AAAI 2022上那些值得关注的NLP论文

©PaperWeekly 原创 · 作者 | 王馨月
单位 | 四川大学
研究方向 | 自然语言处理

缩略词
1.1 SimCLAD

论文标题:
SimCLAD: A Simple Framework for Contrastive Learning of Acronym Disambiguation
论文链接:
https://arxiv.org/abs/2111.14306
这篇文章的作者针对缩略词消歧问题,提出了一个简单的缩略词消歧对比学习框架(Simple framework for Contrastive Learning of Acronym Disambiguation , SimCLAD)。具体来说是一种持续对比预训练方法,通过学习真实含义和歧义短语之间的短语级对比分布来增强预训练模型的泛化能力。

上图是首字母消歧的示例,目标是预测字典中长形式缩写词的正确含义。一个好的预测不仅应该理解上下文的含 义,还应该区分歧义短语的含义。

上图是本文提出框架的示意图。框架包含两个域预训练模型(学生和教师),它们使用相同的参数进行初始化。在预训练阶段,教师的参数被冻结,为学生模型提供编码表示。此外,教师支持学生模型的 MLM 格式良好的原始目标(即 MLM 与 NSP)。
作者有意 mask 了原始的短形式首字母缩写词()以在教师模型中区分模糊的长形式缩略词(),其中符号 + 和 - 是正样本和负样本。在学生模型的预训练过程中采用了对比损失。具体来说,就是通过将学生模型的输入句子中的缩写词(即 CL)与教师产生的“正确含义”进行屏蔽而不屏蔽相应的短语来获得的。为了获得字典中“reference”的表示(虚线框),我们通过对标记的嵌入进行平均来执行短语平均方法(即对比学习)。
同时,我们让正负样本的表示距离保持距离,以增强模型区分混淆样本的能力。其中学生学习的 masked 缩略词更接近教师产生的真实含义(实线箭头),而远离字典中其他令人困惑的短语(虚线箭头)。
短语级对比预训练 loss 计算如下:

其中 是指示函数,当 是 masked 缩略词并且是相应长格式 的缩写时 。
在微调的过程中,作者连接输入句子的最终隐藏状态 和可能的短语表示 以获得两个分类和对比学习的特征 ,在预训练模型上添加一个非线性投影层,用于获得表示。最后,以多任务的方式进行微调,并对两个分类损失和对比损失进行加权平均:

实验结果如下图,可以看出,预训练模型的性能优于基于规则的方法,因为基于规则的方法由于泛化性差,很难从字典中混淆的首字母缩写词选项中挑选出正确的短语。SciBERT 在三个分数中都击败了 RoBERTa,这表明特定领域的预训练对于科学文档的理解具有重要意义。
科学领域预训练模型可以捕获令人困惑的首字母缩写词的深层表示。hdBERT 融合了不同类型的隐藏特征,以在二进制分类中获得更好的泛化,从而在此任务中表现良好。BERT-MT 的结果表明,确实有很多有用的技巧可以帮助模型增强鲁棒性的能力。
值得注意的是,所提出的方法在三个分数上都优于其他基线,这表明具有持续对比预训练的预训练模型可以进一步提高模型表示首字母缩略词的能力。集成方法可以进一步提高最终结果的多样性,从而在测试集中获得最佳性能。

1.2 PSG

论文标题:
PSG: Prompt-based Sequence Generation for Acronym Extraction
论文链接:
https://arxiv.org/abs/2111.14301
缩略词提取任务(如下图)是指从文档中找到首字母缩写词(短格式)及其含义(长格式),这对于科学文档理解任务很重要。针对这一任务,这篇文章的作者提出了一种基于 prompt 的序列生成(Prompt-based Sequence Generation, PSG)方法。具体来说,作者设计了一个模板,用于 prompting 提取的具有自回归的首字母缩略词文本。并设计位置提取算法用于提取生成答案的位置。在低资源环境中提取越南语和波斯语的缩略词的结果表明,本文所提出的方法优于目前的 SOTA 方法。

作者将首字母缩略词提取任务视为序列生成问题。给定文本的一系列 token ,任务旨在从原始文本中找到相应的位置。标签表示短形式 (即首字母缩写词)和长形式 (即短语),则任务为:

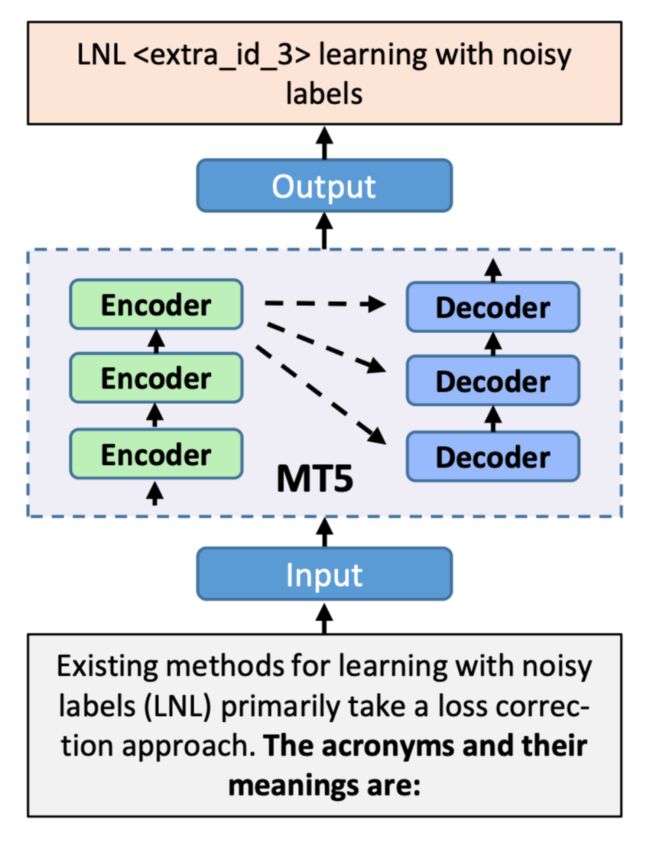
上图是模型架构示意图。作者使用 MT5 模型作为生成序列的 backbone,首先使用手动设计的 prompt 输入文本,使用 MT5 tokenizer 进行标记,然后通过自注意机制使用 encoder 对输入进行编码。最后,输出由 decoder 通过自回归产生。输出包含未使用的 token ,是用于 prompt tuning 的占位符,从而进一步利用来自预训练模型的外部知识。
手动设计 prompt,以从预训练模型中提取相关知识进行序列生成,表示“首字母缩略词及其含义是:”。未使用的 token 被用作占位符来控制输出,形成模板进行提示调优,其中
序列生成的 loss 自回归执行,如下,其中 是上下文编码, 是 decoder 生成的序列中的单词, 是模型参数。

提取位置作者使用了一种贪心遍历搜索的方法,采用从左到右的正则方法来寻找对应的位置边界。同时,需要通过检测边界边距来确保提取的输出没有重叠,使得提取的位置相互独立。算法如下:

作者在越南语和波斯语数据集上实验结果如下:

1.3 ADBCMM

论文标题:
ADBCMM: Acronym Disambiguation by Building Counterfactuals and Multilingual Mixing
论文链接:
https://arxiv.org/abs/2112.08991
项目地址:
https://github.com/WENGSYX/ADBCMM
这篇文章针对首字母消歧问题提出了一种称为 ADBCMM 的方法,为了提升低资源数据集的性能,作者基于课程学习的方法,在预训练模型的基础上,首先对四个不同语言的数据集混合训练,之后再在相关的数据集上“微微调”。在 SDU@AAAI- 22 - Shared Task 2: Acronym Disambiguation 中,作者所提出的方法在法语和西班牙语中获得第一名。
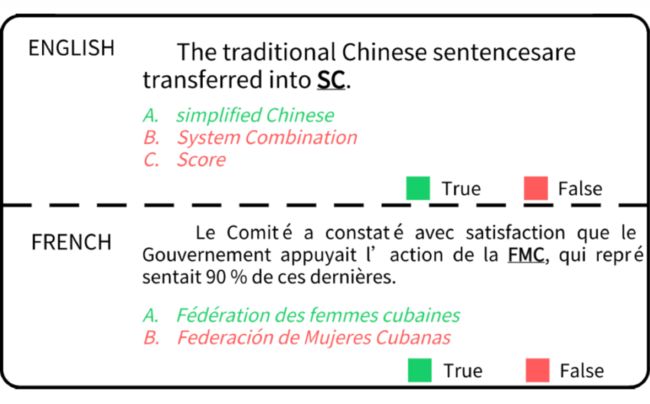
上图是英语与法语的缩略词对比,英语中的缩略词一般是由单词首字母构成,而法语中则不完全是这样。

