【《深度学习入门》—— 学习笔记(二)】
《深度学习入门》—— 学习笔记(二)_5-8章
第五章 误差反向传播法
方法一:基于数学式 - 严密简洁
方法二:基于计算图(computational graph) - 直观
5.1 计算图
【用计算图求解】
- 构建计算图
- 在计算图上,从左向右进行计算
其中,“从左向右进行计算”是一种正方向上的传播,简称为正向传播(forward propagation)。正向传播是从计算图出发点到结束点的传播。
【局部计算】
计算图可以集中精力于局部计算。无论全局的计算有多么复杂,各个步骤所要做的就是对象节点的局部计算。虽然局部计算非常简单,但是通过传递它的计算结果,可以获得全局的复杂计算的结果。
【为何用计算图解题】 - 局部计算 - 无论全局是多么复杂的计算,都可以通过局部计算使各个节点致力于简单的计算,从而简化问题。
- 利用计算图可以将中间的计算结果全部保存起来。
- 使用计算图最大的原因是,可以通过反向传播高效计算导数。
综上,计算图的优点是,可以通过正向传播和反向传播高效地计算各个变量的导数值。
5.2 链式法则
【计算图的反向传播】

【链式法则】
如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示。
【链式法则和计算图】

反向传播的计算顺序是,先将节点的输入信号乘以节点的局部导数(偏导数),然后再传递给下一个节点。
5.3 反向传播
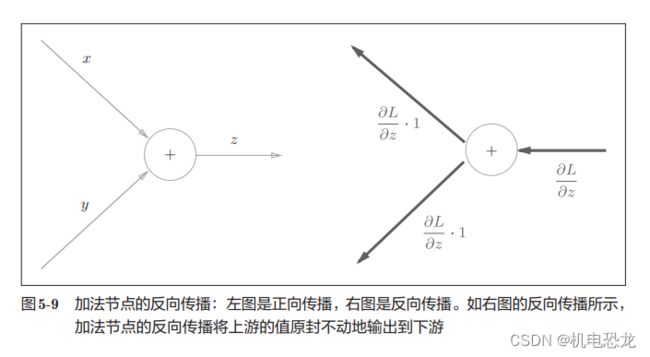
【加法节点的反向传播】
【乘法节点的反向传播】
乘法的反向传播会将上游的值乘以正向传播时的输入信号的“翻转值”后传递给下游。翻转值表示一种翻转关系。

加法的反向传播只是将上游的值传给下游,并不需要正向传播的输入信号。但是,乘法的反向传播需要正向传播时的输
入信号值。因此,实现乘法节点的反向传播时,要保存正向传播的输入信号。
5.4 简单层的实现
把要实现的计算图的乘法节点称为“乘法层”(MulLayer),加法节点称为“加法层”(AddLayer)。
【乘法层的实现】
层的实现中有两个共通的方法(接口)forward()和backward()。forward()对应正向传播,backward()对应反向传播。

init()中会初始化实例变量x和y,它们用于保存正向传播时的输入值。forward()接收x和y两个参数,将它们相乘后输出。backward()将从上游传来的导数(dout)乘以正向传播的翻转值,然后传给下游。
【加法层的实现】

加法层不需要特意进行初始化,所以__init__()中什么也不运行(pass语句表示“什么也不运行”)。加法层的forward()接收x和y两个参数,将它们相加后输出。backward()将上游传来的导数(dout)原封不动地传递给下游。
5.5 激活函数层的实现
【ReLU层】

在式(5.8)中,如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游。反过来,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停在此处。
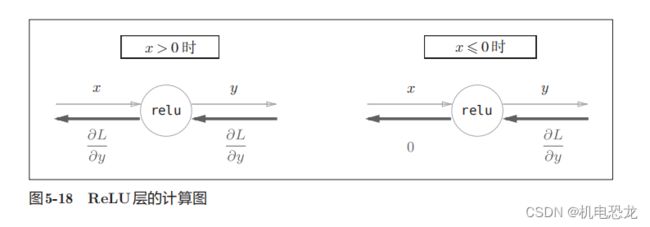

Relu类有实例变量mask。这个变量mask是由True/False构成的NumPy数组,它会把正向传播时的输入x的元素中小于等于0的地方保存为True,其他地方(大于0的元素)保存为False。如果正向传播的输入值小于等于0,则反向传播的值为0。反向传播中会使用正向传播时保存的mask。将从上游传来的dout的mask中的元素为True的地方设为0。
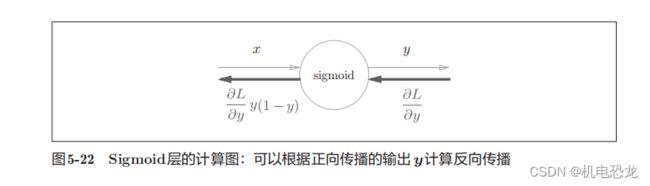
【Sigmoid层】




5.6 Affine/Softmax层的实现
5.6.1 Affine层

神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换”A。因此,这里将进行仿射变换的处理实现为“Affine层”。几何中,仿射变换包括一次线性变换和一次平移,分别对应神经网络的加权和运算与加偏置运算。

之前计算图中各个节点间流动的是标量,这个例子中各个节点间传播的是矩阵。



5.6.2 批版本的Affine层


Softmax-with-Loss 层



5.7 误差反向传播法的实现
【神经网络学习的全貌图】
前提
神经网络中有合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为学习。神经网络的学习分为下面4个步骤。
步骤1(mini-batch)
从训练数据中随机选择一部分数据。
步骤2(计算梯度)
计算损失函数关于各个权重参数的梯度
步骤3(更新参数)
将权重参数沿梯度方向进行微小的更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
【对应误差反向传播法的神经网络实现】




