自监督学习-对比学习-MoCo Momentum Contrast 阅读笔记
Momentum Contrast for Unsupervised Visual Representation Learning
原文地址:CVPR 2020 Open Access Repository https://openaccess.thecvf.com/content_CVPR_2020/html/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.html
https://openaccess.thecvf.com/content_CVPR_2020/html/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.html
收录:CVPR 2020 Best paper
代码: GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
1. 背景知识
A. 什么是对比学习

假如有两类,分别使用同一个特征提取器分别提取出特征。对比学习 希望在一个特征空间里,不同的类的特征尽量远离彼此。
B. 什么是无监督的训练方式?
在视觉领域,大家巧妙地设计代理任务,从而人为定义一些规则,这些规则可以用来定义哪些图片是相似的,哪些图片是不相似的,从而可以提供一个监督信号去训练模型,这也就是所谓的自监督训练
讲一个最广泛的代理任务:instance discrimination 如何定义哪些图片是相似的,哪些图片是不相似的呢? instance discrimination 是这么做的:只有从自己图片裁剪下来的才是正样本,属于同一类。其它都是负样本。(或者是一个物体的不同视角,一张图片是RGB还是灰度都可以作为正样本) 由此一来,每个图片都是自己的类。ImageNet就不是1000类,而是100多万类(图片总量)。
这样一个框架就是对比学习常见的实现方式了。看起来好像平平无奇,但对比学习就厉害的地方就是它的灵活性。只要你能找到一种方式定义什么是正样本,什么是负样本,剩下的操作都是比较标准。
大家大开脑洞去制定很多正样本负样本的规则,
比如在视频领域,同一视频的任意两帧都是正样本,而其它视频里所有帧都是负样本。
在NLP领域,NLP, simCSE 把同样的句子扔给模型,但是做 2 次 forward,通过不同的 dropout 得到一个句子的 2 个特征;和其它所有句子的特征都是负样本。
CMC 论文:一个物体的不同视角 view(正面、背面;RGB 图像和灰度图像;不同crop)都可以作为不同形式的正样本。
对比学习实在是太灵活了,哪个领域都能用。扩展到多模态领域,也就造就了open AI 的 CLIP 模型
3.Momentum

yt-1 是上一个时刻的输出, xt是当前的输入,m是动量超参,0~1。当m趋近于1的时候,就不怎么依赖当前的输入了。moco利用了这种特性,让字典学习的特征缓慢的更新,尽可能地保持一致。
摘要
MOCO用于无监督表征学习。我们从另外一个角度来理解对比学习,即从一个字典查询的角度来理解对比学习。moco中建立一个动态的字典,这个字典由两个部分组成:一个队列queue和一个移动平均的编码器 moving-averaged encoder。
这两个东西造就了一个更大的和更一致consistent的字典,对无监督的对比学习有很大的帮助。(队列中的样本不需要做梯度反传,因此可以在队列中存储很多负样本,从而使这个字典可以变得很大。使用移动平均编码器的目的是使队列中的样本特征尽可能保持一致,即不同的样本通过尽量相似的编码器获得特征的编码表示。)
moco under the comon linear protocol 在imageNet分类上能取得很好的结果(comon linear protocol 指 把预训练好的backbone 冻住,在加上一个linear protocol,分类,就能够做别的任务)更重要的是,moco学习到的特征能够很好的迁移到下游任务!(这是moco这篇文章的精髓,因为无监督学习的目的就是通过大规模无监督预训练,获得一个较好的预训练模型,然后能够部署在下游的其他任务上,这些下游任务通常可能没有那么多有标签数据可以用于模型训练)。MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins。这样,有监督和无监督之间的鸿沟在很大程度上被填平了。
