Pytorch情感分析(task6)
BERT情感分析
-
- 数据集
- 步骤
-
- 构建迭代器
- 构建模型
- 设定超参数创建实例
- 选择损失函数和优化器
- train/evaluate
- test
参考: https://github.com/datawhalechina/team-learning-nlp/tree/master/Emotional_Analysis
数据集
IMDB
步骤
使用 transformers library 来获取预训练的Transformer并将它们用作embedding层。
将固定(而不训练)transformer,只训练从transformer产生的表示中学习的模型的其余部分。 在这种情况下,使用双向GRU继续提取从Bert embedding后的特征,最后在fc层上输出最终的结果。
import torch
import random
import numpy as np
SEED = 2021
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
由于BERT已经用特定的词汇进行了训练,这意味着需要使用完全相同的词汇进行训练,并以其 最初训练时相同的方式标记数据。
transformers 库为每个提供的transformer 模型都有分词器。通过加载预训练的“bert-base-uncased”标记器来实现这一点。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokenizer有一个 vocab 属性,它包含我们将使用的实际词汇。 我们可以通过检查其长度来检查其中有多少单词。

tokens = tokenizer.tokenize('Hello WORLD how ARE yoU?') # tokenizer用法

查看tokenizer序列开始和结束的属性(bos_token、eos_token)
init_token = tokenizer.cls_token
eos_token = tokenizer.sep_token
pad_token = tokenizer.pad_token
unk_token = tokenizer.unk_token
print(init_token, eos_token, pad_token, unk_token)
![]()
也可以通过反转词汇表来获得特殊tokens的索引
init_token_idx = tokenizer.convert_tokens_to_ids(init_token)
eos_token_idx = tokenizer.convert_tokens_to_ids(eos_token)
pad_token_idx = tokenizer.convert_tokens_to_ids(pad_token)
unk_token_idx = tokenizer.convert_tokens_to_ids(unk_token)
print(init_token_idx, eos_token_idx, pad_token_idx, unk_token_idx)
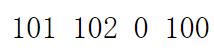
查看可以输入的最大长度
max_input_length = tokenizer.max_model_input_sizes['bert-base-uncased']
print(max_input_length) # 512
def tokenize_and_cut(sentence):
tokens = tokenizer.tokenize(sentence)
tokens = tokens[:max_input_length-2] #扣去cls sep剩下510
return tokens
from torchtext.legacy import data
TEXT = data.Field(batch_first = True, #batch维度在第一维
use_vocab = False, #不需要切分数据
tokenize = tokenize_and_cut,
preprocessing = tokenizer.convert_tokens_to_ids,
init_token = init_token_idx,
eos_token = eos_token_idx,
pad_token = pad_token_idx,
unk_token = unk_token_idx)
LABEL = data.LabelField(dtype = torch.float)
加载数据
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
查看数据长度
print(f"Number of training examples: {len(train_data)}")
print(f"Number of validation examples: {len(valid_data)}")
print(f"Number of testing examples: {len(test_data)}")
#Number of training examples: 17500
#Number of validation examples: 7500
#Number of testing examples: 25000
随便看一个句子的one-hot向量
print(vars(train_data.examples[6]))
可以用convert_ids_to_tokens将索引转为tokens
tokens = tokenizer.convert_ids_to_tokens(vars(train_data.examples[6])['text'])
print(tokens)

为标签构建词汇表
LABEL.build_vocab(train_data)
print(LABEL.vocab.stoi) # defaultdict(None, {'neg': 0, 'pos': 1})
构建迭代器
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
构建模型
from transformers import BertTokenizer, BertModel
bert = BertModel.from_pretrained('bert-base-uncased')
使用预训练的 Transformer 模型,而不是使用embedding层来获取文本的embedding。然后将这些embedding输入GRU以生成对输入句子情绪的预测。我们通过其 config 属性从transformer中获取嵌入维度大小(称为hidden_size)。
import torch.nn as nn
class BERTGRUSentiment(nn.Module):
def __init__(self, bert, hidden_dim, output_dim, n_layers, bidirectional, dropout):
super().__init__()
self.bert = bert
embedding_dim = bert.config.to_dict()['hidden_size']
self.rnn = nn.GRU(embedding_dim,
hidden_dim,
num_layers = n_layers,
bidirectional = bidirectional,
batch_first = True,
dropout = 0 if n_layers < 2 else dropout)
self.out = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
#text = [batch size, sent len]
with torch.no_grad():
embedded = self.bert(text)[0]
#embedded = [batch size, sent len, emb dim]
_, hidden = self.rnn(embedded)
#hidden = [n layers * n directions, batch size, emb dim]
if self.rnn.bidirectional:
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
else:
hidden = self.dropout(hidden[-1,:,:])
#hidden = [batch size, hid dim]
output = self.out(hidden)
#output = [batch size, out dim]
return output
设定超参数创建实例
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
model = BERTGRUSentiment(bert,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT)
检查模型中参数的数量
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
# The model has 112,241,409 trainable parameters
为了固定参数(不需要训练它们),需要将它们的 requires_grad 属性设置为 False。 为此只需遍历模型中的所有 named_parameters,如果它们是 bert 转换器模型的一部分,则设置 requires_grad = False,如微调的话,需要将requires_grad设置为True。
for name, param in model.named_parameters():
if name.startswith('bert'):
param.requires_grad = False
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
# The model has 2,759,169 trainable parameters
查看可训练参数的名称
for name, param in model.named_parameters():
if param.requires_grad:
print(name)

选择损失函数和优化器
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
计算准确度、定义train、evalute函数以及计算训练/评估时期每一个epoch所需时间
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
train/evaluate
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut6-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
加载为我们提供最佳验证集上损失值的参数,并在测试集上应用这些参数 - 并在测试集上达到了最优的结果。
model.load_state_dict(torch.load('tut6-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%') # Test Loss: 0.209 | Test Acc: 91.58%
test
def predict_sentiment(model, tokenizer, sentence):
model.eval()
tokens = tokenizer.tokenize(sentence)
tokens = tokens[:max_input_length-2]
indexed = [init_token_idx] + tokenizer.convert_tokens_to_ids(tokens) + [eos_token_idx]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(0)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
predict_sentiment(model, tokenizer, "This film is terrible")
# 0.03391794115304947