Transformers 库中的 Tokenizer 使用
文章目录
-
- 概述
- 基本使用方法
- 进阶
-
- 基本使用不能满足的情况
- 解决思路
-
- 问题一解决:(有两种思路)
- 问题二解决:
- Tokenizer 中的 Encoder
-
-
- vocab_base 部分
- vocab_add 部分
- 整体部分
-
- Reference
概述
本篇会说明下面几个部分:
- Tokenizer 的主要功能就是将 seqence 转变为一个 id 序列,所以本篇会讲怎么利用 Transformers 库中的 Tokenizer 完成这一功能。
- 上一点提到的功能其实主要依赖的是 Tokenizer 的 Encoder,所以第二点会展开讲 Tokenizer 的 Encoder。
基本使用方法
实现这个 sequence->ids 的功能的操作很简单,有许多办法(列举几个):
-
利用 _call_ (官方推荐方法)。 看了下源码发现,__call__ 中调用的就是 encode_plus() 函数,至于 encode_plus() 和 encode() 的区别已经有不少博文解释了, 这里不再赘述。
-
利用 batch_encode_plus() 方法,官方已弃用,推荐用 1 。 -
利用 encode() 方法,与 4 基本相似。

- 利用 tokenize() 方法和 convert_tokens_to_ids() 方法实现。
Example:(_call_) 将 “I use sub-words” 变为 ids
from transformers import BartTokenizer
model_name = "facebook/bart-base"
tokenizer = BartTokenizer.from_pretrained(model_name)
seq = "I use sub-words ."
res = tokenizer(seq, add_special_tokens=False)
print(res.input_ids)
输出为:

进阶
基本使用不能满足的情况
有时候利用上面的方法还不能满足我们的需求,可能出现下面的情况:
- 图 1 中展示的最终输出的个数为 8 个(其中首位的 0 和 2 分别是 Bart 中的开始符、结束符的 id,即 bos_token_id 和 eos_token_id),而我们期待的 “I use sub-words” 转变之后应该是 5 个(3+2),即我们希望 “sub-words” 不要被分开,这是一个问题。
- 有时候 Tokenizer 中的 vocabulary 中缺少我们需要的词汇。
解决思路
问题一解决:(有两种思路)
-
给整个序列加入一个标识序列,这个标识序列可以设计得很灵活,比如标记每部分 tokens 的长度;或者标记 tokens 的开始和结束位等等,但无论哪种,我们都需要获得每部分 tokens 转变为 ids 之后对应的 ids 有几个。
基于这种想法,我们可以先将 sequence 分开,每部分单独转变为 ids,并统计每部分的 id 个数,下面给出代码:
seq = "I use sub-words ." seq = seq.split() tokens_ids = [[tokenizer.bos_token_id]] for ele in seq: tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele))) tokens_ids.append([tokenizer.eos_token_id]) print(tokens_ids)代码中,我们先自己将文本分词,这样 “sub-words” 会被当作是 list of str 中的一个元素。之后我们手动将 list of str 中的各个元素转变为 id(这部分先用 tokenizer.tokenize 将原始 str 变为 BartTokenizer 词表中存的词,之后再用 tokenizer.convert_tokens_to_ids 将其变为 id)。(并自己手动在首位加入 bos_token 和 eos_token 的 id),输出结果为:
![]()
可以看到,因为我们事先将整个 seq 分成了多份,所以得到的结果也是一个 2 维 列表。但让人奇怪的是,为什么我们手动转变得到的 ids 和图1的结果不一样呢?为了保持与原先结果的一致性,我们将这条指令 tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele))) 中的 tokenizer.tokenize(ele) 部分加入参数 add_prefix_space = True,所以代码变为:
seq = "I use sub-words ."
seq = seq.split()
tokens_ids = [[tokenizer.bos_token_id]]
for ele in seq:
tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele, add_prefix_space = True)))
tokens_ids.append([tokenizer.eos_token_id])
print(tokens_ids)
输出为:
![]()
发现结果虽然基本和图1 结果一致了,但是第一个元素的 id 还是不一样,图1 为 100,此处为 38;又观察到图 2 正好相反,其只有第一个元素与图 1 相同,而之后的都不同。所以可以得知,转变第一个元素为 id 时参数 add_prefix_space 应该为 False。对应的代码修改如下:
seq = "I use sub-words ."
seq = seq.split()
tokens_ids = [[tokenizer.bos_token_id]]
for i,ele in enumerate(seq):
if i: tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele, add_prefix_space = True)))
else: tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele)))
tokens_ids.append([tokenizer.eos_token_id])
print(tokens_ids)
结果为:
结果输出正确。
那么上面说的 add_prefix_space 这个参数具体是干什么用的呢?
-
指定一些词为不可分割的词,什么意思呢?事实上 toknizer 中有这样一个成员变量
unique_no_split_tokens,这是一个列表,里面的每个元素可能是 token 或 tokens,作用是在 tokenizer 转换 ids 时,这些指定的 tokens 不被拆开分转变。下面用代码解释一下:seq = "I use sub-words ." seq = seq.split() tokenizer.unique_no_split_tokens.append("sub-words") tokens_ids = [[tokenizer.bos_token_id]] for i,ele in enumerate(seq): if i: tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele, add_prefix_space = True))) else: tokens_ids.append(tokenizer.convert_tokens_to_ids(tokenizer.tokenize(ele))) tokens_ids.append([tokenizer.eos_token_id]) print(tokens_ids)
可以看到当我们将 “sub-words” 加入到 unique_no_split_tokens 后, tokenizer 是对其整体编码,不再会自动拆开。
问题二解决:
利用 tokenizer.add_tokens() 函数,介绍如图1:
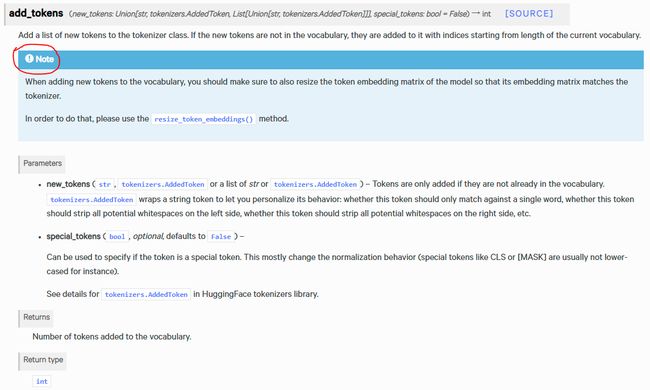
Examples:
# Let's see how to increase the vocabulary of Bert model and tokenizer
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
num_added_toks = tokenizer.add_tokens(['new_tok1', 'my_new-tok2'])
print('We have added', num_added_toks, 'tokens')
# Notice: resize_token_embeddings expect to receive the full size of the new vocabulary, i.e., the length of the tokenizer.
model.resize_token_embeddings(len(tokenizer))
**值得一提是,问题一的解决方法中的 unique_no_split_tokens 其含义就是 special_tokens,所以我们只需在使用 tokenizer.add_tokens() 设置 special_tokens 为 True 就能达到刚刚问题一第二种解决方法的效果。**验证代码如下:
print(tokenizer.unique_no_split_tokens)
tokenizer.unique_no_split_tokens += ["" ]
print(tokenizer.unique_no_split_tokens)