如上图所示,作者使用多项选择模型框架,多项选择模型是指在 BERT 模型的最终输出中添加分类器,每个句子只有一个输出值来表示这个选项的概率,每批将在训练期间输入同一集合中的所有可能选项。对于每一条短文,我们逐一将“长句-[SEP]-缩略词-[SEP]-短文”作为模型的输出,让模型选择最有可能的一条。
如果字典中的单词不足,使用“Padding”进行填充,最终在输出端进行 softmax 分类和 loss 计算。因此,我们可以通过比较方法更准确地得出每个选项的概率。与二元分类模型相比,多项选择模型捕获了更多的语义特征,使模型更全面地训练和预测差异,避免负样本动态构建造成的误差干扰模型。

如上图,训练过程就像一个金字塔。首先使用多种语言的数据进行训练,然后在预训练的基础上使用一种语言进行二次训练。因为在实验中,随着更多语言样本的添加,模型可能会变得不堪重负。尽管法语、英语和西班牙语属于印欧语系,但它们都具有独特的语言属性、句法和词汇。这将是不同语言的噪声干扰,模型可能会忽略特定语言独有的语义特征,而更愿意学习更常见的语义特征。
作者还使用了对抗学习和 D-Drop,为模型带来1-5%的提升。作者还使用了 Child-tuning,即在训练过程中,只微调小部分的权重。

实验结果如上图所示,BETO 是西班牙语预训练模型,Flaubert-base-cased是法语预训练模型。mDeberta-v3-base 作者也是在单语种中做了对比实验。由表可见,mDeberta-v3-base 的如果论单语种微调的性能,远不如只在单个语种中进行预训练的另外两个模型。
不过,如果加上 ADBCMM,也就是使用四份数据集,先进行训练,之后再在单语种中训练,这能大幅提升模型的效果。其中,“ALLs”表示单模型,使用所有方法在 dev 集中达到的最佳成绩。“Finally in Test”,使用了多个模型进行融合,其中包括五折融合/随机融合/加权融合在内的诸多融合策略,达到了最佳的效果。

问答(QA)
2.1 Block-Skim

论文标题:
Block-Skim: Efficient Question Answering for Transformer
论文链接:
https://arxiv.org/abs/2112.08560
NLP 任务中使用的通用 Transformer encoder 在所有层中处理上下文段落中所有输入标记的隐藏状态。然而,与序列分类等其他任务不同,回答提出的问题并不一定需要上下文段落中的所有标记。出于这一特点,这篇文章的作者提出了 Block-Skim,它可以识别必须进一步处理的上下文以及在推理过程中可以在早期安全丢弃的上下文,以提高 Transformer 的性能。更重要的是,这些信息可以充分地从 Transformer 的自注意力权重中推导出来。
作者在较低层的早期进一步修剪与不必要位置相对应的隐藏状态,可以实现显著的推理时间加速,作者观察到以这种方式修剪的模型性能优于它们的全尺寸模型。Block-Skim 提高了 QA 模型在不同数据集上的准确性,并在 BERTbase 模型上实现了 3 倍的加速。

作者建议将上下文分割成块,通过查看注意力权重来学习一个分类器以在较低层中尽早终止不太相关的块。如上图所示,问题和答案标记用红色标记。只有问题和少量证据块被完全处理(黄色)。利用注意力权重(灰色)的知识,略过其他块以加速。在事实答案位置的监督下,一个联合学习丢弃上下文块回答问题的模型表现出比其全尺寸更好的性能。