1. introduction
GPT和BERT在NLP中证明了无监督预训练的成功。视觉领域中还是有监督占据主导地位。语言模型和视觉模型这种表现上的差异,原因可能来自于视觉和语言模型的原始信号空间的不同。语言模型任务中,原始信号空间是离散的。这些输入信号都是一些单词或者词根词缀,能够相对容易建立tokenized的字典。(tokenize:把某一个单词对映为某个特征)。有了这个字典,无监督学习能够较容易的基于它展开,(可以把字典里所有的key(条目)看成一个类别,从而无监督语言模型也类似有监督范式,即有类似于标签的东西来帮助模型进行学习,所以在NLP中,容易进行建模,且模型相对容易进行优化)。但是视觉的原始信号是在一个连续且高维的空间中的,它不像单词那样后很强的语义信息(单词能够浓缩的很好、很简洁)。所以图像(由于原始信号连续且高维)就不适合建立一个字典,而使无监督学习不容易建模,有监督模型更强。
有一些基于对比学习的无监督学习取得了不错的效果,都可以归纳为构造一个动态字典。
【对比学习中的一些概念:锚点-anchor-一个样本-一个图像,正样本-positive-由锚点通过transformation得到,负样本-negative-其他样本,然后把这些样本送到编码器中得到特征表示,对比学习的目标就是在特征空间中,使锚点和正样本尽可能相近,而和负样本之间尽可能远离】
【进一步,把对比学习中,正样本和负样本都放在一起,理解成一个字典,每个样本就是一个key,然后一开始选中作为锚点anchor的那个样本看作query,对比学习就转换成一个字典查询的问题,也就是说对比学习要训练一些编码器,然后进行字典的查找,查找的目的是让一个已经编码好的query尽可能和它匹配的那个特征(正样本编码得到的特征)相似,并和其他的key(负样本编码得到的特征)远离,这样整个自监督学习就变成了一个对比学习的框架,然后使用对比学习的损失函数】

【moco中把对比学习归纳为一个字典查找的问题,因此论文后面基本上用query来代替anchor,用key来代替正负样本】
从动态字典的角度来看对比学习,要想获得比较好的学习效果,字典需要两个特性:一个是字典要尽可能大,另一个是字典中的样本表示(key)在训练过程中要尽可能保持一致。【原因分析:字典越大,就能更好的在高维视觉空间进行采样,字典中的key越多,字典表示的视觉信息越丰富,然后用query和这些key进行对比学习的时候,才更有可能学习到能够把物体区分开的更本质的特征。而如果字典很小,模型有可能会学习到一个捷径(short cut solution)。导致预训练好的模型不能很好的做泛化。关于一致性,是希望字典中的key是通过相同或者相似的编码器得到的样本特征,这样在与query进行对比时,才能尽量保证对比的有效性。反之,如果这些key是经过不同的编码器得到的,query在进行查询时,有可能会找到一个相同或者相似编码器产生的那个key。这就相当于变相的引入了一个捷径(short cut solution),使得模型学不好】而现有的对比学习方法都被上述两个方面中至少一个方面所限制。

moco有两个贡献,基于此,moco构建一个又大又一致的队列,能够去无监督的学习较好的视觉表征。
1、构建队列queue
【分析:这是在对比学习中第一次使用队列这种数据结构。队列queue主要是用来存储前面提到的字典,当字典很大时,显卡的内存就不不够用。因此希望模型每次前向过程时,字典的大小和batch size 的大小无关。
具体的,这个队列可以很大,但是在每次更新这个队列时,是一点一点进行的,即模型训练的每个前向过程时,当前batch抽取的特征进入队列,oldest的batch的特征移除队列。即先入先出。引入队列的操作后,就可以把mini-batch的大小和字典(队列)的大小分开了,所以最后这个字典(队列)的大小可以设置的很大(论文最大设置为65536),队列中的所有元素并不是每个iteration都要更新的,这样只使用一个普通的GPU就可以训练一个很好的模型,(因为simclr这种模型会需要TPU进行训练,非常吃设备)】
2、对编码器的动量更新
