TrDiMP / TrSiam 代码阅读记录 (推理过程) ,以及 pytracking 框架的一些接口
目录
前言、DiMP的一些基础
1、网络结构
一、debug记录
1、args
2、Tracker
3、env
4、tracker_module
5、checkpoint_dict
6、net_constr
7、net_fun_args
8、info
9、init_info_split
10、init_backbone_feat
11、self
12、self
13、pred_module
14、target_center
15、self.layers
16、self
17、self.sample_weights
18、self.training_samples
19、self
20、max2d 中的参数打印
二、功能接口处
1、定义tracker
2、导入local.py 中本地路径设置的内容处
3、传入的参数 tracker_name tracker_parameters 作用的地方
4、超参数设置的地方
5、加载预训练的模型
6、数据增强操作,得到 model 的输入 (没错,前向推理也用了数据增强)
7、对模板的处理过程
1)、骨干网络特征提取
2)输入到 transformer
3)IouNet的过程
8、Gauss mask 的设置
三、一些需要注意的地方
1、训练模型的 命名
2、前向推理过程,但是对模板特征进行提取前进行了数据增强操作,并且保留了所有增强后的效果。
四、 transformer 过程记录
1、encoder过程
2、decoder过程
五、Model predicter 过程
1、model initializer
2、model optimizer
六、 初始化 IoUNet
七、开始跟踪 track
1、对frame 的处理
2、进行骨干网络的特征提取
3、 提取 classification features
4、进行 transformer decoder
5、计算分类得分
6、定位目标
7、更新坐标原点
8、进行IoUNet
9、得到最终的预测 的 bbox
10、更新classifier model
八、大致流程的记录
九、网络结构
前言、DiMP的一些基础
推荐去看这篇大佬的博客以及它的哔哩哔哩讲解。( •̀ ω •́ )y
与ATOM 的方法很接近,这两篇可以一起看
1、网络结构

训练时,样本对儿不在是一对儿图片,而是 模板是一个样本集合(原文3张图片),测试图片是一个图片;

