基于C语言的自动机dot画图脚本设计
基于C语言的自动机dot画图脚本设计
正文开始@Assassin
文章目录
- 基于C语言的自动机dot画图脚本设计
-
- 1. 项目设计报告 -- 基于C语言的自动机dot画图脚本设计
-
- 1.1 Graphviz 画图工具和 dot 语言:
- 1.2 基本画图类别:
- 1.3 图的基本元素:
- 1.4 图的属性:
- 1.5 节点形状:
- 1.6 节点和边的位置:
- 1.7 Graphviz及dot环境的安装:
- 1.8 sxiv终端图片查看器:
- 1.9 dot语言编译指令:
- 1.10 确定的有限状态自动机 (Deterministic Finite Automaton)
- 1.11 非确定的有限状态自动机 (Nondeterministic Finite Automaton)
- 1.12 带有ε的非确定的有限状态自动机 (ε-NFA )
- 1.13 下推自动机(PushDown Automaton)
- 1.14 图灵机(Turing Machine)
- 1.15 项目源代码总体分析:
- 1.16 Makefile编写:
- 1.17 编写静态库:
- 2. 项目产品工具
- 3. 项目使用说明
1. 项目设计报告 – 基于C语言的自动机dot画图脚本设计
项目介绍:
项目运行环境:Linux-Ubuntu20.04 / Centos7.9
文本格式:UTF-8
编译器:gcc/g++ python3 dot
Author:W. Y
项目基本功能:
在文件中给出指定格式的五元组 / 七元组,运行可执行文件自动识别自动机类型,生成对应的dot脚本,并通过dot脚本自动画出相应的状态转移图
1.1 Graphviz 画图工具和 dot 语言:
Graphviz 是一个由 AT&T 实验室启动的开源工具包,用于绘制 dot 语言脚本描述的图形。类似微软的 visio,但是和 visio 也有很大的不同,他是使用一种名为 dot 的语言进行绘图,对于绘制复杂的流程图,类图等非常好用。 这种设计使得用户更关 注于逻辑关系,实现 “所思即所得”。Graphviz 的自动布局功能,无需人为干预就可以做 到 “最小化连线交叉”。 关于 dot 画图的一个非常好的文章见 点我跳转!Drawing graphs with dot
1.2 基本画图类别:
dot 可以生成 GIF,PNG,SVG,PDF 和 PostScript 格式的图片。dot 语言画图的类别可以分成以下两类:
digraph有向图graph无向图
1.3 图的基本元素:
每种图中包含以下常见要素:
node节点edge边subgraph子图attr属性
digraph basicGraph {
main -> parse -> execute;
main -> init;
main -> cleanup;
execute -> make_string;
execute -> printf
init -> make_string;
main -> printf;
execute -> compare;
}
- dot 语言中每个变量表示一个节点
->表示连接边- 使用 dot 命令编译生成 PNG 图片,示例如下:
dot -Tpng fig.dot -o fig.png


1.4 图的属性:
在绘制图的时候一般需要根据需求来设置节点和边的属性,如下例子中:
digraph graphAttrs {
size ="4,4";
main [shape=box]; /* this is a comment */
main -> parse [weight=8];
parse -> execute;
main -> init [style=dotted];
main -> cleanup;
execute -> { make_string; printf}
init -> make_string;
edge [color=red]; // so is this
main -> printf [style=bold,label="100 times"];
make_string [label="make a\nstring"];
node [shape=box,style=filled,color=".7 .3 1.0"];
execute -> compare;
}
size设置图片大小为 4,4(英尺)- 节点和边的属性写在方括号里
shape=box设置节点形状为方框- 花括号表示一个节点连接多个节点
execute -> { make_string; printf}等同于execute -> make_string; execute -> printf; - 节点和边的文字可以使用
label属性来设置
1.5 节点形状:
节点属性默认设置为 shape=ellipse, width=.75, height=.5 并且使用节点的名字作 为其 label 。节点的形状见 shapes 。