【分析:字典中的key最好要保持一致性,即字典中的key最好是通过同一个或者相似的编码器得到的。这个队列queue在更新时,每个Batch的特征是不同时刻的编码器得到的,这样就与前面说的一致性有了冲突,为了解决这个问题,因此moco中提出使用momentum encoder。选用一个很大的动量m,那么这个动量编码器的更新其实是非常缓慢的,实验也证明了使用较大的动量0.999会取得更好的效果】
代理任务的选择。moco提供的是一种机制,它为无监督对比学习提供一个动态字典,所以还需要考虑选择什么样的代理任务。moco是非常灵活的,他可以和很多代理任务相结合。moco论文使用的一个简单的代理任务instance discrimination,但是效果很好。用预训练好的模型再结合一个线性分类器就可以在imageNet上取得和有监督相媲美的结果。【instance discrimination 个体判别任务,例子:有一个query和一个key,是同一个物体的不同视角不同的随机裁剪,这是一个正样本对,其他的都是负样本】
无监督学习最主要的目的是在大量无标注数据上,预训练一个模型,这个模型获得特征能够直接迁移到下游任务上。moco在7个下游任务上(检测、分割等)都取得了很好的结果,打平甚至超过有监督方式。【moco是无监督中第一个都做到了这么好的结果】
moco在imageNet上做了预训练,该数据集有100W样本量。进一步,为了探索无监督的性能上限,moco在10亿样本量的Instagram也进行了预训练【facebook公司自己的,更偏向于真实世界,存在很多真实场景中的问题,如数据分类不均衡导致的长尾问题、一张图片含有多个物体,Instagram数据集图片的挑选和标注都没有那么严格】实验发现,Instagram上训练的模型性能有所提升。
因此,movo通过实验,填平了有监督和无监督之间的一个坑,取得了媲美甚至更好的结果,并且无监督预训练的模型可能会取代有监督预训练的模型。【学术界和工业界有很多基于imageNet预训练的模型进行扩展的工作,所以moco才会有很大的影响力。】
2. related work
无监督学习中,主要有两个方面做文章,一个是代理任务,一个是损失目标函数。代理任务的最终目的是能够获得更好的特征表示,目标函数是可以剥离代理任务进行一些设计,moco主要就是从目标函数上进行的设计与改进。moco中的框架设计最终影响的就是InfoNCE这个目标函数。
目标函数:可以分为判别式,生成式,对比学习和对抗学习。设计生成式模型(重建整张图),使用L1或者L2损失函数等都可以;判别式模型(eight positions,预测位置),通过交叉熵等损失函数的形式。
对比损失函数:在特征空间中衡量每个样本对之间的相似性,目标是让相似的物体之间的特征拉的比较近,不相似物体之间的特征尽量推开。与生成式或者判别式损失函数不同,后者的目标是固定的,前者(对比学习)的目标是在模型训练过程中不断改变的。即对比学习中目标是编码器抽取得到的特征(字典)决定的。
对抗性损失函数:主要衡量的是两个概率分布之间的差异。主要用来做无监督的数据生成。后来也有做特征学习的,迁移学习中很多方法就是通过对抗性损失函数来进行特征的学习。因为如果能够生成很理想的图像,也就意味着模型学习到了数据的底层的分布,这样的模型学习到的特征可能也会很好。
代理任务:denoising auto-encoder重建整张图,context auto-encoder重建图片的某个patch,cross-channel auto-encoder/colorization图片上色,生成pseudo-labels伪标签/transformations of a single image,patch orderings九宫格(打乱顺序或者预测方位),利用视频信息去tracking,或聚类等各种各样的方法。
对比学习VS代理任务:某个代理任务可以和某个对比损失函数配对使用。contrastive predictive coding (CPC) [46] is a form of context auto-encoding上下文自编码,预测性对比学习,利用上下文信息预测未来;contrastive multiview coding (CMC),利用一个物体的不同视角进行对比,和图片上色colorization比较像。【CPC, CMC是对比学习方法早期的一些经典工作。】
