tensor学习笔记
tensor学习
-
- 前言
- 一、什么是张量?
- 二、张量:多维数组
-
- (1)、从 Python 列表到 PyTorch 张量
- (2)、创建Tensor
- (3)、张量的元素类型
-
-
- 1、元素类型介绍
- 2、管理dtype属性
-
- (4)、张量的存储视图
-
-
- 索引存储区
-
- (5)、张量元数据:大小、偏移量和步长
-
-
- 另一个张量的存储视图
-
- (6)、转置
-
-
- 无复制转置
-
- 三、Tensor操作
-
- (1)tensor基本操作
- (2)tensor索引
- (3)广播机制
- 四、tensor和numpy的互相转换
-
-
- Tensor`转NumPy:
- NumPy数组转Tensor:
-
- 五、将张量存储到 GPU
- 六、序列化张量
-
-
- 用 h5py 序列化到 HDF5
-
- Torch Hub
-
- 实操
-
- 1、探索可用的接入点
- 2、加载模型
- 3、探索加载的模型
前言
此博客是对于pytorch的tensor(张量)学习的记录,以加强自己对于tensor的理解和保存笔记,该博客吸收了大量CSDN大佬们的笔记。
一、什么是张量?
在深度学习中支持的一些应用程序,它们总是以某种形式获取数据,如图像或文本数以另一种形式生成数据,如标签、数字或更多的图像或文本。
由于浮点数是网络处理信息的方式,因此我们需要一种方法,将我们希望处理的真实世界的数据编码为网络可理解的数据,然后将输出解码为我们可以理解和使用的数据。为此,PyTorch 引入了一种基本的数据结构:张量(tensor),在深度学习中,我们通常会频繁地对数据进行操作。
tensor的另一个名称是多维数组,张量的维度与用来表示张量中标量值的索引数量一致
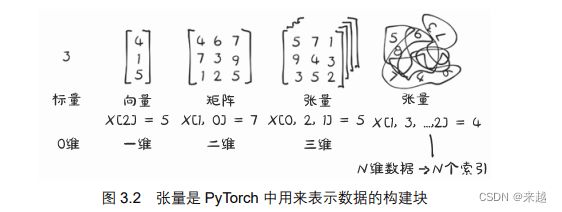
PyTorch 并不是处理多维数组的唯一库。到目前为止,NumPy是最受欢迎的多维数组库,可以说它已成为数据科学的通用语言。PyTorch 具有与 NumPy 无缝互操作的特性,这使得它能够与 Python 中的其他科学库(如 SciPy、scikit-learn 以及 pandas 等)进行最优的集成。
与 NumPy 数组相比,PyTorch 张量具有一些“超能力”,如在 GPU 上执行非常快的操作、在多个设备或机器上进行分布式操作以及跟踪创建它们的计算图。在实现现代深度学习库时,这些都是重要的特性,使Tensor更加适合深度学习。
二、张量:多维数组
张量是一个数组,也就是一种数据结构,
它存储了一组数字,这些数字可以用一个索引单独访问,也可以用多个索引访问。
(1)、从 Python 列表到 PyTorch 张量
让我们看看列表索引的作用,这样我们就可以将其与张量索引进行比较。让我们看看 Python中由 3 个数字组成的列表
# In[1]:
a = [1.0, 2.0, 1.0]
我们可以使用对应的从 0 开始的索引来访问列表的第 1 个元素:
# In[2]:
a[0]
# Out[2]:
1.0
同理修改第三个值:
# In[3]:
a[2] = 3.0
a
# Out[3]:
[1.0, 2.0, 3.0]
(2)、创建Tensor
创建Tensor:
import torch
创建代码汇总:
#创建一个未初始化的tensor
x = torch.empty(5,3)
#初始化一个随机的tensor
x = torch.rand(5,3)
#初始化一个long型全0的tensor
x = torch.zeros(5,3,dtype=torch.long)
#初始化一个确定好数值的tensor
x = torch.tensor([[5,5,2],[1,2,3]])
#默认具有相同的dtype和device
x = x.new_ones(2,3,dtype=torch.float6)
#指定新的tensor y 具有和x一样的形状
y = torch.randn_like(x,dtype=torch.float)
#获取tensor的形状
x.shape
x.size()
#查看张量维度
x.ndim
其他创建tensor函数:
1、我们创建一个5x3的未初始化的Tensor:
a=torch.empty(5,3)
输出:

2、创建一个5x3的随机初始化的Tensor:
x=torch.rand(5,3)
输出:

3、创建一个5x3的long型全0的Tensor:
x=torch.zeros(5,3,dtype=torch.long)
输出:

4、还可以直接根据数据创建:
x=torch.tensor([5.5,3])
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
输出:
tensor([5.5000,3.0000])
tensor([[4., 1.],
[5., 3.],
[2., 1.]])
