Spring-Batch读取数据 文本数据 数据库数据 XML数据 JSON数据
文章目录
-
- 1、框架搭建
- 2、简单数据读取
- 3、文本数据读取
- 4、数据库数据读取
- 5、XML数据读取
- 6、JSON数据读取
- 7、多文本数据读取
Spring Batch读取数据通过
ItemReader接口的实现类来完成,包括 FlatFileItemReader文本数据读取、 StaxEventItemReader XML文件数据读取、 JsonItemReader JSON文件数据读取、 JdbcPagingItemReader数据库分页数据读取等实现,更多可用的实现可以参考: https://docs.spring.io/spring-batch/docs/4.2.x/reference/html/appendix.html#itemReadersAppendix,本文只介绍这四种比较常用的读取数据方式。
1、框架搭建
新建一个Spring Boot项目,版本为2.5.9,artifactId为spring-batch-itemreader
剩下的数据库层的准备,项目配置,依赖引入和Spring Batch入门文章中的框架搭建步骤一致,这里就不再赘述。
2、简单数据读取
前面提到,Spring Batch读取数据是通过ItemReader接口的实现类来完成的,所以我们可以自定义一个ItemReader的实现类,实现简单数据的读取。
新建reader包,然后在该包下新建ItemReader接口的实现类MySimpleIteamReader:
public class MySimpleIteamReader implements ItemReader<String> {
private Iterator<String> iterator;
public MySimpleIteamReader(List<String> data) {
this.iterator = data.iterator();
}
@Override
public String read() {
// 数据一个接着一个读取
return iterator.hasNext() ? iterator.next() : null;
}
}
泛型指定读取数据的格式,这里读取的是String类型的List,read()方法的实现也很简单,就是遍历集合数据。
接着新建job包,然后在该包下新建MySimpleItemReaderDemo类,用于测试我们定义的MySimpleIteamReader,MySimpleItemReaderDemo类代码如下:
@Component
public class MySimpleItemReaderDemo {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job mySimpleItemReaderJob() {
return jobBuilderFactory.get("mySimpleItemReaderJob")
.start(step())
.build();
}
private Step step() {
return stepBuilderFactory.get("step")
.<String, String>chunk(2)
.reader(mySimpleItemReader())
.writer(list -> list.forEach(System.out::println)) // 简单输出,后面再详细介绍writer
.build();
}
private ItemReader<String> mySimpleItemReader() {
List<String> data = Arrays.asList("java", "c++", "javascript", "python");
return new MySimpleIteamReader(data);
}
}
上面代码中,我们通过mySimpleItemReader()方法创建了一个MySimpleIteamReader,并且传入了List数据。上面代码大体和上一节中介绍的差不多,最主要的区别就是Step的创建过程稍有不同。
在MySimpleItemReaderDemo类中,我们通过StepBuilderFactory创建步骤Step,不过不再是使用tasklet()方法创建,而是使用chunk()方法。chunk字面上的意思是“块”的意思,可以简单理解为数据块,泛型reader()方法指定读取数据的方式,该方法接收ItemReader的实现类,这里使用的是我们自定义的MySimpleIteamReader。writer()方法指定数据输出方式,因为这块不是本文的重点,所以先简单遍历输出即可。
启动项目,控制台日志打印如下:
3、文本数据读取
Spring Batch读取文本类型数据可以通过FlatFileItemReader实现,在演示怎么使用之前,我们先准备好数据文件。
在resources目录下新建file文件,内容如下:
// 演示文件数据读取
1,11,12,13
2,21,22,23
3,31,32,33
4,41,42,43
5,51,52,53
6,61,62,63
file的数据是一行一行以逗号分隔的数据(在批处理业务中,文本类型的数据文件一般都是有一定规律的)。在文本数据读取的过程中,我们需要将读取的数据转换为POJO对象存储,所以我们需要创建一个与之对应的POJO对象。在包下新建entity包,然后在该包下新建TestData类:
public class TestData {
private int id;
private String field1;
private String field2;
private String field3;
// get,set,toString略
}
因为file文本中的一行数据经过逗号分隔后为1、11、12、13,所以我们创建的与之对应的POJO TestData包含4个属性id、field1、field2和field3。
接着在job包下新建FileItemReaderDemo:
@Component
public class FileItemReaderDemo {
// 任务创建工厂
@Autowired
private JobBuilderFactory jobBuilderFactory;
// 步骤创建工厂
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job fileItemReaderJob() {
return jobBuilderFactory.get("fileItemReaderJob")
.start(step())
.build();
}
private Step step() {
return stepBuilderFactory.get("step")
.<TestData, TestData>chunk(2)
.reader(fileItemReader())
