Python深度使用指南
python常见的编辑器介绍
IDLE:是一个Python shell,shell指“外壳”,即通过键入文本与程序交互的途径。
Jupyter notebook:是一种 Web 应用,能让用户将说明文本、数学方程、代码和可视化内容全部组合到一个易于共享的文档中。
Jupyter notebook命令模式快捷键(按 Esc 键开启):
| Enter |
转入编辑模式 |
|
| Shift-Enter |
运行本单元,选中下个单元 |
新单元默认为命令模式 |
| Ctrl-Enter |
运行本单元 |
|
| Alt-Enter |
运行本单元,在其下插入新单元 |
新单元默认为编辑模式 |
| Y |
单元转入代码状态 |
|
| M |
单元转入 markdown 状态 |
|
| R |
单元转入 raw 状态 |
|
| 1 |
设定 1 级标题 |
仅在 markdown 状态下时建议使用标题相关快捷键,如果单元处于其他状态,则会强制切换到 markdown 状态 |
| 2 |
设定 2 级标题 |
|
| 3 |
设定 3 级标题 |
|
| 4 |
设定 4 级标题 |
|
| 5 |
设定 5 级标题 |
|
| 6 |
设定 6 级标题 |
|
| Up |
选中上方单元 |
|
| K |
选中上方单元 |
|
| Down |
选中下方单元 |
|
| J |
选中下方单元 |
|
| Shift-K |
连续选择上方单元 |
|
| Shift-J |
连续选择下方单元 |
|
| A |
在上方插入新单元 |
|
| B |
在下方插入新单元 |
|
| X |
剪切选中的单元 |
|
| C |
复制选中的单元 |
|
| Shift-V |
粘贴到上方单元 |
|
| V |
粘贴到下方单元 |
|
| Z |
恢复删除的最后一个单元 |
|
| D,D |
删除选中的单元 |
连续按两个 D 键 |
| Shift-M |
合并选中的单元 |
|
| Ctrl-S |
保存当前 NoteBook |
|
| S |
保存当前 NoteBook |
|
| L |
开关行号 |
编辑框的行号是可以开启和关闭的 |
| O |
转换输出 |
|
| Shift-O |
转换输出滚动 |
|
| Esc |
关闭页面 |
|
| Q |
关闭页面 |
|
| H |
显示快捷键帮助 |
|
| I,I |
中断 NoteBook 内核 |
|
| 0,0 |
重启 NoteBook 内核 |
|
| Shift |
忽略 |
|
| Shift-Space |
向上滚动 |
|
| Space |
向下滚动 |
Jupyter notebook编辑模式快捷键( 按 Enter 键启动):
| Tab |
代码补全或缩进 |
|
| Shift-Tab |
提示 |
输出帮助信息,部分函数、类、方法等会显示其定义原型,如果在其后加 ? 再运行会显示更加详细的帮助 |
| Ctrl-] |
缩进 |
向右缩进 |
| Ctrl-[ |
解除缩进 |
向左缩进 |
| Ctrl-A |
全选 |
|
| Ctrl-Z |
撤销 |
|
| Ctrl-Shift-Z |
重做 |
|
| Ctrl-Y |
重做 |
|
| Ctrl-Home |
跳到单元开头 |
|
| Ctrl-Up |
跳到单元开头 |
|
| Ctrl-End |
跳到单元末尾 |
|
| Ctrl-Down |
跳到单元末尾 |
|
| Ctrl-Left |
跳到左边一个字首 |
|
| Ctrl-Right |
跳到右边一个字首 |
|
| Ctrl-Backspace |
删除前面一个字 |
|
| Ctrl-Delete |
删除后面一个字 |
|
| Esc |
切换到命令模式 |
|
| Ctrl-M |
切换到命令模式 |
|
| Shift-Enter |
运行本单元,选中下一单元 |
新单元默认为命令模式 |
| Ctrl-Enter |
运行本单元 |
|
| Alt-Enter |
运行本单元,在下面插入一单元 |
新单元默认为编辑模式 |
| Ctrl-Shift-- |
分割单元 |
按光标所在行进行分割 |
| Ctrl-Shift-Subtract |
分割单元 |
|
| Ctrl-S |
保存当前 NoteBook |
|
| Shift |
忽略 |
|
| Up |
光标上移或转入上一单元 |
|
| Down |
光标下移或转入下一单元 |
|
| Ctrl-/ |
注释整行/撤销注释 |
仅代码状态有效 |
Pycharm:
VSCode:
print打印
print("I love you.")#字符串用""引起来
print(5 + 3)#运算符
print("well water" + "river")#拼接符
print("I love you." * 8)#会打印8次
print("I love you.\n" * 8)#换行
'''
print("a" + 5)#字符+数值没有意义
print(abc)#字符或字符串需要加引号
'''
print("abcd",end = " ")#print打印完会自动换行,注意end可以实现不换行继续执行,用""内的内容代替换行转义字符
常用转义字符:
\\:反斜杠(\)
\':单引号(')
\":双引号(")
\a:响铃
\b:退格
\n:换行
\t:水平制表
\v:垂直制表
\r:回车
\f:换页
\ooo:ooo为八进制数
\xhh:hh为十六进制数
str1 = 'C:\now'
str2 = 'C:\\now'#转义字符\
print(str1,str2)
str = r'C:\programFiles\Intel'#在所有\后加上\
print(str)长字符串
str = """aaa
bbb
ccc
"""
print(str)random模块
import random
random.randint(1,10)#产生一个1~10之间的随机数
random.getstate()#存储随机数内部结构
random.setstate()#读取随机数内部结构比较运算符
>,>=,
==,!=
is,is not 判断两对象id相等或不等
条件分支语法
if 条件:
条件为真执行的操作
else:
条件为假执行的操作
循环语法
while 条件:
条件为真时执行的操作
先运行比较运算符,再执行逻辑运算符
