【ACL2021】ChineseBERT:香侬科技提出融合字形与拼音信息的中文预训练模型
点击下面卡片,关注我呀,每天给你送来AI技术干货!
来自:PaperWeekly

中文预训练模型
自 BERT 以来,大规模预训练模型已成为自然语言处理研究的一大重点,无论是训练更大的模型,如 BERT 到 RoBERTa, GPT2, GPT3,还是改变预训练方法,如从 Mask Language Model 到 Prompt Pretraining,关于预训练模型的前沿研究从未停滞。
然而,以往的很多预训练模型都是从英文为基础展开:数据为英文,模型架构也为英文而设计(掩码方式)。面向中文的预训练模型,尤其是能够建模汉语这种特定语言特性的预训练模型,相比之下,就较为缺乏。
汉字的最大特性有两个方面:一是字形,二是拼音。汉字是一种典型的意音文字,从其起源来看,它的字形本身就蕴含了一部分语义。比如,“江河湖泊”都有偏旁三点水,这表明它们都与水有关。
而从读音来看,汉字的拼音也能在一定程度上反映一个汉字的语义,起到区别词义的作用。比如,“乐”字有两个读音,yuè 与 lè,前者表示“音乐”,是一个名词;后者表示“高兴”,是一个形容词。而对于一个多音字,单单输入一个“乐”,模型是无法得知它应该是代表“音乐”还是“快乐”,这时候就需要额外的读音信息进行去偏。
为此,本文提出 ChineseBERT,从汉字本身的这两大特性出发,将汉字的字形与拼音信息融入到中文语料的预训练过程。一个汉字的字形向量由多个不同的字体形成,而拼音向量则由对应的罗马化的拼音字符序列得到。二者与字向量一起进行融合,得到最终的融合向量,作为预训练模型的输入。模型使用全词掩码(Whole Word Masking)和字掩码(Character Masking)两种策略训练,使模型更加综合地建立汉字、字形、读音与上下文之间的联系。

论文标题:
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
论文作者:
Zijun Sun, Xiaoya Li, Xiaofei Sun, Yuxian Meng, Xiang Ao, Qing He, Fei Wu and Jiwei Li
论文链接:
https://arxiv.org/abs/2106.16038
收录情况:
Main Conference of ACL 2021
代码链接:
https://github.com/ShannonAI/ChineseBert
在中文机器阅读理解、自然语言推理、文本分类、句对匹配、命名实体识别和分词任务上,ChineseBERT 取得了较为显著的效果提升。在分解实验中,得益于字形信息与拼音信息的正则化效果,ChineseBERT 能在小训练数据的情况下取得更好的效果。
总的来说,本文的贡献如下:
提出将汉字的字形与拼音信息融入到中文预训练模型中,增强模型对中文语料的建模能力;
在中文机器阅读理解等 6 个任务上取得显著的效果提升,在小数据上取得更好的结果;
开源 Base 版本与 Large 版本的预训练模型,供学界使用。
ChineseBERT 的代码、模型均已开源,欢迎大家尝试。

ChineseBERT:融合中文字形与拼音信息
下图是 ChineseBERT 的整体模型框架,主要的改进点在底层的融合层(Fusion Layer)融合了除字嵌入(Char Embedding)之外的字形嵌入(Glyph Embedding)和拼音嵌入(Pinyin Embedding),得到融合嵌入(Fusion Embedding),再与位置嵌入相加,就形成模型的输入。
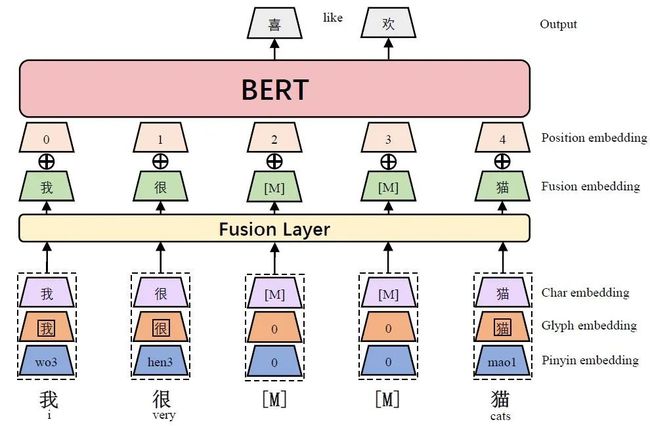
2.1 字形嵌入
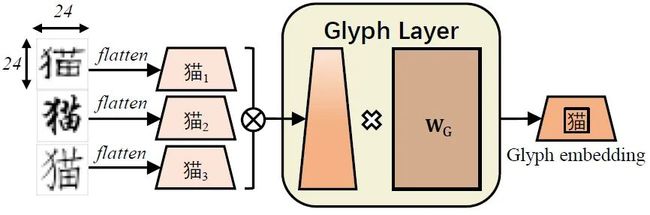
字形嵌入使用不同字体的汉字图像得到。每个图像都是 24*24 的大小,将仿宋、行楷和隶书这三种字体的图像向量化,拼接之后再经过一个全连接 ,就得到了汉字的字形嵌入。
该过程如下图所示:
2.2 拼音嵌入
拼音嵌入首先使用 pypinyin 将每个汉字的拼音转化为罗马化字的字符序列,其中也包含了音调。比如对汉字“猫”,其拼音字符序列就是“mao1”。对于多音字如“乐”,pypinyin能够非常准确地识别当前上下文中正确的拼音,因此ChineseBERT 直接使用 pypinyin 给出的结果。
在获取汉字的拼音序列后,再对该序列使用宽度为 2 的 CNN 与最大池化,得到最终的拼音序列。
该过程如下图所示:

