AB 测试
【AB测试最全干货】史上最全知识点及常见面试题(上篇) - 知乎00、写在前面AB测试我们在工作当中,尤其是在很多的互联网大厂里面,经常是用来验证一个功能最终是否会被上线的重要手段,也是在数据分析面试当中经常会出现的一个考点,所以AB测试的重要性就不言而喻了。但是很多… https://zhuanlan.zhihu.com/p/375902281Evan's Awesome A/B Tools - sample size calculator, A/B test results, and more
https://zhuanlan.zhihu.com/p/375902281Evan's Awesome A/B Tools - sample size calculator, A/B test results, and more https://www.evanmiller.org/ab-testing/什么是 A/B 测试? - 知乎分享下鹅厂数据分析师 jiangeliu(刘健阁) 是如何设计一个 A/B test 的。实验设计AB Test 实验一般有 2 个…https://www.zhihu.com/question/20045543【阿里妈妈数据科学系列】第一篇:认识在线实验 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:拾芥 阿里妈妈数据科学团队 前言在互联网业务中,“增长”是永恒的主题,但随着互联网时代的发展,野蛮增长的流量红利已逐渐消失,如何在策略效果不可见的条件下,实现有…https://zhuanlan.zhihu.com/p/387718416【阿里妈妈数据科学系列】第二篇:在线分流框架下的AB Test - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:拾芥、芋萌 阿里妈妈数据科学团队 背景AB Test 是为同一目标制定两个方案,在同一时间维度,保证其他体验一致的情况下,分析实验组跟对照组的区别,根据实验结果做出决策…https://zhuanlan.zhihu.com/p/390417035【阿里妈妈数据科学系列】第六篇:AB Test 中的那些坑 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:观芷 阿里妈妈数据科学团队 AB Test 的基本原理看似简单,但在实际业务中能够正确使用 AB Test 却并不容易,实验者需要对实验技术和业务特征都有刻深的理解。本文我们将盘…https://zhuanlan.zhihu.com/p/429275927手把手教你从0到1搭建AB测试系统(一) | 人人都是产品经理本文对AB测试做了相关的整体介绍。什么是A/B测试?为什么要使用A/B测试?A/B测试的架构是什么? 最近一段时间在负责公司内部AB测试系统从0到1的搭建,在实现中踩了很多坑,也做了很多竞品分析了解国内外的竞品通用做法。 借此机会总结下这段时间的经验并分享给大http://www.woshipm.com/pd/1692294.html一文搞懂AB Testing的分层分流 | 人人都是产品经理在网络分析中,A / B测试(桶测试或分流测试)是一个随机实验,通常有两个辩题,A和B。如果你还对这个测试不是很明白,那就来文中看看~ 一、定义 在网络分析中,A / B测试(桶测试或分流测试)是一个随机实验,通常有两个变体,A和B。利用控制变量法保持有单一变http://www.woshipm.com/pd/1080730.html数据分析(一)什么是埋点 - 简书一、什么是埋点 所谓埋点是数据领域的专业术语,也是互联网应用里的一个俗称。