这一部分算是一种 特征 fusion形式,跟siamese很像,做卷积。

主要是这个部分做了一些文章。Model Optimizer 会进行迭代优化。
可学习的标签

目的让 负样本的区域为0


在配置 是 TrDimp 还是 TrSiam 时改变的之不过是特征的混合方式。
一、debug记录
1、args

2、Tracker

3、env

4、tracker_module
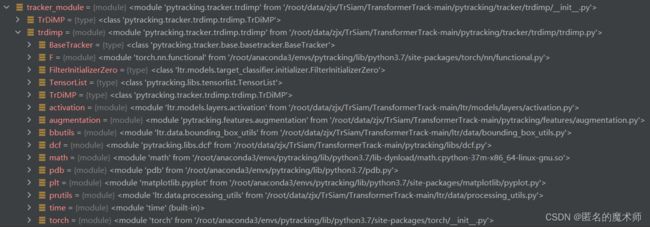
5、checkpoint_dict

6、net_constr
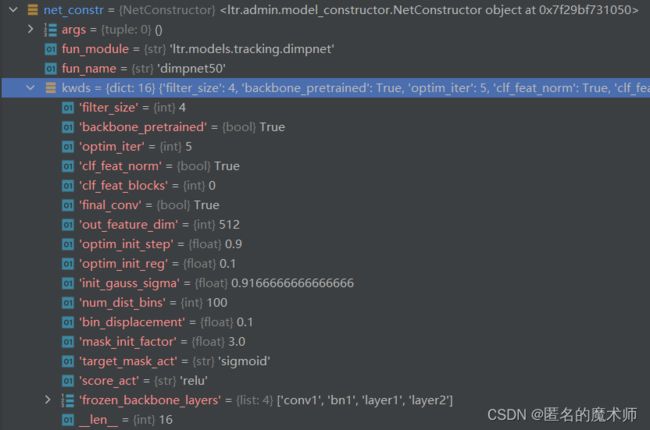
7、net_fun_args

8、info

9、init_info_split

10、init_backbone_feat
![]()
11、self

12、self
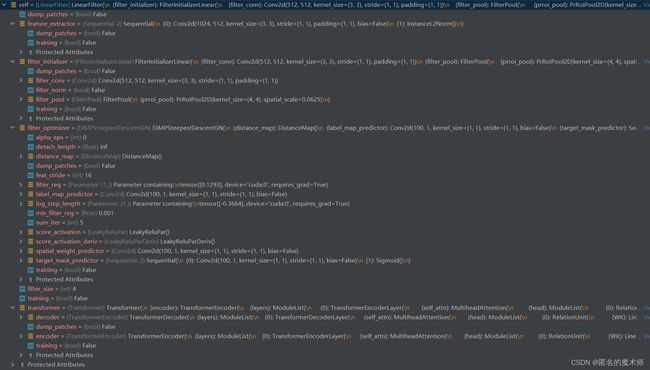
13、pred_module

14、target_center

15、self.layers
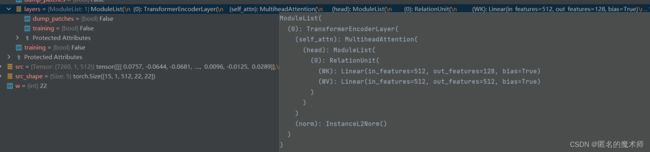
16、self

17、self.sample_weights
![]()
18、self.training_samples
![]()
19、self

20、max2d 中的参数打印

二、功能接口处
1、定义tracker
run_video.py -----19
tracker = Tracker(tracker_name, tracker_param)跳转后,最主要的建立模型的地方在
tracker.py --- 64
tracker_module = importlib.import_module('pytracking.tracker.{}'.format(self.name))
self.tracker_class = tracker_module.get_tracker_class()这个 tracker_class 属性是model(注意,现在的self.tracker_class 的属性不是object,也就是还没有通过TrDiMP类实例化对象), 是通过其所在的项目文件夹下的 pytracking/tracker/trdimp/ __init__.py 返回的
from .trdimp import TrDiMP
def get_tracker_class():
return TrDiMP而且,这个 TrDiMP 类 继承的是 BaseTracker 父类,其在 pytracking/tracker/base/basetracker.py 中,这个就是这个框架 和 模型 对接的接口。
但这也只是 定义了 网络模型, 完全的前向推理过程的tracker 最终定义在 tracker.py ---255
tracker = MultiObjectWrapper(self.tracker_class, params, self.visdom, fast_load=True)2、导入local.py 中本地路径设置的内容处
track.py --- 54
env = env_settings()动态的导入 pytracking/evaluation/local.py 文件中设置的内容,也就是本地环境的路径
3、传入的参数 tracker_name tracker_parameters 作用的地方
tracker.py --- 652
param_module = importlib.import_module('pytracking.parameter.{}.{}'.format(self.name, self.parameter_name))4、超参数设置的地方
tracker.py --- 653
params = param_module.parameters()这些参数的设置都是跟 上面3中传入的参数 有关的。根据传入的参数确定路径,到相应的文件中执
行 parameters 函数。如 trsiam.py 中的那样,如下所示。
def parameters():
params = TrackerParams()
params.debug = 0 # TrackerParams() 类中没有设置初始属性, 这是在主动添加属性
params.visualization = False
params.use_gpu = True
params.image_sample_size = 22*16
params.search_area_scale = 6
params.border_mode = 'inside_major'
params.patch_max_scale_change = 1.5所以,这些文件的主要作用就是设置各个方法的超参数。
5、加载预训练的模型
首先,网络结构的加载被 包含在 上面4中 的超参数加载中,设置超参数的入口为 tracke.py ---236
params = self.get_parameters()然后通过动态导入模块,调用了 pytracking/parameter/trdimp/trsiam.py 中的 parameters 类,其中,在该文件中 trsiam.py --- 70
params.net = NetWithBackbone(net_path='trdimp_net.pth.tar', use_gpu=params.use_gpu)这个类在 pytacking/features/net_wrappers.py 中,其继承了 NetWrapper 父类。在定义 tracker的同时, params 做为参数传入进去
tracker = MultiObjectWrapper(self.tracker_class, params, self.visdom, fast_load=True)当执行 pytracking/evaluation/multi_object_wrapper.py ---18 时
self.tracker_copy = self.base_tracker_class(self.params)self.tracker_copy 就是实例化的 TrDiMP 对象,当继续执行
self.tracker_copy.initialize_features()跳转到 TrDiMP 类中
def initialize_features(self):
if not getattr(self, 'features_initialized', False):
self.params.net.initialize()其中 self.params 在 父类 BaseTracker 中初始化,为 params对象,其中的 net 属性就是NetWithBackbone 类的实例化对象。所以当执行
self.params.net.initialize()时,就会跳转到 NetWithBackbone 类中的
def initialize(self, image_format='rgb', mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
super().initialize()其继承了父类 NetWrapper,继续执行父类中的 initialize 方法
def initialize(self):
self.load_network()到这,就是 加载权重参数的地方 pytracking/features/net_wrappers.py --- 31
self.net = load_network(self.net_path, **self.net_kwargs)并且,在 pytracking/utils/loading.py --- 30 中也体现了路径设置相关的地方
path_full = os.path.join(env_settings().network_path, net_path)6、数据增强操作,得到 model 的输入 (没错,前向推理也用了数据增强)
trdimp.py --- 417
im_patches = sample_patch_transformed(im, self.init_sample_pos, self.init_sample_scale, aug_expansion_sz, self.transforms)这里调用了 pytracking 的接口 sample_patch_transformed ,并且这里返回的 im_patches的shape 为 举例 Tensor:(13,3,352,352) ,第一维不是1,这是因为
im_patches = torch.cat([T(im_patch, is_mask=is_mask) for T in transforms]) 对模板图片进行了 数据增强操作 ,并 拼接在一起。
7、对模板的处理过程
1)、骨干网络特征提取
trdimp --- 86
init_backbone_feat = self.generate_init_samples(im)这一步包括了上面 6中的数据增强操作 ,之后对其进行归一化处理满足正态分布, 然后再进行骨干网络特征提取。
trdimp --- 421
init_backbone_feat = self.net.extract_backbone(im_patches)跳转到 pytrcking/features/net_wrappers.py --- 71
def extract_backbone(self, im: torch.Tensor):
"""Extract backbone features from the network.
Expects a float tensor image with pixel range [0, 255]."""
im = self.preprocess_image(im) # 对 im 进进行归一化
return self.net.extract_backbone_features(im)当执行 return 时,会跳转到 ltr/models/tracking/dimpnet.py 中 ,这个属于自己项目建立的文件。
然后执行
def extract_backbone_features(self, im, layers=None):
if layers is None:
layers = self.output_layers
return self.feature_extractor(im, layers)这里的骨干网络采用的是 ResNet
2)输入到 transformer
trdimp.py --- 89
self.init_classifier(init_backbone_feat)encoder 过程 trdimp --- 605
self.transformer_memory, _ = self.net.classifier.transformer.encoder(self.x_clf.unsqueeze(1), pos=None)最终实现是在 ltr/models/target_classifier/transformer.py --- 69
decoder 过程 trdimp --- 608
_, cur_encoded_feat = self.net.classifier.transformer.decoder(x[i,...].unsqueeze(0).unsqueeze(0), memory=self.transformer_memory, pos=self.transformer_label, query_pos=None)它们都定义在 ltr/models/target_classifier/transformer.py 中
3)IouNet的过程
8、Gauss mask 的设置
trdimp.py --- 598
self.transformer_label = prutils.gaussian_label_function(target_boxes.cpu().view(-1, 4), 0.1, self.net.classifier.filter_size,
self.feature_sz, self.img_sample_sz, end_pad_if_even=False)得到的mask数与模板图片进行数据增强后的数量一致, 其中的一个mask举例如下图所示。