【之所以围绕这两点写相关工作 ,是因为目标函数和代理任务是无监督学习中和有监督学习任务中主要不同的地方。有监督任务有标签信息,无监督学习没有标签,只能通过代理任务来生成自监督信号,来充当标签GT。最后还需要一个Loss衡量输出和GT的差异,让模型学得更好】
3. Method
3.1. Contrastive Learning as Dictionary Look-up
1)损失函数
本文采用的损失函数是InfoNCE,该损失函数是一个K+1(k负样本,1正样本)的SoftMax分类器的对数损失:
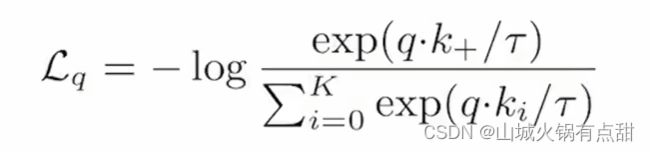
对比学习的目标函数,我们希望这个目标函数具有下面的性质:query和唯一正样本key+相似的时候,希望这个目标函数的值比较低,当query和其他key不相似的时候,loss的值也应该很小,【因为对比学习的目标就是拉近query和正样本key+的距离,同时拉远query和其他样本的距离,如果能达到这个目标,就说明模型训练的差不多了,此时的目标函数的值就应该尽量小,不再继续更新模型。】同样的,当query和正样本key+不相似或者query和负样本key相似时,我们希望目标函数的loss值尽量大一些,来惩罚模型,让模型继续更新参数。
 上面是输出,下面的label
上面是输出,下面的label 
这个和交叉熵函数几乎是一致的,除了交叉熵K表示数据集的类别数。【对比学习中理论上是可以使用cross entropy来当作目标函数的,但是在很多代理任务的具体实现上是行不通的。比如使用instance discrimination,类别数k就变成了字典中的样本数,softmax在有巨量类别时,是工作不了的,同时exponential指数操作,在向量维度是几百万时,计算复杂度会很高,在模型训练时,每个iteration里面这样去计算,会很耗费时间。基于以上情况,有了NCE loss,noise contrastive estimation,思路是把多类别简化成一个二分类问题,数据类别data sample和噪声类别 noise sample,然后拿数据样本和噪声样本做对比。
另外,如果字典的大小是整个数据集,计算复杂度还是没有降下来,为了解决这个问题,思路就是从整个数据集中选一些负样本进行loss计算,来估计整个数据集上的loss,即estimation。所以负样本如果选少了,近似的结果偏差就大了,所以字典的大小也就成了影响模型性能的一个因素,即字典越大,提供更好的近似,模型效果会越好。
InfoNCE是对NCE的一个简单的变体,思路是,如果只看作二分类问题,只有数据样本和噪声样本,对模型学习不是那么友好,因为噪声样本很可能不是一个类,所以把噪声样本看作多个类别会比较合理,最终NCE就变成了上面的公式InfoNCE。
【这个公式中,q 和 k 是模型的logits输出,t 是一个温度参数, 用来控制分布的形状, 取值越大,分布越平滑smooth,取值越小,分布越尖锐peak。温度参数过大,对比损失对所有负样本一视同仁,导致模型的学习没有轻重。温度参数小,导致模型只关注特别困难的负样本,而这些负样本也有可能是潜在的正样本(比如和query是同一类别的样本等),模型过多关注困难的负样本,会导致模型很难收敛,或者模型学习的特征泛化性能比较差】
2)代理任务
由于MoCo的重点不是设计一个新的代理任务,因此他们采用的是实例识别任务。当然,代理任务可以是任意的。
在随机数据增强下,对同一张图像随机裁剪得到两个视图,这两个视图可以被成为正样本对。如果一个q和一个k来自同一样本图像,它们也为正样本对,否则为负样本对。对于每个mini_batch,编码后的q和相应的k形成了正样本对,负样本来自队列。
3.2. Momentum Contrast
1) 将一个字典看成一个队列
在传统的对比学习中,字典的大小就是mini_batch的大小,但这往往会因此GPU内存和算力的限制而不能太大。所以MoCo用队列来储存字典。队列的更新方法是:当前的mini_batch完成编码后就入队,队列中最老的mini_batch出队,因此该字典总是所有数据的一个子集。这样,队列的大小就和mini_batch的大小解耦了,从而就可以实现一个大队列。
2)动量更新