逻辑运算符and,or,not是短路逻辑(当第一个无法确定结果,才会执行第二个运算)
3 > 2 or 1 > 2#左边为true,且是或运算,有一个为真就可判断为真了,or右边不再运算False类型有:
0,0.0,0j(复数),Decimal(0),'',(),[],{},set(),range(),括号内可以是空格或无字符
写语句格式
print('a');print('b')#多条语句写一行
3 > 4 and \#一条语句写多行
1 < 2变量名与数据类型
变量名不能数字开头,可以用_或字母开头
整数:1,2,3
浮点数:0.1,0.2
复数:1+2j
'''由于python与C采用相同的IEEE754标准,于是浮点数会有误差
'''
#消除浮点数的误差
import decimal
a = decimal.Decimal('0.1')
print(a)
#复数
X = 1 + 2j
print(X.real)#取实数位
print(X.imag)#取虚数位
abs(X)#指复数的模:根号下(1^2 + 2^2 )= 2.2306
a = 5
b = 2
c = a//b#X/Y后的值向下取整,5/2 = 2.5,向下取值,2
print(c)
d = pow(2,3,5)#2 ** 3 % 5 = 3
print(d)e记法:ae-b=a*10^(-b)
布尔:True * False:1 * 0 = 0
类型转换:
整型int(),字符串型str(),浮点型float()
获得类型信息:
type(变量名):type(a)
type(常量):type(10)
判断数据类型:
isinstance(变量,数据类型)#若变量为该类型,返回True,否则返回False
isinstance(a,str)
若s为字符串
s = "abc123ABC"
s.isalnum()#s中所有字符都是字母或数字,返回True
s.isalpha()#所有字符都是字母,返回True
s.isdigit()#所有字符都是数字,返回True
s.islower()#所有字符都是小写字母,返回True
s.isupper()#所有字符都是大写字母,返回True
s.istitle()#所有单词都是首字母大写,返回True
s.isspace()#所有字符都是空格,返回True算数操作符
+,-,*,/,%,**,//:加减乘除,求余,乘方,地板除
a = a + 1(a += 1):累积运算符
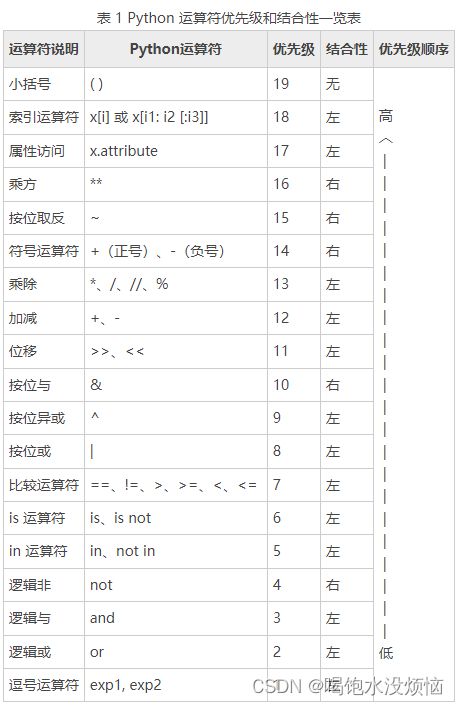
优先级:
** > +,-正负号 > *,/,// > +,-加减 > 比较运算符,=,==,!= >逻辑运算符not > and > or
三元运算符:
small = x if x < y else y
断言(assert)
assert 3 > 4#若为False,会抛出异常AssertionError
assert 3 > 4,'AssertionError is {}'.format('>')
# 当3 > 4,将会抛出异常"AssertionError is >"列表
1列表与遍历列表
member = ["123",'1']#列表可以存放各种元素
for each in member:#遍历列表中的元素
print(each,len(each))
for i in range(1,10,2):#range(1,10,2)生成数组,1~10,步长为2的数组
if i % 2 != 0:
print(i)
continue#终止本次循环,跳转至下一次
i += 2
print(i)2列表常用函数
mix = [1,0.1,"123"]#创建列表
mix.append("456")#添加元素
mix.extend(["789",10])#扩展列表
print(mix,len(mix))
mix.insert(0,'牡丹')#按索引插入元素
print(mix,len(mix))
mix.remove(1)#移除指定元素
print(mix,len(mix))
del mix[1]#删除指定索引处元素
print(mix,len(mix))
mix.pop(0)#删除取出的索引处的元素
print(mix,len(mix))
del mix#删除整个列表3列表切片
mix = [1,2,3,4,5,6,7,8,9,10]
print(mix[1:3])#切片列表[2,3]
print(mix[:3])#切片列表[1,2,3]
print(mix[1:])#切片列表[2,3,4,5,6,7,8,9,10]
print(mix[:])#切片列表[1,2,3,4,5,6,7,8,9,10]
print(mix[::-1])#切片列表[10,9,8,7,6,5,4,3,2,1]
print(mix[::2])#切片列表[1,3,5,7,9]
print(mix[-4:-1])#切片列表[7,8,9]4列表比较
list1 = [123,456]
list2 = [456,123]
print(list1 + list2)#拼接
list1 *= 3#元素重复
print(list1)
list1 > list2#比较大小就是按顺序比较,直到第一个不相等的元素出现,比出的大小就是列表的大小5列表翻转与传递
list2 = [1,2,3,4,5,6,7,8,9]
list.reverse(list2)#翻转列表
print(list2)
list2.sort()#让列表从小到大排序
print(list2)
list2.sort(reverse = True)#让列表从大到小排序
print(list2)
list2 = list2[::-1]#代表从后向前取值,每次步进值为1,注意要赋值才行哦,这不是函数
print(list2)
list3 = list2[:]#对list2进行拷贝,不会随之变化而变化
list3 = list2#只是换个名字,list2改变,list3就会随之改变元组
tuple1 = (1,2,3,4,5,6)#元组不能修改元素哦
tuple2 = 6,7,8,9,10#括号不重要,重要的是逗号
tuple3 = 8 * (8,)#(8,)也是元组哦
print(tuple1,tuple2,tuple3)
print(tuple1 + tuple2 + tuple3)#元组可以拼接哦
print(tuple1[:5] + (6,) + tuple2[1:])#元组也可以切片哦,这就是元组的元素插入