5、获取tensor的形状
points.shape
输出:
torch.Size([3, 2])
(3)、张量的元素类型
1、元素类型介绍
在torch中CPU和GPU的张量分别有8种数据类型

在张量中默认数据类型是32位浮点数
在神经网络中发生的计算通常是用 32 位浮点精度执行的。采用更高的精度,如 64 位,并不会提高模型精度,反而需要更多的内存和计算时间。16 位半精度浮点数的数据类型在标准 CPU 中并不存在,而是由现代 GPU 提供的。如果需要的话,可以切换到半精度来减少神经网络占用的空间,这样做对精度的影响也很小。
2、管理dtype属性
为了给张量分配一个正确的数字类型,我们可以指定适当的 dtype 作为构造函数的参数,例如:
double_points = torch.ones(10, 2, dtype=torch.double)
short_points = torch.tensor([[1, 2], [3, 4]], dtype=torch.short)
我们可以通过访问相应的属性来找出一个张量的 dtype 值:
short_points.dtype
#torch.int16
我们还可以使用相应的转换方法将张量创建函数的输出转换为正确的类型,例如:
double_points = torch.zeros(10, 2).double()
short_points = torch.ones(10, 2).short()
或者使用更方便的方法:
double_points = torch.zeros(10, 2).to(torch.double)
short_points = torch.ones(10, 2).to(dtype=torch.short)
在底层,to()方法会检查转换是否是必要的,如果必要,则执行转换。以 dtype 命名的类型转换方法(如 float())是 to()的简写,但 to()方法可以接收其他参数,
在操作中输入多种类型时,输入会自动向较大类型转换。因此,如果我们想要进行 32 位计算,我们需要确保所有的输入最多是 32 位的。
(4)、张量的存储视图
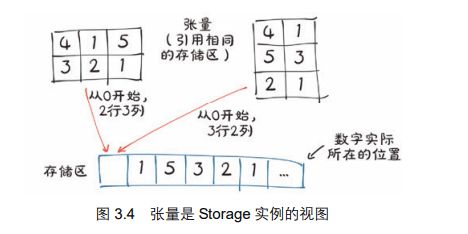
张量中的值被分配到由torch.Storage实例所管理的连续内存块中。存储区是由数字数据组成的一维数组,即包含给定类型的数字的连续内存块,例如 float(代表 32 位浮点数)或 int64(代表 64 位整数)。
一个 PyTorch 的 Tensor 实例就是这样一个 Storage 实例的视图,该实例能够使用偏移量和每个维度的步长(下面有解释)对该存储区进行索引。多个张量可以索引同一存储区,即使它们索引到的数据不同。
索引存储区
在实际中如何使用二维点来索引存储区。可以使用 storage()访问给定张量的存
储区:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points.storage()
#4.0
1.0
5.0
3.0
2.0
1.0
[torch.FloatStorage of size 6]
尽管张量显示自己有 3 行 2 列,但底层的存储区是一个大小为 6 的连续数组。从这个意义上说,张量只知道如何将一对索引转换成存储区中的一个位置。
还可以手动索引存储区。例如:
points_storage = points.storage()
points_storage[0]
#4.0
points.storage()[1]
#1.0
改变一个存储区的值导致与其关联的张量的内容发生变化:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_storage = points.storage()
points_storage[0] = 2.0
points
#tensor([[2., 1.],
[5., 3.],
[2., 1.]])
