[半监督学习] Dual Student: Breaking the Limits of the Teacher in Semi-supervised Learning
与之前的 Mean-Teacher 相比, 这里引入了 Dual Student 概念, 用另一个学生代替老师. 同时定义了一个新的概念: 稳定样本, 为模型结构设计了一个可训练的稳定约束.
论文地址: https://arxiv.org/abs/1909.01804
代码地址: https://github.com/ZHKKKe/DualStudent
会议: ICCV 2019
任务: 分类
Mean-Teacher 结构中的两个角色是紧密耦合的, 并且耦合程度随着训练的进行而增加. 这种现象导致性能瓶颈. 对此, 提出一种新的模式: 用另一个Student Model 取代 Teacher Model. 这两名 Student 共享具有不同初始状态的相同网络架构并分别更新. 因此, 它们的权重不会紧密耦合, 并且每个人都学习自己的知识. 不过由于两个 Student 互不相同, 添加一致性约束可能会导致两个模型相互崩溃. 因此, 这里定义一个概念: 稳定样本, 并提出了一个稳定约束来实现有效的知识交换.
1.Teacher-Student Model
关于 Teacher-Student 模型, 它在 Teacher Model 和 Student Model 之间应用一致性约束来从未标记的数据中学习知识. 形式上, 假设数据集 D \mathcal{D} D 由标记和未标记数据组成, θ ′ \theta' θ′, θ \theta θ 分别表示 Teacher 和 Student 的权重(参数), 一致性约束定义为:
L c o n = E x ∈ D R ( f ( θ , x + ζ ) , T x ) (1) \mathcal{L}_{con}=\mathbb{E}_{x\in\mathcal{D}}\mathcal{R}(f(\theta,x+\zeta),\mathcal{T}_{x})\tag{1} Lcon=Ex∈DR(f(θ,x+ζ),Tx)(1)
其中, f ( θ , x + ζ ) f(\theta,x+\zeta) f(θ,x+ζ) 是 f ( θ ) f(\theta) f(θ) 关于带噪声 ζ \zeta ζ 的数据 x x x 的预测结果. T x \mathcal{T}_{x} Tx 为来自 Teacher 的一致性目标. R \mathcal{R} R 为距离衡量, 通常可用 KL 散度, MSE 等.
2. Deep Co-Training
众所周知, 融合来自多个模型的知识可以提高 SSL 的性能, 即集成(ensembling). 但是, 直接在模型之间添加一致性约束会导致模型相互影响变差. 深度协同训练(Deep Co-Training)利用传统协同训练算法的假设来解决这一问题.
它将来自卷积层的特征视为输入的视图, 并使用来自其他合作学习器的对抗样本来确保模型之间存在视图差异. 然后可以使用一致的预测进行训练. 但是, 该策略需要在整个过程中生成每个模型的对抗样本,这既复杂又耗时.
Dual Student 中也有模型之间的交互, 以打破 EMA Teacher 的限制, 不过 Dual Student 与 Deep Co-Training 之间有两个主要区别:
- Dual Student 没有强制执行一致性约束和不同视图约束, 而是只提取模型的可靠知识, 并通过更有效的稳定约束进行交换.
- Dual Student 方法更有效, 因为其不需要对抗样本.
3. EMA Teacher 的局限性
在讲 Dual Student 之前需要简述一下 Mean-Teacher 的一些局限性及原因.
SSL 中的一个基本假设是平滑假设: 如果高密度区域中的两个数据点接近, 那么相应的输出也应该接近. 现有所有的 Teacher-Student 方法都根据这一假设来使用未标记的数据. 在实践中, 如果 x x x 和 x ‾ \overline{x} x 是从具有不同小扰动的样本中生成的, 那么它们在 Teacher 和 Student 中应该有一致的预测, 并通过一致性约束来实现这一点. 主要集中连个点上: 1.通过集成的方式; 2.精心设计的噪声生成更有意义的目标.
然而 Teacher 本质上是 Student 的 EMA. 因此, 它们的权重是紧密耦合的. Teacher 的 θ ′ \theta' θ′ 更新式子如下:
θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t (2) \theta'_t=\alpha\theta'_{t-1}+(1-\alpha)\theta_t\tag{2} θt′=αθt−1′+(1−α)θt(2)
其中, μ \mu μ, μ ′ \mu' μ′ 分别为 Student 和 Teacher 的扰动(噪声). 当 α = 0 \alpha=0 α=0 时, Mean Teacher Model 与 Π \Pi Π-model 和 VAT 在形式上等价.
Student 的 θ \theta θ 随着模型的收敛而减少, 即 ∣ θ t − θ t − 1 ∣ |\theta_t − \theta_{t−1}| ∣θt−θt−1∣ 随着训练步数 t t t 的增加, 变得越来越小. 而在理论上, 可以证明 EMA Teacher 和 Student 的收敛序列有相同的极限, 所以当训练过程收敛时, Teacher 将非常接近 Student.