【误差反向传播法的梯度确认】
目前介绍了两种求梯度的方法:基于数值微分的方法;解析性地求解数学式的方法。后者通过使用误差反向传播法,即使存在大量参数,也可以高效计算梯度。
数值微分的优点是实现简单,因此,一般情况下不太容易出错。而误差反向传播法的实现很复杂,容易出错。所以,经常会比较数值微分的结果和误差反向传播法的结果,以确认误差反向传播法的实现是否正确。确认数值微分求出的梯度结果和误差反向传播法求出的结果是否一致(严格地讲,是非常相近)的操作称为梯度确认(gradient check)。


【使用误差反向传播法的学习】

5.8 小结

第六章 与学习相关的技巧
6.1 参数的更新
【SGD】
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化(optimization)。在深度神经网络中,参数的数量非常庞大,导致最优化问题更加复杂。

在前几章中,为了找到最优参数,我们将参数的梯度(导数)作为了线索。使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,从而逐渐靠近最优参数,这个过程称为随机梯度下降法(stochastic gradient descent),简称SGD。

lr表示learning rate,这个学习率会保存为实例变量。此外,代码段中还定义了update(params, grads)方法,这个方法在SGD中会被反复调用。参数params和grads(与之前的神经网络的实现一样)是字典型变量,按params[‘W1’]、grads[‘W1’]的形式,分别保存了权重参数和它们的梯度。
缺点:
如果函数的形状非均向(anisotropic),比如呈延伸状,搜索的路径就会非常低效。SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。
【Momentum】

新变量v,对应物理上的速度。式(6.3)表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。Momentum方法给人的感觉就像是小球在地面上滚动。

αv这一项,是指在物体不受任何力时,该项承担使物体逐渐减速的任务(α设定为0.9之类的值),对应物理上的地面摩擦或空气阻力。

【AdaGrad】
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。
在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。
AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习(AdaGrad的Ada来自英文单词Adaptive,即“适当的”的意思)。下面,让我们用数学式表示AdaGrad的更新方法。
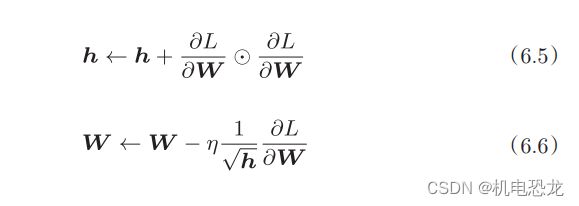
新变量h保存了以前的所有梯度值的平方和(式(6.5)中的表示对应矩阵元素的乘法)。在更新参数时,通过乘以1/√h,可以调整学习的尺度。这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说,可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为 0,完全不再更新。为了改善这个问题,可以使用 RMSProp 方法。RMSProp方法并不是将过去所有的梯度一视同仁地相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多地反映出来。这种操作从专业上讲,称为“指数移动平均”,呈指数函数式地减小过去的梯度的尺度。

这里需要注意的是,最后一行加上了微小值1e-7。这是为了防止当self.h[key]中有0时,将0用作除数的情况。在很多深度学习的框架中,这个微小值也可以设定为参数,但这里我们用的是1e-7这个固定值。
【Adam】
通过组合前面两个方法的优点,有望实现参数空间的高效搜索。此外,进行超参数的“偏置校正”也是Adam的特征。Adam会设置 3个超参数。一个是学习率(论文中以α出现),另外两个是一次momentum系数β1和二次momentum系数β2。根据论文,标准的设定值是β1为 0.9,β2 为 0.999。设置了这些值后,大多数情况下都能顺利运行。
【对比四种方法】

6.2 权重的初始值
不能将权重初始值设为0:为了防止“权重均一化”(严格地讲,是为了瓦解权重的对称结构),必须随机生成初始值。
【隐藏层的激活值的分布】
将激活函数的输出数据称为“激活值”,各层激活值若偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。
各层的激活值的分布都要求有适当的广度。通过在各层间传递多样性的数据,神经网络可以进行高效的学习。相反,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
【ReLU的权重初始值】
但当激活函数使用ReLU时,一般推荐使用ReLU专用的初始值,也就是Kaiming He等人推荐的初始值,也称为“He初始值”。当初始值为He初始值时,各层中分布的广度相同。由于即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值。
总结,当激活函数使用ReLU时,权重初始值使用He初始值,当激活函数为sigmoid或tanh等S型曲线函数时,初始值使用Xavier初始值。这是目前的最佳实践。
6.3 Batch Normalization
【优点】
- 可以使学习快速进行(可以增大学习率)。
- 不那么依赖初始值(对于初始值不用那么神经质)。
- 抑制过拟合(降低Dropout等的必要性)。
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即Batch Normalization层(下文简称Batch Norm层)。




【评估】
综上,通过使用Batch Norm,可以推动学习的进行。并且,对权重初始值变得健壮(“对初始值健壮”表示不那么依赖初始值)。Batch Norm具备了如此优良的性质,一定能应用在更多场合中。
6.4 正则化
机器学习的问题中,过拟合是一个很常见的问题。过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。
【过拟合】
原因:(1) 模型拥有大量参数、表现力强。(2) 训练数据少。
【权力衰减】
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是因为权重参数取值过大才发生的。[损失函数加上权重的L2范数的权值衰减方法]
【Dropout】
如果网络的模型复杂,只用权值衰减难以应付,这种情况使用Dropout方法。Dropout是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递。
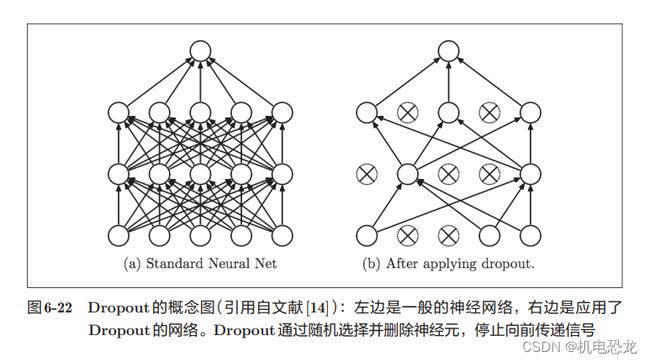