它的学名应该叫做事件追踪,对应的英文是Event Tracking。它主要是针对特定用户行为或事件进...https://www.jianshu.com/p/3e18c16373a2还只知道“A/B测试”?是时候了解一下“多变量测试”了 | 人人都是产品经理彻底的设计改版最好使用A/B测试来验证,而MVT(多变量测试)则表示不同的UI元素之间是如何相互影响的,并支持对设计的渐进式改进。 在优化设计的方法中,A/B测试受到了广泛的关注。MVT(多变量测试)是A/B测试的一种替代方法,但大家对这种方法的了解并不多,通http://www.woshipm.com/ucd/1007558.html1.AB测试一般流程
https://www.evanmiller.org/ab-testing/什么是 A/B 测试? - 知乎分享下鹅厂数据分析师 jiangeliu(刘健阁) 是如何设计一个 A/B test 的。实验设计AB Test 实验一般有 2 个…https://www.zhihu.com/question/20045543【阿里妈妈数据科学系列】第一篇:认识在线实验 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:拾芥 阿里妈妈数据科学团队 前言在互联网业务中,“增长”是永恒的主题,但随着互联网时代的发展,野蛮增长的流量红利已逐渐消失,如何在策略效果不可见的条件下,实现有…https://zhuanlan.zhihu.com/p/387718416【阿里妈妈数据科学系列】第二篇:在线分流框架下的AB Test - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:拾芥、芋萌 阿里妈妈数据科学团队 背景AB Test 是为同一目标制定两个方案,在同一时间维度,保证其他体验一致的情况下,分析实验组跟对照组的区别,根据实验结果做出决策…https://zhuanlan.zhihu.com/p/390417035【阿里妈妈数据科学系列】第六篇:AB Test 中的那些坑 - 知乎欢迎关注:阿里妈妈技术公众号 本文作者:观芷 阿里妈妈数据科学团队 AB Test 的基本原理看似简单,但在实际业务中能够正确使用 AB Test 却并不容易,实验者需要对实验技术和业务特征都有刻深的理解。本文我们将盘…https://zhuanlan.zhihu.com/p/429275927手把手教你从0到1搭建AB测试系统(一) | 人人都是产品经理本文对AB测试做了相关的整体介绍。什么是A/B测试?为什么要使用A/B测试?A/B测试的架构是什么? 最近一段时间在负责公司内部AB测试系统从0到1的搭建,在实现中踩了很多坑,也做了很多竞品分析了解国内外的竞品通用做法。 借此机会总结下这段时间的经验并分享给大http://www.woshipm.com/pd/1692294.html一文搞懂AB Testing的分层分流 | 人人都是产品经理在网络分析中,A / B测试(桶测试或分流测试)是一个随机实验,通常有两个辩题,A和B。如果你还对这个测试不是很明白,那就来文中看看~ 一、定义 在网络分析中,A / B测试(桶测试或分流测试)是一个随机实验,通常有两个变体,A和B。利用控制变量法保持有单一变http://www.woshipm.com/pd/1080730.html数据分析(一)什么是埋点 - 简书一、什么是埋点 所谓埋点是数据领域的专业术语,也是互联网应用里的一个俗称。