如上图,作者提供了一个关于注意力特征图的实证研究,以表明注意力图可以携带足够的信息来定位答案范围。作者比较了训练后的 BERTbase 模型中第 4 层和第 9 层的注意力权重。在第 9 层等后期层,答案标记的注意力权重明显大于不相关标记的注意力权重。然而,在第 4 层等早期层,注意力权重强度对于答案标记和不相关标记无法区分。为了更好地减少延迟,希望尽早找到不相关的令牌。然而,使用注意力权重值作为相关性标准在早期层可能会出现问题。
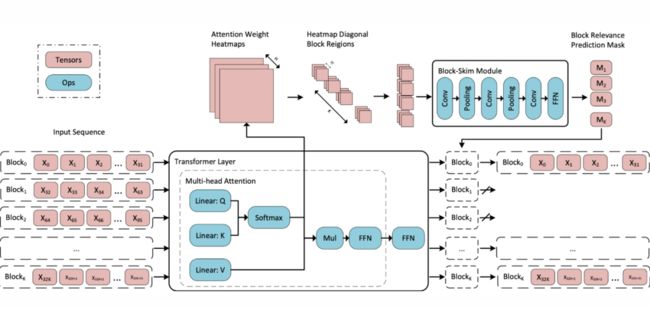
上图是 Block-Skim 的模型示意图,这是基于 Transformer 的模型的即插即用模块,以加速基于 Transformer 的 QA 任务模型。通过将注意力权重矩阵作为特征图处理,只提供对角线区域作为每个输入序列块的输入表示送入 CNN 预测器。使用预测的块掩码,Block-Skim 会跳过不相关的上下文块,这些块不会进入后续层的计算。
此外,作者设计了一种新的训练范式,将 Block-Skim 目标与本地 QA 目标联合训练,其中有关问题位置的额外优化信号直接提供给注意力机制。

实验结果如上图所示,可以看出 Block-Skim 在性能和速度上都有不错的表现。
2.2 MuMuQA

论文标题:
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross- Media Knowledge Extraction and Grounding
论文链接:
https://arxiv.org/abs/2112.10728
这篇文章的作者针对跨模态 QA 任务提出了一个新的 QA 评估基准——Multimedia Multi-hop Question Answering(MUMUQA)task。给定一篇带有图像-标题对和一个问题的新闻文章,系统需要通过从正文文本中提取一小段来回答问题。
重要的是,回答问题需要多跳推理:第一跳,称为图像实体接地,需要图像和标题之间的跨媒体接地,以获得与图像相关的问题的中间答案,命名为桥项 (bridge item);第二跳需要对新闻正文进行推理,通过使用桥项提取一段文本作为最终答案。例如,在下图 a 中,在第一跳中,我们需要将“图像中带蓝色领带的人”定位 到标题中的特定实体“Benjamin Netanyahu”。以“Benjamin Netanyahu”作为第二跳的桥梁项目,进一步从新闻正文中提取最终答案为“Likud”。这些问题需要使用图像中存在的信息进行实体消歧,因此需要跨媒体基础。

此外,作者还引入了一种基于跨媒体知识抽取和综合问答生成的新型多媒体数据增强框架,以自动增强为上述任务提供弱监督的数据。如下图所示,首先,对图像-字幕对进行多媒体实体接地,以识别图像中以字幕为基础的对象,以获得接地实体,例如图中的“Liviu Dragnea”。
接下来,为接地实体生成问题,例如“Liviu Dragnea 被指控了什么?”。我们首先在标题和正文文本上运行最先进的知识提取系统识别正文中对接地实体的提及,例如“Liviu Dragnea”和“chairman ”。它使我们能够找到问题生成的候选上下文,我们将其与接地实体 e 一起输入合成问题生成器以获得问答对(q,a)。
我们确保生成的问题在其文本中提到了接地实体 e。然后,我们编辑这些问题,用其相应的视觉属性替换接地引用,以产生最终的多跳问题,例如“图像中黄色横幅中的人是什么?”。

作者在提出的基准上评估了基于管道和端到端预训练的多媒体 QA 模型。如下图所示,首先,我们将多跳问题拆分为一个引用图像的问题,称为图像问题,以及一个关于文本的问题,称为文本问题。为了实现这一点,作者使用了多跳问题分解模型。如下图中,问题“图像中穿红色外套的人在谈论什么?”分解为“图中穿红衣的人是谁”和“[ANSWER] 谈了什么”,其中 [ANSWER] 表示第一个问题的答案。
我们将第一个问题作为图像问题,将第二个问题作为文本问题。接下来,我们找到一个可以回答图像问题的边框,即图中的蓝色边框。然后,根据嵌入的相似性将图像问题与边框匹配。边框在其视觉属性类上表示为词袋,例如“女人、西装、红色”;问题嵌入也表示为图像问题中标记上的词袋。然后,获得与所选边界框相关的文本跨度,例如蓝色边框的“Nikki Haley”,将此文本跨度称为桥项。最后,我们将桥项插入到文本问题中,并针对单跳纯文本 QA 模型运行它,以获得最终答案。