del tuple1#可以删除元组字符串
1字符串常见函数
str1 = '''xi AOx ie\nxi AOx ie\nxi AOx ie'''
print(str1.capitalize())#首字母大写函数
print(str1.casefold())#大写字母变小写函数
str1.center(10)#将字符串居中,左右用空格填充
str1.count('xi',1,4)#返回子串出现次数
str1.encode(encoding = 'utf-8',errors = 'strict')#以指定编码形式对字符串进行编码
str1.endswith('ie',1,4)#检查是否以某字符串结尾,并且以指定索引为范围,索引参数是非必须的
str1.startswith('ie',1,4)#检查是否以某字符串开头
str1.expandtabs(tabsize=1)#把\t转换成指定的空格符,空格符数量可以控制
str1.find('i',1,4)#返回字符的索引,若不存在该字符返回-1
print(str1.index('O',1,5))#与find功能一样,但是不存在该字符时会抛出异常,可以指定索引范围1~4
str1.rfind('i',1,7)#从右边开始的find
str1.rindex('i',1,7)#从右边开始的index
str1.isalnum()#所有字符都是字母或数字返回True
str1.isalpha()#所有字符都是字母返回True
str1.isdecimal()#所有字符都是十进制数字返回True
str1.isdigit()#所有字符都是数字返回True
str1.islower()#所有字符都是小写字母返回True
str1.isupper()#所有字符都是小写字母返回True
str1.isnumeric()#所有字符都是数字字符返回True
str1.isspace()#所有字符都是空格返回True
str1.istitle()#所有单词都是首字母大写,其余字母小写返回True
str1.join("aaaaa")#在被插入的字符串的每两个字符之间插入str1字符串
str1.ljust(10)#返回一个左对齐的字符串,右边填充上10个空格
str1.rjust(10)#返回一个右对齐的字符串,左边填充上10个空格
str1.lower()#转换大写字母为小写
str1.upper()#转换小写字母为大写
str1.lstrip()#去除左边所有空格
str1.lstrip()#去除末尾空格
str1.strip()#去除前后空格
str1.partition("\t")#字符串切分,分成"\t"之前的部分,"\t"本身,"\t"之后的部分,返回形式(pre_sub,sub,after_sub)
str1.replace('x','j',1)#将字符串中的'x'换成'j',并指定替换1次
str1.rpartition("\t")#从右边开始的partition,但返回格式与partiton一样,只是可能时间复杂度不同
str1.split(sep = 'i',maxsplit = 2)#以sep参数为分隔符,传入None表示默认空格为分隔符,进行切片,从左开始进行切片,最大切片次数为maxsplit的值,返回的是列表哦
str1.splitlines()#按换行符"\n"进行切片
str1.swapcase()#大小写翻转
str1.title()#返回成首字母大写其余字母小写的形式
str1.translate(str.maketrans('x','j'))#translate()根据()里的规则进行字符转换,其中maketrans()可以用来定制这种规则
str1.zfill(50)#返回长度为50的字符串,原字符串右对齐,前面用0填充2字符串的格式化
"{0} love {1}.{2}".format("I","Fishc","com")#通过format函数将字符串传给前面的位置
"{a} love {b}.{c}".format(a = "I",b = "Fishc",c = "com")#效果与上面相同
"{0:.1f}{1}".format(27.658,"GB")#{0:.1f}中0:指格式化参数的开始,.1指四舍五入保留1位小数,f是浮点数的意思
'''
%c 格式化字符及其ASCII码
%s 格式化字符串
%d 格式化整数
%o 格式化无符号八进制数
%x 格式化无符号十六进制数
%f 格式化浮点数,可指定精度
%e 科学计数法格式化浮点数
%E 与%e同
%g 根据值的大小决定使用%f或%e
%G 同%g
m.n m是显示的最小总宽度,n是小数点后的位数
- 用于左对齐
+ 在正数前显示加号
# 在八进制数前显示('0'),在十六进制数前显示'0X'或'0x'
0 显示的数字前填充'0'取代空格
'''
'%c'%97#看ASCII码,是'a',因此返回'a'
"%c%c%c"%(97,98,99)#返回'abc'
'%s%s%s'%('a','b','c')#返回'abc'
'%o'%10#返回'12'
'%5.1f'%27.658#返回' 27.7',共5个字符长,不足的部分左填充空格补齐
'%.2e'%27.658#返回'2.77e+01'
'%10d'%5#返回' 5'
'%-10d'%5#返回'5 ',左对齐啦
'%+10d'%5#返回' +5'
'%010d'%5#返回'0000000005',用0太填充啦序列:列表、元组、字符串
b = 'I love you'
list(b)#返回['I', ' ', 'l', 'o', 'v', 'e', ' ', 'y', 'o', 'u']
c = (1,3,5,7,9)
c = list(c)#返回[1, 3, 5, 7, 9]
c = tuple(c)#类型转换为元组(1, 3, 5, 7, 9)
str(c)#类型转换为字符串,返回'(1, 3, 5, 7, 9)'
max(b)#按ASCII码检索最大字符,元组和列表一样适用,但是不能识别不同数据类型组成的序列,比如('I',1)
tuple1 = (2,5,4.5)
sum(tuple1)#对序列求和
sorted(tuple1)#对元组进行排序,只能用于同类型数据的排序
list(reversed(tuple1))#对元组进行从大到小排序,也只能用于同类型数据的排序
list(enumerate(tuple1))#返回[(索引,数值),(索引,数值),...]
