《Mars说光场》系列文章整理
[导语:国内对光场(Light Field)技术的中文介绍十分匮乏,《Mars说光场》系列文章旨在对光场技术及其应用的科普介绍。]
光场技术是目前最受追捧的下一代显示技术,谷歌、Facebook、Magic Leap等国内外大公司都在大力布局。然而目前国内对光场(Light Field)技术的中文介绍十分匮乏,曹煊博士《Mars说光场》系列文章旨在对光场技术及其应用的科普介绍。
曹煊博士系腾讯优图实验室高级研究员。优图— 腾讯旗下顶级的机器学习研发团队,专注于图像处理、模式识别、深度学习。在人脸识别、图像识别、医疗AI、OCR、哼唱识别、语音合成等领域都积累了领先的技术水平和完整解决方案。
《Mars说光场》系列文章目前已有5篇,包括:
《Mars说光场(1)— 为何巨头纷纷布局光场技术》;
《Mars说光场(2)— 光场与人眼立体成像机理》;
《Mars说光场(3)— 光场采集》;
《Mars说光场(4)— 光场显示》;
《Mars说光场(5)— 光场在三维人脸建模中的应用》;
目录
1、为何巨头纷纷布局光场技术
1.1、什么是光场?
1.2、为什么要研究光场?
1.3、光场4D参数化
1.4、光场4D可视化
1.5、光场技术展望
1.6、参考文献
2、光场与人眼立体成像机理
2.1、人眼的立体成像机理
2.1.1 心理感知
2.1.2 生理感知
2.2、如何满足人眼的视觉要求?
2.2.1 传统显示屏
2.2.2 3D电影
2.2.3 虚拟现实(VR/AR)
2.2.4 光场显示
2.3、参考文献
3、光场采集
3.1、基于微透镜阵列的光场采集
3.2、基于相机阵列的光场采集
3.3、基于编码掩膜的光场采集
3.4、光场采集方案对比
3.5、参考文献
4、光场显示
4.1、体三维显示
4.2、多视投影阵列光场显示
4.3、集成成像光场显示
4.4、全息显示
4.5、多层液晶张量光场显示
4.5.1 液晶工作原理
4.5.2 多层液晶偏振特性
4.5.3 多层液晶的各向异性
4.6 参考文献
5、光场在三维人脸建模中的应用
5.1、反射场在三维成/呈像中的重要性
5.2、USC Light Stage介绍
5.2.1 Light Stage 1
5.2.2 USC Light Stage 2
5.2.3 USC Light Stage 3
5.2.4 USC Light Stage 5
5.2.5 USC Light Stage 6
5.2.6 Light Stage对比总结
5.3、参考文献
1、为何巨头纷纷布局光场技术
【摘要】 — 光场(Light Field)是空间中光线集合的完备表示,采集并显示光场就能在视觉上重现真实世界。全光函数(Plenoptic Function)包含7个维度,是表示光场的数学模型。光场是以人眼为中心对光线集合进行描述。由于光路是可逆的,以发光表面为中心来描述光线集合衍生出与光场类似的概念——反射场(Reflectance Field)。反射场也具有7个维度的信息,但每个维度的定义与光场不尽相同。不论光场还是反射场,由于7个维度的信息会急剧增加采集、处理、传输的负担,因此实际应用中更多的是采用4D光场模型。随着Magic Leap One的上市,以及Google《Welcome to light field》在Steam上发布,光场作为下一代成像/呈像技术,受到越来越多的关注。本文将详细介绍光场的基本概念,尤其是4D光场成像相比传统成像的优势。
1.1、什么是光场?
在人类的五大感知途径中,视觉占据了70%~80%的信息来源;而大脑有大约50%的能力都用于处理视觉信息[1]。借助视觉,我们能准确抓取杯子,能在行走中快速躲避障碍物,能自如地驾驶汽车,能完成复杂的装配工作。从日常行为到复杂操作都高度依赖于我们的视觉感知。然而,现有的图像采集和显示丢失了多个维度的视觉信息。这迫使我们只能通过二维“窗口”去观察三维世界。例如医生借助单摄像头内窥镜进行腹腔手术时,因无法判断肿瘤的深度位置,从而需要从多个角度多次观察才能缓慢地下刀切割。从光场成像的角度可以解释为:因为缺乏双目视差,只能依靠移动视差来产生立体视觉。再例如远程机械操作人员通过观看监视器平面图像进行机械遥控操作时,操作的准确性和效率都远远低于现场操作。
人眼能看见世界中的物体是因为人眼接收了物体发出的光线(主动或被动发光),而光场就是三维世界中光线集合的完备表示。“Light Field”这一术语最早出现在Alexander Gershun于1936年在莫斯科发表的一篇经典文章中,后来由美国MIT的Parry Moon和Gregory Timoshenko在1939年翻译为英文[2]。但Gershun提出的“光场”概念主要是指空间中光的辐射可以表示为关于空间位置的三维向量,这与当前“计算成像”、“裸眼3D”等技术中提及的光场不是同一个概念。学术界普遍认为Parry Moon在1981年提出的“Photic Field”[3]才是当前学术界所研究的“光场”。 随后,光场技术受到MIT、Stanford等一些顶级研究机构的关注,其理论逐步得到完善,多位相关领域学者著书立作逐步将光场技术形成统一的理论体系,尤其是在光场的采集[4]和3D显示[5,6]两个方面。欧美等部分高校还开设了专门的课程——计算摄像学(Computational Photography)。
如图1所示,人眼位于三维世界中不同的位置进行观察所看到的图像不同,用(x, y, z)表示人眼在三维空间中的位置坐标。光线可以从不同的角度进入人眼,用(θ, Φ)表示进入人眼光线的水平夹角和垂直夹角。每条光线具有不同的颜色和亮度,可以用光线的波长(λ)来统一表示。进入人眼的光线随着时间(t)的推移会发生变化。因此三维世界中的光线可以表示为7个维度的全光函数(Plenoptic Function, Plen-前缀具有“全能的、万金油”的意思)[7]。
P(x, y, z, θ, Φ, λ, t)
 图 1. 7D全光函数示意图
图 1. 7D全光函数示意图
上述光场的描述是以人眼为中心。光路是可逆的,因此光场也可以以物体为中心等效的描述。与“光场”相类似的另一个概念是“反射场(Reflectance Field)”。如图2所示,物体表面发光点的位置可以用(x, y, z)三个维度来表示;对于物体表面的一个发光点,总是向180度半球范围内发光,其发光方向可以用水平角度和垂直角度(θ, Φ)来表示;发出光线的波长表示为(λ);物体表面的光线随着时间(t)的推移会发生变化。同理,反射场可以等效表示为7维函数,但其中的维度却表示不同的意义。
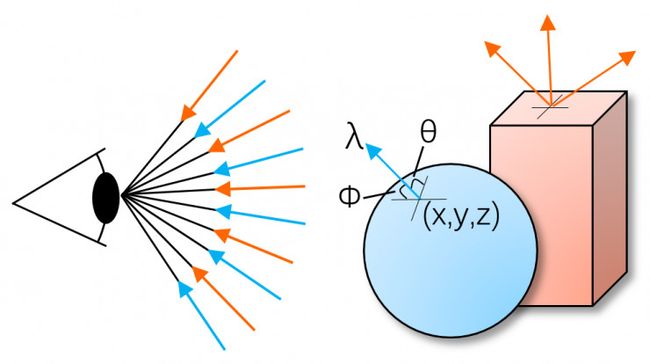 图 2. 7D反射场示意图
图 2. 7D反射场示意图
对比光场与反射场可以发现:光场与反射场都可以用7个维度来表征,光场是以人眼为中心描述空间中所有的光线,反射场是以物体表面发光点为中心描述空间中所有的光线。光场所描述的光线集合与反射场所描述的光线集合是完全一致的。换句话说,光场中的任一条光线都可以在反射场中找到。
1.2、为什么要研究光场?
【从光场采集的角度来看】以自动驾驶为例,首先需要通过多种传感器去“感知”外界信息,然后通过类脑运算进行“决策”,最后将决策以机械结构为载体进行“执行”。现阶段人工智能的发展更倾向于“类脑”的研究,即如何使计算机具有人脑类似的决策能力。然而却忽略了“眼睛”作为一种信息感知入口的重要性。设想一个人非常“聪明”但是视力有障碍,那么他将无法自如的驾驶汽车。而自动驾驶正面临着类似的问题。如果摄像机能采集到7个维度所有的信息,那么就能保证视觉输入信息的完备性,而“聪明”的大脑才有可能发挥到极致水平。研究光场采集将有助于机器看到更多维度的视觉信息。
【从光场的显示角度来看】以LCD/OLED显示屏为例,显示媒介只能呈现光场中(x, y, λ, t)四个维度的信息,而丢失了其他三个维度的信息。在海陆空军事沙盘、远程手术等高度依赖3D视觉的场景中,传统的2D显示媒介完全不能达到期望的效果。实现类似《阿凡达》中的全息3D显示,是人类长久以来的一个梦想。当光场显示的角度分辨率和视点图像分辨率足够高时可以等效为动态数字彩色全息。研究光场显示将有助于人类看到更多维度的视觉信息。
从1826全世界第一台相机诞生[8]至今已经有近两百年历史,但其成像原理仍然没有摆脱小孔成像模型。在介绍小孔成像模型之前,先看看如果直接用成像传感器(e.g. CCD)采集图像会发生什么事呢? 如图3所示,物体表面A、B、C三点都在向半球180度范围内发出光线,对于CCD上的感光像素A'会同时接收到来自A、B、C三点的光线,因此A'点的像素值近似为物体表面上A、B、C三点的平均值。类似的情况也会发生在CCD上的B'和C'点的像素。因此,如果把相机上的镜头去掉,那么拍摄的图片将是噪声图像。
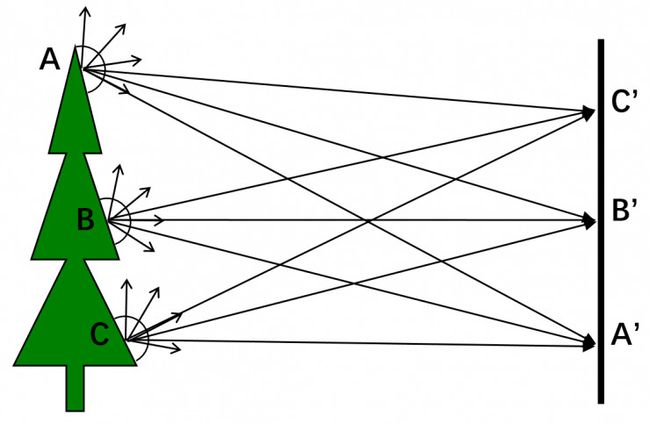 图 3. 无小孔的噪声成像
图 3. 无小孔的噪声成像
如果在CCD之前加一个小孔,那么就能正常成像了,如图4所示。CCD上A'点只接收到来自物体表面A点的光线。类似的,CCD上B'和C'点也相应只接收到物体表面B点和C的点光线。因此,在CCD上可以成倒立的像。
 图 4. 小孔成像
图 4. 小孔成像
实际的相机并没有采用如图4中的理想小孔成像模型,因为小孔直径较小会导致通光亮非常小,信噪比非常低,成像传感器无法采集到有效的信号;如果小孔直径足够小,当与光波长相当时还会产生衍射现象。而小孔直径过大会导致成像模糊。现代的成像设备用透镜来替代小孔,从而既能保证足够的通光量,又避免了成像模糊。如图5所示,物体表面A点在一定角度范围内发出的光线经过透镜聚焦在成像传感器A’点,并对该角度范围内所有光线进行积分,积分结果作为A点像素值。这大大增加了成像的信噪比,但同时也将A点在该角度范围内各方向的光线耦合在一起。
 图 5. 透镜小孔成像
图 5. 透镜小孔成像
小孔成像模型是光场成像的一种降维形式,只采集了(x, y, λ, t)四个维度的信息。RGB-D相机多了一个维度信息(x, y, z, λ, t)。相比全光函数,其主要丢失的维度信息是光线的方向信息(θ, Φ)。缺失的维度信息造成了现有成像/呈像设备普遍存在的一系列问题。在图像采集方面,可以通过调节焦距来选择聚焦平面,然而无论如何调节都只能确保一个平面清晰成像,而太近或太远的物体都会成像模糊,这给大场景下的AI识别任务造成了极度的挑战。在渲染显示方面,由于(θ, Φ)维度信息的缺失会引起渲染物体缺乏各向异性的光线,从而显得不够逼真。好莱坞电影大片中渲染的逼真人物大多采用了光场/反射场这一技术才得以使得各种科幻的飞禽走兽能栩栩如生。
1.3、光场4D参数化
根据7D全光函数的描述,如果有一个体积可以忽略不计的小球能够记录从不同角度穿过该小球的所有光线的波长,把该小球放置在某个有限空间中所有可以达到的位置并记录光线波长,那么就可以得到这个有限空间中某一时刻所有光线的集合。在不同时刻重复上述过程,就可以实现7D全函数的完备采集。Google Daydream平台Paul Debevec团队在Steam平台上推出的《Welcome To Light Field》就是采用了类似的思想实现的。然而,采集的数据量巨大。按照当前的计算机技术水平,难以对7D光场这么庞大的数据进行实时处理和传输。因此有必要对7D光场进行简化降维。
如图6所示,美国斯坦福大学的Marc Levoy将全光函数简化降维,提出(u,v,s,t)4D光场模型[9]。Levoy假设了两个不共面的平面(u,v)和(s,t),如果一条光线与这两个平面各有一个交点,则该光线可以用这两个交点唯一表示。Levoy提出的光场4D模型有一个重要的前提假设:在沿光线传播方向上的任意位置采集到的光线是一样的。换句话说,假设任意一条光线在传播的过程中光强不发生衰减且波长不变。考虑到日常生活中光线从场景表面到人眼的传播距离非常有限,光线在空气中的衰减微乎其微,上述Levoy提出的假设完全合理。
Levoy提出的光场4D模型并不能完备地描述三维空间中所有的光线,与(u,v)或(s,t)平面所平行的光线就不能被该4D模型所表示,例如图6中红色标示的光线。尽管Levoy提出的4D模型不能完备描述三维空间中所有的光线,但可以完备描述人眼接收到的光线。因为当光线与人眼前视方向垂直时,该光线不会进入人眼。因此,这部分光线并不影响人眼视觉成像。Levoy提出的4D模型既降低了表示光场所需的维度,同时又能完备表示人眼成像所需要的全部光线。光场4D模型得到了学术界的广泛认可,关于光场的大量研究都是在此基础上展开。