下图是 MUMUQA 基准的开发和测试集的各种 baseline 的结果,使用最终答案的宏观平均 F1 分数进行评估。结合多媒体知识提取的好处可以从基于管道的多媒体 QA 系统的强大性能中看出。有趣的是,我们看到端到端多媒体 QA 基线的性能不如多跳纯文本系统。这可能是因为 OSCAR 使用图像-字幕对进行了预训练,这使得它可能不适合对较大的文本输入(在这种情况下为新闻正文)进行推理。


关系识别/抽取
3.1 LDSGM

论文标题:
A Label Dependence-aware Sequence Generation Model for Multi-level Implicit Discourse Relation Recognition
论文链接:
https://arxiv.org/abs/2112.11740
项目地址:
https://github.com/nlpersECJTU/LDSGM
隐式语篇关系识别(Implicit discourse relation recognition, IDRR)是语篇分析中一项具有挑战性且至关重要的任务。大多数现有方法训练多个模型独立地预测多级标签,忽略了层次结构标签之间的依赖关系。这篇文章的作者将多级 IDRR 视为条件标签序列生成任务,并为此提出了标签依赖感知序列生成模型(Label Dependence-aware Sequence Generation Model, LDSGM)。
作者首先设计了一个标签注意力 encoder 来学习输入实例的全局表示及其特定级别的上下文,其中集成了标签依赖性以获得更好的标签嵌入。然后,作者使用标签序列 decoder 以自上而下的方式输出预测标签,其中预测的更高级别的标签直接用于指导当前级别的标签预测。
作者进一步开发了一种相互学习增强的训练方法,以利用自下而上方向的标签依赖性,该方法由训练期间引入的辅助解码器捕获。在 PDTB 数据集上的实验结果表明,这篇文章的模型在多级 IDRR 上实现了 SOTA 性能。

上图是带注释的多级标签和插入的连接词的隐式 PDTB 实例。它由两个参数(arg1 和 arg2)组成,并使用三个分层标签进行注释,其中第二级/子标签导致进一步细化顶级/父标签 Contingency 的语义,依此类推。在标注过程中,先插入隐式连接词因为有利于标注标注,可以认为是最细粒度的标注。

上图是 LDSGM 的模型架构。模型主要由一个标签注意力 encoder 和一个标签序列 decoder 组成。
标签注意力 encoder 包括几个堆叠的 Transformer 层、一个图卷积网络(GCN) 和特定于级别的标签注意机制。具体来说,使用 Transformer 层来学习输入实例的局部和全局表示,使用 GCN 通过整合分层结构标签之间的依赖关系来获得更好的标签嵌入,最后使用标签注意机制来从局部表示提取特定级别的上下文。之后,将学习到的全局表示和特定级别的上下文用作 decoder 的输入,以生成标签序列。
标签序列 decoder是一个基于 RNN 的 decoder,它以自上而下的方式(即顶级标签、二级标签等)顺序生成预测标签。通过这样做,可以使用易于预测的更高级别的标签来指导当前级别的标签预测。作者选择门循环单元(GRU)来构建 decoder,因为它在文本生成中的广泛使用和标签序列的短长度(Transformer 也可以用作解码器)。

上图是训练过程的算法描述,最显著的特点是模型和辅助 decoder 可以通过在训练期间在它们之间迭代地传递知识来相互促进。为此,除了传统的基于交叉熵的损失之外,作者还引入了两个额外的损失来最小化这两个解码器的预测标签分布之间的差异:

其中 表示训练集, 和 是 encoder 和 decoder 的参数集, 是辅助 decoder 的参数集。 是真实标签的 one-hot 编码, 和 分别是 decoder 和辅助 decoder 预测到的第 m 级的标签分布。 是 的期望, 是 KL 散度。 是用于控制不同损失项目影响的系数。重复上述知识转移过程,直到两个损失函数收敛。这样做可以捕获自上而下和自下而上方向的标签依赖性。

上图是作者在 PDTB 数据集上进行实验的结果,可以得出:
1. 所有使用上下文词嵌入增强的模型都优于使用静态词嵌入的模型;
2. 在大多数情况下,联合推断多级标签(HierMTN-CRF-RoBERTa、OurEncoder+OurDecoder、LDSGM)比在 BMGF-RoBERTa 中单独预测的性能更好,这意味着整合标签依赖性确实有帮助;
3. LDSGM 模型在所有三个级别的分类任务上都达到了最先进的性能。