三、一些需要注意的地方
1、训练模型的 命名
它默认设置的是 trdimp_net.pth.par
params.net = NetWithBackbone(net_path='trdimp_net.pth.tar', use_gpu=params.use_gpu)所以要是 预训练模型改名了的话,这里也要做相应改变。(举例trsiam.py --- 70,以此类推)
2、前向推理过程,但是对模板特征进行提取前进行了数据增强操作,并且保留了所有增强后的效果。
没错,不是在训练过程,而仅仅是在前向的推理过程,就对模板样本进行了数据增强,然后按第一维度拼接在了一起。
im_patches = sample_patch_transformed(im, self.init_sample_pos, self.init_sample_scale, aug_expansion_sz, self.transforms)
im_patch, _ = sample_patch(im, pos, scale*image_sz, image_sz, is_mask=is_mask)
im_patches = torch.cat([T(im_patch, is_mask=is_mask) for T in transforms]) 然后会对其进行归一化操作,先进行骨干网络特征提取。 这个应该是 DiMp论文中的方法。
四、 transformer 过程记录
1、encoder过程
def forward(self, src, input_shape, pos: Optional[Tensor] = None):
# query = key = value = src
query = src
key = src
value = src
# self-attention
src2 = self.self_attn(query=query, key=key, value=value)
src = src + src2
src = self.instance_norm(src, input_shape)
return src其中 src的shape为 (7260,1,512) <--- (-1, batch, dim),由 torch.Size([15,1,512,22,22]) reshape得到。且这里的 q,k,v 都是同一个值,然后进行attention,再进行残差相加, 最后 norm一下得到输出。得到的输出shape与输入shape一样,都为 (7260,1,512)。但这之后又对其进行了reshape,如下所示
output_feat = output.reshape(num_imgs, h, w, batch, dim).permute(0,3,4,1,2) # 举例: Tensor:(15,1,512,22,22)
output_feat = output_feat.reshape(-1, dim, h, w) # 举例: Tensor:(15,512,22,22)
return output, output_feat但是 encoder 只保留了 output,而不是output_feat,如下所示
self.transformer_memory, _ = self.net.classifier.transformer.encoder(self.x_clf.unsqueeze(1), pos=None)2、decoder过程
for i in range(x.shape[0]): # 举例: x={Tensor:(15,512,22,22)}, x.shape[0]=15
_, cur_encoded_feat = self.net.classifier.transformer.decoder(x[i,...].unsqueeze(0).unsqueeze(0), memory=self.transformer_memory, pos=self.transformer_label, query_pos=None) # 举例: cur_encoder_feat={Tensor:(1,512,22,22)}
if i == 0:
encoded_feat = cur_encoded_feat
else:
encoded_feat = torch.cat((encoded_feat, cur_encoded_feat), 0)
x = encoded_feat.contiguous() # 举例: x={Tensor:(15,512,22,22)}上面说明 是按照 x的第一维也就是数据增强后的每一个特征分别进行 decoder的,这里传进的参数注意一下,包括x,encoder的输出,还有mask
def forward(self, tgt, memory, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): # 举例: tgt={Tensor:(1,1,512,22,22)}, memory={Tensor:(7260,1,512)},pos={Tensor:(15,1,22,22)}, query_pos:None
assert tgt.dim() == 5, 'Expect 5 dimensional inputs'
tgt_shape = tgt.shape # 举例: torch.Szie([1,1,512,22,22])
num_imgs, batch, dim, h, w = tgt.shape
if pos is not None: # True
num_pos, batch, h, w = pos.shape # 15,1,22,22
pos = pos.view(num_pos, batch, 1, -1).permute(0,3,1,2) # 举例: Tensor:(15,484,1,1)
pos = pos.reshape(-1, batch, 1) # 举例: Tensor:(7260,1,1)
pos = pos.repeat(1, 1, dim) # 举例 : Tensor:(7260,1,512)
tgt = tgt.view(num_imgs, batch, dim, -1).permute(0,3,1,2) # 举例: Tensor:(1,484,1,512)
tgt = tgt.reshape(-1, batch, dim) # 举例: Tensor:(484,1,512)
output = tgt
for layer in self.layers:
output = layer(output, memory, input_shape=tgt_shape, pos=pos, query_pos=query_pos)
# [L,B,D] -> [B,D,L]
output_feat = output.reshape(num_imgs, h, w, batch, dim).permute(0,3,4,1,2) # 举例: Tensor:(1,1,512,22,22)
output_feat = output_feat.reshape(-1, dim, h, w) # 举例: Tensor:(1,512,22,22)
# output = self.post2(self.activation(self.post1(output)))
return output, output_feat上面事先进行了形状的变化,在输入decoder之前同变成了 (-1,batch,dim)的形式,然后最终的输出保留了后者,也就是output_feat ,它跟output只是shape不一样
def forward(self, tgt, memory, input_shape, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None):
# self-attention
query = tgt
key = tgt
value = tgt
tgt2 = self.self_attn(query=query, key=key, value=value)
tgt = tgt + tgt2
tgt = self.instance_norm(tgt, input_shape)
mask = self.cross_attn(query=tgt, key=memory, value=pos)
tgt2 = tgt * mask
tgt2 = self.instance_norm(tgt2, input_shape)
tgt3 = self.cross_attn(query=tgt, key=memory, value=memory*pos)
tgt4 = tgt + tgt3
tgt4 = self.instance_norm(tgt4, input_shape)
tgt = tgt2 + tgt4
tgt = self.instance_norm(tgt, input_shape)
return tgt上面就是decoder主要的流程,其中的mask是论文中新提出来的方法,其它的都没有改变什么。
五、Model predicter 过程
入口 trdimp.py --- 616
with torch.no_grad():
self.target_filter, _, losses = self.net.classifier.get_filter(x, target_boxes, num_iter=num_iter,
compute_losses=plot_loss)跳转到 ltr/models/target_classifier/linear_filter.py --- 114
1、model initializer
weights = self.filter_initializer(feat, bb)注意传入的参数,其中 feat为decoder 的输出,bb为 target bbox 的坐标
其中, self.filter_initializer 如下所示
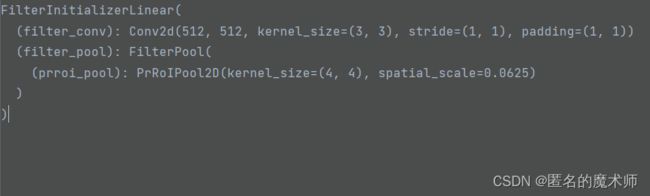
对应于论文中的结构如下
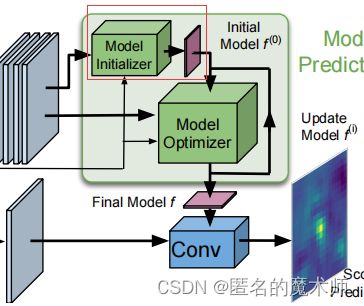
从代码中的内容可以看出,它先经过了一个卷积层,然后进行了RoIPooling ,得到了 初始化的模型 ![]() ,对应论文中的
,对应论文中的

