基于Pytorch 实现残差网络ResNet
基于Pytorch 实现残差网络ResNet
(一)残差?
“数理统计中残差是指实际观察值与估计值(拟合值)之间的差。如果回归模型正确的话, 可以将残差看作误差的观测值。”
“统计学上把数据点与它在回归直线上相应位置的差异称残差”
简单地说,已知函数f(x),想得到f(x0)=b时x0的取值,x0未知,给定一个x0的估计值x1,可以根据b-f(x1)可以求得残差。(与误差x1-x0区别:可以在x0未知的情况下取得)
(二)残差网络
1)Idea起源:
神经网络随着层数的增加可能会出现两个问题:精度下降问题 和 梯度消失/爆炸问题。
2)Idea: 引入恒等映射
恒等映射(Identity Mapping):对任意集合A,如果将映射f : A → A 定义为f ( x ) = x ,即规定A中每个元素x 与自身对应,则称f 为A上的恒等映射
在极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过一堆非线性层来拟合恒等映射更容易。快捷连接简单地执行恒等映射,并将其输出添加到堆叠层的输出(图2)。恒等快捷连接既不增加额外的参数也不增加计算复杂度。整个网络仍然可以由带有反向传播的SGD进行端到端的训练。
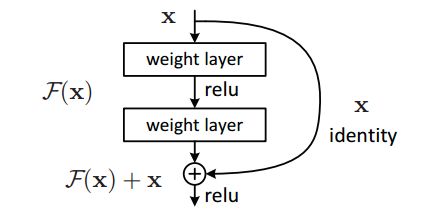
原始网络: 输入: x 输出:权重w'和x的关系函数 目标:F(x,w')->目标函数H(x)
残差网络: 输入:又添加了一个 x 输出: F(x)+x 目标: F(x,w)+x ->目标函数H(x) 即F(x,w)->H(x)-x (如果F(x,w)权重都为零,即为恒等映射)
3)残差网络结构

作者提出的残差块有两种结构(左图:对应Res-18/34 右图:对应Res-54/101/152):
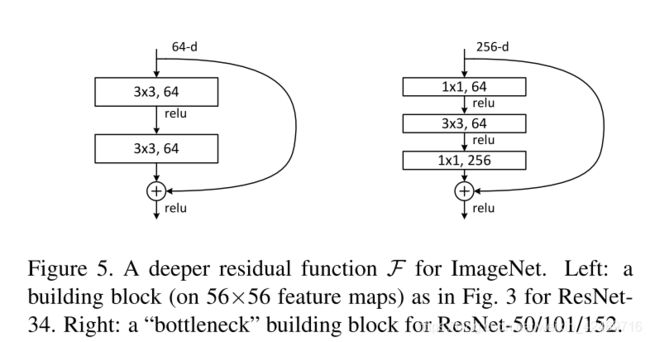
4) 残差网络逐步实现(ResNet-18 和 ResNet-54)
ResNet-18
ResNet-18分为6个部分:
1. Conv1:第一层卷积,没有shortcut机制。
2. layer1:第一个残差块,一共有2个。(每个Layer由若干个Block组成)
3. layer2:第二个残差块,一共有2个。
4. layer3:第三个残差块,一共有2个。
5. layer4:第四个残差块,一共有2个。
6. fc:全连阶层。
PS:这里的残差块是:BasicBlock(区别于后面ResNet中用到的Bottleneck)1 Conv1

输入输出用椭圆形表示,中间是输入输出的尺寸:channel×height×width
直角矩形框指的是卷积层或pooling层,如“3×3,64,stride=2,padding=3 3 \times 3, 64, stride = 2, padding = 33×3,64,stride=2,padding=3”指该卷积层kernel size为3×3 3 \times 33×3,输出channel数为64,步长为2,padding为3。矩形框代表的层种类在方框右侧标注,如“conv1”。
卷积层的输出尺寸计算公式:

2 Layer1

layer1的结构中没有downsample。右图是BasicBlock的主要结构——两个3×3 卷积层。Layer1由两个Block组成(左图中×2) ,即 两个右图结构重复连接。
2 Layer2

layer2:
首先64×56×56输入进入第1个block的conv1,这个conv1的stride变为2,和layer1不同(图红圈标注),这是为了降低输入尺寸,减少数据量,输出尺寸为128×28×28 。
最后到第1个block的末尾处,需要在output加上residual,但是输入的尺寸为64×56×56 ,所以在输入和输出之间加一个 1×1 卷积层,stride=2(图红圈标注),作用是使输入和输出尺寸统一(该部分即:PyTorch ResNet代码中的downsample)。由于已经降低了尺寸,连接的第2个block的conv1的stride就设置为1。由于该block没有降低尺寸,residual和输出尺寸相同,所以也没有downsample部分。
3 layer3-4
layer3和layer4结构和layer2相同,只是通道数变多,输出尺寸变小。
ResNet18和34都是基于Basicblock,结构非常相似,差别只在于每个layer的block数。
Pytorch实现ResNet-18
import torch
import torch.nn as nn
import torch.nn.functionl as F
#定义残差块ResBlock
class ResBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResBlock, self).__init__()
#残差块内连续的2个卷积层
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
#shortcut,这里为了跟2个卷积层的结果结构一致,要做处理
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
#将2个卷积层的输出跟处理过的x相加,实现ResNet的基本结构
out = out + self.shortcut(x)
out = F.relu(out)
return out
#实现ResNet-18模型
class ResNet(nn.Module):
def __init__(self, ResBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.layer1 = self.make_layer(ResBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
#这个函数主要是用来,重复同一个残差块
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
#在这里,整个ResNet18的结构就很清晰了
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out使用CIFAR10数据集测试搭建的ResNet18模型
from resnet import ResNet18
#Use the ResNet18 on Cifar-10
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
#check gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#set hyperparameter
EPOCH = 10
pre_epoch = 0
BATCH_SIZE = 128
LR = 0.01
#prepare dataset and preprocessing
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
trainset = torchvision.datasets.CIFAR10(root='../data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
#labels in CIFAR10
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#define ResNet18
net = ResNet18().to(device)
#define loss funtion & optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
#train
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
#prepare dataset
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
#forward & backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
#print ac & loss in each batch
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
#get the ac with testdataset in each epoch
print('Waiting Test...')
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Test\'s ac is: %.3f%%' % (100 * correct / total))
print('Train has finished, total epoch is %d' % EPOCH)ResNet-50
1. Conv1:第一层卷积,没有shortcut机制。
2. layer1:第一个残差块,一共有3个。(这里的残差块:Bottleneck:输入输出前后添加一个1×1卷积)
3. layer2:第二个残差块,一共有4个。
4. layer3:第三个残差块,一共有6个。
5. layer4:第四个残差块,一共有3个。
6. fc:全连阶层。1 Layer1

和Basicblock不同的一点是,每一个Bottleneck都会在输入和输出之间加上一个卷积层,只不过在layer1中还没有downsample,这点和Basicblock是相同的。至于一定要加上卷积层的原因,就在于Bottleneck的conv3会将输入的通道数扩展成原来的4倍,导致输入一定和输出尺寸不同。左图×3依旧代表右图结构三个重复连接。
2 Layer2

尺寸为256×56×56 输入进入layer2的第1个block后,首先要通过conv1将通道数降下来,之后conv2负责将尺寸降低(stride=2,图从左向右数第2个红圈标注)。到输出处,由于尺寸发生变化,需要将输入downsample,同样是通过stride=2的1×1 1\times11×1卷积层实现。
之后的3个block(layer2有4个block)就不需要进行downsample了(无论是residual还是输入),如图从左向右数第3、4个红圈标注,stride均为1。
3 layer3-4
layer3和layer4结构和layer2相同,只是通道数变多,输出尺寸变小。
ResNet50、101和152都是基于Basicblock,结构非常相似,差别只在于每个layer的block数。
PyTorch实现ResNet-50
import torch
import torch.nn as nn
import torchvision
import numpy as np
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
__all__ = ['ResNet50', 'ResNet101','ResNet152']
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes,out_channels=places,kernel_size=7,stride=stride,padding=3, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
class Bottleneck(nn.Module):
def __init__(self,in_places,places, stride=1,downsampling=False, expansion = 4):
super(Bottleneck,self).__init__()
self.expansion = expansion
self.downsampling = downsampling
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_places,out_channels=places,kernel_size=1,stride=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places*self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places*self.expansion),
)
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places*self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(places*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.bottleneck(x)
if self.downsampling:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,blocks, num_classes=1000, expansion = 4):
super(ResNet,self).__init__()
self.expansion = expansion
self.conv1 = Conv1(in_planes = 3, places= 64)
self.layer1 = self.make_layer(in_places = 64, places= 64, block=blocks[0], stride=1)
self.layer2 = self.make_layer(in_places = 256,places=128, block=blocks[1], stride=2)
self.layer3 = self.make_layer(in_places=512,places=256, block=blocks[2], stride=2)
self.layer4 = self.make_layer(in_places=1024,places=512, block=blocks[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(2048,num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def make_layer(self, in_places, places, block, stride):
layers = []
layers.append(Bottleneck(in_places, places,stride, downsampling =True))
for i in range(1, block):
layers.append(Bottleneck(places*self.expansion, places))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def ResNet50():
return ResNet([3, 4, 6, 3])
def ResNet101():
return ResNet([3, 4, 23, 3])
def ResNet152():
return ResNet([3, 8, 36, 3])
if __name__=='__main__':
#model = torchvision.models.resnet50()
model = ResNet50()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
使用CIFAR10数据集测试搭建的ResNet-50模型
CIFAR-10数据集简介:
数据集共有60000张彩色图像,32*32,分为10个类(10类各自独立,不会出现重叠),每类6000张图。
训练集:50000张 5个训练批次 10000/批次 (一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图)
测试集:10000张 1个批次 (取自10类中的每一类,每一类随机取1000张,剩下的就随机排列组成了训练批)
下面这幅图就是列举了10个类,每一类展示了随机的10张图片:

# encoding: utf-8
import torch
import torch.nn as nn
import torchvision
import numpy as np
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
import torch.optim as optim
__all__ = ['ResNet50', 'ResNet101','ResNet152']
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes,out_channels=places,kernel_size=7,stride=stride,padding=3, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
class Bottleneck(nn.Module):
def __init__(self,in_places,places, stride=1,downsampling=False, expansion = 4):
super(Bottleneck,self).__init__()
self.expansion = expansion
self.downsampling = downsampling
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_places,out_channels=places,kernel_size=1,stride=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places*self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places*self.expansion),
)
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places*self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(places*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.bottleneck(x)
if self.downsampling:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,blocks, num_classes=1000, expansion = 4):
super(ResNet,self).__init__()
self.expansion = expansion
self.conv1 = Conv1(in_planes = 3, places= 64)
self.layer1 = self.make_layer(in_places =64, places=64, block=blocks[0], stride=1)
self.layer2 = self.make_layer(in_places =256,places=128, block=blocks[1], stride=2)
self.layer3 = self.make_layer(in_places=512,places=256, block=blocks[2], stride=2)
self.layer4 = self.make_layer(in_places=1024,places=512, block=blocks[3], stride=2)
self.avgpool = nn.AvgPool2d(1, stride=1)#修改池化层卷积核大小:7 -> 1
self.fc = nn.Linear(2048,num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def make_layer(self, in_places, places, block, stride):
layers = []
layers.append(Bottleneck(in_places, places,stride, downsampling =True))
for i in range(1, block):
layers.append(Bottleneck(places*self.expansion, places))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def ResNet50():
return ResNet([3, 4, 6, 3])
def ResNet101():
return ResNet([3, 4, 23, 3])
def ResNet152():
return ResNet([3, 8, 36, 3])
if __name__=='__main__':
#model = torchvision.models.resnet50()
# model = ResNet50()
# print(model)
#
# input = torch.randn(1, 3, 224, 224)
# out = model(input)
# print(out.shape)
# check gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# set hyperparameter
EPOCH = 10
pre_epoch = 0
BATCH_SIZE = 128
LR = 0.01
# prepare dataset and preprocessing
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
trainset = torchvision.datasets.CIFAR10(root='/home/lxm/2021-2-1/data', train=True, download=True,
transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='/home/lxm/2021-2-1/data', train=False, download=True,
transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# labels in CIFAR10
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# define ResNet18
net = ResNet50().to(device)
# define loss funtion & optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# train
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
# prepare dataset
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# forward & backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print ac & loss in each batch
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
# get the ac with testdataset in each epoch
print('Waiting Test...')
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Test\'s ac is: %.3f%%' % (100 * correct / total))
print('Train has finished, total epoch is %d' % EPOCH)参考博客:
ResNet论文详解_DUT_jiawen的博客-CSDN博客_resnet论文
ResNet网络结构分析 - 知乎
通过Pytorch实现ResNet18 - 知乎
PyTorch实现的ResNet50、ResNet101和ResNet152_mingo_敏-CSDN博客