网络空间安全论文笔记2——漏洞
Exploitability prediction of software vulnerabilities
预测漏洞:基于计数的方法(侧重于预测特定时间范围内软件系统中存在的漏洞数量,在理解安全趋势、分配安全资源或预期发现潜在漏洞方面很有用)和基于分类的方法(预测易受攻击的实体,可以帮助管理者将其资源分配指向易受攻击的漏洞)
提出了一个基于机器学习的框架,描述了如何使用CVSS度量、漏洞类型和产品类型等各种特征来预测易受攻击的漏洞
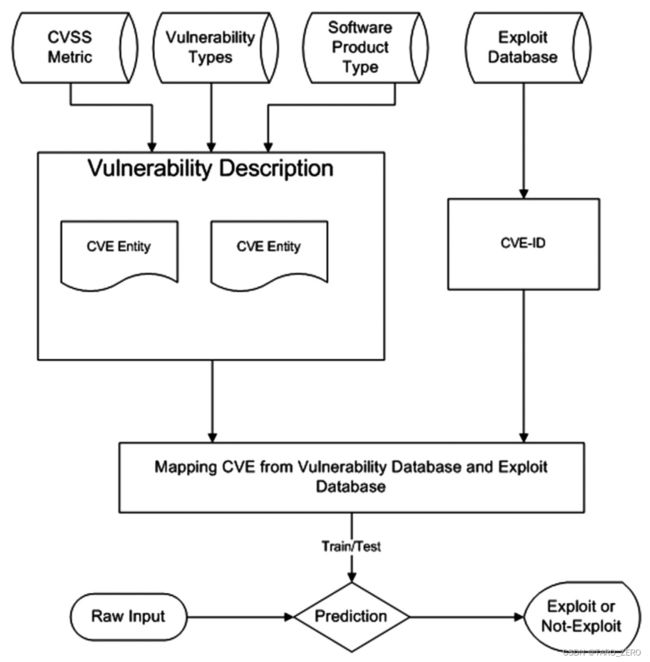
模型预测易受攻击漏洞的准确率>85%
Measuring, analyzing and predicting security vulnerabilities in software systems
提出了漏洞密度作为指标(代码单位大小的漏洞数量),并在 Windows 和 RH Linux 系列操作系统上进行了评估
研究使用逻辑模型(有时可以用线性模型近似)对漏洞发现进行建模
结果表明,漏洞密度的值落在一个值范围内,就像一般缺陷的常用缺陷密度度量一样,漏洞与缺陷总数的比率通常在 1-5% 的范围内
Beyond heuristics: learning to classify vulnerabilities and predict exploits
考虑了一种从数据库(开源漏洞数据库OSVDB和MITRE通用漏洞披露)收集特征的模型以基于概念验证(POC)预测漏洞可用性,同样使用机器学习模型实现
将漏洞分类作为机器学习中的一个问题来改进现有的方法
模型根据一个被标记为“已利用”或“未利用”的大型漏洞数据库进行估计:先从这个数据库中提取信息并将其提取到特征向量中进行分类,随后使用支持向量机对这些特征向量进行分类
A vulnerability analysis and prediction framework
提出了一个集成的数据挖掘框架来自动描述漏洞如何随着时间的推移而发展并检测特定漏洞的演变。同时,模型具有预测功能,可用于预测特定漏洞或估计漏洞组的未来出现概率
A multi-model-integration-based prediction methodology for the spatiotemporal distribution of vulnerabilities in integrated energy systems under the multi-type, imbalanced, and dependent input data scenarios
LineVul: A Transformer-based Line-Level Vulnerability Prediction
背景:基于ML/DL的漏洞预测方法,基于图神经网络的IVDetect依旧不准确且粗粒度(文件级,函数级)
IVDetect局限:训练数据集不够全面,RNN结构仍不能有效学习长距离的依赖关系,精度粗
成果:提出了LineVul,一种基于Transformer的行级漏洞预测方案,提高了精度,也做到细粒度预测(代码行级)

模型改进:不再使用 GloVe 预处理和 RNN 模型,而是使用 BERT 结构和自注意力模型,以捕获远距离依赖关系;同时不再在特定项目的数据集中训练,而是直接利用 CodeBERT 预训练好的语言模型;注意力机制也能更加准确的定位到漏洞部分
训练数据集:使用 Fan 等人提供的基准数据集(目前唯一提供行级ground-truth的漏洞数据集),收集自 348 个开源 Github 项目,其中包括 2002 年至 2019 年的 91 个不同的 CWE,188,636 个 C/C++ 函数,漏洞函数的比率为 5.7%(即 10,900 个易受攻击的函数),以及 5,060,449 个 LOC,比率为0.88% 的易受攻击的行(即 44,603 个易受攻击的行)
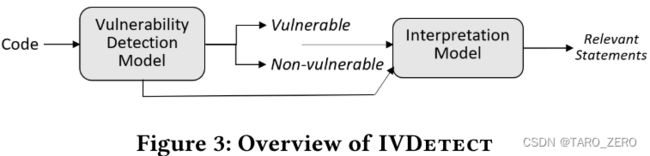
Vulnerability detection with fine-grained interpretations
提出了 IVDetect 漏洞检测模型,模型精度优于此前的研究
对于漏洞检测,我们通过数据和控制依赖关系分别考虑易受攻击的语句及其周围的上下文
具体实现:
先将代码转换为向量表达。利用 GloVe 词嵌入(用于词表示的全局向量)来捕获标记之间的语义相似性,并利用 GRU 模型将向量序列总结为一个特征向量
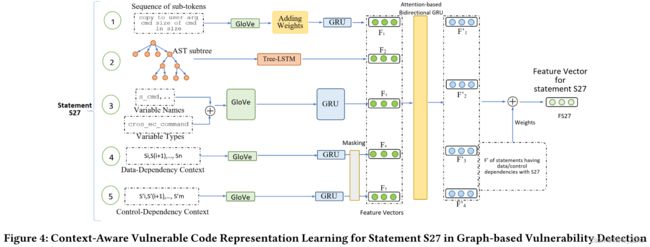