上图是作者消融学习的实验结果。
3.2 AT-BMC

论文标题:
Unifying Model Explainability and Robustness for Joint Text Classification and Rationale Extraction
论文链接:
https://arxiv.org/abs/2112.10424
项目地址:
https://github.com/crazyofapple/AT-BMC
这篇文章的作者提出了一种名为 AT-BMC 的联合分类和基本原理提取模型。它包括两个关键机制:混合对抗训练(Adversarial Training, AT)——旨在使用离散和嵌入空间中的各种扰动来提高模型的鲁棒性;边界匹配约束(Boundary Match Constraint, BMC)——有助于在边界信息引导下更准确地定位关系。
在基准数据集上的实验表明,所提出的 AT-BMC 在分类和基本原理提取方面都大大优于基线。鲁棒性分析表明,所提出的 AT-BMC 有效地将攻击成功率降低了 69%。实证结果表明,稳健的模型和更好的解释之间存在联系。

上图是 AT-BMC 模型的框架。首先使用预训练的语言模型作为共享编码器,将输入编码作为隐藏表示。然后使用线 性分类器对 和 进行建模。输出是由线性分类器预测的标签和由 CRF 解码器生成的基本原理跨 度。作者还根据分类模型的预测标签输出来调节提取模型。通过使用嵌入查找层来实现这一点,并将标签嵌入添加 到编码器的每个 token 表示中。

上图是嵌入层的对抗训练算法。

上图是具有基本原理提取的两个文本分类任务的性能比较以及消融实验。作者比较了使用不同编码器(即 BERT- base 和 RoBERTa-large)的 AT-BMC 的测试集结果。
3.3 Hierarchical Stochastic Attention

论文标题:
Transformer Uncertainty Estimation with Hierarchical Stochastic Attention
论文链接:
https://arxiv.org/abs/2112.13776
这篇文章的作者提出了一种使 transformer 具有不确定性估计的能力,同时保留原始的预测性能的方法。这是通过学习分层随机自注意力来实现的,该自注意力分别关注值和一组可学习的质心。然后使用 Gumbel-Softmax 技巧混合采样质心形成新的注意力头。理论上表明,通过从 Gumbel 分布中采样的自注意力近似是有上限的。作者在具有域内(in-domain, ID)和域外(out-of-domain, OOD)数据集的两个文本分类任务上评估模型。
实验结果本文提出的方法:(1)在比较方法中实现了最佳的预测性能和不确定性权衡;(2)在 ID 数据集上表现出非常有竞争力的预测性能;(3)在 OOD 数据集的不确定性估计中与 Monte Carlo dropout 和 ensemble 方法相当。

上图是不确定性估计的方法。(a)确定性神经网络输出单点预测;(b)贝叶斯神经网络通过从高斯分布中采样来捕捉不确定性;(c)变分 dropout 通过从 Bernoulli 分布中采样 dropout 掩码来捕获不确定性;(d)集成通过将多个独训练的确定性模型与不同的随机种子相结合来捕捉不确定性;(e)用于不确定性估计的 Gumbel-Softmax 技巧,随机性来自 Gumbel 的抽样分类分布。
与上述模型不同,作者提出了一种基于 Gumbel-Softmax 技巧或 Concrete Dropout 的简单而有效的方法。首先,将每个 self-attention head 中的值的确定性注意力分布转换为随机的。然后从 Gumbel-Softmax 分布中对注意力进行采样,该分布控制值上的浓度。
接着将 self-attention 中的关键头正则化以关注一组可学习的质心。这相当于对键执行聚类或对 RNN 中的隐藏状态进行聚类。然后每个新的键头将由 Gumbel-Softmax 采样质心的混合形成。通过从 Gumbel-Softmax 分布中采样来注入随机性。使用这种机制,我们使用基于分层随机自注意的随机变换器来近似 vanilla transformer,即 H-STO-TRANS,它能够对值以及一组可学习质心上的注意分布进行采样。

上图是确定性和随机变换器中多头自注意力的说明。(a)具有确定性自注意的 vanilla transformer。(b)随机 transformer 具有用于加权值 V 的随机自注意力,标准的 Softmax 被 Gumbel-Softmax 取代。(c)分层随机 transformer 随机学习注意值 V 和一组可学习的质心 C。