它的输出为 举例:Tensor:(1,512,4,4),为 weights权重
2、model optimizer
代码中同样,紧接上一步
if self.filter_optimizer is not None:
weights, weights_iter, losses = self.filter_optimizer(weights, feat=feat, bb=bb, *args, **kwargs)注意 输入 为: weights 是 经过model initializer 得到的 filter 的权重, feat 为 decoder 的输出,bb 为 target 的bbox,它们的形状在 forward 中有说明。
其中 self.filter_optimizer 的内容为
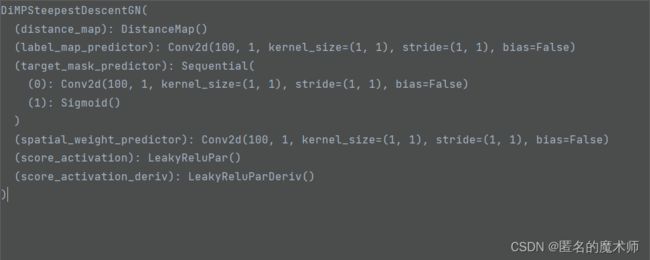
跳转到 ltr/models/target_classifier/optimizer.py --- 101
注意,当 运行 模板帧 的时候, 其中的 参数 num_iter =0, compute_losses 为 False,也就是说初始化模板的时候不进行迭代最优化。而且这里面的变量都是可学习的, 为 tensor 型。
经过一些设置之后,首先会 计算 dist_map,这里截取了其中的一部分如下所示(随着第二维通道数的增加依次排序)

最终的输出 shape 为 Tensor:(15,100,23,23),然后通过它去计算 各种标签,label map、label masks、 label weight
其中 ,self.label_map_predictor
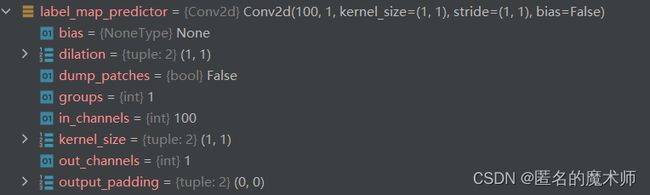
self.target_mask_predictor、

和 self.spatial_weight_predictor
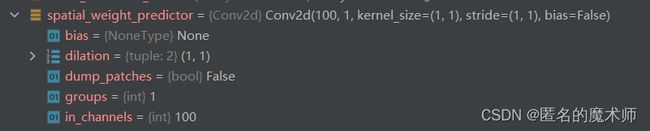
可以看出,它们都是一个卷积模块,且输入通道为100,输出通道为1 的1x1 卷积,下面截取了两张输入的label

可以看到它们分别都学习到了一定的分布。
接下来注意
weight_iterates = [weights]
losses = []
weight_iterates.append(weights)
return weights, weight_iterates, losses且当前是 模板帧的 初始化,并没有做优化,返回的 losses 是空的。
到此,优化器步骤结束,可以看出 初始化模板帧时并没有进行 优化器的迭代。
六、 初始化 IoUNet
入口在 trdimp --- 92
if self.params.get('use_iou_net', True):
self.init_iou_net(init_backbone_feat)IoUNet的网络结构如下所示
AtomIoUNet(
(conv3_1r): Sequential(
(0): Conv2d(512, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_1t): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_2t): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(prroi_pool3r): PrRoIPool2D(kernel_size=(3, 3), spatial_scale=0.125)
(prroi_pool3t): PrRoIPool2D(kernel_size=(5, 5), spatial_scale=0.125)
(fc3_1r): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_1r): Sequential(
(0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_1t): Sequential(
(0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_2t): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(prroi_pool4r): PrRoIPool2D(kernel_size=(1, 1), spatial_scale=0.0625)
(prroi_pool4t): PrRoIPool2D(kernel_size=(3, 3), spatial_scale=0.0625)
(fc34_3r): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(fc34_4r): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(fc3_rt): LinearBlock(
(linear): Linear(in_features=6400, out_features=256, bias=True)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(fc4_rt): LinearBlock(
(linear): Linear(in_features=2304, out_features=256, bias=True)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(iou_predictor): Linear(in_features=512, out_features=1, bias=True)
)它的输入是 init_backbone_feat,也就是骨干网络提取的特征。
当进行到 Get iou features 时,它最终调用的是 ltr/models/tracking/dimpnet.py --- 85
def get_backbone_bbreg_feat(self, backbone_feat):
return [backbone_feat[l] for l in self.bb_regressor_layer]其中 self.bb_regressor_layer 中的内容为