为了进一步可视化, 在 CIFAR-10 SSL 基准上训练了两个结构. 一个包含一个 Student 和一个 EMA Teacher(名为 Sema), 而另一个包含两个独立的模型(名为 Ssplit). 然后, 计算每个结构中两个模型之间的 θ \theta θ 及预测的欧几里得距离. 如下图所示:
![[半监督学习] Dual Student: Breaking the Limits of the Teacher in Semi-supervised Learning_第1张图片](http://img.e-com-net.com/image/info8/e7f04db2e4db47498c5f8e9153c25bd4.jpg)
正如预期的那样, Sema 的 EMA Teacher 与 Student 非常接近, 并且随着 epoch 的增加, 他们的距离接近于零. 相比之下, Ssplit 中的两个模型始终保持较大的距离.
如果 Student 对特定样本的预测有偏差, EMA Teacher 有可能积累错误并强制学生跟随, 使错误分类不可逆转. 大多数方法对一致性约束应用了 ramp-up/down 操作来减轻偏差, 但不足以解决问题. 如 Mean-Teacher 中使用的 ramp-down:
def cosine_rampdown(current, rampdown_length):
"""Cosine rampdown from https://arxiv.org/abs/1608.03983"""
assert 0 <= current <= rampdown_length
return float(.5 * (np.cos(np.pi * current / rampdown_length) + 1))
所以从这个角度来看, 训练独立模型也是有益的.
4. Dual Student
通过上述分析, Dual Student 通过同时训练两个独立的模型来获得松耦合的目标. Dual Student 模型如下图所示:
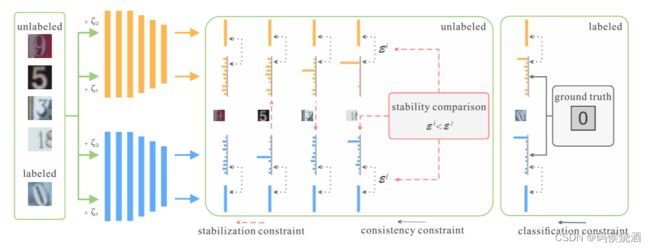
然而, 这两个模型的输出可能相差很大, 直接应用一致性约束会导致它们通过交换错误的知识而相互崩溃. 由于耦合效应, EMA Teacher 不会遇到这个问题.
于是提出了一种有效的方法来克服这个问题, 即只交换模型的可靠知识. 为此需要解决两个问题:
- 如何定义和获取模型的可靠知识.
- 如何相互交换知识.
4.1 稳定样本(Stable Sample)
为解决第一个问题, 引入稳定样本(Stable Sample)概念. 模型可以看作是一个决策函数, 它可以对某些样本做出可靠的预测, 但对其他样本则不能. 这里定义了稳定样本, 并将其视为模型的可靠知识. 稳定样本需要满足两个条件:
- 根据平滑假设, 一个小的扰动不应该影响这个样本的预测, 即模型应该在这个样本的附近是平滑的.
- 这个样本的预测远离决策边界. 这意味着这个样本对于预测标签的概率很高.
Definition 3.1(Stable Sample). 给定一个常数 ξ ∈ [ 0 , 1 ) \xi \in [0, 1) ξ∈[0,1), 一个满足平滑假设的数据集 D ⊆ R m \mathcal{D} \subseteq \mathbb{R}^m D⊆Rm 和一个模型 f : D → [ 0 , 1 ] n f : \mathcal{D} \rightarrow [0, 1]^n f:D→[0,1]n, 对所有 x ∈ D x \in D x∈D 满足 ∥ f ( x ) ∥ 1 = 1 \lVert f(x)\rVert_1 = 1 ∥f(x)∥1=1, 且:
- ∀ x ‾ ∈ D \forall \overline{x} \in \mathcal{D} ∀x∈D, 在 x x x 附近, 它们的预测标签是相同的.
- x x x 满足不等式: ∥ f ( x ) ∥ ∞ > ξ \lVert f(x)\rVert_\infty > \xi ∥f(x)∥∞>ξ
则 x x x 是关于 f f f 的稳定样本. 如下图中, 只有 x 3 x_3 x3, x ‾ 3 \overline{x}_3 x3 满足.

另外可以通过其邻域的预测一致性来反映 x x x 的稳定程度, 预测越一致, x x x 就越稳定.
4.2 通过稳定约束进行训练(Training by the Stabilization Constraint)
为解决第二个问题, 进行如下讨论.
