《机器学习实战》学习笔记第二章-KNN
KNN K-近邻算法
目录
1.K-近邻算法介绍
2.改进约会网站的配对效果
从本文文件中提取数据
创建散点图显示数据相关性
数值归一化
测试算法
给海伦的程序(交互实现)
3.手写识别系统
1.K-近邻算法介绍
以近邻K个点为参考,多数是什么特征,未知点就是什么特征。即采用测量不同特征值直接的距离方法来进行分类。截图来自B站《五分钟机器学习》
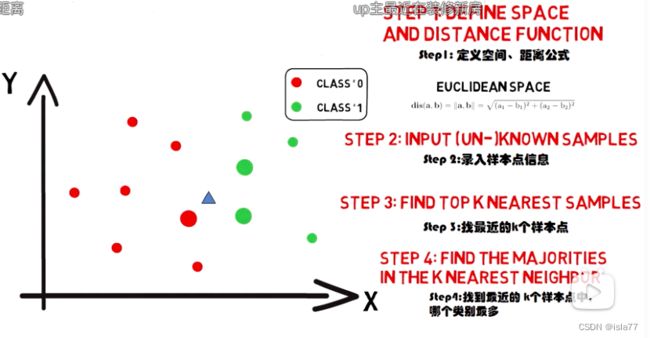
优点:直观,好理解、局部分布,不需要估计整体、精度高、对异常值不敏感、无数据输入假定
缺点:局部估算可能不符合全局分布,对K的取值非常敏感,计算复杂度高,空间复杂度高
使用数据范围:数值型和标称型
一般流程:
1.收集数据
2.准备数据:距离计算所需要的数值,最好是结构化的数据格式
3.分析数据:任何方法
4.训练算法:不需要
5.测试算法:计算错误率
6.使用算法
基本流程:
import numpy as np
import operator
def createDataSet():
group = np.array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX,(dataSetSize,1))-dataSet #tile复制几行几列
sqDiffMat = diffMat**2
sqDistances= sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #将数组按照从小到大的顺序排序,输出对应的索引值。
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] #key
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 #value+1
#字典分解成元组列表,按元组的第二个元素进行逆序排序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
group,labels = createDataSet()
mm = classify0([0,0],group,labels,3)
print(mm)输出B
2.改进约会网站的配对效果
从本文文件中提取数据
def file2matrix(filename): #从文本中提取数据
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines,3)) #设置一个n行3列的数组
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip() #去除两侧空格
listFromLine = line.split('\t') #以空格为界分成列表元素
returnMat[index,:]= listFromLine[0:3] #将index这一行填充上列表中前3个元素
classLabelVector.append(int(listFromLine[-1])) #将列表的最后一列 结果 加入class列表中(1不喜欢,2有点喜欢,3很喜欢)
index +=1
return returnMat,classLabelVector
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')创建散点图显示数据相关性
fig = plt.figure()
ax = fig.add_subplot(111)
plt.xlabel('video time')
plt.ylabel('icecream')
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*np.array(datingLabels),15.0*np.array(datingLabels))
plt.show()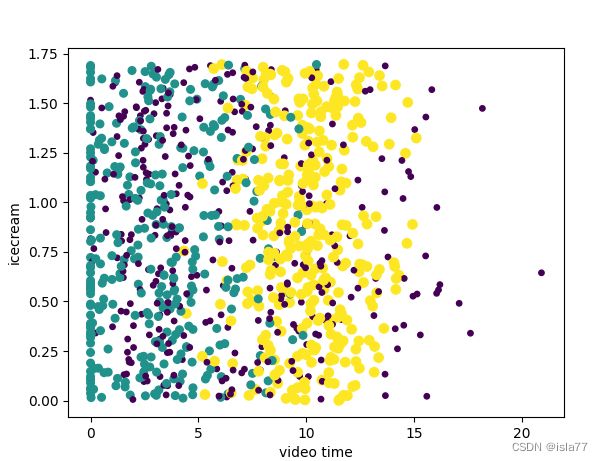
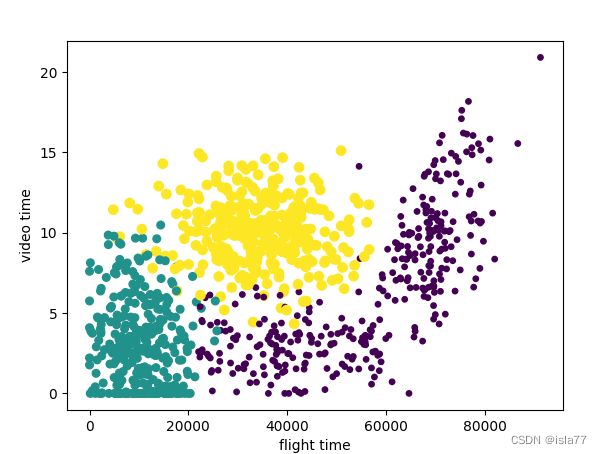
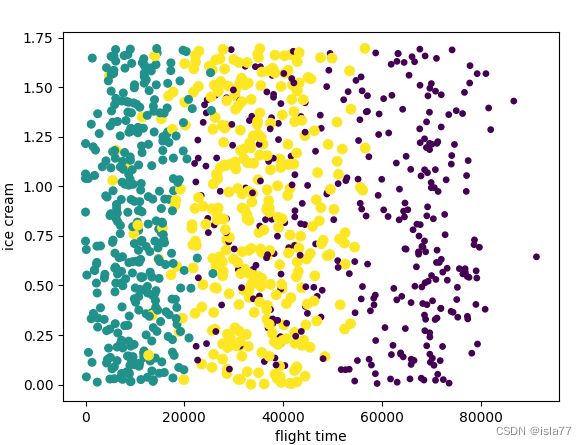
可见飞行时间和游戏时间两个因素是关键因素,应从这两个数据入手分析
数值归一化
因不同类数据直接差值不统一,故需要统一至0-1范围内
newValue = (OldValue-min)/(max-min)
def autoNorm(dataSet):
minVals = dataSet.min(0) #参数0使函数从一列中选取最小值,结果为1行3列数组
maxVals = dataSet.max(0)
ranges = maxVals-minVals
normDataSet = np.zeros_like(dataSet)
m = dataSet.shape[0] #读取数据集行数
normDataSet = dataSet - np.tile(minVals,(m,1)) #m行*1列*3列=m行3列数组
normDataSet = normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,minVals测试算法
def datingClassTest():
hoRatio = 0.1
datingDataMat,datingLabels = file2matrix('datingTestSet.txt')
normMat,ranges,minvals=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
#norMat[i,:]是测试样本;[numTestVecs:m]是训练样本