x = [1,2,3,4]
y = [5,6,7]
list(zip(x,y))#一一对应的合并操作,返回[(1, 5), (2, 6), (3, 7)]字典(又称哈希表或关联数组)与内置函数enumerate和zip
字典含有键和值,键是唯一的,值是可重复的,字典其实就是键值对的集合dict = {'a' : 'abc',1 : '123',...}
字典的值可以是任意的python对象,但是键必须是不可变的对象(基本数据类型和只包含不可变对象的元组)
#enumerate函数
some_list = ['foo','bar','baz']#给定一个列表
mapping = {}#创建一个空字典
for i,v in enumerate(some_list):# 将序列代入这个循环迭代器enumerate返回的是元组(i,v)
mapping[v] = i#利用这个元组可以构建出这个字典
mapping
#zip函数
seq1 = ['foo','bar','baz']
seq2 = ['one','two','three']
seq3 = [False,True]
zipped = zip(seq1,seq2,seq3)#一一对应地拼接成('foo', 'one', False), ('bar', 'two', True),并且长度保持在最短序列的长度
list(zipped)
for i,(a,b) in enumerate(zip(seq1,seq2)):#显然返回元组(i,a,b)的序列
print('{0}:{1},{2}'.format(i,a,b))
pitchers = [('Nolan','Ryan'),('Roger','Clemens'),('Schilling','Curt')]
first_names,last_names = zip(*pitchers)# *指的是收集参数,也就是传入的序列参数,并且将序列的每一个元素看作一个实参,进行该函数的运算
pitchers_tran = [first_names,last_names]# 这就实现了列转行的功能
print(pitchers_tran)字典:
# 创建字典
empty_dict = {}
d1 = {'a' : 'some value','b' : [1,2,3,4]}
d1[7] = 'an integer'# 按照键插入元素
d1['b']#访问元素
'b' in d1#检查是否含有某个键
d1[5] = 'some value'
d1['dummy'] = 'another value'
del d1[5]#按照键删除字典元素
ret = d1.pop('dummy')#用pop方法按照键删除字典元素,且可以接到删除的元素
print(ret)#看看接到的元素是谁
key_list = list(d1.keys())#提供keys,键的迭代器
value_list = list(d1.values())#提供values,值的迭代器
d1.update({'b' : 'foo','c' : 12})#提供合并字典的方法update,对于相同的键,它的值会被覆盖
mapping = {}
for key,value in zip(key_list,value_list):# 用有序的键列表与值列表生成字典
mapping[key] = value
mapping
#有效的字典键类型,用hash化进行判断是否有效
d = {}
d[tuple([1,2,3])] = 5#因为列表[1,2,3]不是不可变对象,所以要先转换成元组,只要该元组内部元素都可哈希化,该元组也可以哈希化
print(d)
hash(tuple([1,2,3]))#检验哈希化
集合
集合可以看成一种特殊的只有键没有值的字典
#集合的创建
set([2,2,2,1,3,3])
{2,2,2,1,3,3}
a = {1,2,3,4,5}
b = {3,4,5,6,7,8}
a.union(b)#取并集
a | b#也是取并集的意思
a.intersection(b)#取交集
a & b#也是取交集的意思
c = a.copy()#产生副本
c |= b#将c设置为c与b的并集
d = a.copy()
d &= b#将d设置为d与b的交集
my_data = [1,2,3,4]
my_set = {tuple(my_data)}#集合中的元素不能是列表,要转化成元组
a_set = {1,2,3,4,5}
{1,2,3}.issubset(a_set)#检查是否为子集(属于)
a_set.issuperset({1,2,3})#检查是否为超集(包含)
列表、字典、集合三大推导式
#列表推导式
result = []
for x in strings:
if len(x) > 2:
result.append(x.upper())
print(result)
'''上下两种方式是等价的'''
strings = ['a','as','bat','car','dove','python']
[x.upper() for x in strings if len(x) > 2]
#dict_comp = {key-exper : value-exper for value in collection if condition}
#用字典推导式创建一个字典
loc_mapping = {index * 2 : len(val) for index,val in enumerate(strings) if index > 0}
print(loc_mapping)
'''上下两种方式功能一致'''
loc_mapping2 = {}
for index,val in enumerate(strings):
if index > 0:
loc_mapping2[index * 2] = len(val)
#set_comp = {exper for value in collection if condition}
#用集合推导式来获取列表中字符串的长度
unique_lengths = {len(x) for x in strings}#如果不需要限制条件,可以不加if condition
#更一般的,我们结合函数-序列迭代器map来用
set(map(len,strings))#map(fun,iterator)指的是让iterator中每个元素都进行一遍fun函数的运算,再转换成集合set()类型
numpy.array数组
1.numpy.array数组的创建或转换
numpy.array(object,dtype=None,copy=True,order=None,subok=False,ndmin=0)
object–数组或嵌套的数列
dtype–数组元素的数据类型,可选
copy–对象是否需要复制,可选
order–创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
subok–默认返回一个与基类类型一致的数组
ndmin–指定生成数组的最小维度
2.numpy.array强大的广播功能
其广播功能使得它的很多函数具备让标量与张量进行运算的能力
函数
1函数文档
def fun(name):
'函数中的name叫形参'#函数文档,用来介绍函数的作用和注意事项
print(name)
fun.__doc__#查看函数文档
help(fun)#功能与上面相同
fun("阿大")#可以直接按照顺序传参
fun(name = "阿大")#也可以指定形参进行传参2可变参数
def test(*params,exp):#可变参数,可以传入多个参数
print("参数长度:",len(params))
print("第二个参数是:",params[1])
print(exp)
test(1,"小黄",3.14,5,exp = 8)#注意在使用可变参数时,若有其他形参,那么调用时必须用关键字参数,否则会报错3改变可变参数的值
def append_element(*params,element):#写一个函数,专门用来修改可变参数的值
params = params + element
return params
data = append_element(1,2,element = (3,))#可变参数可以传入元组,再以形参作为元组进行拼接,注意任何形式的参数都要转化为元组
data阶段练习
1.尝试写代码实现以下截图功能:
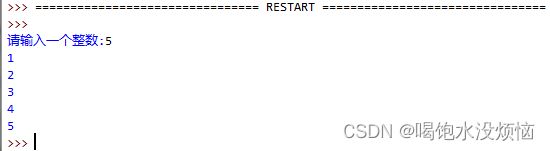
代码如下:
temp = input("输入一个整数:")
value = int(temp)
num = 1
while value >= 1:
print(num)
value -= 1
num += 12.尝试写代码实现以下截图功能:

代码如下:
temp = input("输入一个整数:")
value = int(temp)
while value >= 1:
print(" " * value + "*" * value)
value -= 13. 使用 int() 将小数转换为整数,结果是向上取整还是向下取整呢?你有什么办法使得 int() 按照“四舍五入”的方式取整吗?