.writer(list -> list.forEach(System.out::println))
.build();
}
private ItemReader<TestData> fileItemReader() {
FlatFileItemReader<TestData> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("file")); // 设置文件资源地址
reader.setLinesToSkip(1); // 忽略第一行
// AbstractLineTokenizer的三个实现类之一,以固定分隔符处理行数据读取,
// 使用默认构造器的时候,使用逗号作为分隔符,也可以通过有参构造器来指定分隔符
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
// 设置属性名,类似于表头
tokenizer.setNames("id", "field1", "field2", "field3");
// 将每行数据转换为TestData对象
DefaultLineMapper<TestData> mapper = new DefaultLineMapper<>();
// 设置LineTokenizer
mapper.setLineTokenizer(tokenizer);
// 设置映射方式,即读取到的文本怎么转换为对应的POJO
mapper.setFieldSetMapper(fieldSet -> {
TestData data = new TestData();
data.setId(fieldSet.readInt("id"));
data.setField1(fieldSet.readString("field1"));
data.setField2(fieldSet.readString("field2"));
data.setField3(fieldSet.readString("field3"));
return data;
});
reader.setLineMapper(mapper);
return reader;
}
}
上面代码中,我们在fileItemReader()方法里编写了具体的文本数据读取代码,过程参考注释即可。DelimitedLineTokenizer分隔符行处理器的默认构造器源码如下所示:
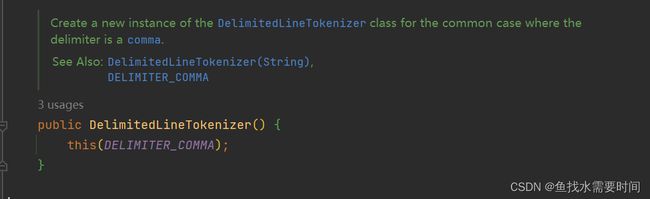
常量DELIMITER_COMMA的值为public static final String DELIMITER_COMMA = ",";,假如我们的数据并不是用逗号分隔,而是用|等字符分隔的话,可以使用它的有参构造器指定:
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer("|");
DelimitedLineTokenizer是AbstractLineTokenizer三个实现类之一:
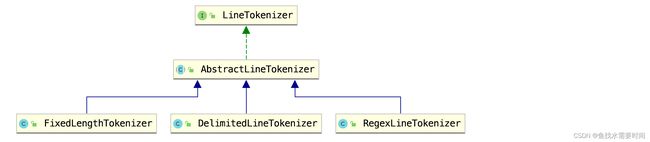
顾名思义,FixedLengthTokenizer通过指定的固定长度来截取数据,RegexLineTokenizer通过正则表达式来匹配数据,这里就不演示了,有兴趣的可以自己玩玩。
编写好FileItemReaderDemo后,启动项目,控制台日志打印如下:

4、数据库数据读取
在演示从数据库中读取数据之前,我们先准备好测试数据。在springbatch数据库中新建一张TEST表,SQL语句如下所示:
-- ----------------------------
-- Table structure for TEST
-- ----------------------------
DROP TABLE IF EXISTS `TEST`;
CREATE TABLE `TEST` (
`id` bigint(10) NOT NULL COMMENT 'ID',
`field1` varchar(10) NOT NULL COMMENT '字段一',
`field2` varchar(10) NOT NULL COMMENT '字段二',
`field3` varchar(10) NOT NULL COMMENT '字段三',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of TEST
-- ----------------------------
BEGIN;
INSERT INTO `TEST` VALUES (1, '11', '12', '13');
INSERT INTO `TEST` VALUES (2, '21', '22', '23');
INSERT INTO `TEST` VALUES (3, '31', '32', '33');
INSERT INTO `TEST` VALUES (4, '41', '42', '43');
INSERT INTO `TEST` VALUES (5, '51', '52', '53');
INSERT INTO `TEST` VALUES (6, '61', '62', '63');
COMMIT;
TEST表的字段和上面创建的TestData实体类一致。
然后在job包下新建DataSourceItemReaderDemo类,测试从数据库中读取数据:
@Component
public class DataSourceItemReaderDemo {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
// 注入数据源
@Autowired
private DataSource dataSource;
@Bean
public Job dataSourceItemReaderJob() throws Exception {
return jobBuilderFactory.get("dataSourceItemReaderJob")
.start(step())
.build();
}
private Step step() throws Exception {
return stepBuilderFactory.get("step")
.<TestData, TestData>chunk(2)
.reader(dataSourceItemReader())
.writer(list -> list.forEach(System.out::println))
.build();
}
private ItemReader<TestData> dataSourceItemReader() throws Exception {
JdbcPagingItemReader<TestData> reader = new JdbcPagingItemReader<>();
reader.setDataSource(dataSource); // 设置数据源