(5)、张量元数据:大小、偏移量和步长
为了在存储区中建立索引,张量依赖于一些明确定义它们的信息:大小、偏移量和步长。图中显示了他们如何互相作用
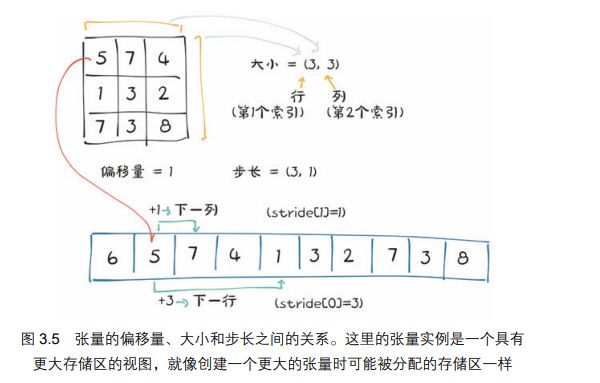
大小(在 NumPy 中称之为形状)是一个元组,表示张量在每个维度上有多少个元素。偏移量是指存储区中某元素相对张量中的第 1 个元素的索引。步长是指存储区中为了获得下一个元素需要跳过的元素数量。
另一个张量的存储视图
我们可以通过提供相应的索引来得到张量中的第 2 个点:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point.storage_offset() #返回tensor的第一个元素与storage的第一个元素的偏移量。
#2
second_point.size()
#torch.Size([2])
得到的张量在存储区中的偏移量为 2,这是因为我们需要跳过第 1 个点,该点有两个元素([4.0,1.0])。同时函数 size()是 Size 类的一个实例,因为该张量是一维的,所以它包含一个元素。需要重点注意的是,函数 size()所包含的信息与张量对象的 shape 属性所包含的信息是一样的。
second_point.shape
#torch.Size([2])
步长是一个元组,指示当索引在每个维度中增加 1 时在存储区中必须跳过的元素数量。例如:
#stride是在指定维度dim中从一个元素跳到下一个元素所必需的步长。
#当没有参数传入时,返回所有步长的元组。否则,将返回一个整数值作为特定维度dim中的步长。
points.stride()
#(2,1) 前面是下一行,后面是下一列
points.stride(0)
#2
points.stride(1)
#1
访问一个二维张量中的位置(i,j)的元素会导致访问存储中的第 storage_offset+stride[0]*i+stride [1]*j 个元素。偏移量通常为 0,如果这个张量是为容纳更大的张量而创建的存储视图,那么偏移量可以为正值。
这种张量和存储区之间的间接关系使得一些操作开销并不大,如果我们想转置一个张量或者提取一个子张量,但存在子张量对原始张量产生影响,因此我们可以通过clone来克隆成一个新的张量
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point[0] = 10.0
points
#tensor([[4., 1.],
[10., 3.],
[2., 1.]])
(6)、转置
无复制转置
我们使用张量 points,它在行中有单独的点,在列中有 x 和 y 坐标,然后将其转置,使各个点都在列中。我们借此机会介绍 t()方法,它是用于二维张量转置的transpose()方法的简写 ,transpose()详细看:transpose()函数
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points
#tensor([[4., 1.],
[5., 3.],
[2., 1.]])
points_t = points.t()
points_t
#tensor([[4., 5., 2.],
[1., 3., 1.]])
我们可以很容易地验证这 2 个张量共享同一个存储区:
id(points.storage()) == id(points_t.storage())
#True
它们只是在形状和步长上有所不同:
points.stride()
#(2, 1)
points_t.stride()
#(1, 2)
这告诉我们,将张量 points 的第 1 个索引增加 1,例如,从 points[0,0]到 points[1,0],将在存储区中跳过 2 个元素,而将第 2 个索引增加 1。例如,从 points[0,0]到点 points[0,1],将在存储区中跳过 1 个元素。换句话说,存储区按顺序逐行保存张量中的元素。
我们将张量 points 转置为 points_t,我们在步长中改变元素顺序后,增加的行(张量的第 1 个索引)将沿着存储区跳跃 1 个单位,就像我们沿着 points 的列移动一样。这就是转置的定义。转置不会分配新的内存,只是创建一个新 Tensor 实例,该实例具有与原始张量不同的步长顺序。
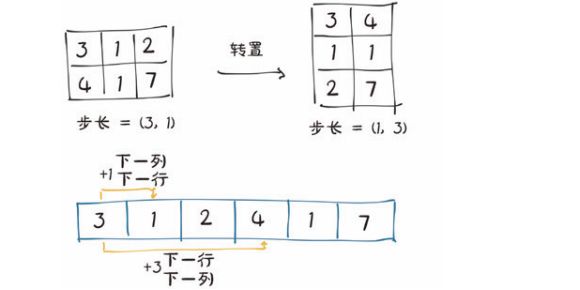
高维转置
PyTorch 中的转置不限于矩阵。我们可以通过指定 2 个维度,即翻转形状和步长,来转置一个多维数组。
一个张量的值在存储区中从最右的维度开始向前排列被定义为连续张量。连续张量很方便,因为我们可以有效地按顺序访问它们,而不必在存储中到处跳转。虽然由于现代 CPU 上的 RAM访问方式,通过改进数据局部性可以提高性能,但这个优势当然取决于算法访问的方式。
连续张量
在 PyTorch 中一些张量操作只对连续张量起作用,如 view()方法。在这种情况下,PyTorch 将抛出一个提供有用信息的异常,并要求我们显式地调用 contiguous()方法。值得注意的是,如果张量已经是连续的,那么调用 contiguous()方法不会产生任何操作,也不会影响性能。
三、Tensor操作
(1)tensor基本操作
tensor的操作都可以在PyTorch的官网中API查找即可,考虑到PyTorch官网可能比较卡
此外还有博主写的常见PyTorch API汇总:Pytorch常用API汇总
以及PyTorch中文文档:PyTorch中文文档