上图是分层随机 transformer 的算法。具体细节也可以在原文中进一步了解。

上图是在 IMDB(ID)和 CR(OOD)数据集上模型的预测性能和不确定性估计。
3.4 Evaluating-Explanations

论文标题:
Explain, Edit, and Understand: Rethinking User Study Design for Evaluating Model Explanations
论文链接:
https://arxiv.org/abs/2112.09669
项目地址:
https://github.com/siddhu001/Evaluating-Explanations
这篇文章的作者进行了一项众包研究,参与者与经过训练以区分真假酒店评论的欺骗检测模型进行交互。他们既要在新评论上模拟模型,又要编辑评论以降低最初预测类别的概率。在训练(但不是测试)阶段,输入跨度被突出显示以传达显著性。通过评估,作者观察到对于线性词袋模型,与无解释控制相比,在训练期间访问特征系数的参与者能够在测试阶段导致模型置信度的更大程度降低。对于基于 BERT 的分类器,流行的局部解释并不能提高其在无解释情况下降低模型置信度的能力。

上图是本文的用户研究,在训练阶段向参与者展示:a)首先,参与者猜测模型预测;(b)参与者编辑评论以降低模型对预测类别的信心。参与者会实时收到有关其编辑的反馈、观察更新的预测、信心和归因。
作者测量了三个指标(a)模拟准确性(b)模型置信度的平均降低(c)翻转示例的百分比。三种混合效应模型可以描述为:


上图是不同解释下的人类表现。没有任何解释有助于参与者模拟模型,而对 BERT 模型的全局解释和逻辑回归模型的特征系数有助于降低模型置信度。

上图是相对于 3 个目标指标的控制的固定效应项 。
作者得出结论:对于线性模型和基于 BERT 分类器的几种解释都没有提高模型的可模拟性。当属性不可用时,在训 练期间可以访问特征系数的参与者可能会在测试期间导致模型置信度大幅下降。有趣的是,对于基于 BERT 的分类器,使用经过训练以模拟其预测的线性学生模型获得的全局提示词和特征系数被证明是有效的。这些结果表明,线 性学生模型的关联可以为基于 BERT 的模型提供见解,重要的是,编辑范式可用于区分解释的相对效用。
3.5 CAP

论文标题:
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
论文链接:
https://arxiv.org/abs/2112.07198
项目地址:
https://github.com/alibaba/AliceMind/tree/main/ContrastivePruning
为了在剪枝模型中保持与任务无关和特定于任务的知识,这篇文章的作者在预训练和微调的范式下提出了对比剪枝(ContrAstive Pruning, CAP)。CAP 被设计为一个通用框架,与结构化和非结构化剪枝兼容。CAP 能够让剪枝后的模型从预训练的模型中学习任务不可知的知识,以及微调模型中的任务特定知识。此外,为了更好地保留剪枝模型的性能,快照(即每次剪枝迭代的中间模型)也可以作为剪枝的有效监督。
实验表明,采用 CAP 始终会产生显著的改进,尤其是在极其稀疏的场景中。仅保留 3% 的模型参数(即 97% 的稀疏性),CAP 在 QQP 和 MNLI 任务中成功实现了原始 BERT 性能的 99.2% 和 96.3%。此外,探索性实验表明,经过 CAP 修剪的模型往往具有更好 的泛化能力。

上图是带有和不带有 CAP 的 BERT 剪枝的比较。展示了具有不同模型稀疏度(50%、90% 和 97%)的 MNLI、QQP 和 SQuAD 任务的平均分数。CAP 在不同的剪枝标准下始终如一地产生改进,在更高的稀疏度下获得更大的收益(1.0 → 1.3 → 2.0)。

