深度学习之路(Pytorch搭建残差网络)
目录
引言
一、从概念上理解
1.怎么来的?
2.残差块
3.残差网络
二、从代码上理解
引言
我是刚刚学习深度学习的知识,想找一篇能够对于初学者很友好的残差网络的博客,发现很少,所以就自己写了这篇博客,记录自己的学习,也方便大家的学习,这是我的初衷。
一、从概念上理解
1.怎么来的?
首先,我们要知道残差网络是怎么来的。残差网络出现的目的是为解决随着网络层数的增加,网络发生退化的现象。这种现象就是:随着网络层数的增加,训练集loss逐渐下降,然后趋于饱和,当我们再增加网络的层数(深度)的话,训练集的loss 反而会增大。但是这并不是过拟合,因为在过拟合的表现是训练的loss一直减小,但是测试的效果缺不理想。
当出现上面这种问题的时候,我们想浅层网络能够达到比深层网络更好的训练结果,这时如果我们把低层的特征传递给高层,那么效果会不会应该至少不比浅层的网络效果差,这时我们就需要给低层和高层之间添加一条直接映射来达到此效果,这就是残差网络的由来。
2.残差块
在实际中,残差网络是由一个个残差块组成的,要想搞明白什么是残差网络,你就必须要先名明白什么是残差块。那么,一个残差块是什么?我们可以用下面和一个公式表达:
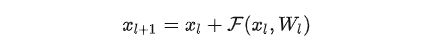
从公式中可以看出这一层的输出与两部分有关,如下图所示,图中左侧对应的部分就是残差公式等号右侧的第一部分,也称为直接映射部分,图中右侧对应部分就是残差公式等号右侧的第二部分,也称为残差部分。
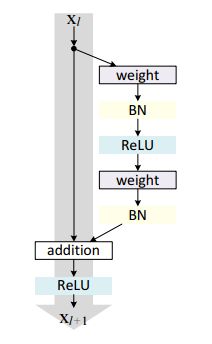
其中,weight在卷积网络中指的是卷积操作,addition是指单位加操作,BN是指归一化,ReLU是指激活函数。
由于在卷积网络中,前一层和下一层的特征数量不一样,这时候就需要卷积来进行升维或者降维。这时,残差块表示为:

注意:这里有一个细节,因为我们的残差网络是由一个个残差块组合起来,一般来说,我们在处理第一个残差块的时候,是不需要1X1卷积的。并且,我理解的1X1卷积是因情况而定,并不一定就是1X1的卷积核,只要能使直接映射部分和残差部分的维度一致就行。
此时,我们可以将残差公式变成:

我们可以自己理解,就是一个残差块是将输入数据分成两个分支,一个是用来做卷积运算,一个用来做残差运算,最后将两个运算结果加在一起。
3.残差网络
其实,你们看下面这一幅图就明白什么是残差网络。

二、从代码上理解
我们将用CIFAR10为数据集搭建下面这个网络:

先介绍一下这个网络,首先,要经过一个3X3的卷积网络,随后经过一个归一化,一个激活函数,紧接着进入到残差网络,这个网络是由三个残差块组成(具体的残差块可以看下图),在就进入平均池化,线性函数。
下面是三个残差块的内部:
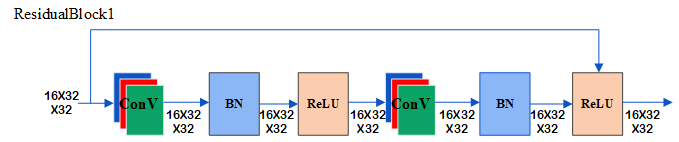