动量更新使得字典变大,但同时也让反向传播更新编码器变得困难,因为梯度要传播到队列中所有的样本。因此MoCo提出,只梯度更新fq编码器,fk编码器复制fq的参数,而不进行梯度更新。但是,仅仅简单的复制是远远不够的,这样做的实验结果很差,因为fq是查询队列,因此θq是不断更新的且更新速度很快,θk要更新需要复制θq,但这会导致正确率不高,因此改为采用动量更新,让θk的更新更具有连续性。所以,fk编码器的更新还需要根据动量更新公式:

其中,θq是编码器fq的参数,θk是编码器fk的参数,m是动量参数,属于[0,1]。上面的公式中,只有θq是通过反向传播更新的。较大的m值,如0.999效果较好。
复制参数值 + 动量更新公式 使得MoCo的字典可以保持与查询q具有一致性
3)Relations to previous work
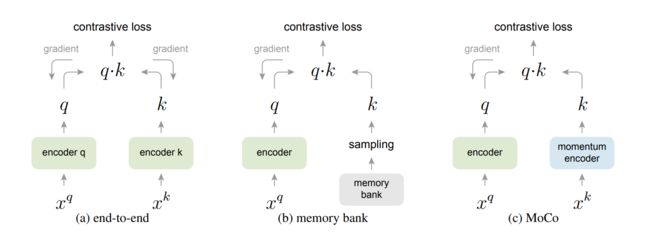
之前的对比学习的方法基本都可以归纳为一个字典查找的问题,到都或多或少受限制于字典的大小或者一致性的问题。
(a) end-to-end,端到端的学习方式,上图(a)所示,端到端的学习方式中,编码器q和编码器k都可以通过梯度回传的方式进行更新,两个编码器可以是不同的网络,也可以是相同的网络。moco中两个编码器是同样的网络架构Res50,因为query和key都是从同一个batch中获得的,通过一次前向传播就可以获得所有样本的特征,并且这些特征是高度一致的。局限性在于字典的大小受限,端到端的方式中,字典的大小和mini-batch的大小是一样,如果想让字典很大,batch size 就要很大,目前GPU加载不了这么大的batch size。另外,即使硬件条件达到,大的batch size 的优化也是一个难点,处理不得当,模型会很难收敛。
【simclr(google)就是端到端的学习方式,并且使用了更多的数据增强方式,在编码器之后还有一个pojector,让学习的特征效果更好,此外还需要TPU,内存大,能够支持更大的batch size 8192,有16382个负样本。】端到端的学习方式,优点是,由于能够实时更新编码器k,字典中的key的一致性会很好,缺点是batch size很大,内存不够。
(b)memory bank,更关注字典的大小,希望字典很大,以牺牲一定的一致性为代价。这种方法中只有一个编码器q,并能够通过梯度回传进行更新,字典的处理,则是把整个数据集的特征都存储,如ImageNet有128万个特征,每个特征128维,600M内存空间,近邻查询效率也很高。然后每次模型训练时,从memory bank中仅从随机采样key,来组成字典,memory bank相当于线下进行的,字典就可以设置的非常大。
但是memory bank的特征一致性不好,样本特征每次训练时选中作为key的那些样本特征,会通过编码器q进行更新,而编码器q的更新会很快,每次更新的特征的差异性会很大,所以memory bank上特征的一致性会很差。另外,由于memory上存放了整个数据集的堂本,也就意味着,模型要训练一整个epoch,memory bank上的特征才能全部更新一次。
moco解决了上面提到的字典大小和特征一致性的问题,通过这个动态字典和动量编码器。
【moco和memory bank方法更相似,都只有一个编码器,都需要额外的内存空间存放字典,memory bank中还提出了proximal optimization损失,目的是让训练变得更加平滑,和moco中的动量更新异曲同工。memory bangk动量更新的是特征,moco动量更新的是编码器k,moco的扩展性很好,可以在亿集数据集上使用,memory bank方法在数据集很大时,还是会受限于内存大小。】
moco简单高效,扩展性好。
3.3. Pretext Task
伪代码:
moco中默认使用的batch size大小是256。数据增强得到正样本对。memory bank中query长度(特征维数)128,为了保持一致,moco也用的128。
对于当前的mini-batch,我们对 queries 及其相应的 keys进行编码,这些键形成正样本对。负样本来自队列。
1) Technical details
编码器可以是任意的卷积神经网络,fq和fk可以是完全相同的,也看可以是部分相同或不同的。我们采用ResNet [33]作为编码器,其最后一个全连接层(在全局平均池化之后)具有固定维输出(128-D [61])。该输出向量通过其 L2 范数 [61] 进行归一化。这是query or key的表示形式。温度 τ 以 Eqn.(1) 为单位设置为 0.07 [61]。数据增强设置遵循[61]:从随机调整大小的图像中获取224×224像素裁剪,然后进行随机颜色抖动,随机水平翻转和随机灰度转换,所有这些都在PyTorch的torchvision包中可用。