所以这一步的主要作用就是获取 backbone_feat 中的这两层特征。
接下来运行到
self.iou_modulation = self.get_iou_modulation(iou_backbone_feat, target_boxes)此时它的输入 为 骨干特征中的layer2、layer3, 和 target_boxes(此时的也就是输入之前的shape为 Tensor:(1,4) )
执行
def get_iou_modulation(self, iou_backbone_feat, target_boxes):
with torch.no_grad():
return self.net.bb_regressor.get_modulation(iou_backbone_feat, target_boxes)会跳转到 ltr/models/bbreg/atom_iou_net.py --- 138 也就是 AtomIoUNet 类中
def get_modulation(self, feat, bb): # feat {list:2} bb {Tensor:(1,4)}
"""Get modulation vectors for the targets.
args:
feat: Backbone features from reference images. Dims (batch, feature_dim, H, W).
bb: Target boxes (x,y,w,h) in image coords in the reference samples. Dims (batch, 4)."""
feat3_r, feat4_r = feat # Tensor:(1,512,44,44) Tensor:(1,1024,22,22)
c3_r = self.conv3_1r(feat3_r) # Tensor:(1,128,44,44)
# Add batch_index to rois
batch_size = bb.shape[0] # 1
batch_index = torch.arange(batch_size, dtype=torch.float32).reshape(-1, 1).to(bb.device) # tensor([[0.]],device='cuda:0')
# input bb is in format xywh, convert it to x0y0x1y1 format
bb = bb.clone()
bb[:, 2:4] = bb[:, 0:2] + bb[:, 2:4] # 右下角顶点
roi1 = torch.cat((batch_index, bb), dim=1) # Tensor:(1,5)
roi3r = self.prroi_pool3r(c3_r, roi1) # Tensor:(1,128,3,3)
c4_r = self.conv4_1r(feat4_r) # Tensor:(1,256,22,22)
roi4r = self.prroi_pool4r(c4_r, roi1) # Tensor:(1,256,1,1)
fc3_r = self.fc3_1r(roi3r) # Tensor:(1,256,1,1)
# Concatenate from block 3 and 4
fc34_r = torch.cat((fc3_r, roi4r), dim=1) # Tensor:(1,512,1,1)
fc34_3_r = self.fc34_3r(fc34_r) # Tensor:(1,256,1,1)
fc34_4_r = self.fc34_4r(fc34_r) # Tensor:(1,256,1,1)
return fc34_3_r, fc34_4_r可以看到 这个过程包含了上面列出的 IoUNet 网络结构中的所有层的操作,也包含Pooling操作。
至此,初始化过程结束。
七、开始跟踪 track
输入的是下一帧图片,frame
入口 pytrcking/evaluation/tracker.py --- 310
out = tracker.track(frame)跳转后, multi_object_wrapper.py --- 148 会有
out = self.trackers[obj_id].track(image, info)继续跳转到 trdimp.py --- 99
1、对frame 的处理
trdimp.py --- 334
im_patches, patch_coords = sample_patch_multiscale(im, pos, scales, sz,
mode=self.params.get('border_mode', 'replicate'),
max_scale_change=self.params.get('patch_max_scale_change', None))得到的 是 crop 后的img,以及相对于原来的原点 的裁剪图片的坐标(左上角顶点,右下角顶点)
举例:
patch_coords tensor([-123,-43,604,684])
在这之后会有对其的处理,计算出它的中心位置
def get_sample_location(self, sample_coord):
"""Get the location of the extracted sample."""
sample_coord = sample_coord.float()
sample_pos = 0.5*(sample_coord[:,:2] + sample_coord[:,2:] - 1) # 举例: tensor:([240.,320.])
sample_scales = ((sample_coord[:,2:] - sample_coord[:,:2]) / self.img_sample_sz).prod(dim=1).sqrt() # (右顶点坐标-左顶点坐标 = w,h) / image的w h 举例: tensor([2.0653])
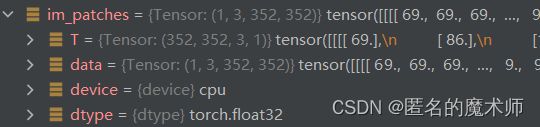
return sample_pos, sample_scales主要对输入的图片进行crop,使其满足输入到model的size,截取了crop前后的img,如下图所示

可以看出以目标为中心进行裁剪的,填充采用的是 F.pad,对边缘的像素进行复制
im_patch = F.pad(im2, (-tl[1].item(), br[1].item() - im2.shape[3], -tl[0].item(), br[0].item() - im2.shape[2]), pad_mode)最终输入到 model 的图片为固定的尺寸 352 大小
2、进行骨干网络的特征提取
紧接上步
with torch.no_grad():
backbone_feat = self.net.extract_backbone(im_patches)在进行骨干特征提取之前 先对im 进行归一化,然后再进行 骨干网络的特征提取
最终返回的是 提取的骨干特征, 裁剪图片的坐标点, crop 的img
return backbone_feat, patch_coords, im_patches3、 提取 classification features

经过 cls Feat 提取特征,这里输出的特征图shape为 Tensor:(1,512,22,22),而初始化模板帧时输出的shape为 x={Tensor:(13,512,22,22)},正好对应DiMP中的下图画框的差异

