如常用的图片格式、SVG、PDF格式等,且支持Linux/Window操作系统。
我们来对上一节鸢尾花的分类绘制决策图吧。
# 导入模块
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
def decision_iris():
"""决策树算法"""
# 1 获取数据集
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=4)
# 2 预估器实例化
estimator = DecisionTreeClassifier(criterion="entropy")
# 3 训练数据集
estimator.fit(x_train, y_train)
# 4 模型评估
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 5 决策树可视化
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
decision_iris()
当启动代码后,一份名为iris_tree.dot的文件会出现在项目文件夹中。我们可以使用Graphviz进行转换。
这里我们有两种转换方式:
一种是直接打开Webgraphviz这个在线工具包,把dot文件内容复制完粘贴绘制即可。但是我后来试了一下这个网站好像坏了,你们也可以试试。
第二种是使用Graphviz工具包,步骤如下:
- 使用conda install Graphviz指令在cmd或者Anaconda prompt进行下载
- 下载完成后用dot -version查看是否下载成功
- 利用cd命令进入dot文件所在位置
- 使用
dot -Tpdf iris_tree.dot -o iris_tree.pdf进行转换 - 查看桌面pdf文件
效果如下:
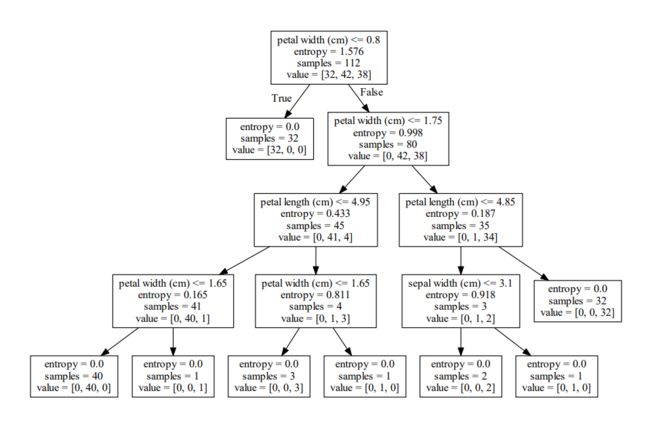
7.6 后话
这一讲就到这里吧,虽然,没有讲到决策回归树,但是我相信我们与它还会见面的,而这么做的目的是,一口气吃成一个胖子是不现实的。在这一讲中,实际上API里面很多其他的参数我都没说,这是因为要考虑我们是初学者的缘故,当你学懂这一讲的时候,你可以看一些偏向于机器学习代码实现的书,它们讲的都比我全。
至于决策树我们可以看到,其分类的准确率和KNN的准确率是不太一样的。实际上,这正是业界内经常谈到的——没有免费午餐定理。不同的算法在同一个训练过程中的表现是不一样的。如果我们不对特征空间有先验假设,则所有算法的平均表现是一样的。
也就是说,没有所谓的世界上最好的算法,只有公认的好方法(支持向量机、决策树、神经网络等)。在进行分类或回归时,我们可以采用不同的算法和调参去提高准确率。
在下一讲中,我们会补全这一讲没有谈到的随机森林和剪枝,如果我还有精力的话,我会再说说其他决策树算法。感谢您的观看。