classifierResult = classify0(norMat[i,:],norMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print(f'the classifier came back with: {classifierResult},the real answer is: {datingLabels[i]}')
if(classifierResult!=datingLabels[i]):
errorCount+=1
result = errorCount/float(numTestVecs)
print(f'the total error rate is:{result}')
datingClassTest()注意datingTestSet.txt中最后一列不是1,2,3表示,而是描述性语言,要在file2matrix函数中修改classLabelVector:
#classLabelVector.append(int(listFromLine[-1])) #将列表的最后一列 结果 加入class列表中(1不喜欢,2有点喜欢,3很喜欢)
if listFromLine[-1]=='didntLike':
classLabelVector.append(1)
elif listFromLine[-1]=='smallDoses':
classLabelVector.append(2)
else:
classLabelVector.append(3)
index +=1结果error date=5%

可以通过改变hoRatio训练样本和测试样本的百分比、K值来尝试得到最优化结果
hoRatio:0.1 K:3 error date=5%
hoRatio:0.1 K:4 error date=4% 最低错误率
hoRatio:0.1 K:4 error date=5%
hoRatio:0.5 K:4 error date=6.2%
hoRatio:0.3 K:4 error date=7.67%
hoRatio:0.2 K:4 error date=8%
hoRatio:0.2 K:3 error date=8%
给海伦的程序(交互实现)
def classifyPerson():
resultList = ['没啥感觉','有点感觉','疯狂迷恋']
ffMiles = float(input('每年获得的飞行常客里程数?'))
persentTats = float(input('玩视频游戏所耗时间百分比?'))
icecream = float(input('每周消费的冰淇淋公升数?'))
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat,ranges,minvals=autoNorm(datingDataMat)
inArr = np.array([ffMiles,persentTats,icecream]) #未归一化
classifierResult = classify0((inArr-minvals)/ranges,normMat,datingLabels,3)
print(f'你对这位男嘉宾大概率会{resultList[classifierResult-1]}')
classifyPerson()
测试结果
3.手写识别系统
先将32*32的二进制图像矩阵转换为1*1024的向量。从图像中提取数字的工作前面已完成。
def img2vector(filename):
returnVect =np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect下面创建识别系统:注意listdir要引用from os import listdir
def handwritingClassTest():
hwLables=[]
trainingFileList = listdir('trainingDigits') #返回指定的文件夹包含的文件名字的列表
m = len(trainingFileList)
trainingMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #提取.txt前面的名字
classNumStr = int(fileStr.split('_')[0]) #文件名都为0_77这种,所以取_前面的数字,为图片表示数字
hwLables.append(classNumStr)
trainingMat[i,:]=img2vector(f'trainingDigits/{fileNameStr}')#第i行添加数据
#下面开始测试
testFileList = listdir('testDigits')
errorcount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest=img2vector(f'testDigits/{fileNameStr}')
classifierResult = classify0(vectorUnderTest,trainingMat,hwLables,3)
print(f'the classifier came back with:{classifierResult},the real answer is {classNumStr}')
if classifierResult!=classNumStr:
errorcount+=1
print(f'the error count is {errorcount/float(mTest)}')
handwritingClassTest()最终结果错误率1.0%
最终引用模块包括