小数取整会采用比较暴力的截断方式,即向下取整。(注:5.5 向上取整为 6,向下取整为 5)但那是对于正数来说……对于负数则刚好相反 —— 是向上取整。
5.4 “四舍五入”结果为:5,int(5.4+0.5) == 5;
5.6 “四舍五入”结果为:6,int(5.6+0.5) == 6大家看明白了吗?
4. Python3 可以给变量命名中文名,知道为什么吗?
Pyhton3 源码文件默认使用utf-8编码(支持中文),这就使得以下代码是合法的:
>>> 阿大 = '我爱你'
>>> print(阿大)
>>> 我爱你
5. 你听说过成员资格运算符吗?
Python 有一个成员资格运算符:in,用于检查一个值是否在序列中,如果在序列中返回 True,否则返回 False。
name = '阿大'
'大' in name
True
'胖大' in name
False6. 使用 if elif else 在大多数情况下效率要比全部使用 if 要高,但根据一般的统计规律,一个班的成绩一般服从正态分布,也就是说平均成绩一般集中在 70~80 分之间,因此根据统计规律,我们还可以改进下程序以提高效率。
score = int(input('请输入一个分数:'))
if 80 > score >= 60:
print('C')
elif 90 > score >= 80:
print('B')
elif 60 > score >= 0:
print('D')
elif 100 >= score >= 90:
print('A')
else:
print('输入错误!')7.请将以下代码修改为三元操作符实现:
x, y, z = 6, 5, 4
if x < y:
small = x
if z < small:
small = z
elif y < z:
small = y
else:
small = z 代码如下:
x,y,z = 6,5,4
small = x if (x < y and x < z) else ( y if y < z else z)8. 设计一个验证用户密码程序,用户只有三次机会输入错误,不过如果用户输入的内容中包含"*"则不计算在内。
i = 3
passwords = 'zxf2ld'
subjective = input('请输入密码:')
while i >= 0:
if subjective == passwords:
print('密码正确,进入程序...')
break
elif '*' in subjective:
print('密码不能含有”*“!','您还有',i,'次机会!',end='')
subjective = input('请重新输入:')
continue
elif i > 0:
print('密码输入错误!','您还有',i,'次机会!',end='')
subjective = input('请重新输入:')
i -= 1
elif i == 0:
print('次数用尽,进入程序失败...')
i -= 19. 什么情况下我们要使循环永远为真?
while Ture:
循环体
比如用于游戏实现,因为游戏只要运行着,就需要时刻接收用户输入,因此使用永远为真确保游戏“在线”。操作系统也是同样的道理,时刻待命,操作系统永远为真的这个循环叫做消息循环。另外,许多通讯服务器的客户端/服务器系统也是通过这样的原理来工作的。 所以永远为“真”虽然是“死循环”,但不一定是坏事,再说了,我们可以随时用 break 来跳出循环!
10. 【学会提高代码的效率】你的觉得以下代码效率方面怎样?有没有办法可以大幅度改进(仍然使用while)?
i = 0
string = 'ILoveYou'
while i < len(string)):
print(i)
i += 1这段代码之所以“效率比较低”是因为每次循环都需要调用一次 len() 函数(我们还没有学到函数的概念,可以解释下:就像你打游戏打得正HIGH的时候,老妈让你去买盐......你有两种选择,一次买一包,一天去买五次,或者一次性买五包回来,老妈要就直接给她。)
i = 0
string = 'ILoveFishC.com'
length = len(string)
while i < length:
print(i)
i += 1 11.什么是P = NP?问题
(1)什么是P问题?
能在多项式时间内求出问题的解的问题,如:o(1),o(logn),o(nlogn),o(n),o(n^2),o(n^3)等
在长度为n的数组中找最大值,就是一个P问题
(2)什么是NP问题
能在多项式时间内确定解是否为原问题的解的问题,q是否为数组a的最大值就是一个NP问题
(3)什么是NP完全问题
能在多项式时间内判断解的正确性,但不能在多项式时间内找出问题的解的问题,它是NP问题但不是P问题
3-SAT问题:给的n个bool值x1,x2,……,xn,给出一个布尔公式:
(x1||x2||x3)&&(!x1||x2||!x3)&&(!x1||!x2||x3) = True?
验证一组x是否满足 = True,o(1)时间就能确定,但计算出各组x则不能在多项式时间内完成。
x1 0 0 ……
x2 0 0 ……
。
。
xn 0 1 ……
只能一个个试,总共2^n种可能,时间复杂度为o(2^n),故为NP完全问题。
其实目前还有很多的NP完全问题,那到底是就没有多项式时间复杂度的算法还是没找到这样的算法呢?我们可以总结为P = NP?