常见基本操作:
a = torch.tensor([[5,5,2],[1,2,3]])
b = torch.tensor([[5,5,2],[1,2,3]])
#操作:
#1.加法
(a + b)
(torch.add(a,b))
#2.减法
(a - b)
#3.除法
(a / b)
#4.乘法(列数必须统一),矩阵乘法就是线代里的乘法
a*b
#5.改变形状(与6、7、8都有关)
y = x.view(6)
z = x.view(-1, 2) # -1所指的维度可以根据其他维度的值推出来
print(x.size(), y.size(), z.size())
#torch.Size([2, 3]) torch.Size([6]) torch.Size([3, 2])
#6.共享内存空间
x += 1
print(x)
print(y) # y也加了1,与上面的5对应
#tensor([[2.0910, 2.5265, 2.3833],[1.4564, 1.3117, 1.5181]])
#tensor([2.0910, 2.5265, 2.3833, 1.4564, 1.3117, 1.5181])
#view()返回的新Tensor与源Tensor虽然可能有不同的size,但是是共享data的,
也即更改其中的一个,另外一个也会跟着改变。
#7.创造一个副本
x_cp=x.clone.view(15)
x-=1
print(x)
prinf(x_cp)
#tensor([[1.0910, 1.5265, 1.3833],[0.4564, 0.3117, 0.5181]])
#tensor([2.0910, 2.5265, 2.3833, 1.4564, 1.3117, 1.5181])
创建了一个副本,内容都是一样的,但不共享空间
#8.标量Tensor转换成一个Python number:
x = torch.randn(1)
print(x)
print(x.item())
#tensor([2.3466])
#2.3466382026672363
#9.矩阵乘法
a = torch.ones(2,2) * 3
b = torch.ones(2,2)
#三种表达方式
torch.mm(a,b) # 只适用于2维
torch.matmul(a,b)
troch.mul(a,b)
ab
#tensor([[6., 6.],[6., 6.]])
#10.unsqueeze 删除纬度
#torch.unsqueeze()这个函数主要是对数据维度进行扩充。
a = torch.tensor([1.2,2.3])
a
# tensor([1.2000, 2.3000])
a.shape
# torch.Size([2])
a.unsqueeze(0) # 0表示在张量最外层加一个中括号变成第一维,数字为几就代表在第几个空位添加维度,从0开始
# tensor([[1.2000, 2.3000]]) shape 是torch.Size([1, 2])
a.unsqueeze(-1) # 在第一个维度(中括号)的每个元素加中括号,-2对应的是0,-1对应的是1,以此类推。
# tensor([[1.2000],[2.3000]]) shape 是torch.Size([2, 1])
#11.squeeze 增加纬度
#torch.squeeze() 这个函数主要对数据的维度进行压缩,squeeze()函数只能压缩维度为1的矩阵,其他不能删除。
b = torch.rand(32)
b.squeeze().shape # 若不填写参数,则把维度shape是1的都给删除掉
# torch.Size([32])
b.squeeze(0).shape
# torch.Size([32, 1, 1])
这是一些最基本的操作,我们的tensor还需要进行一些数学运算,常见的数学操作:tensor常用操作
(2)tensor索引
如果我们需要得到一个张量中除第 1 点以外的所有点,使用范围索引表示法很容易实现,
该方法也适用于标准的 Python 列表:

为了达到我们的目标,我们可以对 PyTorch 张量使用相同的表示法。使用该方法的一个好处是就像在 NumPy 和其他 Python 科学库中一样,我们可以为张量的每个维度使用范围索引:

我们额外需要注意的是:索引出来的结果与原数据共享内存,也即修改一个,另一个会跟着修改。
除了常用的索引选择数据之外,PyTorch还提供了一些高级的选择函数:

(3)广播机制
我们看到如何对两个形状相同的Tensor做按元素运算。当对两个形状不同的Tensor按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个Tensor形状相同后再按元素运算。例如:
x = torch.arange(1, 3).view(1, 2)
print(x)
#tensor([[1, 2]])
y = torch.arange(1, 4).view(3, 1)
print(y)
#tensor([[1],
[2],
[3]])
print(x + y)
#tensor([[2, 3],
[3, 4],
[4, 5]])
四、tensor和numpy的互相转换
我们常用numpy()和from_numpy()将Tensor和NumPy中的数组相互转换。但是需要注意的一点是:
这两个函数所产生的的Tensor和NumPy中的数组共享相同的内存(所以他们之间的转换很快),改变其中一个时另一个也会改变!!!