它的学名应该叫做事件追踪,对应的英文是Event Tracking。它主要是针对特定用户行为或事件进...https://www.jianshu.com/p/3e18c16373a2还只知道“A/B测试”?是时候了解一下“多变量测试”了 | 人人都是产品经理彻底的设计改版最好使用A/B测试来验证,而MVT(多变量测试)则表示不同的UI元素之间是如何相互影响的,并支持对设计的渐进式改进。 在优化设计的方法中,A/B测试受到了广泛的关注。MVT(多变量测试)是A/B测试的一种替代方法,但大家对这种方法的了解并不多,通http://www.woshipm.com/ucd/1007558.html1.AB测试一般流程

ab测试观测的大部分指标是比率类指标
1.确定目标
2.确定随机分组的单位,然后进行分组,在业务实践中,分组单位一般是用户UV,或者是流量。RTC(受控随机试验)的原理要求被分组的单位之间彼此独立,这个要求是进行分组对象选择时最重要的考量。在按钮颜色选择的例子中,我们通常既可以选择PV也可以选择UV为单位。但在复杂一些的环境中,PV和UV的独立性假设都有可能不被满足。比如,假定我们的受试用户的浏览行为有极大差异,少数用户贡献了大多数的浏览,那么PV之间的独立性就可能受到削弱,以为不同PV来自于同一个用户的可能性比较大。又比如,用户之间有社交联系,那么UV之间的独立性也会受到削弱。流量即页面浏览量或点击量,用户每一次对网站中的每个网页访问均被记录一次PV,用户对用以页面的多次访问,多次累计。UV通过互联网访问、浏览这个网页的自然人。
3.确定样本量,在具体的业务中,确定样本量涉及两个决策:受试用户或者流量的占比和实验运行的时长。
4.假设检测。在实际业务中,实验着一般都会采用大样本理论版本的t-检验,也即z-检验。
2.AB 流量分割 - 辛普森悖论
正确的测试,除了被测试变量外,其他可能影响结果的变量的比例都应该保持一致,这需要对流量进行均匀合理的分割。
2.1 分流分层原理
2.1.1 分流
用户分流是指按照地域、性别、年龄等把用户均匀地分为几个组,1个用户只能出现在1个组中。但是实际情况中,往往会同时上线多个实验,拿广告来说,有针对样式形态的实验,有针对广告位置策略的实验,有针对预估模型的实验。如果只是按照这种分流模式来,在每组实验放量10%的情况下,整体的流量只能同时开展10个实验。这个实验的效率是非常低的。为了解决这个问题,提出了用户分层、流量复用的方法。
2.2.2 分层
同一份流量可以分布在多个实验层,也就是说同一批用户可以出现在不同的实验层,前提是各个实验层之间无业务关联,保证这一批用户都均匀地分布到所有的实验层里,达到用户“正交”的效果就可以。所谓的正交分层,其实可以理解为互不影响的流量分层,从而实验流量复用的效果,层与层之间没有业务关联度。

- 分流:组1、组2通过分流的方式分为2组流量,此时组1和组2是互斥的,即组1+组2=100%试验流量。
- 分层:流量流过组2中的B1层、B2层、B3层时,B1层、B2层、B3层的流量都是与组2的流量相等,相当于对组2的流量进行了复用,即B1层=B2层=B3层=组2
- 扩展:流量流过组2中的B1层时,又把B1层分为了B1-1,B1-2,B1-3,此时B1-1,B1-2,B1-3之间又是互斥的,即B1-1层+B1-2层+B1-3层=B1层。
3.实验分类
3.1 AB实验
AB实验、ABn实验、AA实验(这是个好思路,可以验证AB设计的是否合理,随机从总体中选出几组分析,若A和A相差很大,说明实验对象分组的随机性不够,使得实验组和控制组的受试对象有内在的差异)、MVT实验
3.2 类实验