print(tokenizer.unique_no_split_tokens)
tokenizer.add_tokens("" , special_tokens=True)
print(tokenizer.unique_no_split_tokens)

可以发现,两种方式得到的结果是一致的(仅仅顺序不同,但无所谓)。
Tokenizer 中的 Encoder
上面介绍了 Tokenizer 将 seqence 转变为 ids 的方法,这种转变利用的就是 Tokenizer 中的 Encoder,而事实上,这个 Encoder 只是一个 dict 变量,里面的 item 的形式为 "word":id,整个 dict 存储的就是 vocabulary 中所有词汇和相应 id 的对应关系。
我们知道,现在说的 Transformers 库中的都是预训练模型,那么也就是意味着这个 Encoder 中包含着的词汇之后是可以通过预训练模型得到一个经过预训练的高维表示,那么如果如上面提到的我们需要另外 add_tokens 的 tokens 肯定没有对应的高维表示(毕竟这些词汇没有跟着一起预训练)。基于这种考虑 Transformers 中将 Tokenizer 的原始词汇和新加的词汇区别开来,如图:
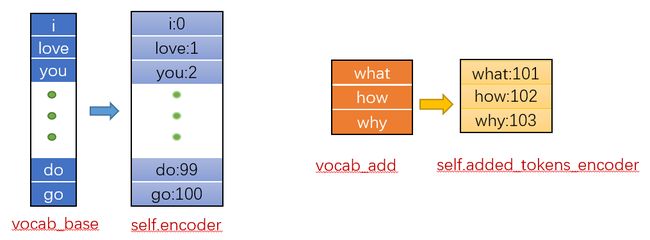
从图 9 中可以看到,可以将 Tokenizer 中的 words 分为两类:
vocab_base 部分
预训练模型本身就有的 words 组成的 vocabulary 我称其为 vocab_base,存储该 vocabulary 中 word 和 id 对应关系的是 self.encoder(如图):
可以看到 self.encoder 中的内容是读取的 vocab_file 中的内容。
针对 vocab_base 的相关操作:
- vocab_base 的词汇个数:
tokenizer.vocab_size(如图)
可以看到,其实 vocab_size 就是 len(self.encoder)
vocab_add 部分
使用者自己加入的 words 组成的 vocabulary 我称其为 vocab_add,存储该 vocabulary 中 word 和 id 对应关系的是 self.added_tokens_encoder(如图):
可以看到 self.added_tokens_encoder 只是个空字典(废话,还没加 token,当然是空的)。
针对 vocab_add 的相关操作:
- vocab_add 的内容:
tokenizer.get_added_vocab()(如图)

- vocab_add 的大小(即 add_tokens 的个数):因为 Transformers 中没有专门提供这个的接口,所以我们直接用指令
len(tokenizer.added_tokens_encoder)即可。
整体部分
整体指得即 self.encoder + self.added_tokens_encoder,即 vocab_base + vocab_add,我用 vocab_all 表示。
针对 vocab_all 的相关操作:
- vocab_all 的内容:
tokenizer.get_vocab(可能有的 pretrain model 没有提供这个接口)
- vocab_all 中 item 个数(即 word 个数):
len(tokenizer)
Reference
- [4] tokenizer.add_tokens()