- 节点的形状分为两类
polygon-based和record-based - 除了
record和Mrecord属于record-based以外,其它都是polygon-based polygon-based一般直接作为形状record-based可以用于递归定义
1.6 节点和边的位置:
节点和边的分别通过 rankdir 属性控制
LRleft-to-rightTBtop-to-bottomBTbottom-to-topRLright-to-left
对于有时间线的图,子图的 rank 可以设置为:
same子图中的所有节点属于同一个级别min最小级别source使得子图中的级别相同,并且严格小于其他节点max最大级别sink
1.7 Graphviz及dot环境的安装:
-
Centos:
sudo yum install -y graphviz
-
Ubuntu:
sudo apt install -y graphviz
1.8 sxiv终端图片查看器:
-
Centos:(由于centos yum没有sxiv安装包,源码安装这里浪费的时间有点多,详细步骤如下
1.下载源码编译 2.提示config.h不存在 需要make config.h 3.sxiv.h:27:10: fatal error: Imlib2.h: No such file or directory 27 | #include| ^~~~~~~~~~ compilation terminated. make: *** [autoreload_inotify.o] Error 1 需要sudo yum install imlib2-devel-1.4.5 4.image.c:31:10: fatal error: libexif/exif-data.h: No such file or directory 31 | #include | ^~~~~~~~~~~~~~~~~~~~~ compilation terminated. make: *** [image.o] Error 1 需要sudo yum install libexif-devel 5.image.c:35:10: fatal error: gif_lib.h: No such file or directory 35 | #include | ^~~~~~~~~~~ compilation terminated. make: *** [image.o] Error 1 需要sudo yum install giflib-devel 6.sudo make 7.sudo make PREFIX="/your/dir" install(make install 默认是安装到/usr/local/bin) 8.cp to PATH 9.sxiv: Error opening X display 需要sudo yum install xorg-x11-xauth xorg-x11-fonts-* xorg-x11-font-utils xorg-x11-fonts-Type1 xterm 需要sudo yum install -y xorg-x11-xauth xorg-x11-utils xorg-x11-fonts-* (ubuntu :sudo apt-get install xbase-clients) 10.安装x manager处理x11转发请求 xmanager 
-
Ubuntu:ubuntu apt可直接安装sxiv
sudo apt install -y sxiv
1.9 dot语言编译指令:
dot -Tpng example.dot -o example.png
1.10 确定的有限状态自动机 (Deterministic Finite Automaton)
在计算理论中,确定有限状态自动机或确定有限自动机(英语:deterministic finite automaton, DFA)是一个能实现状态转移的自动机。对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符,它都能根据事先给定的转移函数转移到下一个状态(这个状态可以是先前那个状态)。

状态S1表示在输入的字符串中有偶数个0,而S2表示有奇数个0。接收状态为S1,即该自动机可以识别的语言是有偶数个0的字符串

1.11 非确定的有限状态自动机 (Nondeterministic Finite Automaton)
在计算理论中,非确定有限状态自动机(NFA)是对每个状态和输入符号对可以有多个可能的下一个状态的有限状态自动机。这区别于确定的有限状态自动机(DFA),它的下一个可能状态是唯一确定的。在形式理论中可以证明它们是等价的;就是说,对于任何给定NFA,都可以构造一个等价的DFA,反之亦然。
-
NFA同DFA一样,消耗输入符号的字符串。对每个输入符号它变换到一个新状态直到所有输入符号到被耗尽。
-
不像DFA,非确定意味着对于任何输入符号,它的下一个状态不是唯一确定的,可以是多个可能状态中的任何一个。因此在形式定义中,一般都谈论状态幂集的子集:转移函数不提供一个单一状态,而是提供所有可能状态的某个子集。

可以很清晰地看出,NFA相较于DFA而言,五元组只有转移函数δ上的差别,DFA读入一个字符会跳转到一个确定的状态Q,而NFA存在读取一个字符跳转到多个状态的情况(幂集 2Q),也就是说输入一个符号时,下一个跳转的状态是Q的子集。

1.12 带有ε的非确定的有限状态自动机 (ε-NFA )
一种扩展的NFA是NFA-λ(也叫做NFA-ε或有ε-NFA),它允许到新状态的变换不消耗任何输入符号。例如,如果它处于状态1,下一个输入符号是a,它可以移动到状态2而不消耗任何输入符号,因此就有了歧义:在消耗字母a之前系统是处于状态1还是状态2呢?由于这种歧义性,可以更加方便的谈论系统可以处在的可能状态的集合。因此在消耗字母a之前,NFA-ε可以处于集合{1,2}内的状态中的任何一个。等价的说,可以想象这个NFA同时处于状态1和状态2:这给出了对幂集构造的非正式提示:等价于这个NFA的DFA被定义为此时处于状态q={1,2}中。不消耗输入符号的到新状态的变换叫做λ转移或ε转移。它们通常标记着希腊字母λ或ε。
-
简单来说, ε -NFA 就是在NFA的基础上可以进行空转移,也就是说状态之间可以不经过输入也可以完成状态切换。DFA不具备此项能力。
-
ε –NFA的五元组跟NFA的唯一不同就是转移函数,可以读取的字符是字母表与ε的并集(Σ∪ε)
-
可以很清晰地看出ε –NFA的转移值比NFA多了一个ε

