Dataset和DataLoader;pytorch-lightning、pytorch训练代码大概流程
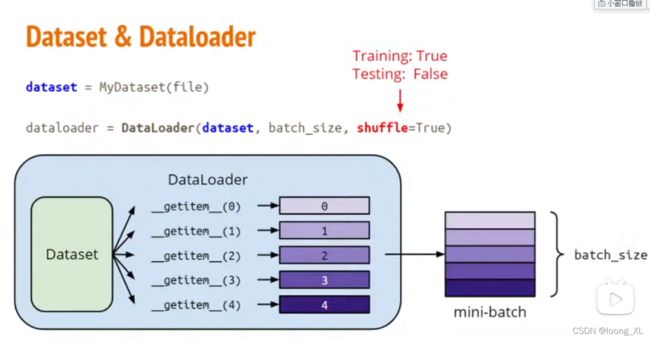
1、Dataset和DataLoader
1)Dataset类,构建数据,需要重写__len__和__getitem__这两个函数
2)DataLoader,迭代器,加载Dataset数据把分batch用作模型输入

import torch
import torch.utils.data.dataset as Dataset
#引入DataLoader:
import torch.utils.data.dataloader as DataLoader
import numpy as np
Data = np.asarray([[1, 2], [3, 4],[5, 6], [7, 8]])
Label = np.asarray([[0], [1], [0], [2]])
#创建子类
class subDataset(Dataset.Dataset):
#初始化,定义数据内容和标签
def __init__(self, Data, Label):
self.Data = Data
self.Label = Label
#返回数据集大小
def __len__(self):
return len(self.Data)
#得到数据内容和标签
def __getitem__(self, index):
data = torch.Tensor(self.Data[index])
label = torch.IntTensor(self.Label[index])
return data, label
if __name__ == '__main__':
dataset = subDataset(Data, Label)
print(dataset)
print('dataset大小为:', dataset.__len__())
print(dataset.__getitem__(0))
print(dataset[0])
#创建DataLoader迭代器
#创建DataLoader,batch_size设置为2,shuffle=False不打乱数据顺序,num_workers= 4使用4个子进程:
dataloader = DataLoader.DataLoader(dataset,batch_size= 2, shuffle = False, num_workers= 0)
#使用enumerate访问可遍历的数组对象:
for i, item in enumerate(dataloader):
print('i:', i)
data, label = item
print('data:', data)
print('label:', label)
batch_size= 2

 DataLoader 单独取值iter
DataLoader 单独取值iter
data_loader = DataLoader.DataLoader(dataset,batch_size= 2, shuffle = False, num_workers= 0)
iter(data_loader).next() ##单独取一个batch

DataLoader数据集划分
参考:https://www.jianshu.com/p/dd698d3eb451
from torch.utils.data import Dataset, DataLoader,SubsetRandomSampler
dataset = subDataset(Data, Label)
# 首先产生数据索引的乱序排列
shuffled_indices = np.random.permutation(len(dataset))
train_idx = shuffled_indices[:int(0.8*len(dataset))]
val_idx = shuffled_indices[int(0.8*len(dataset)):]
train_loader = DataLoader(dataset, batch_size = 6, drop_last = True, sampler = SubsetRandomSampler(train_idx))
val_loader = DataLoader(dataset, batch_size = 6, drop_last=False, sampler=SubsetRandomSampler(val_idx))
2-1、pytorch-lightning
参考:https://github.com/PyTorchLightning/pytorch-lightning
pytorch的高层封装,更容易编写;类似于keras之于tensorflow
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, random_split
from torchvision import transforms
import pytorch_lightning as pl
class LitAutoEncoder(pl.LightningModule):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3))
self.decoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28))
def forward(self, x):
# in lightning, forward defines the prediction/inference actions
embedding = self.encoder(x)
return embedding
def training_step(self, batch, batch_idx):
# training_step defines the train loop. It is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = F.mse_loss(x_hat, x)
self.log("train_loss", loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train, val = random_split(dataset, [55000, 5000])
autoencoder = LitAutoEncoder()
trainer = pl.Trainer()
trainer.fit(autoencoder, DataLoader(train), DataLoader(val))
2-2、pytorch代码大概流程
from torch.utils.data import Dataset, DataLoader
from torch import nn, from_numpy, optim
import numpy as np
class DiabetesDataset(Dataset):
""" Diabetes dataset."""
# Initialize your data, download, etc.
def __init__(self):
xy = np.loadtxt('./data/diabetes.csv.gz',
delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = from_numpy(xy[:, 0:-1])
self.y_data = from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
class Model(nn.Module):
def __init__(self):
"""
In the constructor we instantiate two nn.Linear module
"""
super(Model, self).__init__()
self.l1 = nn.Linear(8, 6)
self.l2 = nn.Linear(6, 4)
self.l3 = nn.Linear(4, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
In the forward function we accept a Variable of input data and we must return
a Variable of output data. We can use Modules defined in the constructor as
well as arbitrary operators on Variables.
"""
out1 = self.sigmoid(self.l1(x))
out2 = self.sigmoid(self.l2(out1))
y_pred = self.sigmoid(self.l3(out2))
return y_pred
# our model
model = Model()
# Construct our loss function and an Optimizer. The call to model.parameters()
# in the SGD constructor will contain the learnable parameters of the two
# nn.Linear modules which are members of the model.
criterion = nn.BCELoss(reduction='sum')
optimizer = optim.SGD(model.parameters(), lr=0.1)
# Training loop
for epoch in range(2):
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels = data
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(inputs)
# Compute and print loss
loss = criterion(y_pred, labels)
print(f'Epoch {epoch + 1} | Batch: {i+1} | Loss: {loss.item():.4f}')
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
loss.backward()
optimizer.step()
import torch
from torch.utils.data import DataLoader
# 数据集加载器
train_loader = DataLoader(dataset = train_data, batch_size = 128, shuffle = True)
val_loader = DataLoader(dataset = val_data, batch_size = 1, shuffle = False)
# 定义模型
model = Net()
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr = 0.01)
# 定义损失函数
criterion = torch.nn.CrossEntropyLoss()
# 定义训练epoch的次数
epochs = 500
# 判断设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 开始训练
for epoch in range(epochs):
print('epoch {}'.format(epoch + 1))
train_loss = 0
train_acc = 0
# 训练
model.train()
for i, (x, y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
model = model.to(device)
out = model(x)
loss = criterion(out, y)
train_loss += loss.item()
prediction = torch.max(out,1)[1]
pred_correct = (prediction == y).sum()
train_acc += pred_correct.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('train loss : {:.6f}, acc : {:.6f}'.format(train_loss / len(train_data), train_acc / len(train_data)))
# 验证
model.eval()
with torch.no_grad(): # 或者@torch.no_grad() 被他们包裹的代码块不需要计算梯度, 也不需要反向传播
eval_loss = 0
eval_acc = 0
for i, (x, y) in enmuerate(val_loader):
out = model(x)
loss = criterion(out, y)
eval_loss += loss.item()
prediction = torch.max(out, 1)[1]
pred_correct = (prediction == y).sum()
eval_acc += pred_correct.item()
print('evaluation loss : {:.6f}, acc : {:.6f}'.format(eval_loss / len(val_data), eval_acc / len(val_data)))