正向传播时传递了信号的神经元,反向传播时按原样传递信号;正向传播时没有传递信号的神经元,反向传播时信号将停在那里。
机器学习中经常使用集成学习。所谓集成学习,就是让多个模型单独进行学习,推理时再取多个模型的输出的平均值。通过进行集成学习,神经网络的识别精度可以提高好几个百分点。这个集成学习与 Dropout有密切的关系。这是因为可以将 Dropout理解为,通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习。并且,推理时,通过对神经元的输出乘以删除比例(比如,0.5等),可以取得模型的平均值。也就是说,可以理解成,Dropout将集成学习的效果(模拟地)通过一个网络实现了。
6.5 超参数的验证
超参数是指,比如各层的神经元数量、batch大小、参数更新时的学习率或权值衰减等。如果这些超参数没有设置合适的值,模型的性能就会很差。尽可能高效地寻找超参数的值。
【验证数据】
之前我们使用的数据集分成了训练数据和测试数据,训练数据用于学习,测试数据用于评估泛化能力。由此,就可以评估是否只过度拟合了训练数据(是否发生了过拟合),以及泛化能力如何等。不能使用测试数据评估超参数的性能。 如果使用测试数据调整超参数,超参数的值会对测试数据发生过拟合。因此,调整超参数时,必须使用超参数专用的确认数据。用于调整超参数的数据,一般称为验证数据(validation data)。我们使用这个验证数据来评估超参数的好坏。
根据不同的数据集,有的会事先分成训练数据、验证数据、测试数据三部分,有的只分成训练数据和测试数据两部分,有的则不进行分割。在这种情况下,用户需要自行进行分割。
【超参数的最优化】
进行超参数的最优化时,逐渐缩小超参数的“好值”的存在范围非常重要。所谓逐渐缩小范围,是指一开始先大致设定一个范围,从这个范围中随机选出一个超参数(采样),用这个采样到的值进行识别精度的评估;然后,多次重复该操作,观察识别精度的结果,根据这个结果缩小超参数的“好值”的范围。通过重复这一操作,就可以逐渐确定超参数的合适范围。
步骤0
设定超参数的范围。
步骤1
从设定的超参数范围中随机采样。
步骤2
使用步骤1中采样到的超参数的值进行学习,通过验证数据评估识别精度(但是要将epoch设置得很小)。
步骤3
重复步骤1和步骤2(100次等),根据它们的识别精度的结果,缩小超参数的范围。
反复进行上述操作,不断缩小超参数的范围,在缩小到一定程度时,从该范围中选出一个超参数的值。这就是进行超参数的最优化的一种方法。
在超参数的最优化中,如果需要更精炼的方法,可以使用贝叶斯最优化(Bayesian optimization)。贝叶斯最优化运用以贝叶斯定理为中心的数学理论,能够更加严密、高效地进行最优化。
【超参数最优化的实现】
观察可以使学习顺利进行的超参数的范围,从而缩小值的范围。然后,在这个缩小的范围中重复相同的操作。这样就能缩小到合适的超参数的存在范围,然后在某个阶段,选择一个最终的超参数的值。
6.6 小结

第七章 卷积神经网络
卷积神经网络CNN(Convolutional Neural Network),被用于图象识别、语音识别等各种场合。
7.1 整体结构
CNN中新出现了卷积层(Convolution层)和池化层(Pooling层)。
之前介绍的神经网络中,相邻层的所有神经元之间都有连接,这称为全连接(fully-connected)。另外,我们用Affine层实现了全连接层。如果使用这个Affine层,一个5层的全连接的神经网络就可以通过图7-1所示的网络结构来实现。
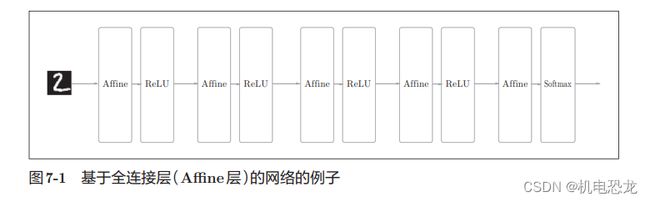
 CNN 中新增了 Convolution 层 和 Pooling 层。CNN 的层的连接顺序是“Convolution - ReLU -(Pooling)”(Pooling层有时会被省略)。这可以理解为之前的“Affi ne - ReLU”连接被替换成了“Convolution -ReLU -(Pooling)”连接。CNN中,靠近输出的层中使用了之前的“Affi ne - ReLU”组合。此外,最后的输出层中使用了之前的“Affine -Softmax”组合。这些都是一般的CNN中比较常见的结构。
CNN 中新增了 Convolution 层 和 Pooling 层。CNN 的层的连接顺序是“Convolution - ReLU -(Pooling)”(Pooling层有时会被省略)。这可以理解为之前的“Affi ne - ReLU”连接被替换成了“Convolution -ReLU -(Pooling)”连接。CNN中,靠近输出的层中使用了之前的“Affi ne - ReLU”组合。此外,最后的输出层中使用了之前的“Affine -Softmax”组合。这些都是一般的CNN中比较常见的结构。
7.2 卷积层
【全连接层存在的问题】
之前介绍的全连接的神经网络中使用了全连接层(Affine层)。在全连接层中,相邻层的神经元全部连接在一起,输出的数量可以任意决定。全连接层存在的问题:数据的形状被“忽视”了。
卷积层可以保持形状不变。另外,CNN中,有时将卷积层的输入输出数据成为特征图(feature map)。其中卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。
【卷积计算】
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。