Tensor`转NumPy:
a=torch.ones(5)
b=a.numpy()
print(a,b)
#tensor([1.,1.,1.,1.,1.]) [1. 1. 1. 1. 1.])
a+=1
print(a,b)
#tensor([2.,2.,2.,2.,2.]) [2. 2. 2. 2. 2.])
b+=1;
print(a,b)
#tensor([3.,3.,3.,3.,3.]) [3. 3. 3. 3. 3.])
NumPy数组转Tensor:
import numpy as np
a=torch.ones(5)
b=torch.from_numpy(a)
print(a,b)
#[1. 1. 1. 1. 1.] tensor([1.,1.,1.,1.,1.],dtype=torch.float64)
a+=1
print(a,b)
#[2. 2. 2. 2. 2.] tensor([2.,2.,2.,2.,2.],dtype=torch.float64)
b+=1;
print(a,b)
#[3. 3. 3. 3. 3.] tensor([3.,3.,3.,3.,3.],dtype=torch.float64)
#还有一个常用的方法就是直接用torch.tensor()将NumPy数组转换成Tensor
#需要注意的是该方法总是会进行数据拷贝,返回的Tensor和原来的数据不再共享内存。
PyTorch 中默认的数字类型是 32 位浮点数,而 NumPy 默认的数据类型是 64 位的。我们通常要使用 32 位浮点数,因此我们需要确保我们的张量转换后的数据类型是 torch.float。
五、将张量存储到 GPU
除了 dtype,PyTorch 张量还有设备(device)的概念,即张量数据在计算机上的位置。下面我们将通过指定构造函数的相应参数在 GPU 上创建一个张量:
points_gpu = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]], device='cuda')
我们可以使用 to()方法将在 CPU 上创建的张量复制到 GPU 上:
points_gpu = points.to(device='cuda')
如果我们的机器有多个 GPU,我们也可以通过从 0 开始传递一个整数来确定存储张量的 GPU,
例如:
points_gpu = points.to(device='cuda:0')
在此基础上,对张量执行的任何操作,例如将所有元素乘一个常数,都将在 GPU 上执行
以下是上述代码产生的操作:
● 张量 points 被复制到 GPU;
● 在 GPU 上分配一个新的张量,用来存储乘法运算的结果;
● 返回该 GPU 存储的张量的句柄。
因此,如果我们给结果增加一个常数:
points_gpu = points_gpu + 4
加法仍然在 GPU 上执行,没有信息流到 CPU,除非我们输出或访问得到的张量。为了将张量移回 CPU,我们需要向 to()方法提供一个 cpu 参数,例如:
points_cpu = points_gpu.to(device='cpu')
我们也可以使用简写的 cpu()和 cuda()方法来代替 to()方法实现相同的目标:
points_gpu = points.cuda() #GPU默认为0
points_gpu = points.cuda(0)
points_cpu = points_gpu.cpu()
总结:
# 以下代码只有在PyTorch GPU版本上才会执行
if torch.cuda.is_available():
device = torch.device("cuda") # GPU
y = torch.ones_like(x, device=device) # 直接创建一个在GPU上的Tensor
x = x.to(device) # 等价于 .to("cuda")
z = x + y
print(z)
print(z.to("cpu", torch.double)) # to()还可以同时更改数据类型
#tensor([[2, 3]], device='cuda:0’)
#tensor([[2., 3.]], dtype=torch.float64)
六、序列化张量