2)Shuffling BN
我们的编码器 fq 和 fk 都具有Batch Normalization (BN) [37],如标准 ResNet [33]。在实验中,我们发现使用BN会阻止模型学习良好的表示,如[35]中类似报道的那样(避免使用BN)。该模型似乎“欺骗”了pretext task,并很容易找到一个低损失的解决方案。这可能是因为样本之间的intra-batch communication(由BN引起)泄漏了信息。
我们通过 shuffling BN 来解决此问题。我们使用多个 GPU 进行训练,并针对每个 GPU 在样本上独立执行 BN(如常见做法中所做的那样)。对于key编码器 fk,我们在当前mini-batch中随机排列示例顺序,然后再在 GPU 中分配(并在编码后随机排列);query编码器 fq 的mini-batch的示例顺序不会更改。这可确保用于计算a query and its positive key的batch statistics来自两个不同的子集。这有效地解决了作弊问题,并允许training从BN中受益。
4. Experiments
数据集:ImageNet-1M,100W数据量,Instagram-1B,10亿数据量。后者是为了验证moco模型扩展性好。由于使用个体判别的代理任务,ImageNet的类别量就是数据量。另外,Inatagram数据集更能反应真实世界的数据分布,这个数据集中的样本不是精心挑选的,有长尾、不均衡等问题,图片中物体有一个或多个。
训练:【相较于之后的SimCLR、BYOL等工作,moco对硬件的要求都是最低的,相对更容易实现的,affordable。并且moco、moco-v2系列工作,其泛化性能都很好,做下游任务时,预训练学习到的特征依旧非常强大。SimCLR的论文引用相对更高一些,moco的方法更平易近人一些】
200epoch,ResNet50,53h。优化器:SGD,权重衰减率0.0001,SGD动量0.9。
对于ImageNet-1M:学习率0.03,8GPU,batch_size128。
对于Instagram-1B:学习率0.12,64GPU,batch_size1024。
4.1. Linear Classification Protocol
预训练模型加一个线性分类头,即一个全连接层。
作者做了一个grid search,发现分类头的最佳学习率是30,非常不可思议。一般深度学习中的工作,很少有learning rate会超过1。因此,作者认为,这么诡异的学习率的原因在于,无监督对比学习学到的特征分布,和有监督学习到的特征分布是非常不一样的。
Ablation:contrastive loss mechanisms
消融实验。三种对比学习流派之间的比较。实验结果如下图所示:
上图中,横坐标k表示负样本的数量,可以近似理解为字典的大小,纵坐标是ImageNet上的top one 准确率。end-to-end方法,受限于显卡内存,字典大小有限,32G的显卡内存,能用的最大的batch size是1024。memory bank方法整体上比end-to-end和moco效果都要差一些,主要就是因为特诊的不一致性导致的。另外,黑线的走势是不知道的,因为硬件无法支撑相关的实验,其后面结果可能会更高,也可能会变差。moco的字典大小,从16384增长到65536,效果提升已经不是很明显了,所以没有更大的字典的比较。上图结论:moco性能好、硬件要求低、扩展性好。
Ablation:momentum
消融实验,动量更新。实验结果下图所示:
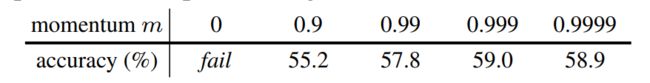
动量参数0.99-0.9999,效果会好一些。 大的动量参数,保证了字典中特征的一致性。动量参数为0,即每个iteration里面,直接把编码器q拿来作为编码器k,导致模型无法收敛,loss一致在震荡,最终模型训练失败。这个实验非常有力的证明了字典一致性的重要性。
Comparison with previous results.