2.3 融合嵌入
将汉字的字嵌入、字形嵌入与拼音嵌入拼接在一起,然后经过一个全连接层 ,就得到了该汉字对应的融合嵌入。

每个汉字对应的融合嵌入与位置嵌入相加,就是每个汉字给模型的输入。模型的输出就是每个汉字对应的高维向量表征,基于该向量表征对模型进行预训练。

预训练
3.1 预训练数据
预训练数据来自 CommonCrawl,在经过数据清洗后,用于预训练 ChineseBERT 的数据规模为约 4B 个汉字。我们使用 LTP toolkit 识别词的边界。
3.2 掩码策略
预训练的一大关键步骤是确定如何掩码(Masking)输入文本。ChineseBERT 综合使用两种掩码策略:全词掩码(Whole Word Masking, WWM)与字掩码(Char Masking, CM)。
字掩码:最简洁最直观的掩码方法,以单个汉字为单位进行掩码。
全词掩码:以词为单位,将词中的所有字掩码。注意基本的输入单元依然是字,只是一个词包含的所有汉字都被掩码。比如,“我喜欢紫禁城”在掩码词“紫禁城”之后就是“我喜欢[M][M][M]”,而非“我喜欢[M]”。
使用两种掩码方式易于模型从不同的角度融合字、字形、拼音及上下文信息。
3.3 预训练细节
由于 ChineseBERT 结构与原始 BERT 在输入层的结构不同,所以 ChineseBERT 从头开始预训练而不用 BERT 初始化。
为了习得短期上下文与长期上下文,ChineseBERT 在 Packed Input 与 Single Input 之间交替训练,前者是将模型的输入扩展到最大长度 512,后者则将单个句子作为输入。Packed Input 作为输入的概率为 0.9,Single Input 作为输入的概率是 0.1。
无论是 Packed Input 还是 Single Input,都在 90% 的时间使用 WWM,在 10% 的时间使用 CM。除此之外,ChineseBERT 还使用了动态掩码策略,避免重复的预训练语料。
ChineseBERT 有 base 和 large 两个版本,分别有 12/24 层,输入向量维度分别是 768/1024,每层head数量为 12/16。其他预训练细节如训练步数、学习率、batch size 详见原文。

实验
我们在中文机器阅读理解(MRC)、自然语言推理(NLI)、文本分类(TC)、句对匹配(SPM)、命名实体识别(NER)和中文分词(CWS)任务上评测 ChineseBERT。比较的基线模型有 ERNIE,BERT-wwm,RoBERTa-wwm 和 MacBERT。
4.1 机器阅读理解
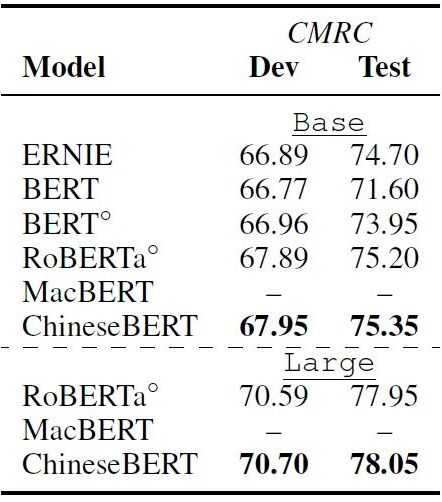
中文机器阅读理解数据集包括 CMRC2018 和 CJRC。CMRC 2018 是抽取式机器阅读理解任务,而 CJRC 则额外包含了“无答案”问题。
下表是实验结果。在两个数据集上,ChineseBERT 都取得了效果提升,值得注意是在 CJRC 数据集上,EM 的提升比 F1 更加显著,这表明 ChineseBERT 能够更好地抽取准确的答案文段。