4、进行 transformer decoder
对应论文中的结构,对 跟踪帧 不经过encoder过程,而是直接decoder。

decoder 的输入如下所示
def transformer_decoder(self, sample_x: TensorList):
"""Transformer."""
with torch.no_grad():
decoded_feat, out_feat = self.net.classifier.transformer.decoder(sample_x.unsqueeze(0), memory=self.transformer_memory, pos=self.transformer_label, query_pos=None) ######### self.transformer_label
return decoded_feat, out_feat可以看到,它的输入是 跟踪帧的 classification 特征,self.transformer_memory为初始化模版帧的 encoder 的输出,而 self.transformer_label 是 上图中的masks
self.transformer_memory, _ = self.net.classifier.transformer.encoder(self.x_clf.unsqueeze(1), pos=None)
# mask in Transformer
self.transformer_label = prutils.gaussian_label_function(target_boxes.cpu().view(-1, 4), 0.1, self.net.classifier.filter_size,
self.feature_sz, self.img_sample_sz, end_pad_if_even=False)5、计算分类得分
scores_raw = self.classify_target(test_x)这里的输入来自 decoder的输出,计算分类得分的主要过程如下所示 (最终跳转到 ltr/models/layers/filter.py --- 5)
scores = self.net.classifier.classify(self.target_filter, sample_x)
scores = F.conv2d(feat.reshape(num_images, -1, feat.shape[-2], feat.shape[-1]), filter,
padding=padding, groups=num_sequences) # Tensor:(1,1,23,23)这里的 self.target_filter 就是 模板帧 decoder的输出经过 optimizer 后得到的 filter,如下所示
self.target_filter, _, losses = self.net.classifier.get_filter(x, target_boxes, num_iter=num_iter,
compute_losses=plot_loss)最终 的 计算分类的得分图 的shape 为 Tensor:(1,1,23,23)
6、定位目标
紧接上步
translation_vec, scale_ind, s, flag = self.localize_target(scores_raw, sample_pos, sample_scales)传入的参数分别为 score_raw 分类得分图,sample_pos 目标在crop img的中心坐标,sample_scales 裁剪目标相对于原img 的比例
首先对得分图进行处理,拿出得分图中的最大分数,以及它所在的得分图中的坐标。 这个过程通过 pytracking/libs/dcf.py 中的 max2d 函数实现的,如下所示
max_score1, max_disp1 = dcf.max2d(scores)
# =============
def max2d(a: torch.Tensor) -> (torch.Tensor, torch.Tensor): # a Tensor:(1,23,23)
"""Computes maximum and argmax in the last two dimensions."""
max_val_row, argmax_row = torch.max(a, dim=-2) # 第一维通道方向对比, 取 23X23 的列最大值,并返回最大值的位置 Tensor:(1,23), Tensor:(1,23)
max_val, argmax_col = torch.max(max_val_row, dim=-1) # 取出 max_val_row 中的最大值,并返回所在的位置 相当于所在的行的位置 Tensor:(1,) tensor:([1.1927],device='cuda:0') Tensor:(1,) tensor:([12],device='cuda:0')
# a = argmax_col.numel() # {int} 1
# b = argmax_col.view(-1) # tensor([12],device='cuda:0')
# c = torch.arange(a) # tensor([0])
argmax_row = argmax_row.view(argmax_col.numel(),-1)[torch.arange(argmax_col.numel()), argmax_col.view(-1)] # 拿出 最大值 所在的 列的位置 Tensor:(1,) tensor:([13], device='cuda:0')
argmax_row = argmax_row.reshape(argmax_col.shape) # tensor:([13], device='cuda:0')
argmax = torch.cat((argmax_row.unsqueeze(-1), argmax_col.unsqueeze(-1)), -1) # 最大值所处 的行列的位置 也就是在 score 得分图中的位置 tensor:[12,13]
return max_val, argmax 接下来通过 得分最大值的坐标 来计算 返回原图片上的坐标。
max_disp1 = max_disp1[scale_ind,...].float().cpu().view(-1) # tensor([13.,12.])
target_disp1 = max_disp1 - score_center # 以得分图中心为坐标原点,计算最大值的坐标 tensor([2.,1.])
translation_vec1 = target_disp1 * (self.img_support_sz / output_sz) * sample_scale然后会根据阈值判断一下目标所属的情况
if max_score1.item() < self.params.target_not_found_threshold: # False
return translation_vec1, scale_ind, scores_hn, 'not_found'
if max_score1.item() < self.params.get('uncertain_threshold', -float('inf')): # False
return translation_vec1, scale_ind, scores_hn, 'uncertain'
if max_score1.item() < self.params.get('hard_sample_threshold', -float('inf')): # False
return translation_vec1, scale_ind, scores_hn, 'hard_negative'接下来会计算一下 mask out neighborhood,
target_neigh_sz = self.params.target_neighborhood_scale * (self.target_sz / sample_scale) * (output_sz / self.img_support_sz)其中的参数来自:
# params.target_neighborhood_scale = 2.2 来自 parameter/trdimp 中的超参数设置# self.target_sz = torch.Tensor([state[3], state[2]]) 为模板帧的bbox的长和宽,原图片上的# sample_pos, sample_scales = self.get_sample_location(sample_coords)sample_scales = ((sample_coord[:,2:] - sample_coord[:,:2]) / self.img_sample_sz).prod(dim=1).sqrt() # (右顶点坐标-左顶点坐标 = w,h) / image的w hsample_scale = sample_scales[scale_ind] 总的来说就是crop img的h和w/采样img 的 h w# output_sz 为[22.,22.] 输出的得分图的大小# self.img_support_sz 为[352.,352.],输入到model中的尺寸
可以看到上面的输入都是固定的值,并没有与model中的任何输出有任何的关联
它最终得到的是 对应得分图上的一块区域的mask
tneigh_top = max(round(max_disp1[0].item() - target_neigh_sz[0].item() / 2), 0)
tneigh_bottom = min(round(max_disp1[0].item() + target_neigh_sz[0].item() / 2 + 1), sz[0])
tneigh_left = max(round(max_disp1[1].item() - target_neigh_sz[1].item() / 2), 0)
tneigh_right = min(round(max_disp1[1].item() + target_neigh_sz[1].item() / 2 + 1), sz[1])
scores_masked = scores_hn[scale_ind:scale_ind + 1, ...].clone() # tensor:(1,23,23)
scores_masked[...,tneigh_top:tneigh_bottom,tneigh_left:tneigh_right] = 0但是这步的主要作用就是用于对干扰物的判别,对 mask的区域的得分让其归0得到新的得分图,然后重新执行寻找得分图最大值的操作。也就是 max_score2 找到最大值后通过阈值进行判断后,看看是否属于干扰物等等,如下所示
if disp_norm2 > disp_threshold and disp_norm1 < disp_threshold:
return translation_vec1, scale_ind, scores_hn, 'hard_negative'
