李宏毅机器学习(2021)学习笔记 02
文章目录
- 前言
- 正文
-
- 定义新模型
-
- 如何拟合复杂曲线?
- sigmoid函数
- 本期模型
- 模型总结
- 模型的线性代数表示
- 模型的流程图
- 定义损失函数
- 优化损失函数
-
- 流程与梯度
- 补充技巧
- 验证结果
-
- 激活函数
- 进一步改进
- 测试验证
- 遗留问题
- 总结
前言
这篇文章是李宏毅老师《机器学习2021》第2期视频(链接在这里(需要))的学习笔记。
上期有一个错误,在机器学习第二步中,我说视频是2022年,其实是2021年的,不过应该并不影响理解。

正文
第2期视频,仍然使用预测观看人数这个案例,介绍了神经网络或深度学习的基础模式。
顺便感叹一下,李宏毅老师的教学是真的好,神经网络用了几年了,激活函数、神经元和感知机等概念倒是很熟,但是从这个角度理解神经网络还是头一次,有种豁然开朗拨云见日的感觉。
如果你已经对神经网络有基本的了解,却还懵懵懂懂为什么要这样做,为什么有效,这期视频会解答一部分疑惑。如为什么要引入激活函数等。
具体来说,这一期视频在上一期视频的基础上,对线性回归模型进行改造,引入更加复杂的神经网络模型,继续预测观看人数,从而介绍了神经网络的基本思想、流程和概念,并对深度学习和神经网络的关系做了说明。
这篇文章剩余部分结构如下:
- 定义新模型。使用sigmoid函数,拟合更加复杂的曲线。
- 定义损失函数。
- 优化参数。
- 其他模型及改进,介绍神经网络和深度学习。
定义新模型
如何拟合复杂曲线?
上一期视频我们用线性回归模型对频道观看人数做预测,虽然有一点效果,但线性回归模型对于复杂的真实世界来说,有些太过简单。真实的数据,不可能总是呈现出同一个方向的向上或向下,有时会出现一些曲折,如下图:
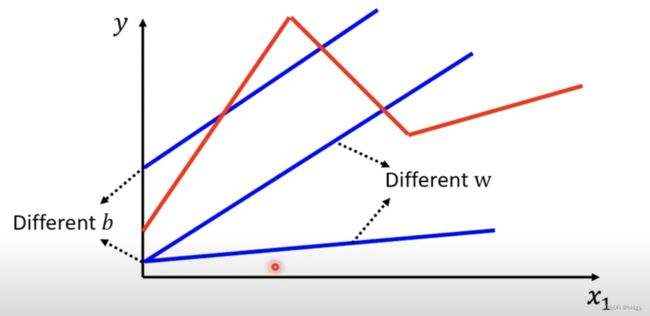
如上图所示,红色的曲线是一条有两个转折点的折线,且三段红色的线其斜率各不相同,有上有下。在这种情况下,仅凭单一的直线很难拟合出红色曲线,就像图中的三条蓝线都无法很好的拟合红色线。
为了能够更好的拟合红色曲线,我们需要一组更复杂的蓝色曲线,如下图所示。这一组蓝色曲线加上一个常数就可以拟合红色曲线。在下图中我们可以看到,有一条完全平行于x轴的蓝色平行线,这条线代表常数。
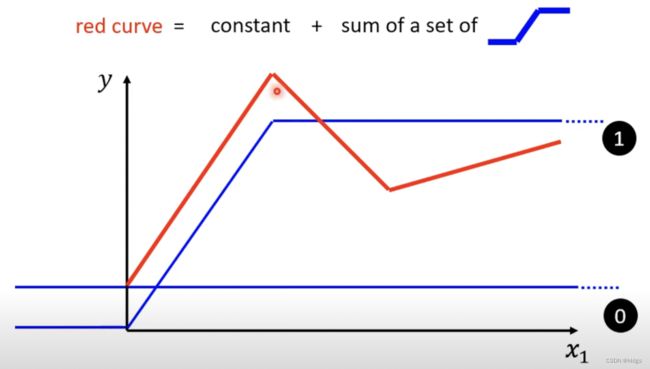
如上图,我们引入一种三段的蓝色曲线,来模拟红色曲线。上图中,蓝色曲线一开始是平行于x轴(且取值为0,因为已经有常数蓝色曲线了),到达第一个转折点(即红色线段的起点)时,蓝色线段以斜率 b b b上升,显然这个斜率和红色曲线第一段的斜率相同,即二者平行。可以很明显的看出,在这一段中,蓝色曲线加上已有的常数,就会与红色曲线的第一段重合。而过了红色曲线的第一段后,蓝色曲线保持峰值不变,与x轴平行。