reader.setFetchSize(5); // 每次取多少条记录
reader.setPageSize(5); // 设置每页数据量
// 指定sql查询语句 select id,field1,field2,field3 from TEST
MySqlPagingQueryProvider provider = new MySqlPagingQueryProvider();
provider.setSelectClause("id,field1,field2,field3"); //设置查询字段
provider.setFromClause("from TEST"); // 设置从哪张表查询
// 将读取到的数据转换为TestData对象
reader.setRowMapper((resultSet, rowNum) -> {
TestData data = new TestData();
data.setId(resultSet.getInt(1));
data.setField1(resultSet.getString(2)); // 读取第一个字段,类型为String
data.setField2(resultSet.getString(3));
data.setField3(resultSet.getString(4));
return data;
});
Map<String, Order> sort = new HashMap<>(1);
sort.put("id", Order.ASCENDING);
provider.setSortKeys(sort); // 设置排序,通过id 升序
reader.setQueryProvider(provider);
// 设置namedParameterJdbcTemplate等属性
reader.afterPropertiesSet();
return reader;
}
}
dataSourceItemReader()方法中的主要步骤就是:通过JdbcPagingItemReader设置对应的数据源,然后设置数据量、获取数据的sql语句、排序规则和查询结果与POJO的映射规则等。方法末尾之所以需要调用JdbcPagingItemReader的afterPropertiesSet()方法是因为需要设置JDBC模板
(afterPropertiesSet()方法源码):
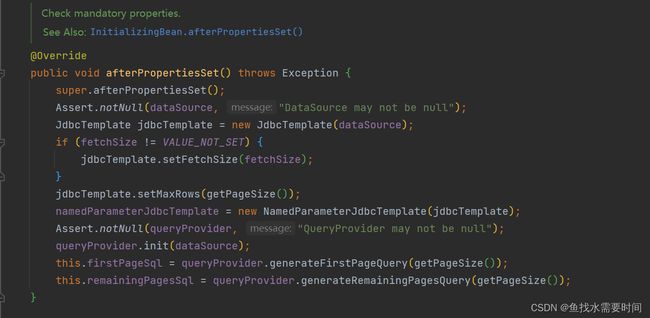
启动项目,控制台日志打印如下:

5、XML数据读取
Spring Batch借助Spring OXM可以轻松地实现xml格式数据文件读取。在resources目录下新建file.xml,内容如下所示:
<tests>
<test>
<id>1id>
<field1>11field1>
<field2>12field2>
<field3>13field3>
test>
<test>
<id>2id>
<field1>21field1>
<field2>22field2>
<field3>23field3>
test>
<test>
<id>3id>
<field1>31field1>
<field2>32field2>
<field3>33field3>
test>
<test>
<id>4id>
<field1>41field1>
<field2>42field2>
<field3>43field3>
test>
<test>
<id>5id>
<field1>51field1>
<field2>52field2>
<field3>53field3>
test>
<test>
<id>6id>
<field1>61field1>
<field2>62field2>
<field3>63field3>
test>
tests>
xml文件内容由一组一组的TestData实体类属性一一对应。
准备好xml文件后,在pom中引入spring-oxm依赖:
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-oxmartifactId>
dependency>
<dependency>
<groupId>com.thoughtworks.xstreamgroupId>
<artifactId>xstreamartifactId>
<version>1.4.11.1version>
dependency>
接着在job包下新建XmlFileItemReaderDemo,演示xml文件数据获取:
@Component
public class XmlFileItemReaderDemo {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job xmlFileItemReaderJob() {
return jobBuilderFactory.get("xmlFileItemReaderJob")
.start(step())
.build();
}
private Step step() {
return stepBuilderFactory.get("step")
.<TestData, TestData>chunk(2)
.reader(xmlFileItemReader())
.writer(list -> list.forEach(System.out::println))
.build();
}
private ItemReader<TestData> xmlFileItemReader() {
StaxEventItemReader<TestData> reader = new StaxEventItemReader<>();
reader.setResource(new ClassPathResource("file.xml")); // 设置xml文件源
reader.setFragmentRootElementName("test"); // 指定xml文件的根标签
// 将xml数据转换为TestData对象
XStreamMarshaller marshaller = new XStreamMarshaller();
// 指定需要转换的目标数据类型
Map<String, Class<TestData>> map = new HashMap<>(1);
map.put("test", TestData.class);
marshaller.setAliases(map);
reader.setUnmarshaller(marshaller);
return reader;
}
}
在xmlFileItemReader()方法中,我们通过StaxEventItemReader读取xml文件,代码较简单,看注释即可。
6、JSON数据读取
在resources目录下新建file.json文件,内容如下:
[
{
"id": 1,
"field1": "11",
"field2": "12",
"field3": "13"
},
{
"id": 2,
"field1": "21",