图是 CAP 的框架,逐步剪枝模型 ,其中数字表示稀疏率(%)。总体而言,CAP 由 三个对比模块组成:PrC、SnC 和 FiC。
PrC(绿线):使用预训练模型 进行对比学习,以保持与任务无关的知识。
SnC(黄线):使用快照 进行对比学习,以弥合预训练模型和当前修剪模型之间的差距,并获得历史和多样 化的知识。
FiC(蓝线):使用微调模型 进行对比学习,以获得特定于任务的知识。
实线表示当前修剪模型 的学习,而虚线表示先前快照 和 的学习。
将 PrC、SnC 和 FiC 放在一起,就可以得到 CAP 框架。注意,我们可以灵活地与 CAP 中的不同修剪标准集成。
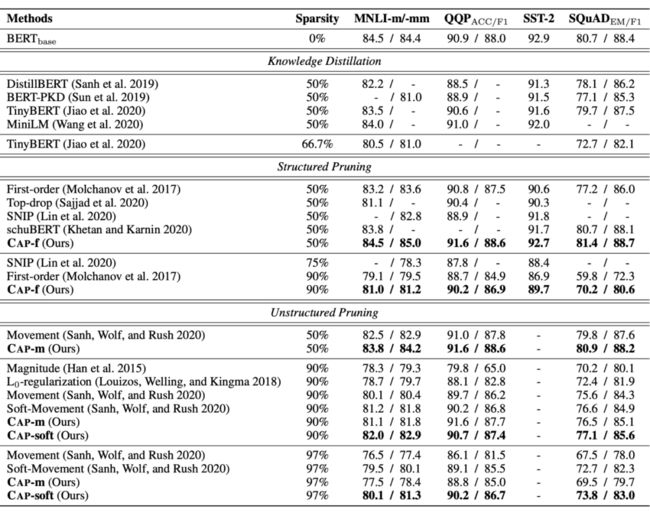
上图是 CAP 与其他没有数据增强的模型压缩方法的比较。CAP 在不同任务的相同稀疏率下始终实现最佳性能。

上图是不同对比模块的消融研究。可以看出删除任何对比模块都会导致修剪模型的退化,尤其是在高度稀疏的情况下。
作者在原文中还给出了更详细的实验结果对比,值得进一步学习。
3.6 Probing Linguistic Information

论文标题:
Probing Linguistic Information For Logical Inference In Pre-trained Language Models
论文链接:
https://arxiv.org/abs/2112.01753
这篇文章的作者提出了一种在预训练的语言模型表示中探测语言信息以进行逻辑推理的方法。探测数据集涵盖了主要符号推理系统所需的语言现象列表。作者发现(i)预训练的语言模型确实编码了几种类型的语言信息用于推理,但也有一些类型的信息被弱编码(ii)语言模型可以通过微调有效地学习缺失的语言信息。总体而言,作者的研究结果提供了关于语言模型及其预训练程序捕获逻辑推理的语言信息的哪些方面的见解。此外,作者展示了语言模型作为支持符号推理方法的语义和背景知识库的潜力。

作者提出的推理信息探测框架如上图所示。作者定义了一组探测任务,专注于符号系统所需的不同类型的语言信息。特别是,涵盖了关于句法、基本语义和高级语义推理的语言信息。高级语义推理通常依赖于多种类型的基本语义。例如,基于关系知识的语义对齐需要回指解析、命名实体和词汇语义。我们要回答两个问题:(1)预训练的语言模型是否对符号推理系统必不可少的语言信息进行编码?(2)预训练的语言模型是否在 NLI 任务的微调过程中获取新的语言信息以进行推理?

上图是句子 “A young and tall boy wearing a black uniform is trying to catch a fast soccer ball, in front of a soccer goal.” 的用于表示语义知识的语义图。

上图是语义对齐任务和矛盾签名检测任务的示例。红色框是语义对齐的跨度。黄色框是形成矛盾签名的跨度。蓝色框是与语义对齐或矛盾无关的跨度。这里 P 代表前提,H 代表假设。对于标签, 表示 和 对齐。 表示标记 到 属于语义对齐对中的第一个短语。探测数据首先从 NLU 的多个挑战数据集中收集,然后为边缘和顶点探测框架手动注释。

上图列出了探测和微调实验的结果。语言模型为一个标签编码比其他标签更多的语言信息。这种标签方面的信息差异再次证明了一些语言信息在语言模型中的推理缺失和不完整。此外,我们发现语言模型可以通过对 NLI 任务的微调来有效地学习高级语义推理中某些类型的缺失信息。总体而言,语言模型显示出作为支持更强大的符号推理的语言信息知识库的潜力。
对于未来的工作,可以通过构建更详细的探测数据集对语言模型中的每种语言信息进行进一步分析。人们还可以设计逻辑系统,该系统可以从预先训练的语言模型中访问语言信息,并将它们应用到推理过程中,以提高大型基准测试的性能。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