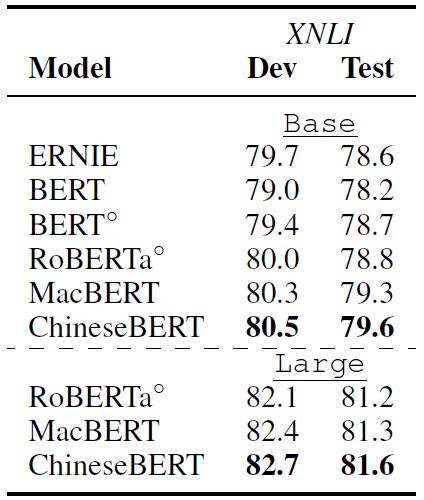
4.2 自然语言推理
自然语言推理数据集为 XNLI,包含了 2.5K 的验证数据和 5K 的测试数据。下表是实验结果,可以看到,ChineseBERT 在测试集上比 MacBERT 提升了 0.3 的准确率。
4.3 文本分类
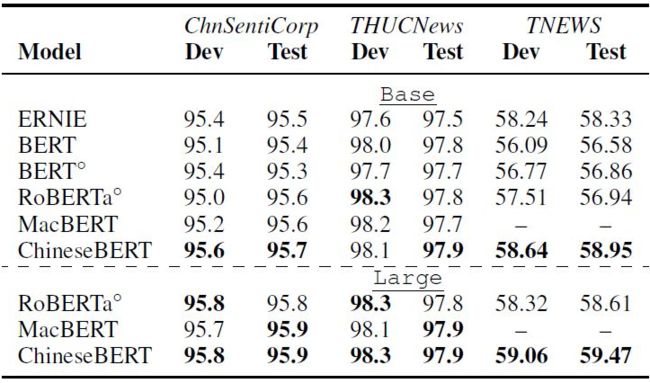
文本分类数据集包括 THUC-News,ChnSentiCorp 和 TNEWS,前两个数据集较为简单,即使是 vanilla BERT 模型都能取得超过 95% 的准确率,而 TNEW 数据集则是一个 15 类短文本新闻分类数据集,难度更大。
下表是实验结果,在 THUCNews 和 ChnSentiCorp 上,ChineseBERT 提升不大,这是因为数据集本身较为简单。在 TNEWS 上,ChineseBERT 的提升更加明显,base 模型提升为 2 个点准确率,large 模型提升约为 1 个点。
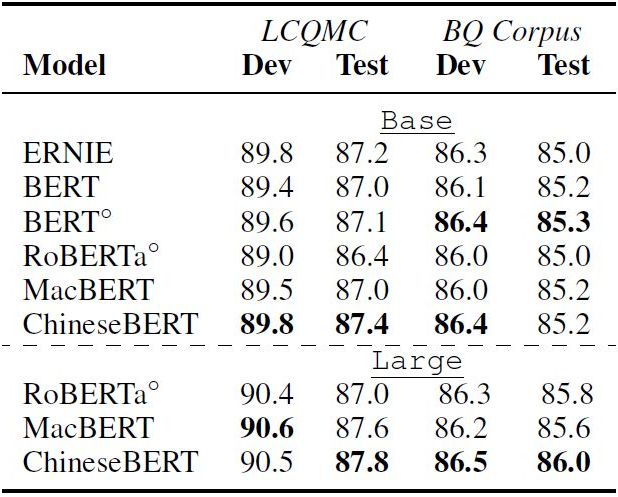
4.4 句对匹配
句对匹配数据集包括 LCQMC 和 BQ Corpus,每条数据给出两个句子,需要判断它们是否有语义相关性。结果如下表所示,在 LCQMC 上,ChineseBERT 提升较为明显,base 模型提升 0.4 的准确率,large 模型提升 0.2 的准确率。在 BQ Corpus 上,large 模型提升了 0.4 的准确率。
4.5 命名实体识别
命名实体识别数据集包括 OntoNotes 4.0 与 Weibo。OntoNotes 4.0 包括 18 种实体类别,Weibo 包括 4 种实体类别。结果如下表所示。相比 Vanilla BERT 与 RoBERTa 模型,ChineseBERT 在两个数据集上均提升了约 1 点的 F1 值。