"field2": "22",
"field3": "23"
},
{
"id": 3,
"field1": "31",
"field2": "32",
"field3": "33"
}
]
JSON对象属性和TestData对象属性一一对应。在job包下新建JSONFileItemReaderDemo,用于测试JSON文件数据读取:
@Component
public class JSONFileItemReaderDemo {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job jsonFileItemReaderJob() {
return jobBuilderFactory.get("jsonFileItemReaderJob")
.start(step())
.build();
}
private Step step() {
return stepBuilderFactory.get("step")
.<TestData, TestData>chunk(2)
.reader(jsonItemReader())
.writer(list -> list.forEach(System.out::println))
.build();
}
private ItemReader<TestData> jsonItemReader() {
// 设置json文件地址
ClassPathResource resource = new ClassPathResource("file.json");
// 设置json文件转换的目标对象类型
JacksonJsonObjectReader<TestData> jacksonJsonObjectReader = new JacksonJsonObjectReader<>(TestData.class);
JsonItemReader<TestData> reader = new JsonItemReader<>(resource, jacksonJsonObjectReader);
// 给reader设置一个别名
reader.setName("testDataJsonItemReader");
return reader;
}
}
7、多文本数据读取
多文本的数据读取本质还是单文件数据读取,区别就是多文件读取需要在单文件读取的方式上设置一层代理。
在resources目录下新建两个文件file1和file2,file1内容如下所示:
// 演示文件数据读取
1,11,12,13
2,21,22,23
3,31,32,33
4,41,42,43
5,51,52,53
6,61,62,63
file2内容如下所示:
// 演示文件数据读取
7,71,72,73
8,81,82,83
然后在job包下新建MultiFileIteamReaderDemo,演示多文件数据读取:
@Component
public class MultiFileIteamReaderDemo {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job multiFileItemReaderJob() {
return jobBuilderFactory.get("multiFileItemReaderJob")
.start(step())
.build();
}
private Step step() {
return stepBuilderFactory.get("step")
.<TestData, TestData>chunk(2)
.reader(multiFileItemReader())
.writer(list -> list.forEach(System.out::println))
.build();
}
private ItemReader<TestData> multiFileItemReader() {
MultiResourceItemReader<TestData> reader = new MultiResourceItemReader<>();
reader.setDelegate(fileItemReader()); // 设置文件读取代理,方法可以使用前面文件读取中的例子
Resource[] resources = new Resource[]{
new ClassPathResource("file1"),
new ClassPathResource("file2")
};
reader.setResources(resources); // 设置多文件源
return reader;
}
private FlatFileItemReader<TestData> fileItemReader() {
FlatFileItemReader<TestData> reader = new FlatFileItemReader<>();
reader.setLinesToSkip(1); // 忽略第一行
// AbstractLineTokenizer的三个实现类之一,以固定分隔符处理行数据读取,
// 使用默认构造器的时候,使用逗号作为分隔符,也可以通过有参构造器来指定分隔符
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
// 设置属姓名,类似于表头
tokenizer.setNames("id", "field1", "field2", "field3");
// 将每行数据转换为TestData对象
DefaultLineMapper<TestData> mapper = new DefaultLineMapper<>();
mapper.setLineTokenizer(tokenizer);
// 设置映射方式
mapper.setFieldSetMapper(fieldSet -> {
TestData data = new TestData();
data.setId(fieldSet.readInt("id"));
data.setField1(fieldSet.readString("field1"));
data.setField2(fieldSet.readString("field2"));
data.setField3(fieldSet.readString("field3"));
return data;
});
reader.setLineMapper(mapper);
return reader;
}
}
上面代码中fileItemReader()方法在文本数据读取中介绍过了,多文件读取的关键在于multiFileItemReader()方法,该方法通过MultiResourceItemReader对象设置了多个文件的目标地址,并且将单文件的读取方式设置为代理。
启动项目,控制台日志打印如下:
文章出处
到此,本章内容就介绍完啦,如果有帮助到你 欢迎点个赞吧!!您的鼓励是博主的最大动力! 有问题评论区交流。