若证明出P = NP,则表示NP完全问题能在多项式时间内求出解;若证明出P != NP,则表示根本没有多项式时间复杂度的解法。
12. 三色球问题
有红、黄、蓝三种颜色的球,其中红球 3 个,黄球 3 个,绿球 6 个。先将这 12 个球混合放在一个盒子中,从中任意摸出 8 个球,编程计算摸出球的各种颜色搭配。
print('red\tyellow\tgreen')
for red in range(0, 4):
for yellow in range(0, 4):
for green in range(2, 7):
if red + yellow + green == 8:
# 注意,下边不是字符串拼接,因此不用“+”哦~
print(red, '\t', yellow, '\t', green)输出的是8个球中,red,yellow,green分别的球数。
13. 下边的列表分片操作会打印什么内容?请问 list1[0] 和 list1[0:1] 一样吗?
list1 = [1, 3, 2, 9, 7, 8]
list1[2:5][2, 9, 7](注意不包含 8 哦,因为 5-2==3,只有三个元素);
不一样,list1[0] 返回第0个元素的值,list1[0:1] 返回一个只含有第0个元素的列表。
14. 如果你每次想从列表的末尾取出一个元素,并将这个元素插入到列表的最前边,你会怎么做?
list1 = [1, 3, 2, 9, 7, 8]
list1.insert(0,list1.pop())
print(list1)15. list1[-3:-1] 会不会报错,怎么知道一试居然显示 [9, 7],这是怎么回事呢?

正常索引是从左到右索引,负数索引是从右到左。
16. 在进行分片的时候,我们知道分片的开始和结束位置需要进行指定,但其实还有另外一个隐藏的设置:步长。
1) 之前提到的“简洁”分片操作在这里有效:
list1 = [1, 3, 2, 9, 7, 8]
list1[::2]
[1, 2, 7]2) 步长可以是负数,改变方向(从尾部开始向左走):
list1[::-2]
[8, 9, 3]17. 可以利用分片完成列表的拷贝 list2 = list1[:],那事实上可不可以直接写成 list2 = list1 更加简洁呢? 千万不可以! 好的,为了大家都可以弄明白这个【必须理解】的概念,我啰嗦一下: 上节课我们提到使用分片创建列表的拷贝,例如:
list1 = [1, 3, 2, 9, 7, 8]
list2 = list1[:]
list2
[1, 3, 2, 9, 7, 8]
list3 = list1
list3
[1, 3, 2, 9, 7, 8]看上去貌似一样的,对吧?但事实上呢?我们利用列表的一个小伙伴做下修改,大家看一下差别:
list1.sort()
list1
[1, 2, 3, 7, 8, 9]看到吧,我们的list1已经从小到大排了个序,那list2和list3呢?
list2
[1, 3, 2, 9, 7, 8]可以看到我们使用分片的方式得到的list2很有原则、很有格调,并不会因为list1的改变而改变,这个原理我待会儿跟大家说,我们接着看下list3:
list3
[1, 2, 3, 7, 8, 9]大家可以看到了,真正的汉奸、墙头草是list3,Ta跟着list1改变了,这是为什么呢? 不知道大家还记不记得我们在讲解变量的时候说过,Python的变量就像一个标签,就一个名字而已,贴哪是哪,指哪打哪,呃,我还是给大家伙画个图好。

这下大家应该明白了吧,在为一个固定的东西指定另一个名字的做法,只是向同一个东西增加一个新的标签而已。
18. 与上题不同的一个例子。
old = [1, 2, 3, 4, 5]
new = old
old = [6,7]
print(new)
print(old)会打印:[1, 2, 3, 4, 5] 。
收集参数的应用
def fun(*params,exp):
print('参数长度是:',len(params),exp);
print('第二个参数是:',params[1]);
fun(1,'haha',2,3,5.67,5.44,exp = 8)当收集参数与其他形参同时存在时,除了在定义其他形参时设置默认参数以外,就只能在调用时利用关键字参数索引,否则就会报错,用顺序索引时会被程序误认为是将值赋给前面的收集参数的。
关于全局变量和局部变量
def discounts(price,rate):
final_price = price * rate
old_price = 88
print('修改后的old_price的值是:',old_price)
return final_price
old_price = float(input('请输入原价:'))
rate = float(input('请输入折扣率:'))
new_price = discounts(old_price,rate)
print('修改后old_price的值是:',old_price)
print('打折后价格是:',new_price)
print('打印局部变量值:',final_price) #此处会报错,注意,无法直接输出局部变量的值事实上,只能在定义的函数中才有final_price函数,包括price,rate等形式参数也是这样,除此之外的地方是不生效的,执行完就会将存储它们的栈删除
def discounts(price,rate):
final_price = price * rate
old_price = 88
print('修改后的old_price的值是:',old_price) #此处是修改后的值88
return final_price
old_price = float(input('请输入原价:'))
rate = float(input('请输入折扣率:'))
new_price = discounts(old_price,rate)
print('修改后old_price的值是:',old_price) #但是在这里,取值是原值
print('打折后价格是:',new_price)因为在函数中的所谓修改的全局变量,其实被认为是一个新的与全局变量同名的局部变量而已,所以自然它也就不能改变全局变量的值,但是如果不修改全局变量,全局变量就可以在函数中取值。
用global可以在函数中定义全局变量
内嵌函数:
def fun1():
print('fun1运行。。')
def fun2():
print('fun2运行。。')
fun2()
fun1()套娃函数。。。233333
但是在外部运行fun2()会报错,因为该函数与局部变量一样,只能在函数中运行
闭包:就是把内部函数作为返回结果,并且保留该内部函数的一切引用
def func(a):
print("this is :",a)
def result(x,y):
sum = a*x +y #注意这里的a只能引用不能修改,如果要修改,需要写关键字nonlocal
print("sum is :",sum)
return sum
return result #注意这里返回值是函数名,不是result().把result函数作为返回值给func,闭包的核心
#-------------------------函数调用---------------------------------------
#调用外部函数
func(10) #这里只执行了func里面的第一个print.