到这里,第一条(不包括常数)蓝色曲线的任务就完成了,我们引入第二条蓝色曲线,如下图。在这张图中,我们引入了第二条蓝色曲线,同样的,这条蓝色曲线也是有两段平行线和一段斜线组成。不同的是,第二条蓝色曲线一开始平行,在红色曲线的第一个转折点处开始下降,且平行于第二段红色曲线。第二条蓝色曲线同样是从0开始下降,很明显,第二条曲线和第一条曲线以及常数相加,就会和红色曲线重合。
同样地,我们还可以引入第三条曲线,去拟合第三段红色曲线,最终的结果如下图:
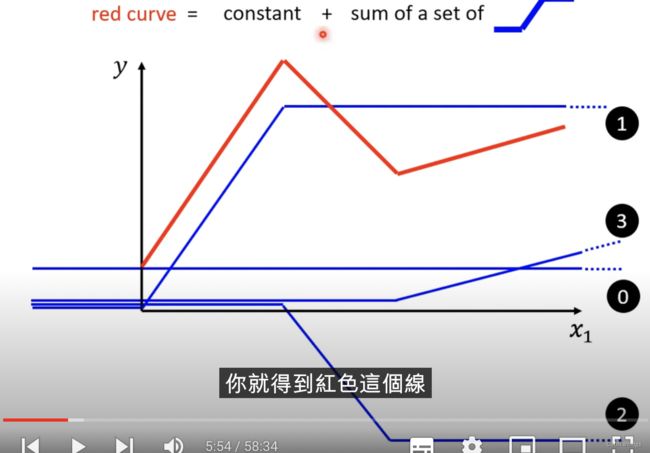
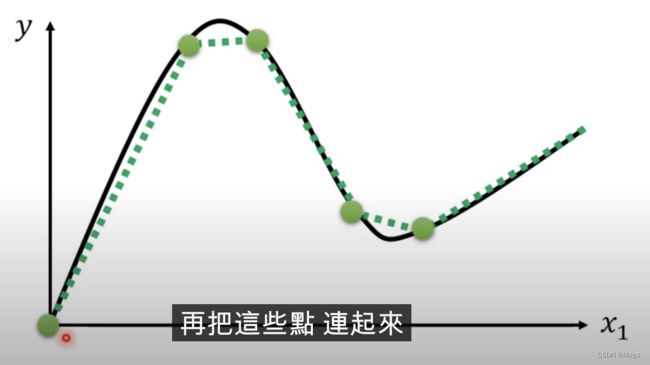
由图中可以看出,0-3四条曲线(编号见图的右边)相加,就可以很好的拟合红色曲线。用这种方式,只要有足够多的蓝色折线,我们几乎可以拟合任何类型的数据,即使红色的曲线不是完全的折线段,而是某种有高有低的曲线,我们也可以近似的选取一些点将红色曲线段化曲为直,如下图:
sigmoid函数
直观的分析结束了,我们需要用数学的方式表达上述过程。蓝色折线通常被称作hard sigmoid,这种蓝色折线虽然很好,但是在实际使用中我们并不想用分段函数的方式来表示他。为了简化流程,我们使用sigmoid函数拟合他,sigmoid函数公式如下:
s i g m o i d ( b + w x 1 ) = 1 1 + e − ( b + w x 1 ) sigmoid(b+wx_1) = \frac{1}{1+e^{-(b+wx_1)}} sigmoid(b+wx1)=1+e−(b+wx1)1
很容易看出sigmoid函数的取值范围是0—1之间,因此还需要乘上常数 c c c,就可以近似表示蓝色折线,最终函数形式如下:
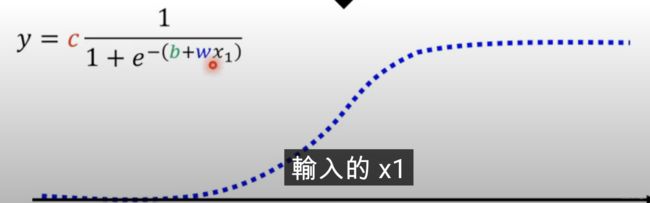
y = c s i g m o i d ( b + w x 1 ) y = c sigmoid(b+wx_1) y=csigmoid(b+wx1)
这个函数的图像如下,可以看出他很好的近似了蓝色折线。如果想要调整它的形状,只需要调节 c c c、 b b b和 w w w三个参数即可,也就是说他们三个就是未知参数。
本期模型
而今天我们的任务(预测观看人数),不管真实的观看数据是什么样的曲线,我们都可以用若干上述函数拟合逼近,因此本期视频的初步模型形式如下,可能需要解释一下的是后半部分,选用了若干sigmoid曲线的加总模拟数据。至于使用多少个sigmoid曲线,这是一个用户自己决定的超参数。
y = b + ∑ c i s i g m o i d ( b i + w i x 1 ) y=b+\sum{c_i}sigmoid(b_i+w_ix_1) y=b+∑cisigmoid(bi+wix1)
同样我们再复习一下最基本的线性模型:
y = b + w x y = b + wx y=b+wx