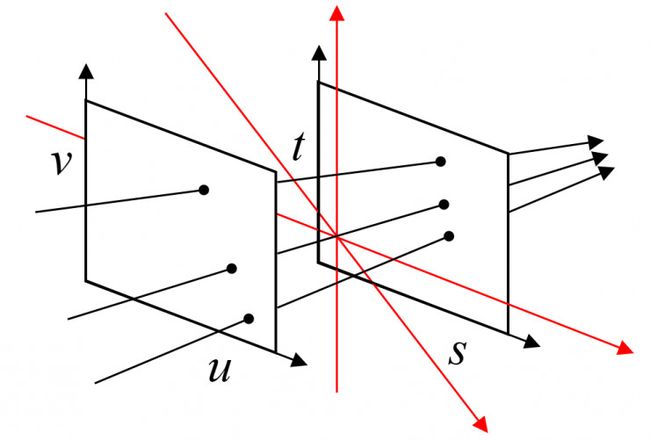 图 6. 4D光场模型
图 6. 4D光场模型
4D光场模型具有可逆性,既能表示光场采集,又能表示光场显示。如图7所示,对于光场采集模型,右侧物体发出的光线经过(s,t)和(u,v)平面的4D参数化表示,被记录成4D光场。对于光场显示模型,经过(u,v)和(s,t)平面的调制可以模拟出左侧物体表面的光线,从而使人眼“看见”并不存在的物体。
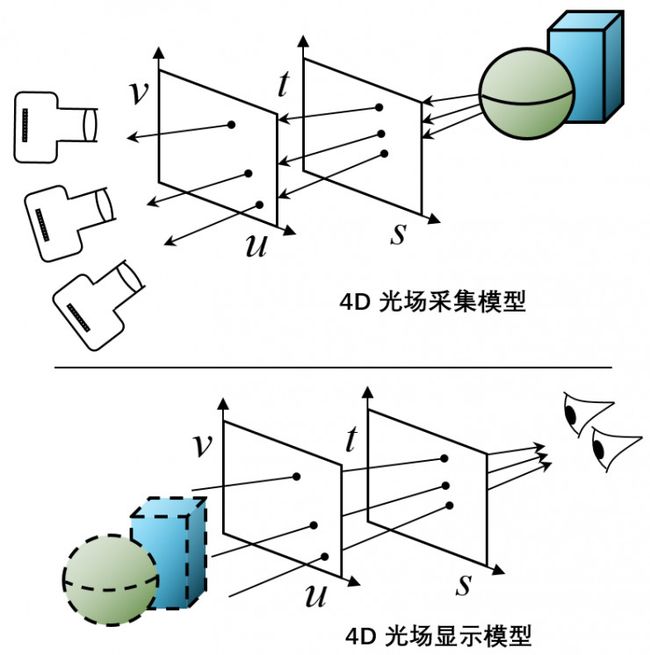 图 7. 4D光场模型的可逆性
图 7. 4D光场模型的可逆性
如图8所示,物体表面A、B、C三点发出的光线首先到达(u,v)平面,假设(u,v)平面上有三个小孔h1、h2、h3,则A、B、C三点发出的光线经三个小孔分别到达(s,t)平面。A、B、C三点在半球范围内三个不同方向的光线被同时记录下来,例如A点三个方向的光线分别被(s,t)平面上A3’、B3’、C3’记录。如果(u,v)平面上小孔数量更多,且(s,t)平面上的像素足够密集,则可以采集到空间中更多方向的光线。需要说明的是,图8中展示的是(u,v)(s,t)光场采集模型在垂直方向上的切面图,实际上可以采集到A、B、C三点9个不同方向(3x3)的光线。
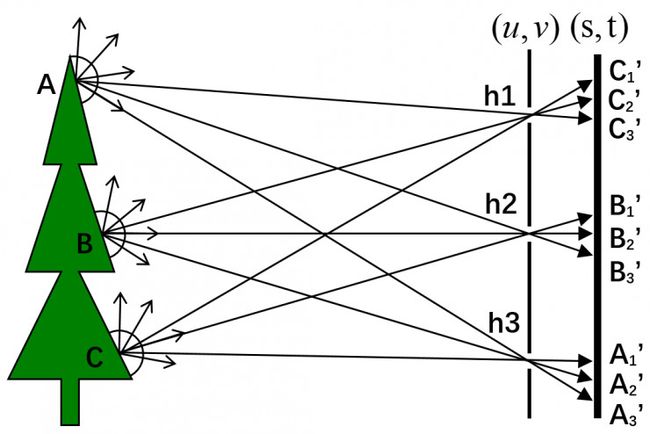 图 8. 4D光场采集空间光线示意图
图 8. 4D光场采集空间光线示意图
图像分辨率和FOV(Field Of View)是传统相机成像性能的主要指标。衡量4D光场的指标不仅有图像分辨率和FOV,还有角度分辨率和FOP(Field Of Parallax)。 图9展示了基于微透镜阵列的光场相机的光路示意图,物体表面发出的光线进入相机光圈,然后被解耦和并分别被记录下来。以B点为例,发光点B在半球范围内发出各向异性的光线,但并不是所有的光线都进入相机光圈,只有一定角度内的光线被成功采集,被光场相机采集到的光线的角度范围决定了能够观察的最大视差范围,我们记这个角度为FOP。换句话说,图9中光场相机只能采集到B点FOP角度范围内的光线。但FOP的大小随着发光点与光场相机的距离远近而不同,因此通常采用基线的长度来衡量FOP的大小,图9中主镜头的光圈直径等效为基线长度。
图9中B点在FOP角度范围内的光线被微透镜分成4x4束光线,光场相机的角度分辨率即为4x4,光场相机的角度分辨率表征了一个发光点在FOP角度范围内的光线被离散化的程度。而基于小孔成像模型相机的角度分辨率始终为1x1。光场的视点图像分辨率同样表征了被采集场景表面离散化程度,成像传感器分辨率除以角度分辨率即为视点图像分辨率。
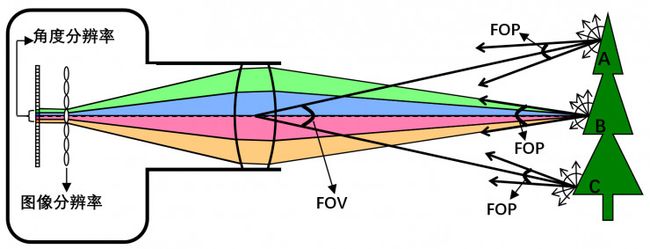 图 9. 透镜阵列4D光场的图像分辨率和角度分辨率
图 9. 透镜阵列4D光场的图像分辨率和角度分辨率
基于相机阵列的光场相机同样可以用视点图像分辨率、角度分辨率、FOV、FOP四个参数来衡量光场相机的各方面性能。如图10所示为4x4相机阵列,B点半球范围内发出的光线中FOP角度范围内的光线被相机阵列分成4x4束并分别被采集。相机的个数4x4即为角度分辨率,单个相机成像传感器的分辨率即为视点图像分辨率。所有相机FOV的交集可以等效为光场相机的FOV。基于相机阵列的光场相机的基线长度为两端相机光心之间的距离。一般而言,基于相机阵列的光场相机比基于微透镜阵列的光场相机具有更长的基线,也就具有更大的FOP角度。
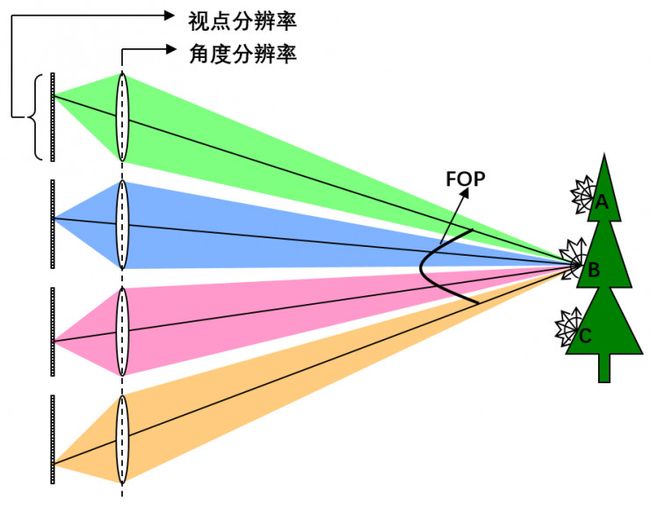 图 10. 相机阵列4D光场的图像分辨率和角度分辨率
图 10. 相机阵列4D光场的图像分辨率和角度分辨率
1.4、光场4D可视化
4D光场数据可以表示为(Vx, Vy, Rx, Ry),其中(Vx, Vy)表征了角度分辨率,表示有Vx*Vy个视点(View)图像;(Rx, Ry)表征视点图像分辨率,表示单个视点图像的分辨率为Rx*Ry。如图11中上侧图展示了7x7光场的可视化,表示共有49个视点图像,每个视点的图像分辨率为384x512。视点图像分辨率越高,包含的细节越多。角度分辨率越高,单位角度内视点数量越多,视差过度就越平滑。角度分辨率越低,视点就越稀疏,观看光场时视点跳跃感越明显。假设在10度的可视角度内水平方向上包含了7个视点,相邻视点间的角度为1.67度,在2米的观看距离,相邻两个视点的水平距离为29毫米。当视点个数减少,相邻视点的空间距离变大,观看者移动观看位置时就会感到明显的视点跳跃。
光场中任意两个视点间都存在视差,将光场(Vx, Vy, Rx, Ry)中的部分视点图像放大,如图11中下侧所示;同一行所有视点图像之间只有水平视差,没有垂直视差;同一列所有视点图像之间只有垂直视差,没有水平视差。
 图 11. 光场角度分辨率和视点分辨率可视化分析
图 11. 光场角度分辨率和视点分辨率可视化分析
光场作为高维数据,不便于可视化分析。为了更好的分析光场中的视差,往往将光场中某一个水平/垂直视点上所有图像的同一行/列像素堆成一幅2D图像,称之为光场切片数据(Light Field Slice)。光场切片图像可以将光场中的水平视差和垂直视差可视化,便于直观分析。如图12中蓝色线条所在的行像素堆叠后就形成了图12中下侧的光场切片图像。类似的,如图11中将光场中同一垂直视点上所有绿色线条所在的列像素堆叠后就形成了图11中右侧的光场切片图像。
 图 12. 光场切片图例
图 12. 光场切片图例
1.5、光场技术展望
从全世界光场技术的发展趋势来看,美国硅谷的科技巨头争相布局和储备光场技术,有些甚至已经出现了Demo应用。在光场的采集方面,例如Google在Steam平台上发布的《Welcome to Light Field》、Lytro光场相机。在光场显示方面,例如Magic Leap采用的两层离散光场显示技术、NVIDIA发布的近眼光场显示眼镜、Facebook旗下Oculus的道格拉斯•兰曼团队正在研发的光场VR头盔。
光场技术的研究主要分为两大方面,包括光场采集和光场显示。光场采集技术相对更成熟,在某些To B领域已经基本达到可以落地使用的程度。光场采集主要是提供3D数字内容,一次采集可以推广使用,这并不要求由个体消费者来完成,一般都是由一个团队来完成。因此对于光场采集系统的硬件成本、体积、功耗有更大的可接受度。相比之下,光场显示是偏向To C的产品,个体用户在成本、体积、功耗、舒适度等多方面都极度挑剔。光场显示在多个高校和科研机构已经完成了原形样机的开发,在通往商业化实用的道路上,目前最大的挑战就在于光场显示设备的小型化和低功耗。
Magic Leap One的推出似乎并没有达到消费者原本对它的期待,这其中的差距是可以解释的。是否具备光场显示对于VR/AR头盔来说最大的区别是能否解决VAC (Vergence–Accommodation Conflicts) 问题,关于VAC的解释具体可参见《Mars说光场(2)— 光场与人眼立体成像机理》。当前的VR/AR头盔只有一层呈像平面,会引起头晕、近视等VAC问题。当光场VR/AR头盔中呈现无穷多层不同距离上的呈像平面时,VAC的问题就会得到完美解决。然而在可预见的未来,实现无穷多层呈像平面的光场显示技术是不现实的。换句话说,在可预见的未来,让个体消费者能使用上100%完美理想的光场显示设备,这本来就是一个不切实际的目标。因此只能尽量增加光场中呈像平面的层数,VAC的问题随着呈像层数的增加就会得到越发明显的改善。当呈像层数达到一定数量以后,人眼已经无法明显感受到VAC。就像手机屏幕的分辨率达到一定密度以后,虽然仍是由离散的像素点构成,但人眼已经无法分辨。因此,并不需要刻意追求无穷多层可连续聚焦的光场显示。
在Magic Leap One上市之前,所有商业化的显示设备都是在追求分辨率、色彩还原度等指标的提升,而从来没有显示维度的突破。Magic Leap One是目前全世界范围内第一款具有大于1层呈像平面的商业化头戴显示设备。Magic Leap One的2层呈像平面相比HoloLens的1层呈像平面在视觉体验上并不会带来明显的改善,但是在对长期佩戴所引起的疲劳、不适、近视等问题是会有所改善的。然而用户对此并不买账,可以解释为三方面的原因:(1)目前VR/AR设备的用户使用时间本来就很短,用户对于缓解疲劳等隐性的改善没有立即直观的体验,这些隐性的改善往往会被忽略。(2)现代消费人群没有体验过黑白电视和CRT显示器,在新兴消费人群中1080P、全彩色、无色差等是他们对显示设备的底线要求,而且这种底线还在逐年提高。当Magic Leap One上市时,一旦分辨率或色彩还原度低于消费者能接受的底线,纵然光场显示带来了其他的隐性改善,但消费者会在第一印象中产生抗拒情绪。相比手机的高质量显示,Magic Leap One和HoloLens在显示的质量上都有所退化,对于已经习惯2K的用户而言,很难接受这样的显示质量退化。(3)Magic Leap One的呈像平面从1层增加到2层,这并代表其视觉体验就能改善2倍。只有当呈像平面达到一定数量以后,人眼才能感觉到视觉呈像质量的明显改善。
尽管Magic Leap的2层光场显示并没有得到用户的高度认可,但它在显示的维度上实现了0到1的突破。光场显示层数能够从单层增加到2层,这是光场显示技术商业化的良好开端,后续从2层增加到10层甚至20层只是时间的问题了。回顾手机发展历史,手机显示经历了从大哥大时代的单行黑白屏到现在iPhone X约2K全彩显示屏。我相信目前光场显示设备就像30年前的大哥大一样,正处于黎明前的黑暗,必然还需要经历多次的进化。一旦成功,其最终光场显示的效果相对目前的智能手机来说将会是革命性的进步。
1.6、参考文献
[1] E. N. Marieb and K. N. Hoehn, Human Anatomy & Physiology (Pearson, 2012).
[2] A. Gershun, “The light field,” Moscow, 1936, P. Moon and G. Timoshenko, translators, J. Math. Phys. XVIII, 51–151 (1939).
[3] Moon P, Spencer D E. The photic field[J]. Cambridge Ma Mit Press P, 1981, 1.
[4] Zhang C, Chen T. Light Field Sampling[J]. Synthesis Lectures on Image Video & Multimedia Processing, 2006(1):102.
[5] Javidi B, Okano F. Three-Dimensional Television, Video, and Display Technology[J]. Materials Today, 2003, 6(2):50.
[6] Ozaktas H M, Onural L. Three-Dimensional Television: Capture, Transmission, Display[J]. Thomas Telford, 2008, 2(1):487 - 488.
[7] E. Adelson and J. Bergen, “The plenoptic function and the elements of early vision,” in Computational Models of Visual Processing (MIT, 1991), pp. 3–20.
[8] Todd Gustavson, George Eastman House. Camera: A history of photography from daguerreotype to digital[M]. Sterling Innovation, 2012.
[9] M. Levoy and P. Hanrahan, Light field rendering[C]. Proceedings of ACM SIGGRAPH, 1996.