接下来我们我们可以看一下残差块的代码:
# 残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
# 卷积
self.conv1 = conv3x3(in_channels, out_channels, stride)
# 归一化
self.bn1 = nn.BatchNorm2d(out_channels)
# 激活函数
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
# 前行传播
def forward(self, x):
# 当我传进残差块中参数时,需要进行两次卷积,两次归一化,两次激活函数
# 但第一次和第二次的卷积、归一化、激活函数是不一样
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
下面是残差网络的搭建,我们里面有三个残差块,每个残差块内部都要经过两次卷积,但是每次卷积都要注意stride的数据量:
# ResNet模型
class ResNet(nn.Module):
# num_classes=10是因为我们的CIFAR10数据集是10分类的。
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)[2,2,2,2]
# self.layer1 = self.make_layer(block, 16, layers[0])
self.layer1 = self.make_layer(block, 16, layers)
# self.layer2 = self.make_layer(block, 32, layers[0], 2)
self.layer2 = self.make_layer(block, 32, layers, 2)
# self.layer3 = self.make_layer(block, 64, layers[1], 2)
self.layer3 = self.make_layer(block, 64, layers, 2)
self.avg_pool = nn.AvgPool2d(8)
# 输入特征64,变成输出特征10
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if(stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
# 初始化通道,为后续残差网络做准备
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
# 先3X3的卷积,其为3X32X32的大小
out = self.conv(x)
# 经过一个归一化
out = self.bn(out)
# 经过一个激活函数
out = self.relu(out)
# 经过第一个残差块,为30X16X32X32
out = self.layer1(out)
# 经过第二个残差块,为30X32X16X16
out = self.layer2(out)
# 经过第三个残差块,为30X64X8X8
out = self.layer3(out)
# 在经过一个平均池化,为30X64X1X1
out = self.avg_pool(out)
# 再经过一个变形,为30X64
out = out.view(out.size(0), -1)
# 最后经过一个Linear函数,将输入特征,变成10,为30X10
out = self.fc(out)
# print(out.size())
return out如果你理解了上面的代码,那么我将给你一个完整的代码,这是在GPU下运行的代码,如果你想要在CPU上运行,那么你需要进行更改模型、损失函数以及输入数据这三个参数,另其在CPU中运行:
import torch.optim
import torchvision
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
transform = transforms.Compose([
# 将图片转成40X40大小
transforms.Resize(40),
# 随机图片水平翻转
transforms.RandomHorizontalFlip(),
# 随机裁剪成32X32大小
transforms.RandomCrop(32),
# 将HWC转置为CHW格式
transforms.ToTensor()])
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=transform,
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=30, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=30, shuffle=False)
# 定义3X3的卷积
def conv3x3(in_channels, out_channles, stride=1):
return nn.Conv2d(in_channels, out_channles, kernel_size=3, stride=stride, padding=1, bias=False)
# 残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
# 卷积
self.conv1 = conv3x3(in_channels, out_channels, stride)
# 归一化
self.bn1 = nn.BatchNorm2d(out_channels)
# 激活函数
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
# 前行传播
def forward(self, x):
# 当我传进残差块中参数时,需要进行两次卷积,两次归一化,两次激活函数
# 但第一次和第二次的卷积、归一化、激活函数是不一样
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# ResNet模型
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers)
self.layer2 = self.make_layer(block, 32, layers, 2)
self.layer3 = self.make_layer(block, 64, layers, 2)
self.avg_pool = nn.AvgPool2d(8)
# 输入特征64,变成输出特征10
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if(stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
# 初始化通道,为后续残差网络做准备
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
# 先3X3的卷积,其为3X32X32的大小
out = self.conv(x)
# 经过一个归一化
out = self.bn(out)
# 经过一个激活函数
out = self.relu(out)
# 经过第一个残差块,为30X16X32X32
out = self.layer1(out)
# 经过第二个残差块,为30X32X16X16
out = self.layer2(out)
# 经过第三个残差块,为30X64X8X8
out = self.layer3(out)
# 在经过一个平均池化,为30X64X1X1
out = self.avg_pool(out)
# 再经过一个变形,为30X64
out = out.view(out.size(0), -1)
# 最后经过一个Linear函数,将输入特征,变成10,为30X10
out = self.fc(out)
# print(out.size())
return out
# 创建网络模型
resnet = ResNet(ResidualBlock, 2).cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.001
optimizer = torch.optim.Adam(resnet.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("--------第{} 轮训练开始---------".format(i + 1))
# 训练步骤开始
resnet.train() # 可有可没有
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
# 前向 + 后向 + 优化器
imgs = Variable(imgs)
# print(imgs)
targets = Variable(targets)
optimizer.zero_grad()
outputs = resnet(imgs)
loss = loss_fn(outputs, targets) # 损失函数
loss.backward() # 后向传播
# 优化器优化模型
optimizer.step()
total_train_step = total_train_step + 1
# .item()是将tensor数据类型变成一个真实的数字
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
# resnet.eval() # 可有可没有
total_test_loss = 0
total_accuracy = 0
# 让模型的梯度消除
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
imgs = Variable(imgs)
targets = Variable(targets)
outputs = resnet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
# 当我们进行分类问题的时候,我们就需要下面这一行代码,如果是目标检测或者自然语言处理的时候,就暂时不需要。
# argmax(1)指的是横向对比大小,返回最大值的下标
# argmax(0)指的是纵向对比大小,返回最大值的下标
# == 值的是输出概率结果与目标的结果是否一致,是返回True,否则返回False
# sum()是用来计算统计True的个数
# print(outputs)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(resnet.state_dict(), "ResNet_{}.pth".format(i + 1))
print("模型已保存")
writer.close()
参考:
1.详解残差网络
2.基于pytorch的残差网络实现
3.Pytorch学习笔记(六)