假设用(height, width)表示数据和滤波器的形状,则在本例中,输入大小是(4, 4),滤波器大小是(3, 3),输出大小是(2, 2)。另外,有的文献中也会用“核”这个词来表示这里所说的“滤波器”。

对于输入数据,卷积运算以一定间隔滑动滤波器的窗口并应用。这里所说的窗口是指图7-4中灰色的3 × 3的部分。如图7-4所示,将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。
在全连接的神经网络中,除了权重参数,还存在偏置。CNN中,滤波器的参数就对应之前的权重。并且,CNN中也存在偏置。

【填充】
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),这称为填充(padding),是卷积运算中经常会用到的处理。使用填充主要是为了调整输出的大小。因为如果每次进行卷积运算都会缩小空间,那么在某个时刻输出大小就有可能变为 1,导致无法再应用卷积运算。为了避免出现这样的情况,就要使用填充。

如图7-6所示,通过填充,大小为(4, 4)的输入数据变成了(6, 6)的形状。然后,应用大小为(3, 3)的滤波器,生成了大小为(4, 4)的输出数据。这个例子中将填充设成了1,不过填充的值也可以设置成2、3等任意的整数。在图7-5的例子中,如果将填充设为2,则输入数据的大小变为(8, 8);如果将填充设为3,则大小变为(10, 10)。
【步幅】
应用滤波器的位置间隔称为步幅(stride)。增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。
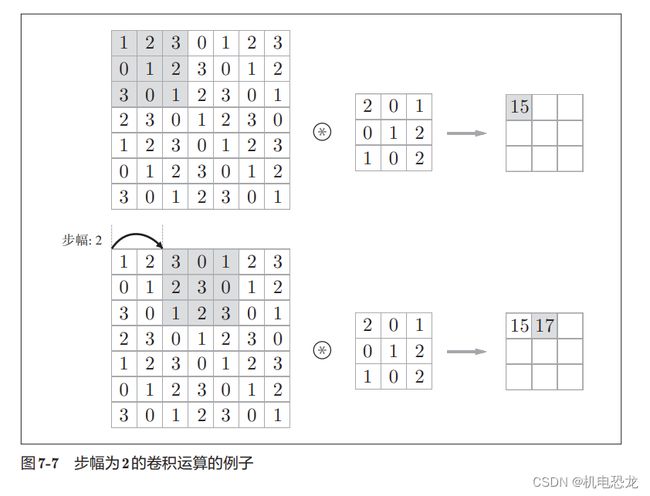
对于填充和步幅,如何计算输出大小:

虽然只要代入值就可以计算输出大小,但是所设定的值必须使式(7.1)分别可以除尽。当输出大小无法除尽时(结果是小数时),需要采取报错等对策。顺便说一下,根据深度学习的框架的不同,当值无法除尽时,有时会向最接近的整数四舍五入,不进行报错而继续运行。
【3维数据的卷积计算】


需要注意的是,在3维数据的卷积运算中,输入数据和滤波器的通道数要设为相同的值。在这个例子中,输入数据和滤波器的通道数一致,均为3。滤波器大小可以设定为任意值(不过,每个通道的滤波器大小要全部相同)。
【综合方块思考】
方块是如图7-10所示的3维长方体。把3维数据表示为多维数组时,书写顺序为(channel, height, width)。

在这个例子中,数据输出是1张特征图。所谓1张特征图,换句话说,就是通道数为1的特征图。
在通道方向上也拥有多个卷积计算的输出,需要用到多个滤波器(权重)。

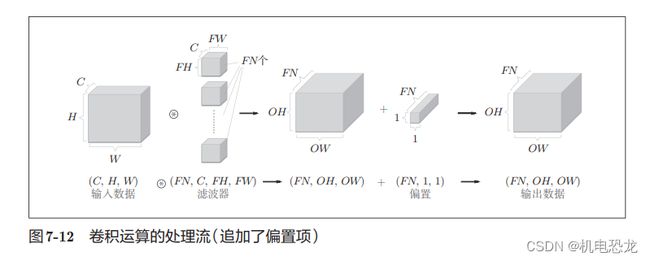
【批处理】
对卷积运算进行批处理,是按(batch_num, channel, height, width)的顺序保存数据。网络间传
递的是4维数据,对这N个数据进行了卷积运算。也就是说,批处理将N次的处理汇总成了1次进行。

7.3 池化层

图7-14的例子是按步幅2进行2 × 2的Max池化时的处理顺序。“Max池化”是获取最大值的运算,“2 × 2”表示目标区域的大小。一般来说,池化的窗口大小会和步幅设定成相同的值。
除了Max池化之外,还有Average池化等。相对于Max池化是从目标区域中取出最大值,Average池化则是计算目标区域的平均值。在图像识别领域,主要使用Max池化。
【池化层的特征】
- 没有要学习的参数 - 池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。
- 通道数不发生变化 - 经过池化运算,输入数据和输出数据的通道数不会发生变化。如图7-15所示,计算是按通道独立进行的。
- 对微小的位置变化具有鲁棒性(健壮) - 输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性。
7.4 卷积层和池化层的实现
【4维数组】