转载自:https://www.leiphone.com/news/201810/N14i2K6UmZzK5TcE.html
2、光场与人眼立体成像机理
【摘要】 — 人眼产生三维立体视觉来源于心理感知和生理感知。根据能够产生多少3D视觉信息,可以把现有显示设备分为4个层级。第1等级是传统的2D显示屏:只能产生仿射、遮挡、光照阴影、纹理、先验知识五方面的心理视觉暗示,从而“欺骗”大脑产生伪3D视觉。第2等级是眼镜式3D电影:能提供部分生理视觉信息(双目视差),但缺少移动视差和聚焦模糊。第3等级是VR头盔:具有更多的生理视觉信息,能同时提供双目视差和移动视差,但仍然缺乏聚焦模糊。第4等级是光场显示:能提供所有的心理和生理视觉信息,可以在视觉上逼真重现真实世界。
2.1、人眼的立体成像机理
2.1.1 心理感知
众所周知,人眼能感知到远近深度信息的一个重要方面是因为我们拥有两只眼睛,从而可以从双目视差中判断物体深度。然而双目视差并不是我们感知三维世界的唯一途径。人眼对三维环境的感知主要可以分为心理感知和生理感知。其中心理感知主要是通过仿射、遮挡、光照阴影、纹理、先验知识五方面的视觉暗示[1,2],从而“欺骗”大脑感知到三维信息,如图1所示,尽管是在平面上绘图却能产生一定的三维视觉。
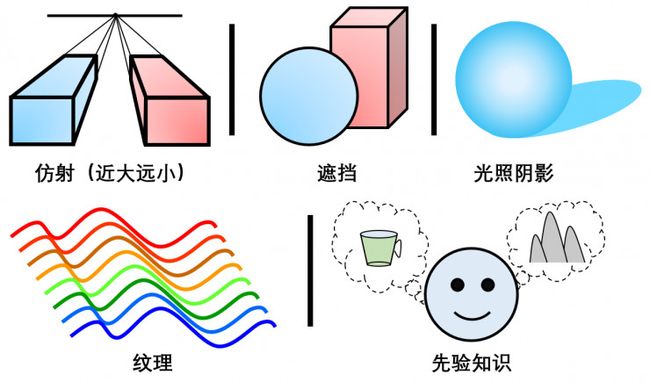 图 1. 人眼感知深度的心理暗示信息
图 1. 人眼感知深度的心理暗示信息
(1)仿射:其直观的感受是“近大远小”,随着物体与人眼的距离减小,物体在人眼的成像越大。
(2)遮挡:更近的物体会遮挡更远的物体,通过相互遮挡关系可以判断物体间的相对远近关系。
(3)光照阴影:不同方向的光照会在物体表面产生不同的阴影,通过对阴影模式的判断可以推断物体的三维形状。
(4)纹理:通过有规律重复的动/静态特征分布产生立体视觉。
(5)先验知识:人类在观看大量物体以后会总结一些基本的经验,例如天空中的飞机和风筝都非常小,但飞机比风筝距离人眼更远。
2.1.2 生理感知
上述五种心理感知上的立体视觉通过平面介质即可呈现,例如手机屏幕、电视屏幕、画布等。然而立体视觉的生理感知需要对人眼产生特殊的视觉刺激,无法通过2D平面介质呈现。立体视觉的生理感知主要包括双目视差、移动视差、聚焦模糊[3],分述如下。
(1)双目视差(binocular parallax):如图2所示,视差即同一个物体在左右眼中所成的像之间的轻微偏差。所观察的物体越近,则视差越大。所观察的物体越远,则视差越小。为了避免左右眼视差所产生的重影,人眼会动态的调节视线的汇聚方向。当我们观看漫天繁星时,双眼的视线方向几乎平行,当我们观察自己的鼻尖时,双眼的视线方向会相交于鼻尖,通过双眼汇聚的角度可以判断物体的远近。双目视差的感知必须依靠双目协同工作才能完成。
 图 2. 生理视觉信息(双目视差与双目汇聚)
图 2. 生理视觉信息(双目视差与双目汇聚)
(2)移动视差(motion parallax):如图3所示,当远近不同的物体在空间中移动时,在人眼中产生的位移会不同。当发生同样的空间移动时,远处的物体在人眼中产生的位移更小,近处的物体在人眼中产生的位移更大。例如当我们在移动的汽车上观看窗外的风景时,近处的树木总是飞快的向后移动,而远处的高山却移动缓慢。与双目视差不同,单眼就可以感知到移动视差。例如鸽子虽然有双眼,但是两只眼睛位于头部的两侧,双眼的视野范围并不重合,因此鸽子无法依靠双目视差来感知深度。鸽子主要依靠移动视差来判断物体远近,从而完成着陆和啄食等动作。
 图 3. 生理视觉信息(移动视差)
图 3. 生理视觉信息(移动视差)
(3)聚焦模糊(Accommodation):如图4所示,人眼的睫状肌扮演着相机镜头的调焦功能,从而使聚焦平面上的物体清晰成像,非聚焦平面的物体成像模糊。如图4所示,当睫状肌紧绷时,人眼聚焦在近处平面。当睫状肌舒张时,人眼聚焦在远处平面。单眼即可感知到聚焦模糊。当我们举起大拇指,用单眼去观察大拇指上的指甲盖纹理时,门口的盆栽以及墙上的油画变得模糊了。当我们用单眼试图看清盆栽或者油画时,大拇指却模糊了。根据睫状肌的屈张程度和对应的聚焦模糊反馈,视觉系统可以判断出物体的相对远近。
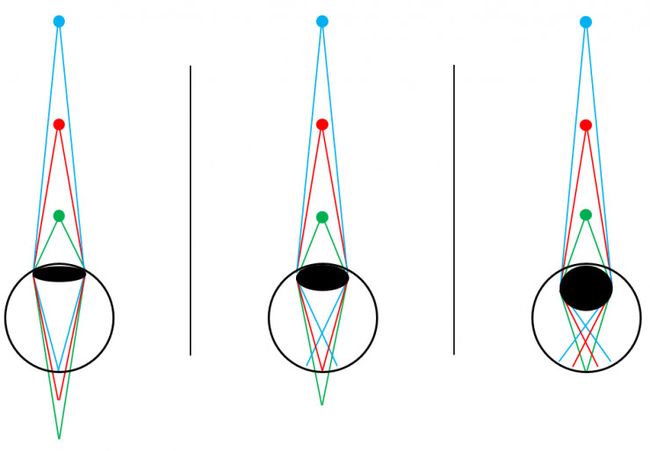 图 4. 生理视觉信息(聚焦模糊)
图 4. 生理视觉信息(聚焦模糊)
2.2、如何满足人眼的视觉要求?
2.2.1 传统显示屏
从黑白到彩色,从CRT到LCD/OLED,从720p到4K,显示设备的色彩还原度和分辨率在不断的提高,然而却始终没有显示维度的突破。根据7D全光函数的描述,目前的2D显示屏可以在(x, y)位置显示不同的像素。但每个像素在可视角度(一般为120度)范围内不同的方向发出的光线却是近似相同(或同向衰减)。因此2D显示屏只能提供各向同性的光线,不能呈现光线的方向信息(θ, Φ),如图5所示。换句话说,传统显示屏只能呈现(x, y, λ, t)四个维度的信息,只能提供上述仿射、遮挡、光照阴影、纹理、先验知识这五种心理感知信息。然而对于双目视差、移动视差、聚焦模糊三方面的生理感知却无能为力。首先、左右眼从显示屏接收到的图像完全一样,因此不能产生双目视差。其次、当人眼在屏幕前左右移动时,显示屏所呈现的内容会产生相同的位移,因此无法提供移动视差。最后,显示屏上所有像素的实际发光位置到人眼的距离都是一致的,并不会引起人眼睫状肌的屈张,所以显示屏无法提供动态聚焦。
 图 5. 传统2D显示器各向同性光学特性
图 5. 传统2D显示器各向同性光学特性
2.2.2 3D电影
3D电影除了提供传统显示屏的心理视觉感知信息,还能提供双目视差这一生理视觉感知信息。如图6所示,3D电影通过一副立体眼镜将两幅具有细微偏差的图像分别呈现给左右眼(当取下立体眼镜,直视大屏时会看到两幅重叠的图像),让人眼感知到双目视差,进而让大脑融合左右眼图像产生三维信息。立体眼镜的工作原理又包括分光式、偏振式、快门式三种,这里不再展开讨论。然而,3D电影只提供了双目视差这一种生理视觉信息,并不能提供移动视差和聚焦模糊。举个例子,如果是一场真人话剧,左侧的观众应该看到演员的右侧脸;而右侧的观众应该看到演员的左侧脸。然而在3D电影院中,左侧和右侧的观众看到的都是演员的同一个侧脸。即使观众戴着立体眼镜跑动到电影院的任一位置,所看到的仍然是同一个视点。换句话说,3D电影院呈现的图像并不会因为观看位置的移动而更新视点图像。由于缺乏移动视差和聚焦模糊,观看3D电影时双目视差告诉大脑看到了3D场景,而移动视差和聚焦模糊又告诉大脑看到了2D场景,大脑会在3D和2D这两种状态之间不停的切换。由于双目视差与移动视差和聚焦模糊之间的冲突,从而导致“烧脑”。这也是大部分人群第一次体验3D电影时会产生不适感的主要原因。当大脑适应这种相互冲突的3D视觉后,不适感会明显减轻,但是所体验的视觉效果还是无法与真实三维世界相媲美。
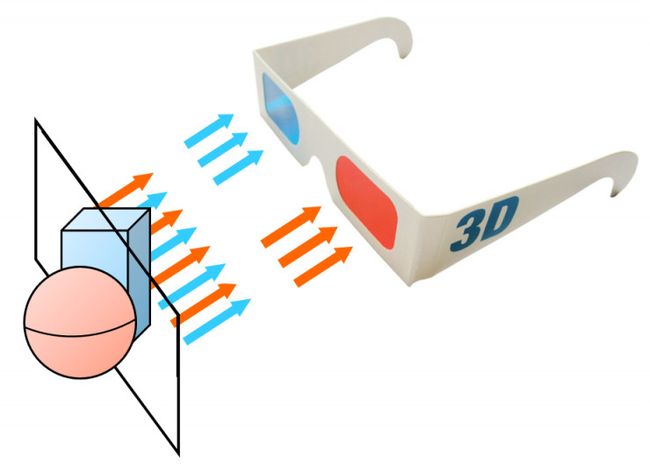 图 6. 3D电影产生立体视觉原理
图 6. 3D电影产生立体视觉原理
2.2.3 虚拟现实(VR/AR)
虚拟现实(Virtual Reality,VR/AR/MR都在本文讨论范围内)头盔属于头戴显示设备(HMD,Head Mounted Display)的一种[4,5]。相比3D电影,虚拟现实头盔不仅能提供双目视差,还能提供移动视差,从而带来更丰富逼真的立体视觉体验。虚拟现实头盔主要利用准直放大透镜(Collimating Lens)将眼前的显示屏图像放大并拉远。如图7所示,虚拟现实头盔的显示屏与透镜光心的距离略小于透镜焦距,屏幕上某一真实像素发出的光线经透镜折射进入人眼,沿着折射后光线的反向延长方向,人眼将感知到较远处的虚拟像素。同样的两套准直放大光学显示系统分别为左右眼提供不同的图像。
 图 7. 虚拟现实头盔准直放大光路示意图
图 7. 虚拟现实头盔准直放大光路示意图
相比于3D电影院,VR头盔最大的改进之处在于它能提供移动视差。当人眼移动到不同的位置或旋转到不同的方向时,VR头盔会提供不同视点的图像。仍然以观看演员为例,在3D电影院中无论观众移动到任何位置或旋转到任意方向,所看到的都是演员的同一个侧脸。而在VR中,随着观众的移动,可以看到演员的左侧脸、右侧脸、下巴等不同的视点。正是由于VR所提供的移动视差,使得观众从导演预先设定的观看视角中脱离出来,可以从自己喜欢的角度去观察。这是VR能够提供强烈沉浸感的主要原因之一。
那么VR头盔是不是就能在视觉上完美地重现真实三维世界呢? 答案是:还差一个关键要素,那就是聚焦模糊。VR头盔能同时提供双目视差和移动视差,但目前在售的VR头盔中都不能提供聚焦模糊(Accommodation)。VR头盔中使用的显示屏与主流手机使用的显示屏都属于LCD/OLED范畴。举个例子,真实环境中人眼看到远处的高山和近处的人物是分别接收了从远近不同地方发出的光线。然而VR屏幕中出现的高山和人物都是从距离人眼相同距离的显示屏上发出的光线。无论人眼聚焦在“远处”的高山还是“近处”的人物,睫状肌都是处于相同的屈张程度,这与人眼观看实际风景时的聚焦模糊状态是不相符的[6,7]。
引起VR眩晕主要有两方面的原因:(1)运动感知与视觉感知之间的冲突;(2)视觉感知中双目视差与聚焦模糊之间的冲突;详述如下。
人体主要依靠前庭、本体感觉、视觉三方面的感知途径综合推断出人体的位置、运动状态、姿态等信息。一方面,人耳的前庭内有3个半规管,每个半规管就像半瓶水一样;当人体运动时,前庭内的“半瓶水”就会晃动,再加上本体感觉的信息,大脑从而推断出目前的运动加速度和姿态。另一方面,人眼视觉能感知周边三维环境,从而反向推断出目前自身的位置等信息,类似与SLAM的工作原理[8]。在早期的VR设备中,由于定位精度、渲染速度,显示屏刷新频率等技术的限制,当身体移动时,VR头盔呈现画面并不准确和及时。例如在VR中“走独木桥”,身体已经移动而双目图像并未及时更新,此时前庭和本体感觉告诉大脑身体已经移动,而VR视觉告诉大脑身体没有移动,从而导致大脑产生困惑,这可以总结为“身已动,而画面未动”。再例如在VR中“坐过山车”,双目图像快速的切换让大脑以为身体在快速的上下移动,而实际上身体却是静止的坐在椅子上,会导致大脑产生困惑,这可以总结为“画面已动,而身未动”。随着VR设备在屏幕刷新率的提高、移动端图像渲染帧率的提升、交互定位精度的提高,以及万向跑步机和体感椅的出现,引起VR眩晕的第(1)方面原因已经得到大幅缓解。
第(2)方面原因引起的VR眩晕才是当前亟待解决的主要问题。VR头盔佩戴者始终聚焦在一个固定距离的虚拟屏幕上,而不能随着虚拟显示物体的远近重聚焦(refocus)。例如通过VR头盔观看远处的高山时,人眼通过双目视差感知到高山很远,但人眼并没有实际聚焦到那么远。类似的,当通过VR头盔观看近处的人物时,人眼仍然聚焦在虚拟屏幕上,与双目视差所呈现的人物距离不符。由于双目视差和聚焦模糊所呈现的远近距离不同,从而导致大脑产生深度感知冲突,进而引起视觉疲劳[9]。这种现象在学术上称为ACC或者AVC(Accommodation-Convergence Conflics, Accommodation-Vergence Conflics)[10,11,12]。与此同时,目前VR头盔的呈像平面为固定焦距,长期佩戴存在引起近视的潜在风险。如果希望VR取代手机成为下一代移动计算平台,首先就需要解决VR设备长时间安全使用的问题。目前来看,光场显示是解决这一问题的最佳方案之一。
2.2.4 光场显示
光场显示包含全光函数中所有维度的光线信息,可以提供上述所有的心理视觉感知信息和生理视觉感知信息。目前光场显示主要有:体三维显示(Volumetric 3D Display)、多视投影阵列(Multi-view Projector Array)、集成成像(Integral Imaging)、数字全息、多层液晶张量显示等多种技术方案。《Mars说光场(4)— 光场显示》会进一步分析光场显示技术的实现原理。
随着显示技术的演进,显示设备能提供越来越丰富的视觉感知信息。根据所能呈现的视觉信息,可以将显示设备分为4个等级,如图8所示。2D平面显示只能提供心理视觉信息来“欺骗”大脑产生三维立体视觉,属于第1等级。眼镜式3D电影不仅能提供心理视觉信息,还能提供部分生理视觉信息(双目视差),属于第2等级。现阶段的VR/AR/MR头盔在眼镜式3D电影的基础上进一步增加了移动视差,属于第3等级。光场是终极显示方式,能提供所有的心理和生理视觉信息,属于第4等级。
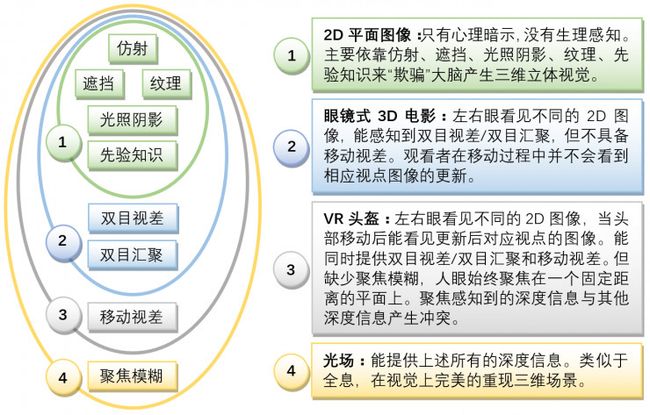 图 8. 不同等级显示技术所能提供的视觉信息范畴
图 8. 不同等级显示技术所能提供的视觉信息范畴
2.3、参考文献
[1] Geng J.Three-dimensional display technologies[J]. Advances in Optics and Photonics,2013, 5(4): 456-535.