创建动态张量是很好的,但是如果里面的数据是有价值的,我们将希望将其保存到一个文件中,并在某个时间加载回来。毕竟,我们不希望每次运行程序时都要从头开始对模型进行训练。PyTorch 在内部使用 pickle 来序列化张量对象,并为存储添加专用的序列化代码。通过以下方法可以将张量 points 保存到 ourpoints.t 文件中:
torch.save(points, '../data/ourpoints.t') #文件夹名
作为替代方法,我们可以传递一个文件描述符来代替文件名:
with open('../data/ourpoints.t','wb') as f:
torch.save(points, f)
加载张量 points 同样可以通过一行代码来实现:
points = torch.load('../data/ourpoints.t')
或者通过以下代码:
with open('../data/p1ch3/ourpoints.t','rb') as f:
points = torch.load(f)
如果我们只是想用 PyTorch 加载张量的话,我们可以用这种方法快速地保存张量,但是文件格式本身是不具有互用性的,即我们无法用除 PyTorch 之外的软件读取张量。根据用例的不同,这可能是一种局限,也可能不是,但我们应该学习如何在需要的时候以一种可互用的方式来保存张量,接下来我们将了解如何做到这一点。
用 h5py 序列化到 HDF5
每个用例都是唯一的,但我们觉得在将 PyTorch 引入已经依赖于不同库的现有系统时,需要互操作地保存张量的情况会更常见。新项目可能不需要经常这样做。
但是在有需要的情况下,可以使用 HDF5 格式和 h5py 库。HDF5 是一种可移植的、被广泛支持的格式,用于将序列化的多维数组组织在一个嵌套的键值对字典中。
Python 通过 h5py 库支持 HDF5,该库接收和返回 NumPy 数组格式的数据。
我们可以使用以下命令安装 h5py:
conda install h5py
我们将张量 points 转换为一个 NumPy 数组(如前所述,这不会带来开销),同时将其传递给 create_dataset()函数:
import h5py
f = h5py.File('../data/ourpoints.hdf5', 'w')
dset = f.create_dataset('coords',data=points.numpy())
f.close()
这里的“coords”是保存到 HDF5 文件的一个键,我们可以有其他键,甚至可以嵌套键。HDF5中有趣的事情之一是,我们可以在磁盘上索引数据集,并只访问我们感兴趣的元素。假设我们只想加载数据集中的最后 2 个点:
f = h5py.File('../data/ourpoints.hdf5', 'r')
dset = f['coords']
last_points = dset[-2:]
当进行打开文件或需要数据集对象操作时,不会加载数据。更确切地说,在我们请求数据集中第 2 行到最后一行数据之前,数据一直保存在磁盘上。此时,h5py 访问这两列并返回一个类似 NumPy 数组的对象,该对象将所访问的区域封装在数据集中,其行为类似于 NumPy 数组,并与其具有相同的 API。
因此我们要将返回的对象传递给 torch.from_numpy()函数直接获得张量。注意,在这种情况下,数据会被复制到张量所在的存储中:
last_points = torch.from_numpy(dset[-2:])
f.close()
一旦完成数据加载,就关闭文件。关闭 HDF5 文件会使数据集失效,然后试图访问 dset 会抛出一个异常。只要我们按照以上代码的顺序进行操作,就不会有问题,就可以正常使用 last_points 张量了。
Torch Hub
在深度学习早期就已经发布了预训练模型,但是直到 PyTorch 1.0,还没有办法确保用户有一个统一的接口来获取它们。TorchVision 是一个规范接口的好例子,但是其他设计者,如 CycleGAN 和 NeuralTalk2 的设计者,他们选择了不同的设计。
PyTorch 在 1.0 版本中引入了 Torch Hub,它是一种机制,通过该机制作者可以在 GitHub 上发布模型,无论是否预先训练过权重,都可以通过 PyTorch 可以理解的接口将其公开发布。这使得从第三方加载预训练的模型就像加载 TorchVision 模型一样简单,PyTorch Hub 是一个简易 API 和工作流程. 为复现研究提供了基本构建模块, 包含预训练模型库.