【基于 im2col的展开】

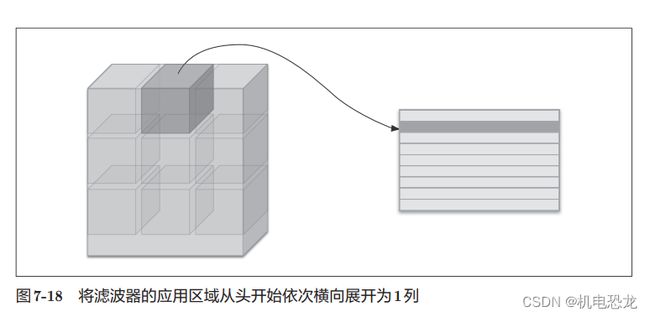
为了便于观察,将步幅设置得很大,以使滤波器的应用区域不重叠。而在实际的卷积运算中,滤波器的应用区域几乎都是重叠的。在滤波器的应用区域重叠的情况下,使用im2col展开后,展开后的元素个数会多于原方块的元素个数。因此,使用im2col的实现存在比普通的实现消耗更多内存的缺点。但是,汇总成一个大的矩阵进行计算,对计算机的计算颇有益处。比如,在矩阵计算的库(线性代数库)等中,矩阵计算的实现已被高度最优化,可以高速地进行大矩阵的乘法运算。因此,通过归结到矩阵计算上,可以有效地利用线性代数库。
im2col这个名称是“image to column”的缩写,翻译过来就是“从图像到矩阵”的意思。Caffe、Chainer 等深度学习框架中有名为im2col的函数,并且在卷积层的实现中,都使用了im2col。

【卷积层的实现】


卷积层的初始化方法将滤波器(权重)、偏置、步幅、填充作为参数接收。滤波器是 (FN, C, FH, FW)的 4 维形状。另外,FN、C、FH、FW分别是 Filter Number(滤波器数量)、Channel、Filter Height、Filter Width的缩写。这里用粗体字表示Convolution层的实现中的重要部分。在这些粗体字部分,用im2col展开输入数据,并用reshape将滤波器展开为2维数组。然后,计算展开后的矩阵的乘积。
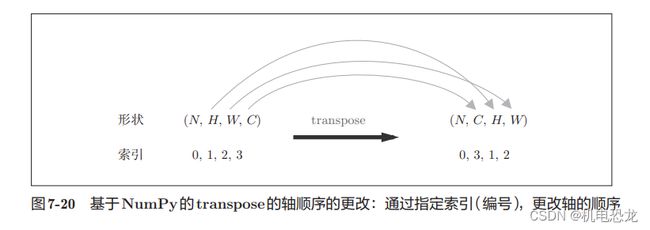
以上就是卷积层的forward处理的实现。在进行卷积层的反向传播时,必须进行im2col的逆处理。
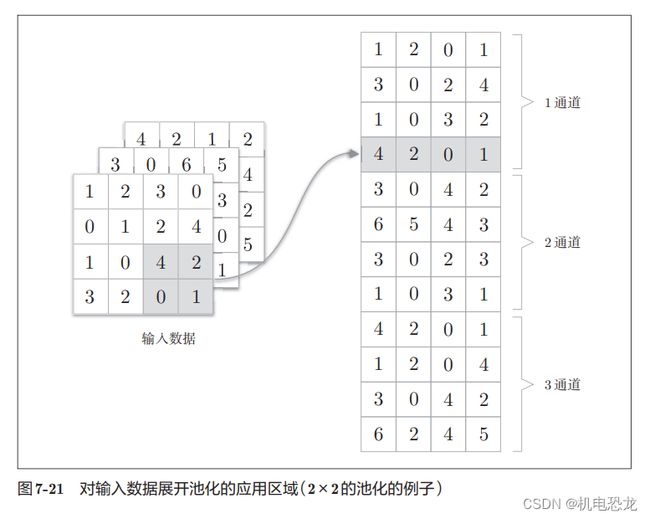
【池化层的实现】
池化层的实现和卷积层相同,都使用im2col展开输入数据。不过,池化的情况下,在通道方向上是独立的,这一点和卷积层不同。具体地讲,如图7-21所示,池化的应用区域按通道单独展开。
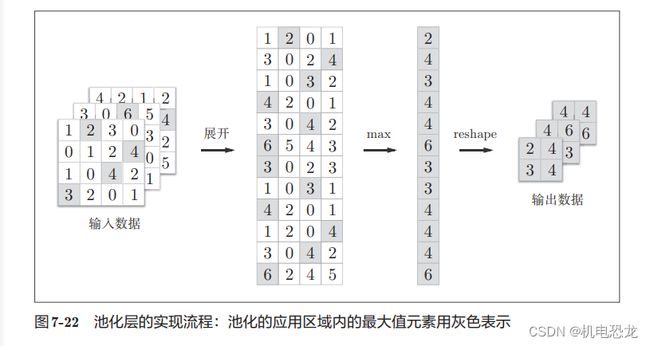

池化层的实现按下面3个阶段进行:
- 展开输入数据。
- 求各行的最大值。
- 转换为合适的输出大小。
最大值的计算可以使用 NumPy 的 np.max方法。np.max可以指定axis参数,并在这个参数指定的各个轴方向上求最大值。比如,如果写成np.max(x, axis=1),就可以在输入x的第1维的各个轴方向上求最大值。
7.5 CNN的实现


首先式初始化的最开始部分:

权重参数的初始化部分:

生成必要的层:

进行推理的predict方法和求损失函数值的loss方法:

接下来是基于误差反向传播法求梯度:
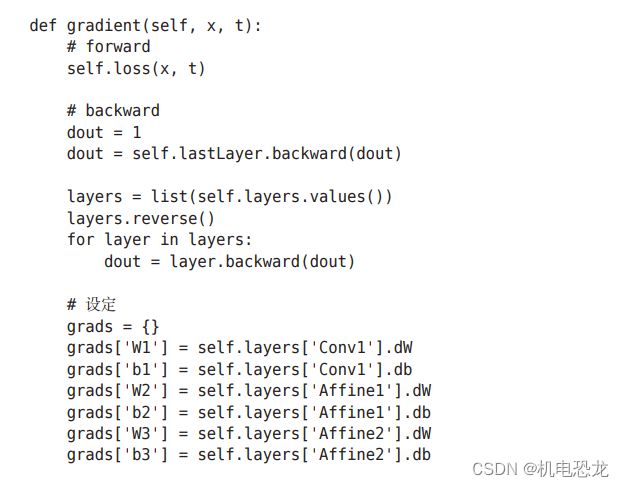
参数的梯度通过误差反向传播法(反向传播)求出,通过把正向传播和反向传播组装在一起来完成。最后,把各个权重参数的梯度保存到grads字典中。这就是SimpleConvNet的实现。
如上所述,卷积层和池化层是图像识别中必备的模块。CNN可以有效读取图像中的某种特性,在手写数字识别中,还可以实现高精度的识别。
7.6 CNN的可视化
【第 1层权重的可视化】

如果要问图7-24中右边的有规律的滤波器在“观察”什么,答案就是它在观察边缘(颜色变化的分界线)和斑块(局部的块状区域)等。
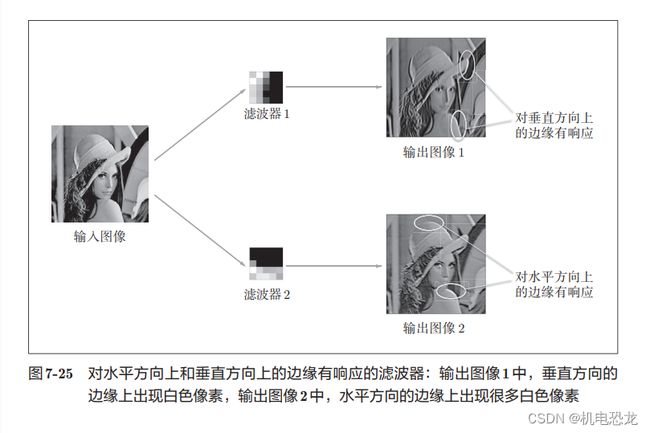
由此可知,卷积层的滤波器会提取边缘或斑块等原始信息。而刚才实现的CNN会将这些原始信息传递给后面的层。
【基于分层结构的信息提取】
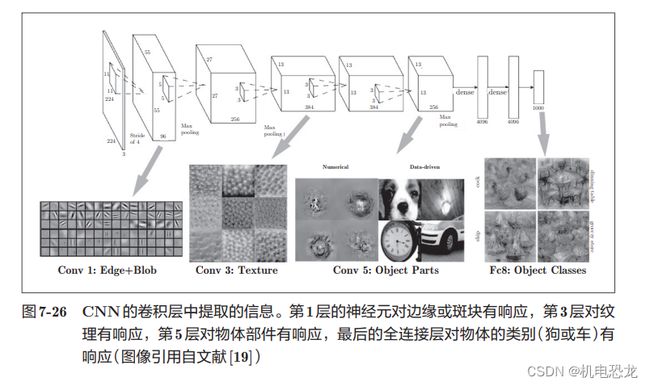
如果堆叠了多层卷积层,则随着层次加深,提取的信息也愈加复杂、抽象,这是深度学习中很有意思的一个地方。最开始的层对简单的边缘有响应,接下来的层对纹理有响应,再后面的层对更加复杂的物体部件有响应。也就是说,随着层次加深,神经元从简单的形状向“高级”信息变化。换句话说,就像我们理解东西的“含义”一样,响应的对象在逐渐变化。
7.7 具有代表性的CNN
- LeNet
LeNet在1998年被提出,是进行手写数字识别的网络。如图7-27所示,它有连续的卷积层和池化层(正确地讲,是只“抽选元素”的子采样层),最后经全连接层输出结果。

和“现在的CNN”相比,LeNet有几个不同点。第一个不同点在于激活函数。LeNet中使用sigmoid函数,而现在的CNN中主要使用ReLU函数。此外,原始的LeNet中使用子采样(subsampling)缩小中间数据的大小,而现在的CNN中Max池化是主流。 - AlexNet
在LeNet问世20多年后,AlexNet被发布出来。AlexNet是引发深度学习热潮的导火线,不过它的网络结构和LeNet基本上没有什么不同,如图7-28所示。

AlexNet叠有多个卷积层和池化层,最后经由全连接层输出结果。虽然结构上AlexNet和LeNet没有大的不同,但有以下几点差异。
• 激活函数使用ReLU。
• 使用进行局部正规化的LRN(Local Response Normalization)层。
• 使用Dropout(6.4.3节)。
如上所述,关于网络结构,LeNet和AlexNet没有太大的不同。但是,围绕它们的环境和计算机技术有了很大的进步。具体地说,现在任何人都可以获得大量的数据。而且,擅长大规模并行计算的GPU得到普及,高速进行大量的运算已经成为可能。大数据和GPU已成为深度学习发展的巨大的原动力。
7.8 小结

第八章 深度学习
深度学习是加深了层的深度神经网络。
8.1 加深网络

这个网络使用He初始值作为权重的初始值,使用Adam更新权重参数。把上述内容总结起来,这个网络有如下特点。
• 基于3×3的小型滤波器的卷积层。
• 激活函数是ReLU。
• 全连接层的后面使用Dropout层。
• 基于Adam的最优化。
• 使用He初始值作为权重初始值。
【进一步提高识别精度】
对于大规模的一般物体识别的情况,因为问题复杂,所以加深层对提高识别精度大有裨益。