if disp_norm2 < disp_threshold and disp_norm1 > disp_threshold:
return translation_vec2, scale_ind, scores_hn, 'hard_negative'
if disp_norm2 > disp_threshold and disp_norm1 > disp_threshold:
return translation_vec1, scale_ind, scores_hn, 'uncertain'最终返回的是
return translation_vec1, scale_ind, scores_hn, 'normal'分别为
目标中心在原图上的位置(这个是相对坐标), scale_ind 0 , s 分类得分图 ,flag 'normal'
7、更新坐标原点
在上不之后,会更新 crop img 的坐标原点,因为 crop 就是 以 这个 为中心进行裁剪的。
new_pos = sample_pos[scale_ind,:] + translation_vec # crop img 的中心坐标 加上 返回原图片上对应的偏离坐标 = 在 crop img 中的坐标
self.update_state(new_pos)8、进行IoUNet
首先在这里放上ATOM 的IoUNet 的算法.具体详见这里
文章利用在大规模数据集上离线训练的IOUNet设计目标估计模块,再利用一个两层卷积网络并在线更新设计对目标外观鲁棒的目标分类模块。
ATOM是一个两阶段的追踪框架,首先通过目标分类分支生成10个proposals(可能的边界框),再利用目标估计分支预测这10个可能的边界框与真实边界框之间的IOU(交并比),选最高的三个取平均值作为最终的预测结果。# trdimp --- 748 predicted_box = output_boxes[inds, :].mean(0)这篇文章借鉴了目标识别中相似思想的IOUNet,还在文章利用IOUNet生成**(target-specific)目标特定的特征调制向量**,将原本相关滤波对目标真值计算岭回归的问题转变成对目标预测IOU最大化。
文章花了一些篇幅来介绍这个如何在两层卷积网络中反向传播更新梯度以求在实时的fps下完成在线更新。其在线更新的核心在于网络参数的优化方程是最小化平方差+岭回归正则化,反向传播更新梯度使用了共轭梯度。,这里也和MOSSE的优化参数很像,所以这个方法才被分类为相关滤波的吧。
这个过程在 trdimp.py --- 138 中
self.refine_target_box(backbone_feat, sample_pos[scale_ind,:], sample_scales[scale_ind], scale_ind, update_scale_flag)优化的过程在 trdimp.py --- 731 中
output_boxes, output_iou = self.optimize_boxes(iou_features, init_boxes)最终通过下面函数实现
def optimize_boxes_relative(self, iou_features, init_boxes):
"""Optimize iounet boxes with the relative parametrization ised in PrDiMP"""
output_boxes = init_boxes.view(1, -1, 4).to(self.params.device) # Tensor:(1,10,4)
step_length = self.params.box_refinement_step_length # 0.0025
if isinstance(step_length, (tuple, list)): # False
step_length = torch.Tensor([step_length[0], step_length[0], step_length[1], step_length[1]]).to(self.params.device).view(1,1,4)
sz_norm = output_boxes[:,:1,2:].clone() # 举例: tensor([[[102.6465, 75.5323]]], device='cuda:0')
output_boxes_rel = bbutils.rect_to_rel(output_boxes, sz_norm) # Tensor:(1,10,4)
for i_ in range(self.params.box_refinement_iter): # self.params.box_refinement_iter : 10
# forward pass
bb_init_rel = output_boxes_rel.clone().detach()
bb_init_rel.requires_grad = True
bb_init = bbutils.rel_to_rect(bb_init_rel, sz_norm)
outputs = self.net.bb_regressor.predict_iou(self.iou_modulation, iou_features, bb_init) # Tensor:(1,10)
if isinstance(outputs, (list, tuple)): # False
outputs = outputs[0]
outputs.backward(gradient = torch.ones_like(outputs))
# Update proposal
output_boxes_rel = bb_init_rel + step_length * bb_init_rel.grad
output_boxes_rel.detach_() # 截断反向传播
step_length *= self.params.box_refinement_step_decay
# for s in outputs.view(-1):
# print('{:.2f} '.format(s.item()), end='')
# print('')
# print('')
output_boxes = bbutils.rel_to_rect(output_boxes_rel, sz_norm)
return output_boxes.view(-1,4).cpu(), outputs.detach().view(-1).cpu()首先初始化 bbox ,用已经在前面更新的 self.pos 得到新的 init_box
然后进行 特征提取,输入的是 backbone_feat,主要经历的过程如下
def get_iou_feat(self, feat2): # layer2 layer3
"""Get IoU prediction features from a 4 or 5 dimensional backbone input."""
feat2 = [f.reshape(-1, *f.shape[-3:]) if f.dim()==5 else f for f in feat2]
feat3_t, feat4_t = feat2 # layer2, layer3
c3_t = self.conv3_2t(self.conv3_1t(feat3_t)) # Tensor:(1,256,44,44)
c4_t = self.conv4_2t(self.conv4_1t(feat4_t)) # Tensor:(1,256,22,22)
return c3_t, c4_t
其中 的 网络结构来自于 AtomIoUNet
(conv3_1t): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_2t): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_1t): Sequential(
(0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_2t): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)接下来 会产生随机的box,然后优化这些box
output_boxes, output_iou = self.optimize_boxes(iou_features, init_boxes)它的输入为 随机的box和 进行特征提取得到的 iou_features。在这里面,会进行
outputs = self.net.bb_regressor.predict_iou(self.iou_modulation, iou_features, bb_init)会跳转到 ltr/models/bbreg/atom_iou_net.py --- 96
"""Predicts IoU for the give proposals.
args:
modulation: Modulation vectors for the targets. Dims (batch, feature_dim).
feat: IoU features (from get_iou_feat) for test images. Dims (batch, feature_dim, H, W).
proposals: Proposal boxes for which the IoU will be predicted (batch, num_proposals, 4)."""它的输入来自
# 初始化模板帧时 所进行的 IoUNet 初始化
self.iou_modulation = self.get_iou_modulation(iou_backbone_feat, target_boxes)
# 提取得到的 iou_features
# 围绕目标随机产生的 bb_init在 predict_iou 函数中,会进行ROI Pooling
roi3t = self.prroi_pool3t(c3_t_att, roi2)
roi4t = self.prroi_pool4t(c4_t_att, roi2)这个过程的进行 在 ltr/external/PreciseRoIPooling/pytorch/prroi_pool/functional.py --- 41
这里最终会经过一个全连接层
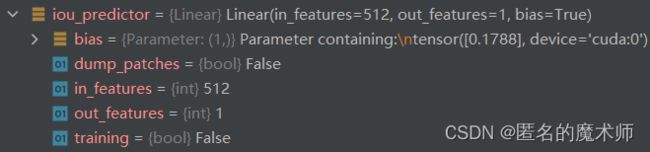
输出这10个 box 预测的IoU。
他接下来还会进行反向传播 ,更新 proposal
outputs.backward(gradient = torch.ones_like(outputs))
output_boxes_rel = bb_init_rel + step_length * bb_init_rel.grad然后循环执行上述操作
最终返回的是
return output_boxes.view(-1,4).cpu(), outputs.detach().view(-1).cpu()这两个应该是 对应的bbox和 预测的 Iou,上面的过程应该就是IoUNet的处理过程,没有做过多的深入了解,大致看一下下面的图片