在实践中, 只使用两个接近的样本来近似稳定样本的条件, 以减少计算开销. 形式上, 使用 θ i \theta_i θi 和 θ j \theta_j θj 来表示两个 Student 的权重. 首先定义一个布尔函数 { c o n d i t i o n } 1 \{condition\}_1 {condition}1, 当条件为真时输出1, 否则输出0. 假设 x ‾ \overline{x} x 是样本 x x x 的噪声增强. 然后检查 x x x 是否是 Student i i i 的稳定样本:
R x i = { P x i = P x ‾ i } 1 & ( { M x i > ξ } 1 ∥ { M x ‾ i > ξ } 1 ) (3) \mathcal{R}_x^i=\{\mathcal{P}_x^i=\mathcal{P}_{\overline{x}}^i\}_1 \& (\{\mathcal{M}_x^i > \xi\}_1 \rVert \{\mathcal{M}_{\overline{x}}^i > \xi\}_1) \tag{3} Rxi={Pxi=Pxi}1&({Mxi>ξ}1∥{Mxi>ξ}1)(3)
其中 M x i = ∥ f ( θ i , x ) ∥ ∞ \mathcal{M}_x^i=\lVert f(\theta^i,x) \rVert_{\infty} Mxi=∥f(θi,x)∥∞, P x i \mathcal{P}_x^i Pxi, P x ‾ i \mathcal{P}_{\overline{x}}^i Pxi 分别为 x x x, x ‾ \overline{x} x 的预测值. 超参数 ξ \xi ξ 是 [ 0 , 1 ) [0, 1) [0,1) 中的置信度阈值. 如果样本 x x x 的最大预测概率超过 ξ \xi ξ, 则认为 x x x 离分类边界足够远. 然后用欧几里得距离来衡量预测的一致性, 来表示 x x x 的稳定性, 如下:
ε x i = ∥ f ( θ i , x ) − f ( θ i , x ‾ ) ∥ 2 (4) \varepsilon_x^i=\lVert f(\theta^i,x)-f(\theta^i,\overline{x}) \rVert^2 \tag{4} εxi=∥f(θi,x)−f(θi,x)∥2(4)
较小的 ε x i \varepsilon_x^i εxi 意味着 x x x 对 Student i i i 更稳定. Student i i i 和 j j j 的预测之间的距离可以使用均方误差(MSE)来衡量:
L m s e ( x ) = ∥ f ( θ i , x ) − f ( θ j , x ) ∥ (5) \mathcal{L}_{mse}(x) = \lVert f(\theta^i,x)-f(\theta^j,x) \rVert \tag{5} Lmse(x)=∥f(θi,x)−f(θj,x)∥(5)
最后, Student i i i 在样本 x x x 上的稳定约束写为:
L s t a i ( x ) = { { ε x i > ε x j } 1 L m s e ( x ) , R x i = R x j = 1 R x j L m s e ( x ) , o t h e r v i s e (6) \mathcal{L}_{sta}^i(x) = \begin{cases} \{\varepsilon_x^i > \varepsilon_x^j\}_1 \mathcal{L}_{mse}(x),\mathcal{R}_x^i=\mathcal{R}_x^j=1 \\ \mathcal{R}_x^j \mathcal{L}_{mse}(x),othervise \\ \end{cases} \tag{6} Lstai(x)={{εxi>εxj}1Lmse(x),Rxi=Rxj=1RxjLmse(x),othervise(6)
以相同的方式计算 Student j j j 的稳定约束. 正如我们所看到的, 稳定约束根据两个学生的输出动态变化. 有三种情况:
- 如果 x x x 对两个 Student 都不稳定, 则不应用约束.
- 如果 x x x 只对 Student i i i 稳定, 它可以引导 Student j j j.
- 如果 x x x 对于两个 Stusent 都是稳定的, 则计算稳定性, 并将约束从更稳定的一个应用到另一个.
Student i i i 的最终约束是三个部分的组合: 分类约束、每个模型中的一致性约束和模型之间的稳定性约束. 如下:
L i = L c l s i + λ 1 L c o n i + λ 2 L s t a i (7) \mathcal{L}^i=\mathcal{L}_{cls}^i+\lambda_1\mathcal{L}_{con}^i+\lambda_2\mathcal{L}_{sta}^i \tag{7} Li=Lclsi+λ1Lconi+λ2Lstai(7)
其中 λ 1 \lambda1 λ1 和 λ 2 \lambda2 λ2 是平衡约束的超参数. 训练过程如下:

4.3 Dual Student 的变种(Variants of Dual Student)
这里有 Dual Student 的两个变体, 名为 Multiple Student 和 Imbalanced Student.
Multiple Student: 遵循与深度协同训练(Deep Co-Training)相同的策略, 假设 Multiple Student 包含 2 n 2n 2n 个学生模型, 在每次迭代中, 将这些学生随机分成 n n n 对, 然后像 Daul Student 一样更新每一对. 由于此方法不需要模型具有视图差异, 因此数据流可以在 Stusent 之间共享. 这与 Deep Co-Training 不同, 后者要求每对都有一个专有的数据流. 在实践中, 四名 Student ( n = 2 n = 2 n=2) 比两名 Stusent 取得了明显进步. 但是拥有四个以上的 Student 并不会进一步提高表现.
Imbalanced Student: 由于具有更多参数的架构通常具有更好的性能, 因此可以使用预先训练的高性能 Teacher 来改进知识蒸馏(Knowledge Distillation)任务中的轻量级 Student. 基于同样的想法, 通过增强一个学生的能力, 将 Dual Student 扩展到 Imbalanced Student. 但是, 不将复杂模型视为 Teacher, 因为知识将相互交换. 这里发现弱学生的进步与强学生的能力成正比.