共生成五个向量:用于捕获词汇信息的子标记序列,用作图形模型中节点信息的变量名称和类型,数据依赖上下文,控制依赖上下文,随后使用 Tree-LSTM 生成 AST 树的表示
然后使用 FA-GCN 进行漏洞预测。将输入处理成由许多语句组成的程序依赖图(PDG),FA-GCN执行滑动窗口沿着 PDG 的所有节点(语句)将生成的特征向量链接到特征矩阵,接入归一化和全连接层转为向量,投入分类器得到预测分数
基于 GNNExplainer 的细粒度漏洞预测。用以解释哪些子图对模型的漏洞预测贡献最大
利用 FA-GCN(即特征注意力图卷积网络)方法来预测功能级漏洞,并利用 GNNExplainer 来定位漏洞的细粒度位置。
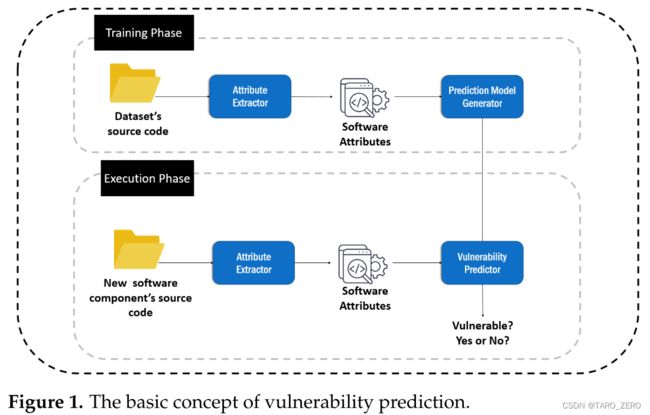
Examining the Capacity of Text Mining and Software Metrics in Vulnerability Prediction
构建和比较了基于软件度量和文本挖掘(词袋,标记序列)的漏洞预测模型
数据集: Ferenc 等人提供的漏洞数据集,包含来自现实世界开源软件应用程序的漏洞,并通过添加通过文本挖掘提取的附加特征(例如,BoW 和标记序列)来扩展它
漏洞预测结构
结果表明,基于文本挖掘的模型在 F2 分数方面优于基于软件度量的模型,而使用软件度量丰富基于文本挖掘的模型并未发现为其预测性能提供任何附加值
Deep learning based vulnerability detection: Are we there yet
漏洞数据集
合成数据:SATE IV Juliet 和 SARD 数据集,使用已知漏洞模式合成,这些数据集最初是为评估基于静态和动态分析的漏洞预测工具而设计的
半合成数据:Draper 数据集,包含从开源存储库收集但使用静态分析器进行注释的函数。同时 SARD 和国家漏洞数据库 (NVD) 数据集也经常被修改以证明将它们与原始上下文隔离开来的漏洞。尽管这些数据集比合成数据集更复杂,但由于简化和隔离,它们并不能完全捕捉现实世界漏洞的复杂性。
真实数据: Devig 数据集,代码和相应的漏洞注释均来自真实世界的来源。
漏洞预测中的DL方法总结
文本挖掘方法先将软件代码转换为向量表示,然后学习其中的隐含特征,对代码中可能存在的漏洞进行预测和定位。最近,许多DL模型也开始应用于漏洞预测任务。Li等提出VulDeePecker模型,在漏洞预测任务中引入了深度神经网络(BiLSTM),同时公开了第一个用于深度学习方法的漏洞数据集。Zhou等提出基于图神经网络的Devign模型,使用代码的图属性(即 AST、CFG、DFG)完成对代码的表征。Li等提出的SySeVR模型使用基于数据依赖的语义信息表征代码。Russel等使用CNN和RNN模型。Chakraborty等提出了新的用于深度学习的漏洞数据集,并证实了更高质量的数据集确实为DL方法带来了显著的准确性提升。Li等提出了IVDetect模型,提取代码中的数据和控制依赖关系生成五个维度的向量表示,统一交由RNN模型训练学习,带来了精确度上的提升并能够定位到漏洞所在函数块。基于此, Fu等提出了LineVul模型,使用CodeBERT预训练模型完成代码的词向量转化,使用行粒度数据集进行训练,使用图神经网络捕获文本中的依赖关系,模型得到更高预测准确性的同时得以定位至漏洞所在代码行。
VulDeePecker: A Deep Learning-Based System for Vulnerability Detection.
Devign: effective vulnerability identification by learning comprehensive program semantics via graph neural networks.
SySeVR: A framework for using deep learning to detect software vulnerabilities.
Automated vulnerability detection in source code using deep representation learning.
Deep learning based vulnerability detection: Are we there yet
Vulnerability detection with fine-grained interpretations
LineVul: A Transformer-based Line-Level Vulnerability Prediction