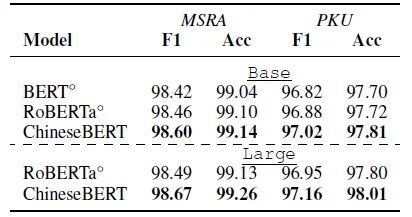
4.6 中文分词
中文分词数据集包括 MSRA 和 PKU,如下表的结果所示,ChineseBERT 在 F1 和 Accuracy 两个指标上均有一定程度的提升。

分解实验
5.1 字形嵌入与拼音嵌入的效果
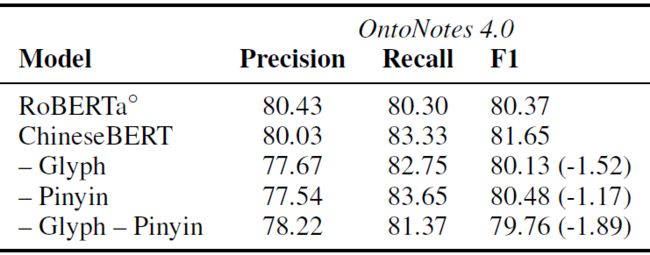
首先我们探究字形嵌入和拼音嵌入是否对下游任务有效。我们在命名实体识别数据集 OntoNotes 4.0 上实验。我们分别去掉字形嵌入、拼音嵌入以及二者,检验它们在测试集上的效果。
结果如下表所示。可以看到,不管是移除字形嵌入还是拼音嵌入,都会严重损害模型效果:移除字形嵌入使 F1 值降低 1.52,移除拼音嵌入使模型 F1 值下降 1.17,而移除两者导致模型 F1 值下降 1.89。以上结果表明了,字形嵌入和拼音嵌入具备一定的信息增益效果。
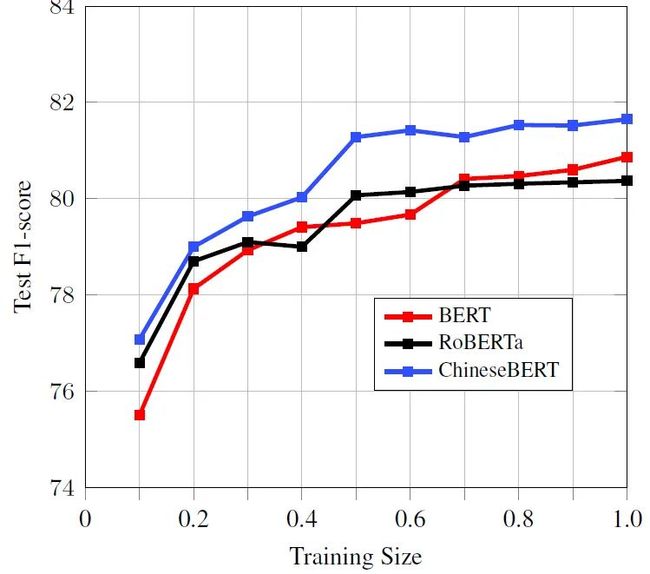
5.2 小数据量下的模型效果
因为引入了字形与拼音信息,我们猜测在更小的下游任务训练数据上,ChineseBERT 能有更好的效果。为此,我们随机从 OntoNotes 4.0 训练集中随机选择 10%~90% 的训练数据,并保持其中有实体的数据与无实体的数据的比例。
结果如下表所示。ChineseBERT 在小数据下的确具有更好的效果,尤其是当训练数据 >30% 时,ChineseBERT 的效果提升更加显著。这是因为,好的字形嵌入和拼音嵌入需要一定的训练数据才能习得,不充分的训练数据会使这二者不能得到充分训练。

小结
本文提出了 ChineseBERT,一种融合了中文字形与拼音信息的中文大规模预训练模型。使用汉字字形信息与拼音能够不但有助于汉字消歧,并且具有正则化作用,使模型更好建模潜在文本语义。在中文机器阅读理解等 6 个任务和十余个数据集上的实验表明,ChineseBERT 取得了显著的效果提升,并且在小数据集上也具有更好的表现。未来,我们将在更大的语料上训练 ChineseBERT。
ChineseBERT 的代码、模型均已开源,欢迎大家尝试。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!