严格定义来说,类实验研究是因为受实际条件所限不能随机分组或不能设立平行的对照组,类实验更多的是人们遵照AB实验的逻辑,逐步放宽实验限定而形成的实验方法,核心思想仍然是控制变量的对比发。
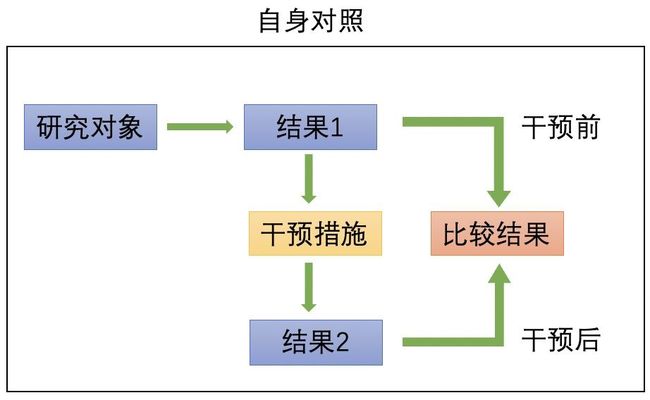
自身对照
对研究对象自身在干预前后两个阶段的效果进行观察或测量,以评价干预效果。自身对照中,对照组和实验组的数据来自同一样本,自身对照更多的应用在无法分组的场景下,比如政策实施前后的效果差异,自身对照中存在明显的缺陷是,我们无法对时间变量进行控制,因此自身对照更多的是作为一些定性分析而应用。
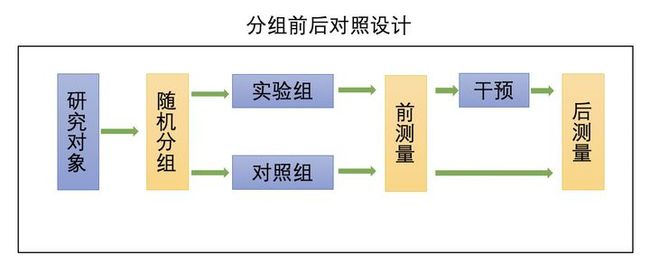
分组前后对照设计
将研究对象随机分为实验组和对照组,实验组给与干预措施,对照组不干预,得出自变量与因变量之间的关系,量化了一部分实验组的可能的误差因素。
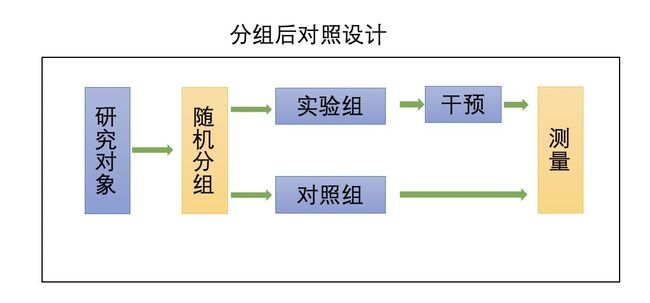
分组后对照实验
类似实验前后对照设计,但是无法进行前后比较的实验,这主要是对于历史数据的缺失造成的,例如新客分组,在用户成为我们的新客之前,我们并有没用户相关的历史数据,因此无法对干预措施前的历史数据做有效的测量,只能假设实验前分组并无差异,以干预后的测量结果作为最终的实验效果。这也是我们站外智能优选的方案,用商品做的ab切分,最终看,实验效果被淹没在商品影响下了。
4.正交试验设计
在一个全局流量下同时进行的在线分流实验有很多,因此在进行实验前需要确定流量必须互斥还是可以进行正交,正交实验之每个独立实验为一层,层与层之间的流量是正交的,一份流量经过每层实验时,都会再次随机打散,且随机效果离散。互斥实验指实验在用一层拆分流量,且无论如何拆分,不同组的流量是不重叠的。
规则一:正交、互斥
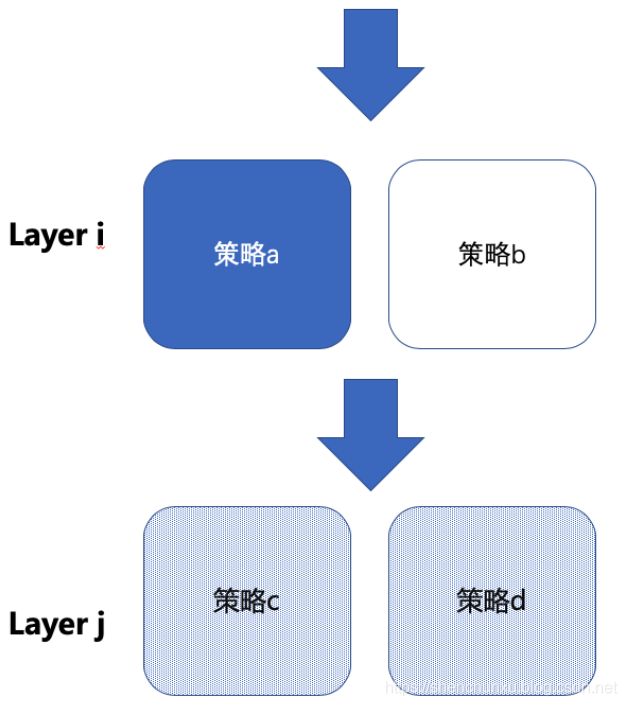
规则二:
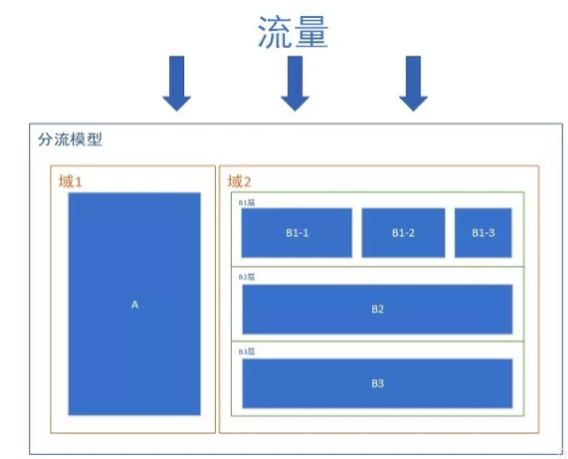
同一份流量经过B1,之后又经过B2,B1可能是文案1,B2可能是图2.最终展示给PV的页面可能就是带有文案1和图2的页面,分层并不影响指标,前提是正交,没有业务关联度。
5.数据质量
数据中可能存在大量的缺失值及大量的噪音。
数据清理:主要通过填补缺失值、光滑噪声数据,平滑或删除离群点,以解决数据的不一致性。
数据集成:
数据规约:
数据变换
6.埋点
做AB测试时我们经常听到一个词叫“埋点”。“埋点”是互联网应用里的一个俗称,学名应该叫事件跟踪,对应的英文是Event Tracking。应用系统(网站、App等)在设计和实现时主要关注核心业务功能,投入运营后,在做用户行为分析时发现核心业务系统的数据远远不够,需要采集更多用户行为等相关数据,这样就需要在应用的代码中添加一些额外的代码来采集数据,这就是所谓的“埋点”。
7.分流算法
进行分流算法的目的是将线上用户按照固定的流量比例分配到不同实验(桶)中,并且保持这种实验(桶)分配关系,以此来对照验证相关的指标是否有所好转,所以为了保持这种用户和实验(桶)的分配关系,我们使用了hash取模的方式将一个用户固定在了一个0到100的区间中,这样只要对应实验(桶)的区间没有变化,这个用户和实验(桶)的分配关系就不会变化。在分流策略这块,实验用户实际上和流量占比之间还是存在关系的,因为流量比例会变化,选定用户如果没有一定关系,流量比例一动影响会比较大。
创意这块的电商算法,其实要接触的东西太多了,视觉算法,分类,检测,分割,传统的色彩管理,颜色迁移,爬虫,创意优选的推荐,效率合图,以及这个ab测试,这算上是数据分析的东西,任重而道远。