对比二者的形式,很容易理解今天的模型就是把简单的直线,换成了若干个蓝色折线和一个常数相加。上一期我们提到过可以用过去几天的数据来预测明天的数据,从而提高精度,于是线性模型就变为如下形式,即过去几天的数据各自拥有一个权重。
y = b + ∑ w i x i y=b+\sum{w_ix_i} y=b+∑wixi
同样地,使用sigmoid的魔心也可以引入过去多日的数据,这样模型就变为:
y = b + ∑ i c i s i g m o i d ( b i + ∑ j x j w i j ) y = b+\sum_{i}{c_isigmoid(b_i+\sum_j{x_jw_{ij}})} y=b+i∑cisigmoid(bi+j∑xjwij)
即每一个“蓝色折线”的形状都取决于过去若干天的数据,然后再由若干蓝色折线相加得到最终的模型。其中 i i i 的取值范围是sigmoid的个数, j j j 的取值范围是选用的天数(称为特征数)。
模型总结
到这里可能有点乱,做一个总结。本期视频使用多个sigmoid函数拟合真实数据,模型的形式如下。其意义是,每一条sigmoid函数都由过去若干天的数据决定,而多条sigmoid函数(及一个常数)加总得到最终的模型。
y = b + ∑ i c i s i g m o i d ( b i + ∑ j x j w i j ) y = b+\sum_{i}{c_isigmoid(b_i+\sum_j{x_jw_{ij}})} y=b+i∑cisigmoid(bi+j∑xjwij)
在模型中,未知参数是 b b b、 c i c_i ci、 b i b_i bi和 w i j w_{ij} wij,注意这里 b b b和 b i b_i bi不是同一个参数,只是刚好重名。
此外还有一些超参数,如 i i i 和 j j j 的取值范围,他们分别意味着有多少条sigmoid曲线和使用过去多少天的数据(又被称作特征数)。
模型的线性代数表示
当特征变多(在这个例子中就是使用的过去的天数变大)和sigmoid曲线数量变多时,在使用上述写法可能不够直观,应该用线性代数向量和矩阵的形式写出,如下(懒得打了hhh)。除了第一个b之外,其他符号都代表一个向量或矩阵, σ \sigma σ用来代表sigmoid。
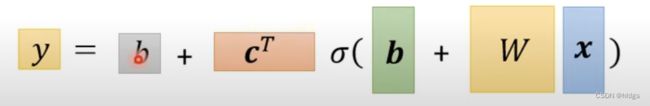
模型的流程图
整个模型的流程可以用上图表示。假设我们选取过去三天的历史数据作为特征,首先把三个x乘以对应的权重相加;接着再把加权后的和分别输入到三个sigmoid函数中,得到三个sigmoid函数值;再将这三个值乘以对应的权重,与常数 b b b 相加,得到最后的y值
定义损失函数
有了模型之后,下一步就是在训练数据上定义损失函数。尽管我们对模型做出了修改,但损失函数的定义并没有修改,仍然是之前的模式,即:
L ( θ ) = 1 N ∑ e n L(\theta) = \frac{1}{N}\sum{e_n} L(θ)=N1∑en
其中 θ \theta θ 表示参数向量(在上一步中我们给出了模型的线性代数表示,将所有未知参数组合成一个向量即为 θ \theta θ )。而 e n e_n en 的计算也同第一期视频一样,有两种方法可供选择:
e n = ∣ y ^ n − y n ∣ e_n = \left|\hat{y}_n-y_n\right| en=∣y^n−yn∣
e n = ( y ^ n − y n ) 2 e_n = \left(\hat{y}_n-y_n\right)^2 en=(y^n−yn)2
优化损失函数
流程与梯度
有了损失函数之后,就要对损失函数做优化,求解下述优化问题,得到最优参数向量 θ ∗ \theta^* θ∗。
θ ∗ = a r g m i n L \theta^* = argmin L θ∗=argminL
优化损失函数的步骤和第一期视频基本一致:首先,随机取一个初始向量 θ 0 \theta^0 θ0;其次,用 L L L 对各参数求偏导,得到梯度向量;再次,用公式求出新的参数向量 θ i + 1 = θ i − η ∇ L ( θ i ) \theta_{i+1} = \theta_i - \eta\nabla L(\theta^{i}) θi+1=θi−η∇L(θi);最后,当(1)梯度为零向量;(2)已经训练足够多轮 这两个条件满足其一时,结束训练,否则继续第二步。
这里提到了梯度的概念,上一期视频就介绍过优化用的是梯度下降法,但是由于举例用的是单一变量,因此只提到了偏导。实际上,梯度向量就是把函数对他的所有变量分别求偏导,再组合成的一个向量,常用 ∇ L \nabla L ∇L 表示。
补充技巧
在数据量很大时,L每一次迭代并不需要在所有训练数据上计算。我们可以把训练数据分成若干份,每一份叫做一个batch,每次计算损失函数及其梯度只要在一个batch上计算即可。在一个batch上计算一次叫做一次updata,在所有batch上计算一遍,则叫做一个episode。
举个例题,一共有10000条数据,每个batch包括10条数据,一个episode有( 10000 10 = 1000 \frac{10000}{10} = 1000 1010000=1000)个updates。这里一个batch有几个数据也是一个超参数。
验证结果
这一步,我们应该用最优参数的模型,在测试数据上验证结果。李宏毅老师并没有验证sigmoid函数模型的结果,在这里他又介绍了另一种拟合蓝色折线的函数——ReLu函数。
激活函数
ReLu(Rectified Linear Unit)函数形式如下:
y = c m a x ( 0 , b + w i x ) y=cmax\left(0,b+w_ix\right) y=cmax(0,b+wix)