[2] B. Blundell and A. Schwarz, Volumetric Three Dimensional Display System
(Wiley, 2000).
[3] T. Okoshi, Three-Dimensional Imaging Techniques (Academic, 1976).
[4] O. Cakmakci and J. Rolland, “Head-worn displays: a review,” J. Disp. Technol. 2, 199–216 (2006).
[5] D. Cheng, Y. Wang, H. Hua, and M. M. Talha, “Design of an optical see-through headmounted display with a low f-number and large field of view using a free-form prism,” Appl. Opt. 48, 2655–2668 (2009).
[6] T. Inoue and H. Ohzu, ―Accommodation responses to stereoscopic three-dimensional display,‖ Appl. Opt., vol. 36, 4509-4515 (1997)
[7] Vienne C, Sorin L, Blondé L, et al. Effect of the accommodation-vergence conflict on vergence eye movements[J]. Vision Research, 2014, 100:124-133.
[8] Davison A J, Reid I D, Molton N D, et al. MonoSLAM: Real-Time Single Camera SLAM[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2007, 29(6):1052-1067.
[9] D. M. Hoffman, A. R. Girshick, K. Akeley, and M. S. Banks, “Vergence–accommodation conflicts hinder visual performance and cause visual fatigue,” J. Vis. 8(3):33, 1–30 (2008).
[10] Mackenzie K J, Watt S J. Eliminating accommodation-convergence conflicts in stereoscopic displays: Can multiple-focal-plane displays elicit continuous and consistent vergence and accommodation responses?[J]. Proceedings of SPIE, The International Society for Optical Engineering, 2010, 7524:752417-752417-10.
[11] Hoffman D M, Banks M S. Disparity scaling in the presence of accommodation-vergence conflict[J]. Journal of Vision, 2010, 7(9):824.
[12] Takaki Y. Generation of natural three-dimensional image by directional display: Solving accommodation-vergence conflict[J]. Ieice Technical Report Electronic Information Displays, 2006, 106:21-26.
转载:https://www.leiphone.com/news/201810/g0gGjodYqf91S6Ak.html
3、光场采集
【摘要】 — 光场显示能在视觉上完全重现真实世界,但在显示光场以前首先要采集光场,否则将会是“巧妇难为无米之炊”。传统相机拍摄的2D图片不能用于光场显示[1],因此需要专业的光场采集设备。相关研究者已经建立了一系列光场采集的理论[2],并在光场采集技术的发展过程中出现了多种设计方案,受到广泛关注和研究的主要有三种设计思路:
(1)基于微透镜阵列(Microlens Array)的光场采集;
(2)基于相机阵列(Camera Array)的光场采集[3];
(3)基于编码掩膜(Coded Mask)[4]的光场采集。
3.1、基于微透镜阵列的光场采集
基于微透镜阵列的光场采集最早可以追溯到1908年Lippmann提出的集成成像(Integral photography)[5],集成成像为基于微透镜阵列的光场采集奠定了重要的理论基础。关于集成成像的发展历史,可以参考Roberts在2003年的详细梳理[6]。基于集成成像理论,MIT的Adelson在1992年尝试采用微透镜阵列来制造光场相机[7],斯坦福Levoy将集成成像应用于显微镜,实现了光场显微镜[8]。
基于透镜阵列的光场采集主要依靠在成像传感器与主镜头之间加入一片微透镜阵列,物体表面光线首先经过主镜头,然后经过微透镜,最后到达成像传感器(e.g. CCD/CMOS)。如图1所示,物体表面A点在FOP角度范围内发出的光线进入相机主镜头并聚焦于微透镜,微透镜将光线分成4x4束,并被成像传感器上对应的16个像素记录。类似的,空间中其它发光点,例如B点和C点,在其FOP角度范围内的光线都被分成4x4束并被分别记录。
微透镜阵列的主要作用是将物体表面同一点在一定角度范围内的各个方向发出光线进行离散化解耦,图1中的微透镜将光线离散化为4x4束,离散化程度由微透镜光学参数、主透镜光学参数及微透镜与成像传感器之间的距离等多方面因素决定。
参照光场4D模型,微透镜阵列好比(s, t)平面,成像传感器好比(u, v)平面。在基于微透镜阵列的光场采集模型中,(s, t)平面微透镜的数量决定了光场的图像分辨率。(u, v)平面像素数量决定了能采集光线的总数量,(u, v)平面像素总量与(s, t)平面微透镜数量的比值即为光场角度分辨率,也即采集视点个数。
 图 1. 基于微透镜阵列的光场采集原理示意图
图 1. 基于微透镜阵列的光场采集原理示意图
基于微透镜阵列的光场采集具有体积小,单次拍摄成像等优点。但也存在两个明显的缺陷,一方面是单视点的图像分辨率损失严重[9],例如使用4K(4096*2160)的图像传感器采集4x4视点的光场,则图像分辨率在水平方向和垂直方向都降低到原分辨率的四分之一,既单个视点图像分辨率只有1024*540。另一方面是采集光场的FOP角度较小,也即视差较小,只能在较小的角度范围内变换视点。
尽管存在上述的缺点,但由于总体成本在可控范围内,基于微透镜的光场采集方案是商业化光场相机主要采用的方案。目前已经商业化的光场相机主要包括美国的Lytro和德国的Raytrix。Lytro是一款基于微透镜阵列的手持光场相机,由斯坦福大学Ren Ng(Marc Levoy的博士生)在2005年提出 [10,11],并分别于2011年和2014年正式向市场推出第一代和第二代手持式光场相机Lytro[12]。相比传统相机,Lytro的关键设计是在传统相机中嵌入一块微透镜阵列,如图2所示。物体发出的光线被主透镜聚焦在微透镜阵列平面,微透镜阵列将光线分开并被图像传感器分别记录下来,从而同时记录了不同方向上光线的强度。
 图 2. 美国Lytro基于微透镜阵列的光场相机
图 2. 美国Lytro基于微透镜阵列的光场相机
Raytrix [13]是德国一家创业公司,同样是基于微透镜阵列的便携式光场相机[14]。Lytro主要面向大众普通用户,而Raytrix不仅面向普通用户还面向工业和科研应用领域,如图3所示。Raytrix扩大了采集光场的深度范围[15]并开发了一套自动标定算法用于标定光场相机[16]。
 图 3. 德国Raytrix基于微透镜阵列的光场相机
图 3. 德国Raytrix基于微透镜阵列的光场相机
Adobe Systems Inc. 的Todor Georgeiv在2006年研究了视点分辨率与角度分辨率之间的互相平衡关系[17],在2008年提出了一种统一的光场相机仿射光路理论[18]并提高光场分辨率[19],基于该理论框架构造的光场相机如图4所示。严格来说,Todor Georgeiv提出的光场相机与上述Lytro和Raytrix的基于微透镜阵列的光场相机并不完全相同。图4中透镜阵列更靠近相机主透镜位置,解耦合后的光线在成像传感器上形成的图像与Lytro或Raytrix并不相同,因此从成像传感器原始数据提取光场的算法也与Lytro和Raytrix不同。
 图 4. 美国Adobe Systems Inc.光场相机
图 4. 美国Adobe Systems Inc.光场相机
3.2、基于相机阵列的光场采集
基于相机阵列的光场采集不需要对相机进行改造,但需要增加相机的数量。光线从物体表面发出,分别进入多个相机镜头,并分别被对应的成像传感器记录。如图5所示为4x4相机阵列,A点在半球范围内发出各向异性的光线,其中FOP角度范围内的光线进入了相机阵列,并被分成4x4束光线,每束光线被对应的镜头聚焦在成像传感器上,由此A点各向异性的光线被离散化为4x4束并被分别记录。
对比图1中基于微透镜的光场采集方案,相机阵列通过多个镜头将物体表面同一点在一定角度内各向异性的光线解耦和,并离散为多束光线分别记录。解耦和后的离散化程度由相机阵列的规模决定。相机数量越多,离散化程度越高。
参照光场4D模型,图5中镜头阵列好比(s, t)平面,成像传感器阵列好比(u, v)平面。(s, t)平面镜头的数量,也即相机的数量,决定了光场视点个数。(u, v)平面所有像素数量决定了能采集光线的总数量。(u, v)平面像素总量与(s, t)平面镜头数量的比值即为单个视点分辨率。一般而言,相机阵列中各个相机成像传感器的分辨率一致,所以单个相机成像传感器的分辨率即为光场视点分辨率。
 图 5. 基于相机阵列的光场采集示意图
图 5. 基于相机阵列的光场采集示意图
相比基于微透镜阵列的光场相机,基于相机阵列的光场采集方案具有两个明显的优势:(1)采集光场的FOP角度较大,也即视差较大,可以在较大的角度范围内变换视点。(2)图像分辨率不损失,因此单个视点的图像分辨率一般都高于基于微透镜阵列的光场相机。但基于相机阵列的光场采集方案也存在成本高昂,体积较大的明显缺陷,例如图6中Jason Yang于2002年在MIT搭建出全世界第一套近实时相机阵列[20],由8x8共64个相机组成,单个视点分辨率为320x240,光场采集速率为18FPS,延迟为80毫秒。
 图 6. Jason Yang于2002年在MIT实现的实时相机阵列
图 6. Jason Yang于2002年在MIT实现的实时相机阵列
斯坦福大学Bennett Wilburn在2000年实现了数据编码压缩的光场视频相机[21],之后进一步改进光场相机系统,在2004年展示了稠密光场相机阵列[22]。Bennett Wilburn设计的稠密光场相机阵列包含52个30fps的COMS成像单元,单个视点分辨率为640x480,如图7所示。
 图 7. Bennett Wilburn于2004年在斯坦福大学设计的稠密光场相机阵列
图 7. Bennett Wilburn于2004年在斯坦福大学设计的稠密光场相机阵列
Bennett Wilburn在2005年进一步增加相机数量到约100个,构建了大规模光场相机阵列[23],并搭建了三种不同类型的大规模光场相机,如图8所示,分别是(a)紧密排列的长焦镜头大规模相机阵列,主要用于实现高分辨率成像。(b)紧密排列的广角镜头大规模相机阵列,主要用于实现高速视频捕获和混合合成孔径成像。(c)分散排布的大规模相机阵列。
 图 8. Bennett Wilburn于2005年在斯坦福大学设计的大规模光场相机阵列
图 8. Bennett Wilburn于2005年在斯坦福大学设计的大规模光场相机阵列
由于硬件成本高昂,体积较大等缺点,目前To C端的应用中还没有采用基于相机阵列的光场采集方案。曹煊在2015年提出稀疏相机阵列光场采集方案[24],利用压缩感知和稀疏编码大大减少了相机数量,降低了硬件成本,但仍然存在体积大的问题。Pelican是美国硅谷的一家创业公司,正在尝试将相机阵列小型化。该公司在2013年实现了超薄高性能的相机阵列[25],如图9所示。通过光学设计的优化[26]和光场超分辨算法的应用[27,28],Pelican制造了小巧的相机阵列,并形成一个独立的光场相机模块。Pelican综合了多种方法在保持相机阵列轻薄的前提下提升了所采集光场分辨率[29,30]。
 图 9. 美国初创公司Pelican设计的超小体积高性能相机阵列
图 9. 美国初创公司Pelican设计的超小体积高性能相机阵列
3.3、基于编码掩膜的光场采集
基于微透镜阵列和基于相机阵列的光场采集都有一个共同点——“阵列”。前者通过多个微透镜构成阵列,牺牲图像分辨率换取角度分辨率。后者通过多个相机构成阵列,在不牺牲图像分辨率的情况下增加了角度分辨率,但是需要增加大量的图像传感器。总体而言,视点分辨率与角度分辨率是一对矛盾因素,总是此消彼长。通过增加成像传感器数量来抵消这一矛盾会造成硬件成本的急剧增加。
上述两种光场采集方案必须在图像分辨率和角度分辨率之间进行折中。学术界最新出现的基于编码掩膜的光场采集打破了这一局限。该方案通过对光场的学习去掉光场的冗余性,从而实现了采集更少的数据量而重建出完整的光场。
如图10所示,在传统相机的成像光路中加入一片半透明的编码掩膜,掩膜上每个像素点的光线透过率都不一样(也称为编码模式),进入光圈的光线在到达成像传感器之前会被掩膜调制,经过掩膜调制后的光线到达成像传感器。利用提前学习好的光场字典,从单幅采集的调制图像就可以重建出完整的光场。掩膜的编码模式理论上可以采用随机值,Kshitij Marwah证明了通过约束变换矩阵的转置与变换矩阵的乘积为单位矩阵可以得到优化的编码掩膜,采用优化后的编码掩膜可以重建出更高质量的光场。
 图 10. Kshitij Marwah于2013年在MIT设计的掩膜光场相机
图 10. Kshitij Marwah于2013年在MIT设计的掩膜光场相机
很多学者已经尝试利用编码掩膜来实现计算成像,例如国立台湾大学的Chia-Kai Liang 在2008年采用可编程的光圈结合多次曝光成像实现了光场采集[31]。美国MIT大学在掩膜相机方面的研究非常深入,MIT大学CSAIL的Anat Levin 于2007年采用编码光圈实现了深度图像的采集[32],MIT Media Lab的Veeraraghavan Ashok 在2007年采用掩膜实现了可以重聚焦的相机[33],后于2011年结合闪光灯和相机掩膜实现了对高频周期变化的图像进行高速摄像[34]。MIT Media Lab的Kshitij Marwah于2013年提出了基于掩膜的压缩光场采集[35]。
基于编码掩膜的光场采集方案最大的优势在于不需要牺牲图像分辨率就能提高角度分辨率。但该方案存在光场图像信噪比低的缺点,这主要是由于两方面的原因造成:
(1)掩膜的透光率不能达到100%,因此会损失光线信号强度,导致成像信噪比低;
(2)所重建的最终光场图像并不是成像传感器直接采集得到,而是通过从被调制的图像中进行解调制得到;本质上是基于已经学习的光场字典去“猜”出待重建的光场。
3.4、光场采集方案对比
上述三种主流的光场采集方案与传统相机总结对比如下表。
| 采集数据维度 | 优点 | 缺点 | |
| 传统相机 | R(x, y, λ, t) | 技术成熟, 价格低廉 | 只能采集平面图片, 等同于角度分辨率为1X1的低阶光场 |
| 微透镜阵列 | R(x, y, θ, Φ, λ, t) | 体积小, 成本较低 | 图像分辨率损失严重 |
| 相机阵列 | R(x, y, θ, Φ, λ, t) | 基线大,视差大 图像分辨率较高 |
成本高,体积大 硬件同步困难 |
| 编码掩膜 | R(x, y, θ, Φ, λ, t) | 体积小 分辨率不损失 |
信噪比低 光场质量下降 |
表1. 传统2D采集设备与光场采集设备的对比
基于微透镜阵列的光场采集具有体积小巧,硬件成本低等优点。但其缺点也很明显:1)光场视点图像分辨率损失严重,随着视点数量的增加,单个视点分辨率急剧降低。2)受到相机光圈的限制,光场中可观察的视差范围较小。
基于相机阵列的光场采集相比基于微透镜阵列的光场采集具有更多优点:1)视点分辨率不损失,由单个相机成像传感器决定。2)光场的视差范围更大。但基于相机阵列的光场采集仍然面临两个问题:1)需要的相机数量较多,硬件成本高昂,例如采集7x7视点的光场需要49个相机。2)相机同步控制复杂,数据量大,存储和传输成本高。
基于编码掩膜的光场采集打破了角度分辨率与视点图像分辨率之间的互相制约关系,利用“学习”的方法去掉光场冗余性,从少量信息中恢复光场。虽然存在信噪比降低的问题,但在2K时代,分辨率不损失这一优点使得该方案受到广泛关注。
3.5、参考文献
[1] Van Berkel C. Image Preparation for 3D-LCD[C]//Stereoscopic Displays and Virtual Reality Systems VI,1999.