【加深层的动机】
- 可以看到层越深,识别性能也越高。
- 可以减少网络的参数数量。说得详细一点,就是与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。比如,重复三次3 × 3的卷积运算时,参数的数量总共是27。而为了用一次卷积运算“观察”与之相同的区域,需要一个7 × 7的滤波器,此时的参数数量是49。
- 使学习更加高效。通过加深层,可以将各层要学习的问题分解成容易解决的简单问题,从而可以进行高效的学习。
叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将 ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
8.2 深度学习的小历史
【ImageNet】
ImageNet是拥有超过100万张图像的数据集。如图8-7所示,它包含了各种各样的图像,并且每张图像都被关联了标签(类别名)。

【VGG】
VGG是由卷积层和池化层构成的基础的CNN。它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。VGG中需要注意的地方是,基于3×3的小型滤波器的卷积层的运算是连续进行的。重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”的处理,最后经由全连接层输出结果。

【GooleLeNet】
GoogLeNet的网络结构如图8-10所示。图中的矩形表示卷积层、池化层等。GoogLeNet的特征是,网络不仅在纵向上有深度,在横向上也有深度(广度)。
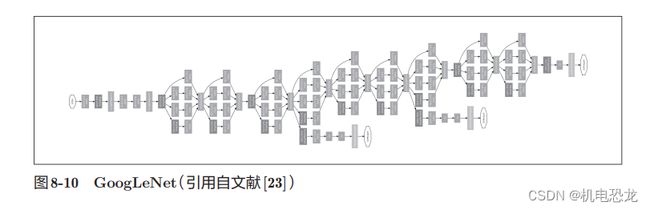
GoogLeNet在横向上有“宽度”,这称为“Inception结构”。Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果。GoogLeNet的特征就是将这个Inception结构用作一个构件(构成元素)。此外,在GoogLeNet中,很多地方都使用了大小为1 × 1的滤波器的卷积层。这个1 × 1的卷积运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理。

【ResNet】
ResNet是微软团队开发的网络。它的特征在于具有比以前的网络更深的结构。在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。ResNet中,为了解决这类问题,导入了“快捷结构”(也称为“捷径”或“小路”)。导入这个快捷结构后,就可以随着层的加深而不断提高性能了(当然,层的加深也是有限度的)。通过引入这种快捷结构,即使加深层,也能高效地学习。这是因为,通过快捷结构,反向传播时信号可以无衰减地传递。

因为快捷结构只是原封不动地传递输入数据,所以反向传播时会将来自上游的梯度原封不动地传向下游。这里的重点是不对来自上游的梯度进行任何处理,将其原封不动地传向下游。因此,基于快捷结构,不用担心梯度会变小(或变大),能够向前一层传递“有意义的梯度”。通过这个快捷结构,之前因为加深层而导致的梯度变小的梯度消失问题就有望得到缓解。

ResNet通过以2个卷积层为间隔跳跃式地连接来加深层。另外,根据实验的结果,即便加深到150层以上,识别精度也会持续提高。
实践中经常会灵活应用使用ImageNet这个巨大的数据集学习到的权重数据,这称为迁移学习,将学习完的权重(的一部分)复制到其他神经网络,进行再学习(fine tuning)。比如,准备一个和 VGG相同结构的网络,把学习完的权重作为初始值,以新数据集为对象,进行再学习。迁移学习在手头数据集较少时非常有效。
8.3 深度学习的高速化
大多数深度学习的框架都支持GPU(Graphics Processing Unit),可以高速地处理大量的运算。另外,最近的框架也开始支持多个GPU或多台机器上的分布式学习。
【需要努力解决的问题】
AlexNex中,大多数时间都被耗费在卷积层上。实际上,卷积层的处理时间加起来占GPU整体的95%,占CPU整体的89%!因此,如何高速、高效地进行卷积层中的运算是深度学习的一大课题。卷积层中进行的运算可以追溯至乘积累加运算。因此,深度学习的高速化的主要课题就变成了如何高速、高效地进
行大量的乘积累加运算。
【基于GPU的高速化】
GPU原本是作为图像专用的显卡使用的,但最近不仅用于图像处理,也用于通用的数值计算。由于GPU可以高速地进行并行数值计算,因此GPU计算的目标就是将这种压倒性的计算能力用于各种用途。所谓GPU计算,是指基于GPU进行通用的数值计算的操作。
深度学习中需要进行大量的乘积累加运算(或者大型矩阵的乘积运算)。这种大量的并行运算正是GPU所擅长的(反过来说,CPU比较擅长连续的、复杂的计算)。因此,与使用单个CPU相比,使用GPU进行深度学习的运算可以达到惊人的高速化。
通过im2col可以将卷积层进行的运算转换为大型矩阵的乘积。这个im2col方式的实现对 GPU来说是非常方便的实现方式。这是因为,相比按小规模的单位进行计算,GPU更擅长计算大规模的汇总好的数据。也就是说,通过基于im2col以大型矩阵的乘积的方式汇总计算,更容易发挥出 GPU的能力。
【分布式学习】
为了进一步提高深度学习所需的计算的速度,可以考虑在多个GPU或者多台机器上进行分布式计算。现在的深度学习框架中,出现了好几个支持多GPU或者多机器的分布式学习的框架。其中,Google的TensorFlow、微软的CNTK(Computational Network Toolki)在开发过程中高度重视分布式学习。以大型数据中心的低延迟·高吞吐网络作为支撑,基于这些框架的分布式学习呈现出惊人的效果。
关于分布式学习,“如何进行分布式计算”是一个非常难的课题。它包含了机器间的通信、数据的同步等多个无法轻易解决的问题。可以将这些难题都交给TensorFlow等优秀的框架。
【运算精度的位数缩减】
在深度学习的高速化中,除了计算量之外,内存容量、总线带宽等也有可能成为瓶颈。关于内存容量,需要考虑将大量的权重参数或中间数据放在内存中。关于总线带宽,当流经GPU(或者CPU)总线的数据超过某个限制时,就会成为瓶颈。考虑到这些情况,我们希望尽可能减少流经网络的数据的位数。
关于深度学习的位数缩减,到目前为止已有若干研究。最近有人提出了用1位来表示权重和中间数据的Binarized Neural Networks方法。为了实现深度学习的高速化,位数缩减是今后必须关注的一个课题,特别是在面向嵌入式应用程序中使用深度学习时,位数缩减非常重要。
8.4 深度学习的应用案例
【物体检测】
物体检测是从图像中确定物体的位置,并进行分类的问题。如图8-17所示,要从图像中确定物体的种类和物体的位置。物体检测是比物体识别更难的问题。之前介绍的物体识别是以整个图像为对象的,但是物体检测需要从图像中确定类别的位置,而且还有可能存在多个物体。