print("------------")
f1 = func(10) #相当于把result传递给f1,并且将对func()的形参和局部变量的引用都存储在其中
f1(10,20) #上面的效果等同于func(10)(10,20),对内部函数result进行调用。类似于多重列表的调用
print(f1(10,20)) #打印函数的返回值。
'''
this is : 10
------------
this is : 10
sum is : 120
sum is : 120
120
'''lamda表达式,过滤函数filter,迭代函数map
list(filter(lambda x: x if not x % 3 else None,range(100)))
#用lambda表达式,设置x范围为range(100),将范围内的数通过lambda表达式一个个
#进行运算,能被3整除的数就返回该数本身,不能被3整除的数就返回None,
#filter函数可以过滤掉所有为False的值,因此所有为None的值都会被过滤掉
#剩下的就是能被3整除的数了,通过list将其转化为数组
list(map(lambda x : [(2*x)+1,2*(x+1)],range(5)))
#map函数可以实现迭代的功能,格式:map(function,iterator1,iterator2,...)
#就是将序列一个个通过function函数的方式进行计算
#lambda表达式可以进行快速定义函数,并且在使用完后自动清除
'''
lambda x : [(2*x)+1,2*(x+1)]
相当于一个可自动释放的函数
def fun(x):
return [(2*x)+1,2*(x+1)]
'''
def make_repeat(n):
return lambda s : s * n
double = make_repeat(2)
print(double(8))
print(double('FishC'))
#把闭包与lambda结合起来使用,把lambda定义的函数作为内部函数返回出来递归:函数调用自己
第一:需要自己不断引用自己
第二:需要有办法结束递归
注:递归比迭代慢
汉诺塔问题:
def move(n, a, b, c):
if(n == 1): #当n只有1层时,将盘子从a挪到c上
print(a,"->",c)
return
move(n-1, a, c, b) #利用c柱,将前n-1个盘子从a挪到b上
move(1, a, b, c) #将最后1个盘子从a挪到c上
move(n-1, b, a, c) #将前n-1个盘子从b挪到c上
move(3, "a", "b", "c") #利用b柱,将3个盘子从a挪到c上递归的其他应用:
字典与集合的使用(与元组、列表、字符串等不同,它不是数据类型,它是映射类型)
索引:a[b.index('b_index')] #获取b列表中“b_index”的索引传递给a,来检索对应索引位置的数据
字典:dict1 = {key1:value1,key2:value2} #它是一种映射,代表了key的取值为value的这样一种映射
dict1[key1] #直接根据key可以给出对应value的值
dict1[key1] = value3 #可以直接改变key的值,如果该key不存在,则会自动添加新的key并为它赋值
dict1.keys() #打印出所有的key值
dict1.values() #打印出所有的value值
dict1.get(keys,'没有值') #keys存在且有值,则返回该值,否则返回设定值”没有值“
集合:set1 = {1,2,3,4,5,6} #没有映射关系就是集合,并且不能索引,每个元素只有唯一一个,可以用来去
set1.add(7) #添加元素
set1.remove(6) #移除元素
frozenset() #不可变集合,不能增减元素
异常抛出与处理
try: #异常检测区域
f = open('我为啥是个文件.csv')
print(f.read())
except OSError as reason: #出现该异常就可以抛出
print('出错啦,原因是:'+ str(reason))
else:
print('没有异常') #指除了except的情况以外的时候,执行这里
finally: #无论是否异常都会执行此部分代码
f.close()
raise OSError('异常') #主动抛出的异常else与循环语句联用
while 循环条件:
执行循环
else:
循环结束就执行本语句,循环不结束或失败就不执行本语句
for i in range(10):
执行循环
else:
循环结束就执行本语句,循环不结束或失败就不执行本语句
面向对象编程
python无处不是对象,属性是对象,方法也是对象,而实例对象就是用self表示的。
属性与方法:
class C:
count = 0
def tag(self,x):
self.num = x
c = C()
c.count #count属性的调用
c.tag() #tag方法的调用封装、继承、多态
封装
封装就是一个对象,比如list,它有很多调用的函数,但是我们不知道具体内容,这就是封装
继承
纵向关系的类的继承:
class mylist(list): #class 子类(父类):
pass
list1 = mylist() #子类继承父类的属性与方法
list1.append(1) #可以使用父类的函数
print(list1)一段练习操作:
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0,10)
self.y = r.randint(0,10)
def move(self):
self.x -= 1
print("我的位置是:",self.x,self.y)
class Goldfish(Fish):
pass
class Carp(Fish):
pass
class Salmon(Fish):
pass
class Shark(Fish):
def __init__(self): #重写了__init__方法,就被覆盖掉了
self.hungry = True
def eat(self):
if self.hungry:
print("吃货的梦想就是天天有的吃")
Fish.__init__(self) #调用未绑定的父类方法,就是让子类的实例对象self获得父类带来的__init__方法,不加的话就会被覆盖掉
super().__init__() #与上一句作用一样,super函数可以帮助获得想获得的父类的__init__方法,比上面的方法好在不用找到所有的父类的实例对象,可以自己找到所有继承对象
self.hungry = False
else:
print("撑了。吃不下了")
Fish.__init__(shark) #这样也可以,就是让子类获得父类的__init__方法
fish = Fish()
fish.move()
fish.move()
goldfish = Goldfish()
goldfish.move()
goldfish.move()
shark = Shark()
shark.eat()
shark.move()多重继承:
class A1:
def a1(self):
print('a1')
