python:就多维列表和数组之间新增(append),MinMaxScaler转化(transform)和逆转化(inverse_transform)的小tips
近期在写自己科创的代码时,突然有一个小问题困住了我,花了好长时间才解决了这个问题,花点时间在这里记录下来,以防后面时间长了忘记。
我在训练一个模型切分训练集的时候,取数据窗口长度为60,所需要的每单个数据元为5*1的数组,x_train为59个数据元的集合,y_train为窗口最后一个数据元,想要保持的数据格式为:x_train的dim,也就是维数为5,数据长度为59。为了保持每个数据元的割裂,我用train_data1=train_data.tolist()这个命令将我的数据集变成了列表。
In[1]:train_data1[:10]
Out[2]:
[[0.8553037388216707,
0.675346604903694,
0.8447580774898489,
0.6991041643000897],
[0.5886998139314192,
0.6684080123006382,
0.6753978417127304,
0.612303647730045],
[0.6628480452995626,
0.7285871314151744,
0.703418092547667,
0.6935364218111242],
[0.6773272787519096,
0.5363182189403202,
0.6605314637614943,
0.5520136982167441],
[0.5871108784436903,
0.586171848489129,
0.6008423369218985,
0.5037563860771432],
[0.5378805435790657,
0.44840015392034127,
0.5451509321046841,
0.47089541942774105],
[0.45498767712297594,
0.4533985059335639,
0.4497919897555356,
0.43962675516171323],
[0.4667109780462604,
0.39392160778564156,
0.4589224007567516,
0.4157683897635649],
[0.33569203199046393,
0.4410491587149279,
0.421340596263859,
0.348921949131868],
[0.42509827911071385,
0.3544454240359274,
0.41282633316387907,
0.362264739776327]]
但是当我用append命令时却出现报错 AttributeError: 'numpy.ndarray' object has no attribute 'append'
在查询了append的官方文档后,我发现:
a.append(b):是将b原封不动的追加到a的末尾上,会改变a的值,其中,b可为列表、元组、字符串、一串数/字符/字符串
如果我用多个数据元合并在一起使用append函数自然会出现数据集不是想要的结构或者报错的情况。我想到,那如果我用一个temp空变量数组先存储59个数据元,再把列表转换成数组的方式使用append函数加入到x_train数组中,这样的方法是否可行。实验如下:
for j in range(needlen,training_data_len):
for z in range(j-needlen,j-1):
temp_train.append(train_data1[z])
temp1_train=np.array(temp_train)
x_train.append(temp1_train)
temp_train=[]
y_train.append(train_data[j,1])
x_train,y_train=np.array(x_train),np.array(y_train)
得到的数据结构为:
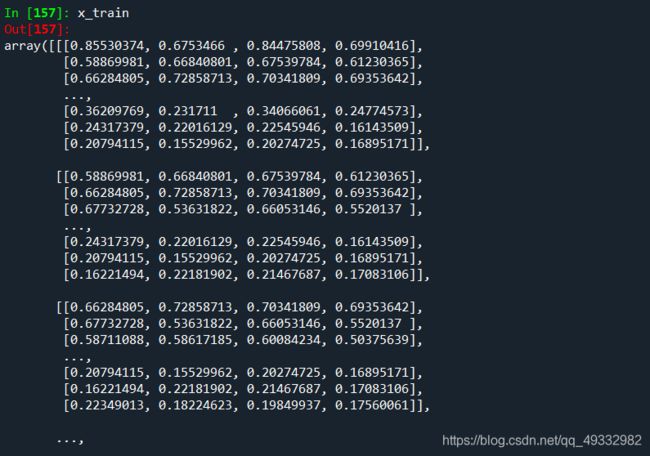 符合所训练模型的input_shape()。
符合所训练模型的input_shape()。
对于机器学习中,训练集的数据需要归一化处理,而且不能失去其中特征,所以采用MinMaxScaler函数。导入:
from sklearn.preprocessing import MinMaxScaler
需要注意的是,对于不同的数据列做归一化处理后,如果要逆转化的话,所逆转化的数据列数一定要是和之前转化的列数相同。实操如下:
scaler=MinMaxScaler(feature_range=(0,1))
scaled_data=scaler.fit_transform(dataset)
scaler1=MinMaxScaler(feature_range=(0,1))
scaled_data1=scaler1.fit_transform(dataset1)
pred=model.predict(x_test)
predtion=scaler1.inverse_transform(pred)
#如果用scaler.inverse_transform来则会显示如下报错:
#non-broadcastable output operand with shape (407,1) doesn't match the broadcast shape (407,4)
可以把scaler和scaler1理解成一个函数,不同的参数调整使其归一化的原理使得他不可以相互混用。
另对于model=Sequential()加点小说明:在使用model.add加入两层以上网络层后,第一层要加上return_sequences=True命令,这样可以保证数据在层数之间的正确传递。