[2] Chai J X, Tong X, Chan S C, et al. Plenoptic sampling[C]// Conference on Computer Graphics and Interactive Techniques. ACM Press/Addison-Wesley Publishing Co. 2000:307-318.
[3] Levoy M. Light Fields and Computational Imaging[J]. Computer, 2006, 39(8):46-55.
[4] Lanman D. Mask-based light field capture and display[C]// Ph.D. Dissertation, Brown University, 2011.
[5] Lippmann G. Epreuves reversibles. Photographies integrals[J]. Comptes-Rendus Academie des Sciences, 1908, 146(3):446-451.
[6] Roberts D E. History of Lenticular and Related Autostereoscopic Methods[J]. Leap Technologies Hillsboro, 2003.
[7] Adelson E H, Wang J Y A. Single Lens Stereo with a Plenoptic Camera[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1992, 14(2):99-106.
[8] Levoy M, Ren N, Adams A, et al. Light field microscopy[J]. Acm Transactions on Graphics, 2006, 25(3):924-934.
[9] Hoshino H, Okano F, Isono H, et al. Analysis of resolution limitation of integral photography[J]. Journal of the Optical Society of America A, 1998, 15(8):2059-2065.
[10] Ren N, Levoy M, Bredif M, et al. Light Field Photography with a Hand-Held Plenopic Camera[J]. Tech. Rep. CSTR Stanford Computer Science. 2005.
[11] R. Ng, “Digital light field photography”, PhD. Thesis, Stanford University, 2006.
[12] https://illum.lytro.com/
[13] www.raytrix.de
[14] Raytrix, “Digital imaging system for synthesizing an image using data recorded with a plenoptic camera,” European Patent EP09005628.4 (April 2009).
[15] Perwass C, Wietzke L. Single lens 3D-camera with extended depth-of-field[C]// IS&T/SPIE Electronic Imaging. International Society for Optics and Photonics, 2012.
[16] Heinze C, Spyropoulos S, Hussmann S, et al. Automated Robust Metric Calibration Algorithm for Multifocus Plenoptic Cameras[J]. IEEE Transactions on Instrumentation & Measurement, 2016, 65(5):1197-1205.
[17] Georgeiv T, Zheng K C, Curless B, et al. Spatio-angular resolution tradeoffs in integral photography[C]// Eurographics Symposium on Rendering Techniques, Nicosia, Cyprus. DBLP, 2006:263-272.
[18] Georgeiv T, Intwala C. Light Field Camera Design for Integral View Photography[J]. Adobe Technical Report, 2008.
[19] Lumsdaine A, Georgiev, T, Full resolution lightfield rendering, Adobe Technical Report, 2008.
[20] Yang J C, Everett M, Buehler C, et al. A real-time distributed light field camera[C]// Eurographics Workshop on Rendering. Eurographics Association, 2002:77-86.
[21] Wilburn B S, Smulski M, Lee K, et al. The Light field video camera[J]. Proceedings of SPIE - The International Society for Optical Engineering, 2001, 2002:29--36.
[22] Wilburn B, Joshi N, Vaish V, et al. High-Speed Videography Using a Dense Camera Array[C]// Computer Vision and Pattern Recognition, 2004. CVPR 2004. Proceedings of the 2004 IEEE Computer Society Conference on. IEEE, 2004:II-294-II-301 Vol.2.
[23] Wilburn B, Joshi N, Vaish V, et al. High performance imaging using large camera arrays[J]. Acm Transactions on Graphics, 2005, 24(3):765-776.
[24] Cao X, Geng Z, Li T. Dictionary-based light field acquisition using sparse camera array[J]. Optics Express, 2014, 22(20):24081-24095.
[25] Venkataraman K, Lelescu D, Duparr, et al. PiCam : an ultra-thin high performance monolithic camera array[J]. Acm Transactions on Graphics, 2013, 32(6):166.
[26] Tanida J, Kumagai T, Yamada K, et al. Thin Observation Module by Bound Optics (TOMBO): Concept and Experimental Verification[J]. Applied Optics, 2001, 40(11):1806.
[27] Baker S, Kanade T. Limits on Super-Resolution and How to Break Them[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 2000, 24(9):1167-1183.
[28] Bishop T E, Zanetti S, Favaro P. Light field superresolution[C]// IEEE International Conference on Computational Photography. IEEE, 2009:1-9.
[29] Georgiev T, Chunev G, Lumsdaine A. Superresolution with the focused plenoptic camera[C]// IS&T/SPIE Electronic Imaging. International Society for Optics and Photonics, 2011:78730X-78730X-13.
[30] Wanner S, Goldluecke B. Spatial and Angular Variational Super-Resolution of 4D Light Fields[M]// Computer Vision – ECCV 2012. Springer Berlin Heidelberg, 608-621.
[31] Liang C K, Lin T H, Wong B Y, et al. Programmable aperture photography: Multiplexed light field acquisition[J]. Acm Transactions on Graphics, 2008, 27(3):55.
[32] Levin A, Fergus R, Durand F, et al. Image and depth from a conventional camera with a coded aperture[C]// ACM SIGGRAPH. ACM, 2007:70.
[33] Veeraraghavan A, Raskar R, Agrawal A, et al. Dappled photography: mask enhanced cameras for heterodyned light fields and coded aperture refocusing[C]// SIGGRAPH. 2007:69.
[34] Veeraraghavan A, Reddy D, Raskar R. Coded Strobing Photography: Compressive Sensing of High Speed Periodic Videos[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 2011, 33(4):671-686.
[35] Marwah K, Wetzstein G, Bando Y, et al. Compressive light field photography using overcomplete dictionaries and optimized projections[J]. Acm Transactions on Graphics, 2013, 32(4):1-12.
转载:https://www.leiphone.com/news/201810/YX8QJhR2pn2hDtK4.html
4、光场显示
【摘要】 — 重现一个真实的三维世界,实现类似于《阿凡达》电影所展示的全息显示,是人类长久以来的梦想。如果能采集并投射出全光函数中7个维度的光线,将能使环境中所有人同时获得身临其境的全息视觉体验。光场作为理想的3D显示技术与传统2D显示有着明显的区别:传统的2D显示器只能提供仿射、遮挡、光照阴影、纹理、先验知识五方面心理视觉信息。光场显示除了能产生传统2D显示器的所有信息外,还能提供双目视差、移动视差、聚焦模糊三方面的生理视觉信息。在光场显示技术发展过程中,出现了多种光场显示技术方案,引起广泛关注和研究的主要有五种技术:
(1)体三维显示(Volumetric 3D Display);
(2)多视投影阵列(Multi-view Projector Array);
(3)集成成像(Integral Imaging);
(4)数字全息;
(5)多层液晶张量显示。关于三维显示的详细发展历史及其应用可以参见[1-11]。
 图 1. 电影《阿凡达》中描绘的光场全息三维军事沙盘
图 1. 电影《阿凡达》中描绘的光场全息三维军事沙盘
4.1、体三维显示
体三维显示技术[12,13]主要通过在空间中不同深度平面显示不同图像来实现。如图2所示,屏幕沿着Z轴方向快速往返运动,屏幕移动到不同位置时投影仪投射出不同的图像[14];当屏幕的移动足够快时,由于人眼的视觉暂留特性从而在眼前显示出三维立体图像。然而高速且匀速的往返直线运动难以实现,因此在体三维显示系统中将平移运动转化为旋转运动。
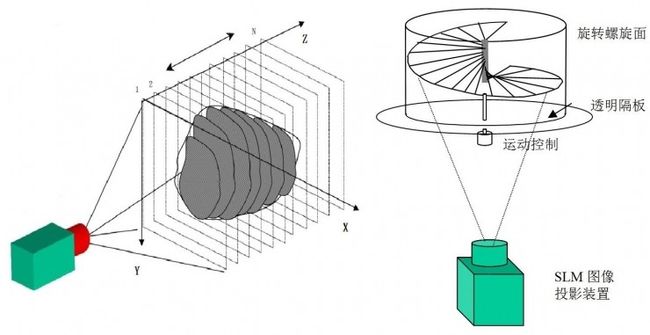 图 2. 平移式/旋转式体三维显示原理示意图
图 2. 平移式/旋转式体三维显示原理示意图
Langhans 从90年代开始研发体三维显示,并陆续推出了名为“Felix”的体三维显示样机。Langhans 在1996年发表了基于激光扫描的体三维显示技术[15],在1998年将体积进一步缩小形成便携式的体三维显示[16],后于2002年实现了可交互的体三维显示[17]。
 图 3. 德国Felix体三维显示系统
图 3. 德国Felix体三维显示系统
美国南加州大学Andrew Jones于2007年研制了360°体显示系统[18],如图4所示。该系统通过高速投影仪将图像投到一个高速旋转的反射镜上。当镜子旋转到不同的位置,投影仪投出对应视点的图像,从而实现360°环视光场显示。Jones在2009年进一步将人脸实时重建技术加入到光场显示系统,实现了远程裸眼3D视频会议[19]。
 图 4. 美国南加州大学实现的360度光场显示
图 4. 美国南加州大学实现的360度光场显示
体三维显示技术在我国起步较晚,中科院自动化研究所于2007研制出基于DMD高速投影仪的体三维显示系统Helix[20],如图5所示,其视点分辨率为1024*768*170,每个体素的大小为0.23*0.23*1mm3,对比度为800:1,3D图像的亮度为100Lux,3D图像刷新率为15fps。实现体三维显示的核心思路是分时复用地在空间中投射不同的图像,牺牲反射场函数中时间t维度换取深度z维度,这就要求投影仪具有非常高的显示帧率。该系统投影170层图像并保持15fps的刷新率,则要求投影仪每秒投影2550幅图像。为了达到如此高的帧率,投影仪只能工作在单色模式下。
 图 5. 中科院自动化所研制的体三维显示系统Helix
图 5. 中科院自动化所研制的体三维显示系统Helix
体三维显示技术原理简单,实现了有限的空间内反射场函数中的5个维度(x, y, z, λ, t),但体三维显示技术存在多方面缺陷:1)体三维显示技术的显示器件不是一个平面,而是一个立体空间,因此占地面积大。2)螺旋面的成型精度要求高,因此加工成本高,不利于量产化。3)单位时间内形成的体素数量有限,视点分辨率有限。4)体三维显示系统需要加入旋转机械运动,投影与运动同步控制困难。
4.2、多视投影阵列光场显示
多视投影阵列三维显示技术通过多个投影仪组成的阵列向空间中一定角度范围内不同方向投射不同图像。相比于体三维显示技术, 多视投影三维显示技术保留了裸眼、多视等优点,并且显示屏幕更接近传统的平面显示器,符合人眼观看显示器的习惯。同时,多视投影三维显示技术去掉了系统中机械运动部件和螺旋显示屏幕,还可以显示复杂纹理和彩色三维内容。但其明显缺点是成本高昂、占地空间大。