模型容量越大效果越好 ,moco在小模型和大模型上都能取得好的效果。
4.2. Transferring Features
无监督学习最主要的目标是要学习一个可以迁移的特征,验证moco模型得到的特征在下游任务上的表现,能不能有好的迁移学习效果。
另外,由于无监督学习的特征分布和有监督学习到的特征分布是很不一样的,在将无监督预训练模型应用到下游任务时,不能每个任务的分类头都进行参数搜索,这样就失去了无监督学习的意义,解决方法是:归一化,然后整个模型进行参数微调。BN层用的是synchronized BN,即多卡训练时,把所有卡的信息都进行统计,计算总的running mean 和running variance,然后更新BN层,让特征归一化更彻底,模型训练更稳定。
Schedules.如果下游任务数据集很大,不在ImageNet上进行预训练,当训练时间足够长,模型效果依然可以很好,这样就体现不出moco的优越性了。但是下游数据集训练时间很短时,moco中预训练还是有效果的。所以moco中用的是较短的训练时间。
PASCAL VOC Object Detection,数据集PASCAL VOC,任务:目标检测,实验结果如下图:
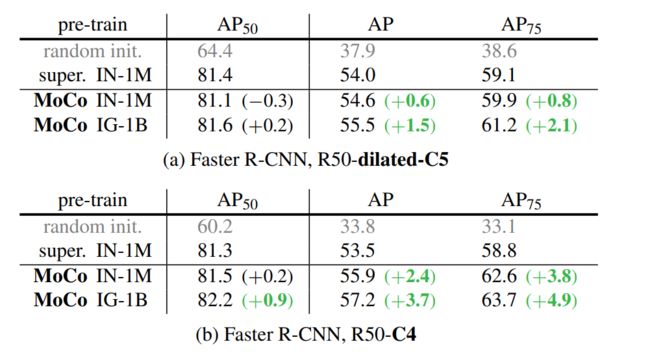
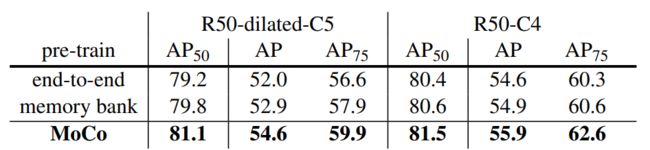
coco数据集,实验结果如下图:

其他任务:人体关键点检测、姿态检测、实例分割、语义分割,实验结果如下图:
总结:moco在很多任务上都超过了ImageNet上有监督预训练的结果,在少数几个任务上稍微差一些,主要是实例分割和语义分割任务,【所以后面有人认为,对比学习不适合dence prediction的任务,这种任务每个像素点都需要进行预测。之后有一些相关的工作来改进这一点,如dence contrast,pixel contrast等】。
在所有这些任务中,在Instagram上预训练的模型要比ImageNet上的效果好一些,说明moco扩展性好,与NLP中结论相似,即自监督预训练数据量越多越好,符合无监督学习的终极目标.
5. Reference
1. MoCo 论文逐段精读【论文精读】_哔哩哔哩_bilibili
2. MoCo 论文详解_flow筝的博客-CSDN博客_moco论文
3. 自监督学习-MoCo-论文笔记_xueliang_的博客-CSDN博客_自监督学习