简而言之就是调用别人训练好的网络架构,以及训练好的权重参数,并且PyTorch Hub的使用非常简单,无需下载模型,只需要敲torch. hub.load()就完成了
官网:Pytorch Hub

这里演示一下deeplabv3,我们找到deeplabv3,点击进入后得到该页面
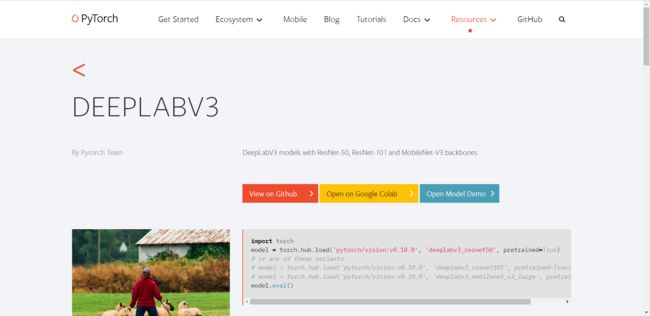
第一个按钮view onGithub点进去后是跳转到GitHub中查看源码:
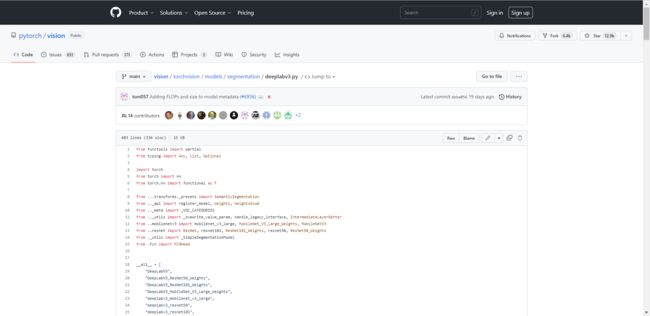
注意看路径是在torchvision下面的models:

第二个按钮Open on Google Colab,PyTorch Hub 还支持 Colab, 能与论文代码结合网站 Paper With Code 集成, 用于更广泛的研究.

里面是对该模型的介绍和解释,其中有一些代码可以直接运行,查看效果

第三个按钮open model demo是直接打开该模型的demo,查看具体情况。
实操
简介用法:
import torch
model = torch.hub.load('pytorch/vision', 'alexnet', pretrained=True)
#hub.load('GitHub仓库的名称和分支', '入口点函数(模块)的名称', 关键参数)
model.eval()
PyTorch Hub 的使用非常简单, 无需下载模型, 只需要敲torch.hun.load()就完成了
作为用户,PyTorch Hub 提供非常简单的工作流程,用户只需要按照以下三个步骤执行即可:(1)探索有价值的模型;(2)加载模型;(3)了解任何给定模型的可用方法。接下来,让我们分别看看每个步骤。
1、探索可用的接入点
用户可以使用 torch.hub.list() 列出仓库中所有可用的接入点。
torch.hub.list('pytorch/vision')
PyTorch Hub 还允许辅助接入点(除了预训练模型)。例如,bertTokenizer 可以用于 BERT 模型中的预处理,这使得用户的工作流程更加顺畅。
2、加载模型
我们已经知道了 Hub中可用的模型,那么用户便能够使用 torch.hub.load() 来加载模型接入点。该命令无需安装其他依赖包,此外,torch.hub.help() 提供了如何实例化模型的信息。
#首先我们需要导入hub
from torch import hub
model = torch.hub.load('pytorch/vision', 'deeplabv3_resnet101', pretrained=True)
#hub.load('GitHub仓库的名称和分支', '入口点函数(模块)的名称', 关键参数)
由于开发者会不断修复 bug,改进模型,因此 PyTorch Hub 也提供了便捷的方法,使得用户可以非常容易地获取最新的更新:
model = torch.hub.load(..., force_reload=True)
一些开发者会在其他分支上推送稳定的模型,而不是在 mater 分支上推送,这样能够保证代码的稳定性。例如,pytorch_GAN_zoo 在 hub 分支上提供稳定的版本。
model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', pretrained=True, useGPU=False)
3、探索加载的模型
从PyTorch Hub加载模型后,用户可以使用下面的工作流程找出模型的可用方法,并更好地了解运行该模型所需的参数。
dir(model) #dir() 用于查看模型的所有可用方法。
#['forward'
...
'to'
'state_dict',
]
help(model.forward) 用于展示模型运行所需的参数:
help(model.forward)
#Help on method forward in module pytorch_pretrained_bert.modeling:
forward(input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None)
...