浙江大学于2012年构建了全视向的三维显示[21],随后又展示了360°三维显示系统[22,23],如图6所示。北京理工大学在2015年实现了可触摸的360度光场显示[24],如图7所示。北京邮电大学将多投影3D显示应用与地理信息系统[25],并比较了3D投影与柱面光场在垂直视差上的区别[26]。
 图 6. 浙江大学360度多视三维显示系统
图 6. 浙江大学360度多视三维显示系统
 图 7. 北京理工大学360度悬浮光场显示
图 7. 北京理工大学360度悬浮光场显示
南加州大学Graphic Lab在2014年提出了一种具有垂直视差的投影仪阵列光场显示方案[27],如图8所示。所提出的方案通过人眼跟踪来判断人眼相对于屏幕的高低位置,并根据人眼位置实时渲染对应视点图像。该技术沿用水平排列的投影仪阵列同时获得了水平视差和垂直视差,但是当同一水平位置上出现高度不同的两个(及以上)观众时,只有其中一个观众能观看到正确视点图像。
 图 8. 南加州大学实现的水平投影仪阵列
图 8. 南加州大学实现的水平投影仪阵列
南加州大学Graphic Lab于2016年提出了与真人1:1的多视投影光场显示系统,并实现了实时对话,如图9所示,该系统包括216个投影仪、6台PC主机。
 图 9. 南加州大学实现的真人1:1的多视投影光场显示系统
图 9. 南加州大学实现的真人1:1的多视投影光场显示系统
之前外界猜测Magic Leap可能使用的光纤扫描投影技术,其实就是基于投影阵列的光场显示。如果投影仪真的能做到1毫米直径,那么Magic Leap的光场显示方案是可行的。但最新上市的Magic Leap One并没有采用这种方案,显然是投影仪的微型化还不能在工程上大规模实现。
4.3、集成成像光场显示
集成成像[19]最早是将微透镜阵列放于成像传感器之前实现光场采集。光场采集和光场显示的光路是可逆的,因此集成成像技术既可应用于光场采集[28],又可应用于光场显示[29,30]。目前已经商业化的裸眼3D电视正是基于集成成像原理。
韩国国立首尔大学Byoungho Lee于2001年将柱面透镜光栅覆盖在LCD表面实现了动态的集成成像3D显示[31]。日本NHK的在1997年采用梯度下标克服了深度有限的问题[32]并在HDTV上实现了实时的三维显示[33]。东京大学Naemura在2001年实现了集成成像的任意视点合成[34]。国内四川大学于2009年利用2层光栅实现了3D显示[35],在2010年通过叠加两块具有不同LPI(Line Per Inch)参数的柱面光栅所实现的3D显示具有更小的图像串扰,更大的可视角[36],如图10所示。北京邮电大学也尝试了两个光栅组合的3D显示[37]。
 图 10. 四川大学采用两层柱面光栅叠加实现的集成成像3D显示
图 10. 四川大学采用两层柱面光栅叠加实现的集成成像3D显示
柱面透镜光栅的主要作用是将不同像素的光线投射到不同的方向。如图11所示,柱面透镜下所覆盖的8个像素分别产生不同的颜色,从而向不同方向投射出不同颜色的光线。然而单个柱面透镜的宽度一般并不等于整数个像素的宽度,因此会存在某个像素横跨两个柱面透镜的情况,此时会产生光线串扰。在商业化的产品中普遍采用的技术方案为:将柱面透镜光栅相对屏幕倾斜,然后通过软件算法来减轻光线的串扰。
 图 11. 柱面透镜光栅光学特性示意图
图 11. 柱面透镜光栅光学特性示意图
基于柱面透镜光栅的光场显示存在一个明显的缺陷:视点图像分辨率损失严重。柱面透镜光栅的尺寸由LPI(Lens Per Inch)决定。当LPI较大时,每个柱面透镜覆盖的像素就越少,从而产生的视点数量较少,在观看时会产生视点不连续的情况。当LPI较小时,每个柱面透镜覆盖的像素就越多,产生的视点数量也较多,但每个视点的图像分辨率损失严重。由于整体可控的像素数量是一定的,当柱面透镜覆盖更多的像素时,单个视点的图像分辨率损失严重。例如采用4K显示屏(4096x2160),一般商业化的裸眼3D显示器在水平方向产生16(或32)个视点,则每个视点的分辨率降低到256x2160。虽然存在分辨率损失的问题,但基于柱面透镜光栅的光场显示方案成本低廉,成为了目前唯一大面积商业化应用的裸眼3D显示方案。而且显示器面板的分辨率正在逐步提高,视点图像分辨率损失的问题将会逐步得到解决。
4.4、全息显示
光场可以看做是“离散的”、“数字化的”全息,当光场的角分辨率和视点分辨率不断提高,光场的显示效果也将不断逼近全息显示。全息显示技术在近几年不断发展,Tay Savas于2008年在《Nature》上展示可更新内容的全息显示[38]。 P.A.Blanche于2010年在《Nature》上展示过彩色的全息显示[39]。总体而言,全息的显示是终极的光场显示效果,但动态彩色大尺度的全息显示技术尚不成熟,仍有待于材料学、微机电、光学等多学科的共同进步。
国内北京理工大学和上海大学在全息成像方面积累了大量工作。北理工在2013年通过调制复振幅实现了动态3D全息显示[40]。在2014年采用编码复用实现了动态彩色3D全息显示[41],如图12所示。随后在2015年采用压缩查询表的方法在3D全息显示中实现了CGH(Computer Generated Hologram)[42]。
 图12. 北京理工大学2014年实现的彩色3D全息显示
图12. 北京理工大学2014年实现的彩色3D全息显示
4.5、多层液晶张量光场显示
光场比传统2D图像具有更高的维度,不论是光场的采集还是显示都会面临牺牲图像分辨率来换取角度分辨率的两难境地。国际上最新的研究思路是将高维的光场进行压缩分解。张量光场显示技术最初由美国MIT Media Lab的Gordon Wetzstein提出[43],如图13所示。Gordon Wetzstein将光场表示为一个张量(Tensor),对张量进行分解即可将高维度的光场压缩为多个向量的张量积,从而利用有限层数的液晶就可以显示出完整的光场。基于多层液晶的张量光场显示原理比较复杂,目前公开的资料比较少,因此本文将用较大篇幅来剖析其工作原理。
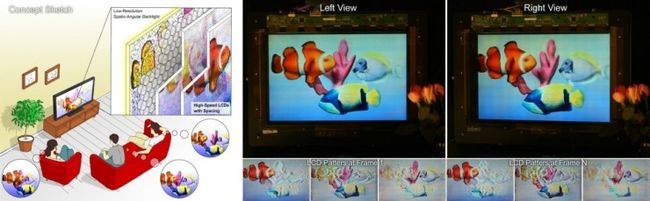 图 13. Gordon Wetzstein 于2013年在MIT实现的张量光场显示
图 13. Gordon Wetzstein 于2013年在MIT实现的张量光场显示
4.5.1 液晶工作原理
液晶的工作原理直接关系到多层液晶光场显示样机的搭建,在搭建多层液晶样机之前有必要详细了解液晶的工作原理及特性。如图14所示[44],背光板发出的光线是均匀自然光,经过下偏光片(起偏膜)过滤变了偏振光。对液晶层施加电压后,液晶会扭转偏振光的偏振方向,扭转角度的大小与施加电压成正比,也即与像素值的大小成正比。经液晶扭转后的偏振光被上偏光片(阻偏膜)过滤,偏振光与上偏光片的夹角越小则透过的光线亮度越高。下偏光片与上偏光片的偏振极性始终垂直。当液晶像素值为0时,液晶对偏振光的扭转角度也为0,偏振光的偏振极性与上偏光片的偏振极性垂直,所以该像素点发出的光线衰减到0,如图14中蓝色偏振光。当液晶像素值为1时,液晶对偏振光扭转90度,偏振光的偏振极性与上偏光片的偏振极性平行,所以该像素点发出的光线不衰减,如图14中红色和绿色偏振光。
 图 14. 液晶面板工作原理示意图
图 14. 液晶面板工作原理示意图
(图片来源于 https://www.xianjichina.com/news/details_34485.html)
4.5.2 多层液晶偏振特性
从上述液晶的成像原理可知每层液晶显示面板都具有起偏膜和阻偏膜,如果直接将多层液晶显示面板平行堆叠起来,那么无论将液晶像素设为多少值,背光发出的光线都无法穿透多层液晶,从而无法显示任何图像。如图15所示,由于第一层液晶LCD#1阻偏膜的存在,背光发出的光线经过第一层液晶后必定为偏振光且偏振极性与第二层液晶LCD#2起偏膜的偏振极性垂直,理论上不会有任何光线经过第二层液晶,也就不会有光线进入第三层液晶。所以,多层液晶前的观看者不会接收到任何光线,呈现一片漆黑。
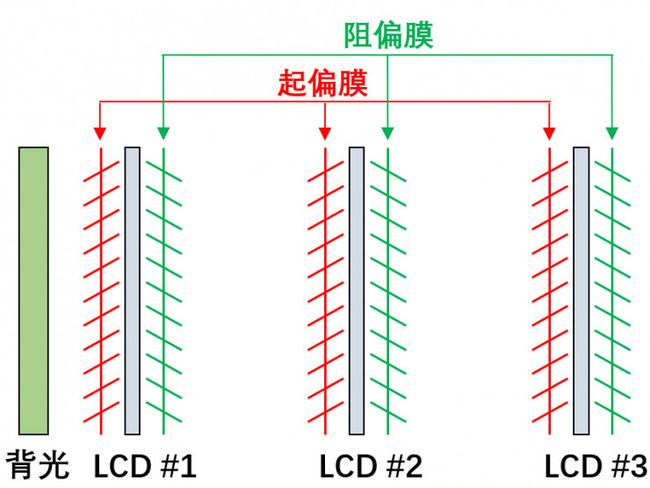 图 15. 直接堆叠多层液晶的偏振特性示意图
图 15. 直接堆叠多层液晶的偏振特性示意图
由上述分析可知,直接将多层液晶显示面板平行堆叠起来无法实现光场显示。为了使得多层液晶能够按照光场4D模型来工作,需要重新排列偏振膜。有两种偏振片排列方式,分别称之为乘法模型和加法模型。乘法模型的偏振片排列方式如图16所示,如果有N层液晶则需要(N+1)块偏振片,在任意两块偏振片之间放入一块液晶,且任意两块相邻的偏振片的偏振极性互相垂直。图16中P1偏振片为正45度偏振极性,对背光进行起偏,所以进入LCD#1的为正45度偏振光。P2偏振片为负45度偏振极性,对LCD#1的偏振光进行阻偏,从而调节从LCD#1出来的光线的亮度,同时保证进入LCD#2的光线都为负45度偏振极性。同理,P3偏振片为正45度偏振极性,对LCD#2的偏振光进行阻偏,从而调节从LCD#2出来的光线的亮度,同时保证进入LCD#3的光线都为正45度偏振极。以此类推,每一层液晶都对进入的光线起到了亮度调制的功能,从而实现了多层液晶联合调制光线。光线从背光板发出穿过多层液晶,每穿过一层液晶,液晶就会对上一层液晶的偏振光进行偏转,且上一层液晶的偏振角度不会累加到当前层液晶的偏转,所以调制关系为乘法运算,可表示为式(1)。当然,我们也可以将乘法运算通过对数转换为加法运算,如式(2)。
l = [a, b, c] = a×b×c (1)
log(l ) =log(a×b×c) = log(a) + log(b) + log(c) (2)
其中,a, b, c分别为目标光线与LCD#1,LCD#2和LCD#3交点上的像素值;为多层液晶联合调制后光线的亮度。
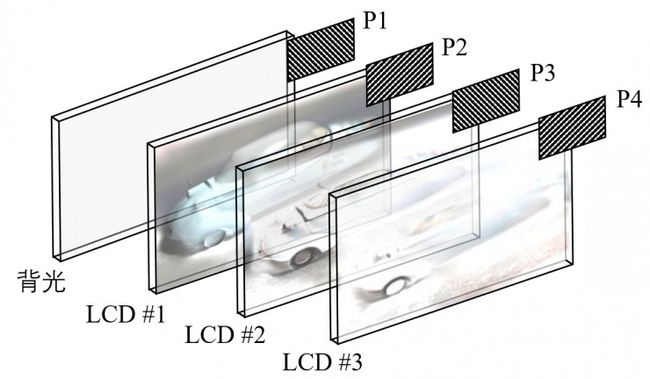 图 16. 多层液晶的乘法模型偏振片排列示意图
图 16. 多层液晶的乘法模型偏振片排列示意图
加法模型的偏振片排列方式如图17所示,如果有N层液晶,不论N为多少,则都只需要两块偏振片,分别位于第一层液晶的起偏位置和第N层液晶的阻偏位置,且两块偏振片的偏振极性互相垂直。图17中P1偏振片为正45度偏振极性,对背光进行起偏,所以进入LCD#1的为正45度偏振光。LCD#1对进入的光线进行偏转,然后进入LCD#2。LCD#2在LCD#1偏转角度的基础上进一步对光线进行偏转,偏转后的光线进入LCD#3。同理,LCD#3在LCD#1和LCD#2偏转角度的基础上进一步对光线进行偏转。P2 偏振片为负45度偏振极性,对经过LCD#3偏转后的光线进行阻偏,从而调制光线亮度。光线从背光板发出穿过多层液晶,每穿过一层液晶,液晶就会对上一层液晶的偏振光进行偏转,且上一层液晶的偏振角度会累加到当前层液晶的偏转,最后进入人眼的光线亮度由多层液晶偏振角度之和来决定,所以多层液晶的调制关系为加法运算,可表示为式(3)。
 图 17. 多层液晶的加法模型偏振片排列示意图
图 17. 多层液晶的加法模型偏振片排列示意图
l = [a, b, c] = a+b+c (3)
其中,a, b, c分别为目标光线与LCD#1,LCD#2和LCD#3交点上的像素值;为多层液晶联合调制后光线的亮度。
4.5.3 多层液晶的各向异性
如图18所示,传统2D显示器每个像素点都会在一定角度范围内发出光线,但每个像素点发出的光线都是各向同性的。换句话说,每个像素点向各个方向发出的光线都具有一样的亮度和颜色。左右眼接收到同样的图像,不同位置的观看者也接收到同样的图像。2D显示器既不能提供双目视差,也不能提供移动视差,因此人眼始终只能看见一幅2D 图像。
 图 18. 传统2D显示器各向同性光学特性
图 18. 传统2D显示器各向同性光学特性
产生各向异性的光线是光场显示的关键。将传统的液晶显示器多层堆叠起来可以构造如图19中光场4D模型,待显示的物体向各个方向发出的光线都可以被多层液晶重现,从而确保多层液晶前不同位置的观众可以接收到不同的光线,不同位置的观众可以看见三维物体的不同侧面。
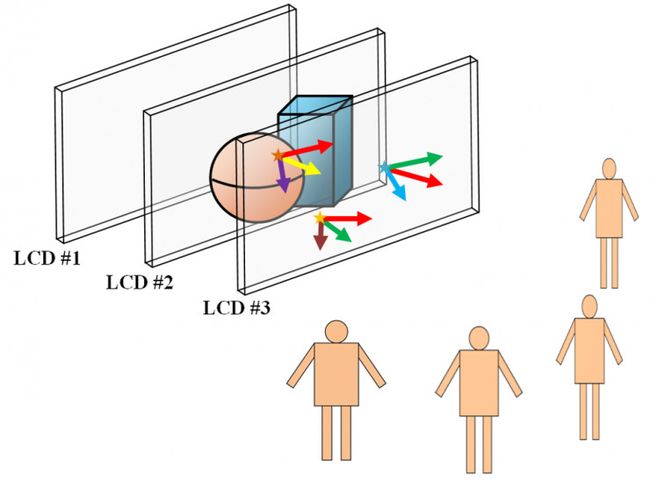 图 19. 多层液晶光场显示原理示意图
图 19. 多层液晶光场显示原理示意图
如图20所示,假设背光是均匀的,所有从背光发出并达到第一层液晶的光线的亮度一致,多层液晶上不同像素的连线就形成了一条不同亮度和颜色的光线。通过不同像素的组合,多层液晶可以在一定空间范围内的任意位置重建出发光点,例如多层液晶之间的点F、多层液晶之后的点G、多层液晶之前的点H,且重建的发光点可以发出各向异性的光线。
 图 20. 多层液晶光场显示光线的各向异性
图 20. 多层液晶光场显示光线的各向异性
图20中F点的光线、G点的光线和分别由三层液晶上的不同像素组合产生,表示为式(4)。类似的,其他光线也可以由多层液晶上像素的联合调制产生。为了实现光线的快速调制,曹煊于2015年开发了基于GPU的并行光场分解算法[45,46]]。
l 1 = [a1, b1, c1]
l i = [ai, bi, ci] (4)
l 3 = [a3, b3, c3]
其中,l i 表示第条光线;ai, bi, ci分别为光线与LCD#1、LCD#2和LCD#3相交的像素;[ai, bi, ci] 可表示两种不同的运算法则,这主要取决于多层液晶的偏振膜的工作方式。
通过上述的分析可知,多层液晶进行光线调制时具有高度的灵活性,可以重现发光点处于多层液晶不同位置时的各向异性光线。当足够多的发光点同时被调制产生时,就能投射出整个三维物体。如图21所示,待显示的三维物体可以设置在多层液晶之前、之后或者中间,从而使观看者感觉物体突出于显示器之外或者凹陷于显示器之内,并且三维显示的“突出感”可以在一定范围内调节。
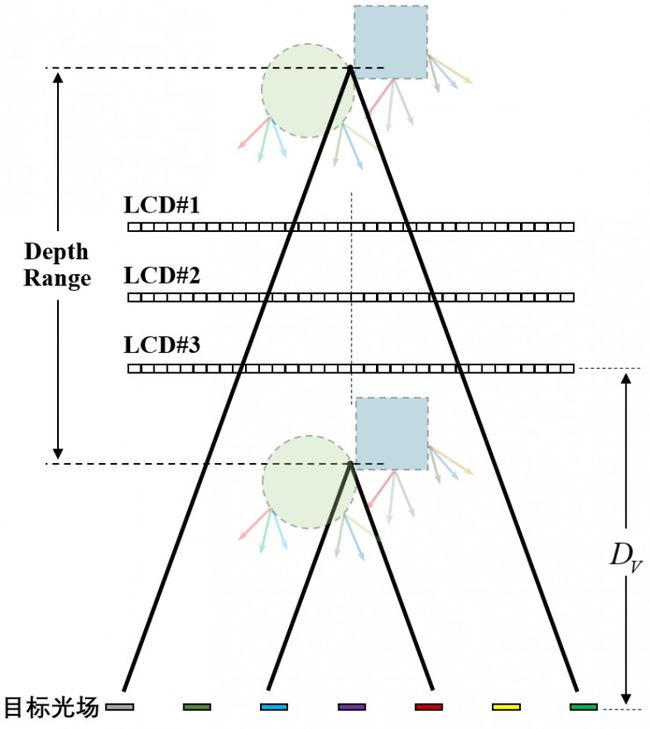 图 21. 多层液晶张量光场显示的深度范围示意图
图 21. 多层液晶张量光场显示的深度范围示意图
张量光场显示本质上是利用多层液晶进行空间复用,形成空间光调制器。该方案不会损失视点图像分辨率,但存在一个明显的缺点:液晶和偏振膜的透光率较低,当背光穿过多层液晶后光强损失严重;因此基于多层液晶的光场显示往往亮度比较低。液晶层数越多,光场显示亮度损失越严重。
需要说明的是,OLED(Organic Light-Emitting Diode)是自发光显示屏,无需背光。多层OLED叠加在一起,进入人眼的光线并不是由多层OLED屏联合调制后的结果,不满足光场4D模型。因此,多层OLED显示屏的堆叠并不能实现张量光场显示。
| 可显示的维度 | 显著优点 | 显著缺点 | |
| 平面显示 2D Display |
R(x, y, λ, t) | 技术成熟 价格低廉 |
缺乏立体 三维信息 |
| 体三维显示 Volumetric 3D Display |
单色:R(x, y, z, t) 彩色:R(x, y, z, λ, t) |
360度可视范围 | 存在机械运动 占地面积大 |
| 多视投影阵列 Multi-view Projector Array |
水平阵列:R(x, y, θ, λ, t) 全阵列:R(x, y, θ, Φ, λ, t) |
分辨率高 可视角度大 |
成本高昂 占地面积大 |
| 集成成像 Integral Imaging |
柱面光栅:R(x, y, θ, λ, t) 透镜阵列:R(x, y, θ, Φ, λ, t) |
成本低廉 | 视点图像分辨率 损失严重 |
| 全息显示 Holographic Display |
R(x, y, z, θ, Φ, λ, t) | 三维显示效果极佳 | 技术尚不成熟 |
| 多层张量显示 Multi-layer Tensor DIsplay |
R(x, y, z, θ, Φ, λ, t) | 成本低 分辨率不损失 |
算法复杂 运算量大 亮度有损失 |
表 1. 传统平面显示与光场显示技术方案对比
4.6 参考文献
[1] S. Pastoor and M. Wöpking, “3-D displays: a review of current technologies,” Displays 17, 100–110 (1997).