其图像如下:
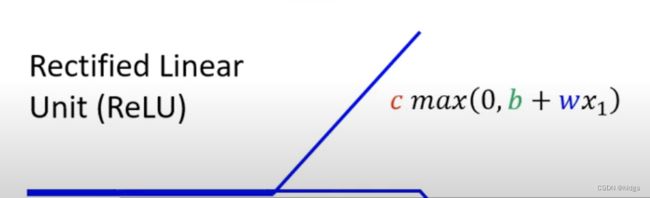
可以看到他是一个只有一段的折线,我们需要用两个不同的ReLu函数加在一起,就可以得到一个蓝色折线(即hard sigmoid)。
Relu和sigmoid都被称为激活函数(activation function)。
进一步改进
上面的模型中,我们其实是将一个线性回归模型,作为sigmoid函数的输入(回想一下,sigmoid内部是 b + w x b+wx b+wx ),而事实上我们也可以将sigmoid函数再输入给另一个sigmoid函数,以提高精度(为什么要这么做?李宏毅老师说未来会做出解释)。那么第一次将若干x输入给sigmoid函数我们可以看作第一层,再将若干sigmoid函数输入给若干sigmoid函数可以看做第二层,以此来推,我们就获得了一个多层的神经网络。多层的结构如下所示:
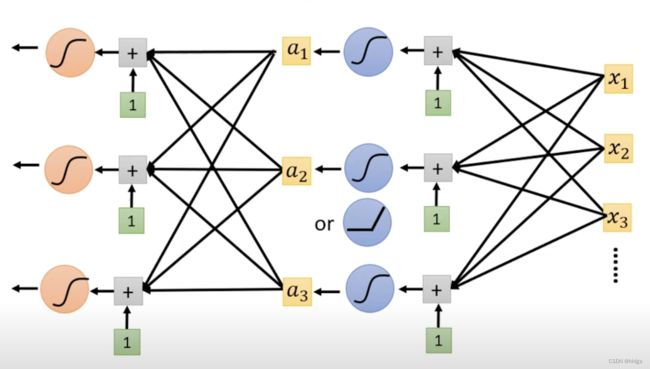
(同理,ReLu函数也可以这样多层叠加)
是的,到这里,我们就得到了神经网络模型,而层数越来越多,越来越多,人们就把神经网络换了个名字,叫做深度学习。
另外,神经网络的层数是一个超参数。每一个sigmoid函数被称作一个神经元。
测试验证
李宏毅老师使用了ReLu作为激活函数的神经网络,利用测试数据做验证,结果如下:

这里有一个细节,4层的模型在训练数据(2017-2020)上表现最好,但是在2021年上表现很差,这种现象被称为过拟合。即模型在训练数据上过度学习,导致在测试数据上表现很差。
遗留问题
李宏毅老师遗留了一些问题,留待以后解决,具体有:
- 如前所说,只要有足够多的sigmoid,可以模拟出任何曲线,那我们为什么不只用一层,增加很多sigmoid函数,而是选择用sigmoid反复迭代?
- 很多层神经网络有哪些训练技巧?
- ReLu和sigmoid哪个好,为什么?
总结
第二期视频主要使用第一期的例子,将线性模型演进到sigmoid函数,并反复迭代,最终成为耳熟能详的神经网络。
对于复杂曲线,简单的线性模型难以拟合,而利用多个sigmoid函数相加的形式,理论上可以逼近任何复杂曲线。因此,本期视频仍然使用上一期视频的流程,首先定义若干sigmoid函数相加的模型,并用线性代数表示;其次,在训练集上定义损失函数;再次,利用梯度下降算法优化损失函数;最后,在测试数据上验证结果。除此之外,李宏毅老师还介绍了ReLu函数,同样可以逼近复杂曲线,且效果往往比sigmoid好,这种函数我们统称为激活函数。最后的最后,李宏毅老师介绍了一种将sigmoid反复迭代的方法,并指出这便是耳熟能详的神经网络模型,且介绍了神经网络可能存在的过拟合问题。
本期视频同样涉及到一些陌生概念,如梯度、激活函数、神经网络、过拟合、深度学习和特征等,这些概念在文中均有解释,不再赘述。