9、得到最终的预测 的 bbox
最终预测的box
predicted_box = output_boxes[inds, :].mean(0)接下来还进行了更新
self.pos = new_pos.clone()
self.target_sz = new_target_sz
self.target_scale = new_scale其中前两个就表示了新预测的bbox
最后新的 bbox 通过他来得到,下面的为 (yxhw)形式
trdimp --- 189
new_state = torch.cat((self.pos[[1,0]] - (self.target_sz[[1,0]]-1)/2, self.target_sz[[1,0]]))out = {'target_bbox': output_state}
10、更新classifier model
trdimp --- 156
self.update_classifier(train_x, target_box, learning_rate, s[scale_ind,...])传入的参数分别为 train_x 为decoder 的输出,target_box 为接下来crop img 中的box以及一些其它的参数
在这个过程中,主要有一个流程
# Update the tracker memory
if hard_negative_flag or self.frame_num % self.params.get('train_sample_interval', 1) == 0: # True
self.update_memory(TensorList([train_x]), target_box, learning_rate)函数中有
# Update sample and label memory
for train_samp, x, ind in zip(self.training_samples, sample_x, replace_ind):
train_samp[ind:ind+1,...] = x其中 self.training_samples 中保留的是
# Initialize memory
self.training_samples = TensorList(
[x.new_zeros(self.params.sample_memory_size, x.shape[1], x.shape[2], x.shape[3]) for x in train_x])追朔于 模板帧的初始化 trdimp --- 628
x = encoded_feat.contiguous() # 举例: x={Tensor:(15,512,22,22)}
if self.params.get('update_classifier', True): # True
self.init_memory(TensorList([x]))
也就是说 这里面保留的是来自decoder 的输出。
八、大致流程的记录
1、 输入原img ---> (432,576,3)
2、 圈目标 (x,y,w,h) 左顶点坐标和长宽
3、 初始化网络, 建立尺寸 img to im ---> tensor(1,3,432,576), self.pos,self.target_sz 中心点坐标和长宽, self.image_sz 原img长宽, self.img_sample_sz 采样尺寸 self.base_target_sz 目标的bbox 在采样尺度下的尺寸 self.min_scale_factor和 self.max_scale_factor 尺度缩放因子
4、 提取骨干特征 nit_backbone_feat {OrderedDict:2} 'layer2' = {Tensor:(13,512,44,44)} 'layer3' = {Tensor:(13,1024,22,22)}
5、 初始化 classifier
|| 得到classification features 、进行dropout x-->{Tensor:(13,512,22,22)} 、self.feature_sz 特征尺寸、self.kernel_size classifier filter kernel 的尺寸、self.output_sz 输出特征的尺寸、target_boxes 数据增强后的目标bbox、 创建mask self.transformer_label--> Tensor:(15,1,22,22)、self.x_clf = x
|| 进行transformer encoder 输入是self.x_clf torch.Size([15,1,512,22,22])、reshape成Tensor:(7260,1,512) <--- (-1, batch, dim) 、输入到encoder中、最终得到的输出 self.transformer_memory Tensor:(7260,1,512)
|| 进行transformer decoder 输入是x[i,...]--->{Tensor:(1,1,512,22,22)} 以及self.transformer_memory --->Tensor:(7260,1,512) 以及self.transformer_label --->Tensor:(15,1,22,22)、
进行reshape 最终输入到decoder中的shape为 Output->Tensor:(484,1,512) memory->{Tensor:(7260,1,512)} pos->Tensor:(7260,1,512)、得到的输出 x={Tensor:(15,512,22,22)}
|| 通过 pridector 得到 filter
经过 model initializer, 经过 model optimizer,init memory
6、 初始化 IoUNet
7、 模板的初始化结束
8、 开始跟踪frame track
9、 crop img
10、 提取骨干特征
11、 提取 classification features
12、 进行 transformer decoder
13、 计算分类得分
14、 定位目标,得到目标相对于原图片中心坐标的 相对坐标
15、 通过ATOM IoUNet 机制确定最终预测的bbox,包括 中心点坐标以及长和宽
16、 更新 classifier 更新memory
九、网络结构
DiMPnet(
(feature_extractor): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
(classifier): LinearFilter(
(filter_initializer): FilterInitializerLinear(
(filter_conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(filter_pool): FilterPool(
(prroi_pool): PrRoIPool2D(kernel_size=(4, 4), spatial_scale=0.0625)
)
)
(filter_optimizer): DiMPSteepestDescentGN(
(distance_map): DistanceMap()
(label_map_predictor): Conv2d(100, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
(target_mask_predictor): Sequential(
(0): Conv2d(100, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): Sigmoid()
)
(spatial_weight_predictor): Conv2d(100, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
(score_activation): LeakyReluPar()
(score_activation_deriv): LeakyReluParDeriv()
)
(feature_extractor): Sequential(
(0): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): InstanceL2Norm()
)
(transformer): Transformer(
(encoder): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(head): ModuleList(
(0): RelationUnit(
(WK): Linear(in_features=512, out_features=128, bias=True)
(WV): Linear(in_features=512, out_features=512, bias=True)
)
)
)
(norm): InstanceL2Norm()
)
)
)
(decoder): TransformerDecoder(
(layers): ModuleList(
(0): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(head): ModuleList(
(0): RelationUnit(
(WK): Linear(in_features=512, out_features=128, bias=True)
(WV): Linear(in_features=512, out_features=512, bias=True)
)
)
)
(cross_attn): MultiheadAttention(
(head): ModuleList(
(0): RelationUnit(
(WK): Linear(in_features=512, out_features=128, bias=True)
(WV): Linear(in_features=512, out_features=512, bias=True)
)
)
)
(norm): InstanceL2Norm()
)
)
)
)
)
(bb_regressor): AtomIoUNet(
(conv3_1r): Sequential(
(0): Conv2d(512, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_1t): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3_2t): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(prroi_pool3r): PrRoIPool2D(kernel_size=(3, 3), spatial_scale=0.125)
(prroi_pool3t): PrRoIPool2D(kernel_size=(5, 5), spatial_scale=0.125)
(fc3_1r): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_1r): Sequential(
(0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_1t): Sequential(
(0): Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv4_2t): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(prroi_pool4r): PrRoIPool2D(kernel_size=(1, 1), spatial_scale=0.0625)
(prroi_pool4t): PrRoIPool2D(kernel_size=(3, 3), spatial_scale=0.0625)
(fc34_3r): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(fc34_4r): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(fc3_rt): LinearBlock(
(linear): Linear(in_features=6400, out_features=256, bias=True)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(fc4_rt): LinearBlock(
(linear): Linear(in_features=2304, out_features=256, bias=True)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(iou_predictor): Linear(in_features=512, out_features=1, bias=True)
)
)