[2] J. Hong, Y. Kim, H.-J. Choi, J. Hahn, J.-H. Park, H. Kim, S.-W. Min, N. Chen, and B. Lee, “Three-dimensional display technologies of recent interest: principles, status, and issues [Invited],” Appl. Opt. 50, H87–H115 (2011).
[3] N. S. Holliman, N. A. Dodgson, G. E. Favalora, and L. Pockett, “Threedimensional displays: a review and applications analysis,” IEEE Trans Broadcast. 57, 362–371 (2011).
[4] J. Geng, “Volumetric 3D display for radiation therapy planning,” J. Disp. Technol. 4, 437–450 (2008)
[5] B. Javidi and F. Okano, Three Dimensional Television, Video, and Display Technologies (Springer, 2011).
[6] N. Dodgson, “Autostereoscopic 3D displays,” Computer 38(8), 31–36 (2005).
[7] R. Hainich and O. Bimber, Displays: Fundamentals & Applications (Peters/CRC Press, 2011).
[8] B. Lee, “Three-dimensional displays, past and present,” Phys. Today 66(4), 36–41 (2013).
[9] H. Urey, K. V. Chellappan, E. Erden, and P. Surman, “State of the art in stereoscopic and autostereoscopic displays,” Proc. IEEE 99, 540–555 (2011).
[10] J.-Y. Son, B. Javidi, S. Yano, and K.-H. Choi, “Recent developments in 3-D imaging technologies,” J. Disp. Technol. 6, 394–403 (2010). Advances in Optics and Photonics 5, 456–535 (2013)
[11] J.-Y. Son, B. Javidi, and K.-D. Kwack, “Methods for displaying threedimensional images,” Proc. IEEE 94, 502–523 (2006).
[12] B. Blundell and A. Schwarz, Volumetric Three Dimensional Display System (Wiley, 2000).
[13] D. MacFarlane, “Volumetric three dimensional display,” Appl. Opt. 33, 7453–7457 (1994).
[14] 耿征. 真三维高清晰度显示技术—信息显示领域的重要发展方向[J]. 科技导报, 2007, 25(20):21-26.
[15] Langhans K, Gerken M. FELIX: a volumetric 3D laser display[J]. Proc Spie, 1996, 2650:265--273.
[16] Langhans K, Bezecny D, Homann D, et al. New portable FELIX 3D display[J]. Proceedings of SPIE - The International Society for Optical Engineering, 1998, 3296:204-216.
[17] Langhans K, Bahr D, Bezecny D, et al. FELIX 3D display: an interactive tool for volumetric imaging[C]// Electronic Imaging. International Society for Optics and Photonics, Proceedings of SPIE 2002, 4660:176-190.
[18] Jones A, Mcdowall I, Yamada H, et al. Rendering for an interactive 360° light field display[J]. ACM Transactions on Graphics (TOG), 2007, 26(3):40.
[19] Jones A, Lang M, Fyffe G, et al. Achieving eye contact in a one-to-many 3D video teleconferencing system[J]. Acm Transactions on Graphics, 2009, 28(3):1-8.
[20] Geng J. A volumetric 3D display based on a DLP projection engine[J]. Displays, 2013, 34(1):39-48.
[21] Xia X, Zheng Z, Liu X, et al. Omnidirectional-view three-dimensional display system based on cylindrical selective-diffusing screen[J]. Applied Optics, 2010, 49(26):4915-20.
[22] Xia X, Wu J, Van C, et al. P-5: A New 360-degree Holo-views Display System with Multi-vertical Views[J]. Sid Symposium Digest of Technical Papers, 2012, 41(1):1241-1244.
[23] Xia X, Liu X, Li H, et al. A 360-degree floating 3D display based on light field regeneration.[J]. Optics Express, 2013, 21(9):11237-47.
[[24]] Song W, Zhu Q, Liu Y, et al. Omnidirectional-view three-dimensional display based on rotating selective-diffusing screen and multiple mini-projectors[J]. Applied Optics, 2015, 54(13):4154-4160.
[25] Xing S, Liu S, Sang X. Multi-projector three-dimensional display for 3D Geographic Information System[J]. Optik - International Journal for Light and Electron Optics, 2017.
[26] Di Z, Sang X, Peng W, et al. Comparative Visual Tolerance to Vertical Disparity on 3D Projector Versus Lenticular Autostereoscopic TV[J]. Journal of Display Technology, 2016, 12(2):178-184.
[27] Jones A V, Bolas M T. Interpolating vertical parallax for an autostereoscopic three-dimensional projector array[J]. Journal of Electronic Imaging, 2014, 23(1):011005.
[28] Javidi B, Jang J S, Stern A, et al. Three dimensional image sensing, visualization and processing using integral imaging[J]. Proceedings of the IEEE, 2006, 94(3):591-607.
[29] Okano F, Hoshino H, Arai J, et al. Real-time pickup method for a three-dimensional image based on integral photography[J]. Applied Optics, 1997, 36(7):1598-603.
[30] Javidi B, Jang J S, Stern A, et al. Three dimensional image sensing, visualization and processing using integral imaging[J]. Proceedings of the IEEE, 2006, 94(3):591-607.
[31] Lee B, Jung S, Min S W, et al. Three-dimensional display by use of integral photography with dynamically variable image planes[J]. Optics Letters, 2001, 26(19):1481-2.
[32] Arai J, Okano F, Hoshino H, et al. Gradient-index lens-array method based on real-time integral photography for three-dimensional images[J]. Applied Optics, 1998, 37(11):2034-2045.
[33] Okano F, Hoshino H, Arai J, et al. Real-time pickup method for a three-dimensional image based on integral photography[J]. Applied Optics, 1997, 36(7):1598-1603.
[34] Naemura T, Yoshida T, Harashima H. 3-D computer graphics based on integral photography.[J]. Optics Express, 2001, 8(4):255-62.
[35] Tao Y H, Wang Q H, Gu J, et al. Autostereoscopic three-dimensional projector based on two parallax barriers.[J]. Optics Letters, 2009, 34(20):3220.
[36] Zhao W X, Wang Q H, Wang A H, et al. Autostereoscopic display based on two-layer lenticular lenses.[J]. Optics letters, 2010, 35(24):4127-4129.
[37] 于迅博, 桑新柱, 陈铎, et al. 3D display with uniform resolution and low crosstalk based on two parallax interleaved barriers[J]. Chinese Optics Letters, 2014, 12(12):34-37.
[38] Tay S, Blanche P A, Voorakaranam R, et al. An updatable holographic three-dimensional display[J]. Nature, 2008, 451(7179):694.
[39] Blanche P A, Bablumian A, Voorakaranam R, et al. Holographic three-dimensional telepresence using large-area photorefractive polymer[J]. Nature, 2010, 468(7320):80.
[40] Li X, Liu J, Jia J, et al. 3D dynamic holographic display by modulating complex amplitude experimentally[J]. Optics Express, 2013, 21(18):20577.
[41] Xue G, Liu J, Li X, et al. Multiplexing encoding method for full-color dynamic 3D holographic display[J]. Optics Express, 2014, 22(15):18473.
[42] Gao C, Liu J, Li X, et al. Accurate compressed look up table method for CGH in 3D holographic display[J]. Optics Express, 2015, 23(26):33194.
[43] Wetzstein G, Lanman D, Hirsch M, et al. Tensor displays:compressive light field synthesis using multilayer displays with directional backlighting[J]. ACM Transactions on Graphics, 2012, 31(4):1-11.
[44] http://lcd.zol.com.cn/575/5755898.html?keyfrom=front
[45] Cao X, Geng Z, Zhang M, et al. Load-balancing multi-LCD light field display[C]. Proceedings of SPIE, The International Society for Optical Engineering, March 17,2015.
[46] Cao X, Geng Z, Li T, et al. Accelerating decomposition of light field video for compressive multi-layer display[J]. Optics Express, 2015, 23(26):34007-34022.