class A2:
def a2(self):
print('a2')
class C(A1,A2): #多重继承
pass
c = C()
c.a1()
c.a2()多态
不同类对象中的函数是不同的
self:实例对象,谁调用这个类,它就是谁,比如
class A:
def a(self):
print("我是%s"%self.name)
tom = A() #此时tom调用了A类,tom就是self了,self所有的方法都会为tom所使用,给tom对应的属性赋值,比如tom.name = "tom",就是给类里的方法赋值了
tom.a() #返回:我是tom横向关系的类的组合
class Turtle:
def __init__(self,x):
self.num = x
class Fish:
def __init__(self,x):
self.num = x
class Pool:
def __init__(self,x,y): #self直接传递了2个参数
self.turtle = Turtle(x) #可以把这个参数给Turtle类中的self,实际上就是给Turtle类的参数turtle赋值
self.fish = Fish(y) #可以把这个参数给Fish类中的self
def print_num(self):
print("水池里有乌龟%d只,%d条"%(self.turtle.num,self.fish.num))
p = Pool(1,10)
p.print_num()-------------------------分割线-------------------------
class C: #这叫定义了一个类
def x(self):
print("x")
C.x() #这是类对象调用方法
c = C() #这就定义了一个实例对象c
c.x() #这就是实例对象的调用方法注意:实例对象改变的优先级,高于类对象,也就是说如果改变了实例对象,那么再改变类对象也不能把它变回来,相反,一般情况下,直接改变类对象,就能把对应的实例对象进行对应变换
-------------------------分割线-------------------------
class C:
def x(self):
print("x-man")
c = C()
c.x() #此时,实例对象c可以调用方法x
c.x = 1 #在不声明的情况下,创建属性x,并赋值为1
c.x #可以调用该属性x
c.x() #但是此时,因为属性与方法重名,都叫x,属性就会覆盖掉方法,就无法调用该方法了绑定
实例对象要想调用方法,必须在类对象中设置实例对象self
class C:
def c_part():
print("hahaha")
C.c_part() #对于类对象,可以没有实例对象self的情况下调用出方法
c = C()
c.c_part() #但对于实例对象,就必须有self才能调用成功了个人理解:定义的类是一个图纸,类对象就是图纸本身,而实例对象则是按照图纸造出来的房子,一般情况下,对图纸进行改造,房子也会跟着变化,但这是没有对房子进行单独改造的情况下,假如出现以下情况:
1.房子已经造出来了,并且还对某一个房子进行了单独改造,那么再去改变图纸,也不能将之前对房子的单独改造覆盖掉了
2.如果已经造出来了房子,再把图纸烧毁,也就是删除类对象 del 类对象名,那房子依然不受影响,它们在某种程度上是独立的个体
几个BIF
issubclass(子类,父类) #可以判断出,是不是父类与子类的关系,注意每个类都是自身的子类,每个类都是object类(基类)的子类
isinstance(实例对象,类) #可以判断出该实例对象,是否来自该类,包括上溯到该类的若干代父类的情况,都能判断为True
hasattr(对象,'属性') #注意属性要用引号引起来,判断该对象是否有该属性
getattr(对象,'属性',"default") #获得属性的值,如果不存在该属性,就打印default
setattr(对象,'属性','值') #创建一个属性,并给它赋值
delattr(对象,'属性') #删除一个属性,如果该属性不存在,就会抛出异常
x = property(get,set,del) #设置一个属性
*args与*kwargs的含义
*args与*kwargs分别对应着传入的参数为列表或字典(键值对)
总的来说,*args代表任何多个无名参数,返回的是元组;**kwargs表示关键字参数,所有传入的key=value,返回字典;
*args和**kwargs的用途:
*args 和 **kwargs 主要用于函数定义, 可以将不定数量的参数传递给一个函数。
*args 是用来发一个非键值对的可变数量的参数列表给一个函数; kwargs允许将一个不定长度的键值对,作为参数传递给一个函数。如果需要在一个函数中处理带名字的参数时,此时就应该使用kwargs了。
def test(a,*args,**kwargs):
print(a)
print(args)
print(kwargs)
test(1,3,5,7,c='2',d=4)
1
(3, 5, 7)
{‘c’: ‘2’, ‘d’: 4}
在test(1,3,5,7,c=‘2’,d=4)中,函数里参数对应的数值为:a=1,*args表示剩下的没有名称的参数,**kwargs表示剩余的键值对。
def ak(*args,**kwargs):
print('args=',args)
print('kwargs=',kwargs)
print('***************************************')
if __name__=='__main__':
ak(2,4,6,8)
ak(a=2,b=4,c=6,d=8)
ak(2,4,6,8,a=1,b=3,c=5)
ak('x', 2, None, a=4, b='6', c=8)
#ak('a', a=1, 1, None, b='2', c=3)

同时使用*args和kwargs时,*args参数必须要列在kwargs前,否则会报错。
readline与readlines
fo = open("runoob.txt", "rw+")
fo.readline() # 这其实就是读取一行
fo.readlines()装饰器
#既不需要侵入,也不需要函数重复执行
import time
def deco(func):
def wrapper():
startTime = time.time()
func()
endTime = time.time()
msecs = (endTime - startTime)*1000
print("time is %d ms" %msecs)
return wrapper
@deco
def func():
print("hello")
time.sleep(1)
print("world")
if __name__ == '__main__':
f = func #这里f被赋值为func,执行f()就是执行func()
f()
所谓装饰器,就是在不改变函数的情况下,为该函数注入一项新的功能,例如这里,deco()函数的参数是func函数,其返回值也就是这个函数func(),当我们为func函数加上装饰器@deco时,再调用func()时,将会自动执行deco(func)函数