 首先(以某种方法)找出形似物体的区域,然后对提取出的区域应用CNN进行分类。
首先(以某种方法)找出形似物体的区域,然后对提取出的区域应用CNN进行分类。
【图像分割】
图像分割是指在像素水平上对图像进行分类。如图8-19所示,使用以像素为单位对各个对象分别着色的监督数据进行学习。然后,在推理时,对输入图像的所有像素进行分类。要基于神经网络进行图像分割,最简单的方法是以所有像素为对象,对每个像素执行推理处理。卷积运算中会发生重复计算很多区域的无意义的计算。

FCN(Fully Convolutional Network)的方法通过一次forward处理,对所有像素进行分类(图
8-20)。FCN的字面意思是“全部由卷积层构成的网络”。相对于一般的CNN包含全连接层,FCN将全连接层替换成发挥相同作用的卷积层。在物体识别中使用的网络的全连接层中,中间数据的空间容量被作为排成一列的节点进行处理,而只由卷积层构成的网络中,空间容量可以保持原样直到最后的输出。

【图像标题的生成】

一个基于深度学习生成图像标题的代表性方法是被称为NIC(NeuralImage Caption)的模型。NIC由深层的CNN和处理自然语言的RNN(Recurrent Neural Network)构成。RNN是呈递归式连接的网络,经常被用于自然语言、时间序列数据等连续性的数据上。NIC基于CNN从图像中提取特征,并将这个特征传给RNN。RNN以CNN提取出的特征为初始值,递归地生成文本。将组合图像和自然语言等多种信息进行的处理称为多模态处理。

RNN的R表示Recurrent(递归的)。这个递归指的是神经网络的递归的网络结构。根据这个递归结构,神经网络会受到之前生成的信息的影响(换句话说,会记忆过去的信息),这是 RNN的特征。
8.5 深度学习的未来
【图像风格变换】
在学习过程中使网络的中间数据近似内容图像的中间数据,这样一来,就可以使输入图像近似内容图像的形状。此外,为了从风格图像中吸收风格,导入了风格矩阵的概念。通过在学习过程中减小风格矩
阵的偏差,就可以使输入图像接近梵高的风格。

【图像的生成】
图8-24中展示的图像是基 于 DCGAN(Deep Convolutional Generative Adversarial Network)方
法生成的卧室图像的例子。DCGAN生成的图像是谁都没有见过的图像(学习数据中没有的图像),是从零生成的新图像。能画出以假乱真的图像的DCGAN会将图像的生成过程模型化。使用大量图像(比如,印有卧室的大量图像)训练这个模型,学习结束后,使用这个模型,就可以生成新的图像。

之前我们见到的机器学习问题都是被称为监督学习(supervised learning)的问题。这类问题就像手写数字识别一样,使用的是图像数据和教师标签成对给出的数据集。不过这里讨论的问题,并没有给出监督数据,只给了大量的图像(图像的集合),这样的问题称为无监督学习(unsupervised learning)。无监督学习虽然是很早之前就开始研究的领域(Deep Belief Network、Deep Boltzmann Machine等很有名),但最近似乎并不是很活跃。今后,随着使用深度学习的DCGAN等方法受到关注,无监督学习有望得到进一步发展。
【自动驾驶】

【Deep Q-Network(强化学习)】
计算机在摸索试验的过程中自主学习,这称为强化学习(reinforcement learning)。强化学习和有“教师”在身边教的“监督学习”有所不同。强化学习的基本框架是,代理(Agent)根据环境选择行动,然后通过这个行动改变环境。根据环境的变化,代理获得某种报酬。强化学习的目的是决定代理的行动方针,以获得更好的报酬(图8-26)。

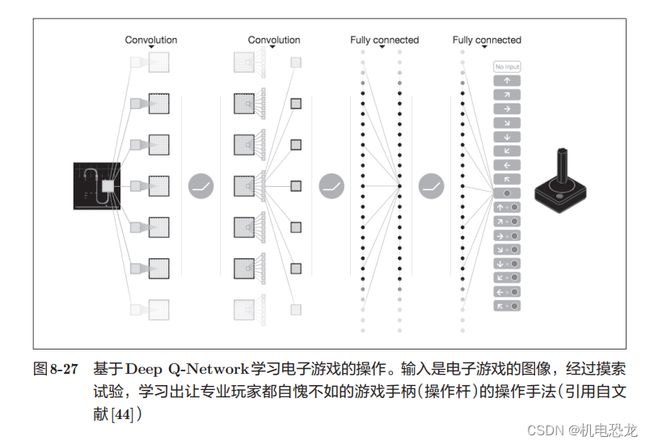
8.6 小结