转载:https://www.leiphone.com/news/201810/liXIs46eMWDYvLdY.html
5、光场在三维人脸建模中的应用
【摘要】 — 三维建模是计算机视觉中的一个经典问题,其主要目标是得到物体/场景的三维信息(e.g. 点云或深度图)。然而只有三维信息还不足以逼真的渲染重现真实世界,还需要表面反射场信息才能在视觉上以假乱真。本文主要介绍美国南加州大学ICT Graphic Lab的Paul Debevec所引领开发的Light Stage技术,该技术已经成功应用在好莱坞电影特效和2014年美国总统奥巴马的数字人脸建模等诸多应用中。
5.1、反射场在三维成/呈像中的重要性
三维建模可以得到物体的几何信息,例如点云、深度图等。但为了在视觉上逼真的重现三维物体,只有几何信息是不够的。不同物体表面在不同光照环境下会呈现出不同的反射效果,例如玉石会呈现出高光和半透明的反射效果、棉麻织物会呈现出漫反射的效果。即使是相同表面,在不同光照下也会呈现出不同的反射效果,例如图1中的精灵在魔法灯的照射下,脸上呈现出相应的颜色和阴影;阿凡达在发光水母的照射下脸上和身上也会呈现对应的反射效果,这就是Relighting所产生的效果。在现实生活中Relighting是一种再正常不过的现象了。然而当电影中Relighting的效果与实际不符时,人眼会感受到莫名的异常。
模拟出与真实物体表面一致的反射特性,对提高计算机渲染成/呈像的逼真度至关重要。在实际的拍摄中并不存在精灵和阿凡达,也不存在魔法灯和发光的水母,如何生成Photorealistic的图像呢?通过计算机模拟反射场(Reflectance Field)是目前好莱坞大片中惯用的方法。反射场是对所有反射特性的一个普适数学模型,物体表面不同位置(x, y, z)在时刻(t)向半球范围内不同角度(θ, Φ)发出波长为(λ)的光线,由R(x, y, z, θ, Φ, λ, t)七个维度构成的光线的集合就是反射场。关于光场和反射场的异同点参见《Mars说光场(1)— 综述》。
 图 1. 反射场Relighting示意图
图 1. 反射场Relighting示意图
5.2、USC Light Stage介绍
Light Stage是由美国南加州大学ICT Graphic Lab的保罗•德贝维奇(Paul Debevec)所领导开发的一个高保真的三维采集重建平台系统。该系统以高逼真度的3D人脸重建为主,并已经应用于好莱坞电影渲染中。从第一代系统Light Stage 1于2000年诞生,至今已经升级到Light Stage 6,最新的一代系统命名为Light Stage X。
5.2.1 Light Stage 1
如图2所示,Light Stage 1 包括1个光源(strobe light)、2个相机(分辨率480x720)、1个投影仪,整个设备直径约3米[1]。光源可沿机械臂垂直移动,同时机械臂可带动光源水平旋转。整个采集过程包括两个阶段:第一阶段是以人脸为中心旋转光源,从而构成64x32个不同方向的等效光源入射到人脸上。与此同时,两个相机同步拍摄不同光照下的左侧脸和右侧脸,每个相机共拍摄2048张图片,如图3所示。需要说明的是光源和相机前分别覆盖了互相垂直的偏振片,用于分离散射和高光(separate diffuse and specular)。第二阶段是投影仪与2个相机配合完成基于结构光的三维重建,如图4所示。整个采集过程耗时约1分钟,采集过程中人脸需要持续保持静止,这对演员保持静止的能力提出了极高的要求。
 图 2. Light Stage 1系统样机
图 2. Light Stage 1系统样机
Light Stage 1采集的图片样例如图3所示,第二行图片中亮点表示光源的位置,第一行图片表示对应光源照射下采集到的人脸图片,实际采集的反射场图片包括64x32光源位置下的2048张图片。采集三维几何模型通过结构光三维重建实现,如图4所示。
 图 3. Light Stage 1 采集图片样例
图 3. Light Stage 1 采集图片样例
 图 4. Light Stage 1 基于结构光的三维重建
图 4. Light Stage 1 基于结构光的三维重建
在进行Relighting渲染之前还需要通过Specular Ball / Mirror Ball采集环境光照,如图5所示。通过Mirror Ball采集的图片需要经过重采样得到离散的环境光照矩阵[2],然后将环境光照应用在反射场图中,得到如图6中Relighting的渲染效果。图6中第二行图片为Specular Ball在不同环境下采集的环境光照展开图,第一行图片为对应光照下人脸渲染结果。需要说明的是,图6中人脸Relighting的渲染图片只限于固定视点,如果需要改变视点需要结合结构光采集的三维几何模型。
 图 5. Specular Ball 采集环境光
图 5. Specular Ball 采集环境光
 图 6. Light Stage 1 人脸Relighting效果
图 6. Light Stage 1 人脸Relighting效果
5.2.2 USC Light Stage 2
Light Stage 2 在Light Stage 1 的基础上增加了更多的光源,将23个白色光源分布于弧形机械臂上[3-5]。机械臂旋转到不同的经线位置,并依次点亮光源,最终形成42x23个不同方向的入射光源。采集时间从1分钟缩短到4秒,降低了演员维持静态表情的难度。如图7所示,右侧为Light Stage 2真机系统,左侧为采集过程中4秒长曝光拍摄图片。
 图 7. Light Stage 2 采集示意图
图 7. Light Stage 2 采集示意图
5.2.3 USC Light Stage 3
在不同的光照环境下,人脸会反射出不同的“脸色”,例如人脸在火炬前会被映红。通过改变环境光照而使物体表面呈现与之对应的反射状态称为“Relighting”。然而在电影拍摄中并不能把演员置身于任意真实的环境中,例如《指环王》中男主角佛罗多·巴金斯置身于火山岩中,又例如阿凡达置身于梦幻蓝色树丛中。Light Stage 3并不用于人脸建模,而是构建一个可控的彩色光照平台,从而可以实现人脸实时的Relighting[6-8]。
Light Stage 3的支撑结构为二十面体,包括42个顶点、120条边、80个面,如图8所示。在每个顶点和每条边的中心放置一个彩色光源,一共可放置162个彩色光源。由于球体底部5个顶点及其相应的边被移除用于演员站立,因此实际光源数量减少到156个。光源型号为Philips Color Kinetics,iColor MR gen3 LED Lamp http://www.lighting.philips.com/main/prof/indoor-luminaires/projectors/icolor-mr-gen3。光源的亮度和颜色通过USB控制PWM占空比来实现。用于人脸图像采集的相机为Sony DXC-9000,帧率60fps,分辨率640x480,FOV 40度。Light Stage 3还包括6个红外光源和1个灰度相机。红外光源的峰值波长为850nm。灰度相机为Uniq Vision UP-610,帧率110 fps,分辨率640x480,FOV 42度,红外滤光片为Hoya R72。彩色相机和红外相机之间采用分光片确保彩色图像和红外图像对齐,30%反射进入红外相机,70%透射进入彩色相机,如图9所示。
 图 8. Light Stage 3 采集系统样机
图 8. Light Stage 3 采集系统样机
 图 9. Light Stage 3 分光采集系统
图 9. Light Stage 3 分光采集系统
如图10所示,Light Stage 3的工作流程如下:首先用Specular Ball采集目标环境光照,或者计算机生成虚拟环境的光照。然后控制156个彩色光源模拟出与目标环境光照相似的光线,演员在Light Stage 3产生的光照下进行表演。最后通过红外成像把Relighting的人像扣出并融合到电影中。由于Light Stage 3不能重建三维人脸模型,因此不能随意切换视点,需要演员精湛的演技将肢体形态与目标环境融合。最终Relighting合成视频如下所示。
 图 10. Light Stage 3 采集图片样例及融合真实环境效果效果
图 10. Light Stage 3 采集图片样例及融合真实环境效果效果
5.2.4 USC Light Stage 5
Light Stage 5采用与Light Stage 3同样的支撑结构,但把156个彩色光源换成156个白色光源,如图11所示[9-12]。每个白色光源包括12个Lumileds LED灯珠,平均分成2组,分别覆盖水平和垂直的偏振片。理想情况下,需要按照Light Stage 2的光照模式依次点亮每个光源并拍照,那么一共需要拍摄156张图片。Light Stage 5创新性地采用了球谐调和光照(Spherical Harmonic Lighting),如图12所示,将光照模式(Lighting Pattern)从156个减少到4个,分别是沿X/Y/Z方向递减的3个梯度光照和1个均匀全亮光照。由于需要拍摄水平和垂直两种偏振状态下的图片,因此每个相机一共需要拍摄8种光照模式下的8张图片。相比之前的Light Stage,整个采集的时间大大缩短。如果采用高速相机可以达到实时采集,如果采用单反相机需要2秒。
 图 11. Light Stage 5 采集系统样机
图 11. Light Stage 5 采集系统样机
 图 12. Light Stage 5 偏振光布局
图 12. Light Stage 5 偏振光布局
人脸包括低频和高频两种几何信息,低频几何信息主要是指鼻梁高低、脸型胖瘦等;高频几何信息主要是指毛孔、胡须、唇纹等。对于低频几何信息,Light Stage 5采用两种三维建模方法:一种是用DLP高速投影仪和Phantom高速摄像机构成基于结构光的实时三维重建。另一种是采用5个单反相机(Canon 1D Mark III)构成多视几何(Multi-view Geometry)重建三维人脸模型。在上述两种三维建模方法的基础上,进一步采用Photometric Stereo来生成高频几何模型。图13为Light Stage 5所完成的“Digital Emily”项目中重建的数字演员艾米丽[13,14],左侧为重建的高精度Normal Map,中间为只用Diffuse Component重建的人脸模型,右侧为同时加上Diffuse Component和Specular Component以后重建的高精细人脸。
 图 13. Light Stage 5 Digital Emily人脸重建效果
图 13. Light Stage 5 Digital Emily人脸重建效果
5.2.5 USC Light Stage 6
如图14和15所示,Light Stage 6是为采集演员全身反射场而设计[15]。支撑结构直径8米,为了使演员处于球体中心,去掉了球体底部1/3。Light Stage 6共包括1111个光源,每个光源由6颗LumiLEDs Luxeon V LED灯珠构成。采集系统包括3台垂直分布的高速摄像机以30fps同步采集图像,每一帧图像包括33种不同光照。所以高速相机实际的工作频率为990Hz。在支撑结构的中心有一个旋转平台,该旋转平台为演员有效的表演区域,直径2米。在采集过程中旋转平台会持续旋转,高速相机从而拍摄到不同视点的演员图像,演员需要不断的重复周期性动作,整个采集过程约几分钟。
 图 14. Light Stage 6 采集系统样机
图 14. Light Stage 6 采集系统样机
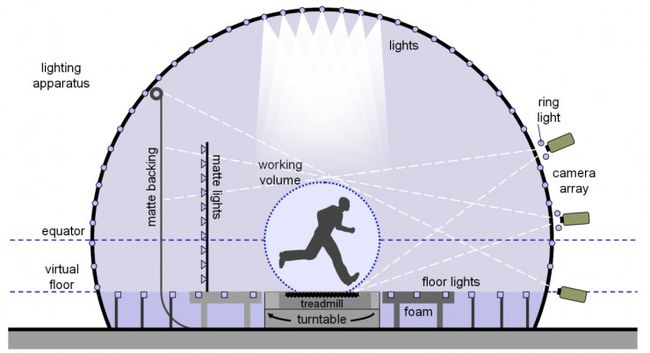 图 15. Light Stage 6 采集系统示意图
图 15. Light Stage 6 采集系统示意图
Light Stage 6并不对人体进行几何建模,而是采用与Light Stage 3类似的原理来实现Relighting。Light Stage 6相比Light Stage 3的改进之处在于视点可切换。Light Stage 6为了实现视点切换,需要演员周期性的重复动作,例如跑步,然后采集到所有不同光照下不同视点的图像。图16上侧图片为1/30秒内某一个相机采集的所有图片,包括26张不同光照下的图片(Lighting Frames),3张红外图片(Matting Frames)用于抠图,3张跟踪图片(Tracking Frames)用于光流对齐图片,1张预留图片(Strip Frame)目前无用,将用于后续其他潜在功能应用。图16下侧图片为相机阵列中上中下三个相机分别采集到的图片。如图17所示,所采集的图片分布于一个圆柱形上,当渲染不同视点下的Relighting图片时,从圆柱形上选择合适的视点进行融合。
 图 16. Light Stage 6 采集图片样例
图 16. Light Stage 6 采集图片样例
 图 17. Light Stage 6 多视点渲染
图 17. Light Stage 6 多视点渲染
5.2.6 Light Stage对比总结
Light Stage 1 和Light Stage 2都是基于稠密采样的反射场采集,因此采集时间较长。Light Stage 3采集彩色光源照射实时生成Relighting图片,但没有进行三维建模,所以应用场景有限。Light Stage 4的研发被搁置了,所以取消了Light Stage 4的命名,转而直接研发Light Stage 5。Light Stage 5基于球谐调和进行反射场的低阶采样,是相对比较成熟的一代系统,已经在《本杰明•巴顿》、《蜘蛛侠》等电影特效中得到应用。最新研发的系统为Light Stage X,小型可移动,专门针对高精度人脸反射场采集建模;其光照亮度、光谱、偏振状态都可以基于USB接口通过电脑编程控制,自动化程度更高,采集时间更短。2014年采集美国时任总统奥巴马头像时,就是基于Light Stage X系统,如图18为采集现场,图19为重建结果。Paul Debevec及其团队核心成员于2016年加入谷歌DayDream部门,主要是将光场技术应用于泛VR领域,其团队于2018年8月在steam平台上上线了《Welcome to light field》体验应用。
| Light Stage 1 |
Light Stage 2 |
Light Stage 3 |
Light Stage 5 |
Light Stage 6 |
|
| 尺寸(直径) |
3米 |
2米 |
2米 |
2米 |
8米 |
| 支撑结构 |
1个光源可沿机械臂上下移动 |
30个光源均匀分布于弧形机械臂 |
二十面体,42个顶点,120条边,80个面。 |
二十面体,42个顶点,120条边,80个面。 |
二十面体的均匀细分,只保留整圆的2/3。圆球结构中心为旋转舞台。 |
| 实际光源数量 |
1个白色 |
30个白色 |
156个彩色LED光源,6个红外光源(850nm峰值波长) |
156个白色LED光源 |
1111个白色LED光源(LumiLEDs Luxeon V) |
| 等效光源数量 |
64x32个白色 |
42x30个白色 |
156个彩色 |
156个白色 |
1111个白色 |
| 相机数量 |
2@480x720 |
2@480x720 |
(a)1个RGB相机(Sony DXC-9000@60fps @640x480 @FOV40)。 (b)1个红外相机。 (Uniq Vision UP-610@110 fps@640x480 @FOV42 Hoya R72滤波片)。 |
(a)双目高速相机(Phantom V7.1 @ 800 × 600)+结构光(DLP projector @1024x768)。 (b)5个相机构成多视几何(Canon 1D Mark III EF 50mm f/1.8 II lenses)。 |
3个高速相机垂直分布。 |
| 采集时间 |
60秒 |
4秒 |
实时 |
实时/2秒 |
几分钟 |
| 三维重建方法 |
结构光 |
结构光 |
无三维建模 |
机构光/多视几何 |
无三维建模,光流配准图像 |
| 优点 |
互相垂直偏振片分离散射和高光。 |
互相垂直偏振片分离散射和高光。 只需要水平旋转,减少采集时间。 |
红外成像用于人像抠图。 彩色光源模拟环境光,实现人像实时Relighting。 |
互相垂直偏振片分离散射和高光。 实时建模/静态建模。 |
互相垂直偏振片分离散射和高光。 可以采集全身运动。 |
| 缺点 |
采集时间过长,人脸难以保持静止。 需要机械旋转。 |
需要机械旋转。 |
无三维建模,不能自由切换视点,需要演员精湛演技。 |
只能建模人脸,不能建模全身。 |
只能建模周期重复性运动。 |
表 1. USC Light Stage汇总对比
 (图片来源于 http://vgl.ict.usc.edu/Research/PresidentialPortrait/)
(图片来源于 http://vgl.ict.usc.edu/Research/PresidentialPortrait/)
图 18. Light Stage X为美国时任总统奥巴马采集人脸头像现场
5.3、参考文献
[1] Debevec P, Hawkins T, Tchou C, et al. Acquiring the reflectance field of a human face[C]// SIGGRAPH '00 : Proc. Conference on Computer Graphics and Interactive Techniques. 2000:145-156.
[2] Debevec P. A median cut algorithm for light probe sampling[C]// ACM SIGGRAPH. ACM, 2008:1-3.
[3] Tim Hawkins, Jonathan Cohen, Chris Tchou, Paul Debevec, Light Stage 2.0, In SIGGRAPH Technical Sketches, 2001.
[4] Hawkins T, Cohen J, Debevec P. A photometric approach to digitizing cultural artifacts[C]// Conference on Virtual Reality, Archeology, and Cultural Heritage. ACM, 2001:333-342.
[5] Hawkins T, Wenger A, Tchou C, et al. Animatable facial reflectance fields[C]// Fifteenth Eurographics Conference on Rendering Techniques. Eurographics Association, 2004:309-319.
[6] Jones A, Gardner A, Bolas M, et al. Simulating Spatially Varying Lighting on a Live Performance[C]// European Conference on Visual Media Production. IET, 2006:127-133.
[7] Wenger A, Hawkins T, Debevec P. Optimizing Color Matching in a Lighting Reproduction System for Complex Subject and Illuminant Spectra.[C]// Eurographics Workshop on Rendering Techniques, Leuven, Belgium, June. DBLP, 2003:249-259.
[8] Debevec P, Wenger A, Tchou C, et al. A lighting reproduction approach to live-action compositing[C]// Conference on Computer Graphics & Interactive Techniques. ACM, 2002:547-556.
[9] Wenger A, Gardner A, Tchou C, et al. Performance relighting and reflectance transformation with time-multiplexed illumination[C]// ACM, 2005:756-764.
[10] Ghosh A, Hawkins T, Peers P, et al. Practical modeling and acquisition of layered facial reflectance[J]. Acm Transactions on Graphics, 2008, 27(5):1-10.
[11] Ma W C, Hawkins T, Peers P, et al. Rapid acquisition of specular and diffuse normal maps from polarized spherical gradient illumination[C]// Eurographics Conference on Rendering Techniques. Eurographics Association, 2007:183-194.
[12] Ghosh A, Fyffe G, Tunwattanapong B, et al. Multiview Face Capture using Polarized Spherical Gradient Illumination[J]. Acm Transactions on Graphics, 2011, 30(6):1-10.
[13] Alexander O, Rogers M, Lambeth W, et al. Creating a Photoreal Digital Actor: The Digital Emily Project[C]// Visual Media Production, 2009. CVMP '09. Conference for. IEEE, 2010:176-187.
[14] Alexander O, Rogers M, Lambeth W, et al. The digital Emily project: achieving a photorealistic digital actor[J]. IEEE Computer Graphics & Applications, 2010, 30(4):20.
[15] Einarsson P, Jones A, Lamond B, et al. Relighting human locomotion with flowed reflectance fields[C]// ACM SIGGRAPH 2006 Sketches. ACM, 2006:76.
转载:https://www.leiphone.com/news/201810/Nkfbu0Her1Em8jlG.html