下面的例子展示一个ε-NFA M,带有二进制字母表,它确定输入是否包含偶数个0或偶数个1。设M =(Q, Σ, T, s0, F)这里的
-
Σ = {0, 1}
-
Q = {s0, s1, s2, s3, s4}
-
E({s0}) = { s0, s1, s3 }
-
F = {s1, s3}
-
转移函数T定义自下列[状态转移表:
0 1 ε S0 {} {} {S1, S3} S1 {S2} {S1} {} S2 {S1} {S2} {} S3 {S3} {S4} {} S4 {S4} {S3} {}
M可以被看作两个DFA的并集:一个有状态{S2, S1},而另一个有状态{S3, S4}。

1.13 下推自动机(PushDown Automaton)
在自动机理论中,下推自动机(Pushdown automaton)是使用了包含数据的栈的有限自动机。下推自动机比有限状态自动机复杂:除了有限状态组成部分外,还包括一个长度不受限制的栈不但包括有限状态的变迁,还包括一个栈的出栈或入栈过程。下推自动机可以形象的理解为,借由加上读取一个容量无限栈的能力,扩充一个能做ε转移的非确定有限状态自动机。下推自动机存在“确定”与“非确定”两种形式,两者并不等价。(对有限状态自动机两者是等价的)
每一个下推自动机都接受一个形式语言。被“非确定下推自动机”接受的语言是上下文无关语言。如果我们把下推自动机扩展,允许一个有限状态自动机存取两个栈,我们得到一个能力更强的自动机,这个自动机与图灵机等价。
下推自动机PDA:
- 比ε-NFA多了一个栈
- 栈:后进先出,只用栈顶,长度无限
- pop:仅仅弹出栈顶的一个符号
- push:可压入一串符号

输入字符串 = ε:
设置 r0 = q1,r1 = q1,δ(r0,ε,ε) --> (q1,ε)。因为 q1 是接受状态,ε被接受。

1.14 图灵机(Turing Machine)
图灵的基本思想是用机器来模拟人们用纸笔进行数学运算的过程,他把这样的过程看作下列两种简单的动作:
- 在纸上写上或擦除某个符号;把注意力从纸的一处移动到另一处。
- 而在每个阶段,人要决定下一步的动作,依赖于(a)此人当前所关注的纸上某个位置的符号和(b)此人当前思维的状态。
为了模拟人的这种运算过程,图灵构造出一台假想的机器,该机器由以下几个部分组成:
-
一条无限长的纸带TAPE。纸带被划分为一个接一个的小格子,每个格子上包含一个来自有限字母表的符号。纸带上的格子从左到右依次被编号为0,1,2…,纸带的右端可以无限伸展。
-
一个读写头HEAD。它可以在纸带上左右移动,能读出当前所指的格子上的符号,并能改变它。
-
一套控制规则TABLE
。它根据当前机器所处的状态以及当前读写头所指的格子上的符号来确定读写头下一步的动作,并改变状态寄存器的值,令机器进入一个新的状态,按照以下顺序告知图灵机命令:
- 写入(替换)或擦除当前符号;
- 移动 HEAD,
L向左,R向右或者N不移动; - 保持当前状态或者转到另一状态。
-
一个状态寄存器。它用来保存图灵机当前所处的状态。图灵机的所有可能状态的数目是有限的,并且有一个特殊的状态,称为停机状态。参见停机问题。

图灵机的正式定义:

第一行程序0,0 -> 0,0R意思就是如果机器读到0,就将其变成0,状态变为0,读写头向右移动一格。R就是向右移动一格,L就是向左移一格,E是错误,S是停机。xx,y -> aa,b中xx是当前状态,y是当前格子的值,aa是程序下一步的状态,b是当前格的修改值。

1.15 项目源代码总体分析:
本项目主要采用C语言进行编写,采用多文件编写的方式,开发环境为linux ubuntu / centos,使用到的编辑环境有vscode,wsl,vim。
编译环境为gcc/ g++,dot,python。
项目主体为8个C文件:

下面简要摘取一下各C文件的关键代码进行分析,头文件这里不再赘言:
top_call.c
#include "fa.h"
#include "pda.h"
#include "turing.h"
/*
顶层模块,用于调用三个子程序
备注,当且仅当三个子程序存在,
且三个子程序命名为turing,pda,fa的时候才能正常使用
*/
int main(int argc, char *argv[])
{
//在使用前对每个文件进行检查,判断文件中的自动机类型
//顶层模块不支持获取控制台输入
if (argc < 2)
{
printf("You must input command line parameters as filename\n");
return 1;
}
//使用手册
if (strcmp(argv[1], "--help") == 0)
{
help_info();
return 2;
}
//char s[200] = {0};
//如果输入了正确的控制台参数作为要获取自动机的文件名
for (int i = 1; i < argc; i++)
{
// 根据文件种类的不同选择不同的程序
Kind fileKind = get_fileKind(argv[i]);
switch (fileKind)
{
case FA_FILE:
fa_getPng(argv[i]);
break;
case PDA_FILE:
pda_getPng(argv[i]);
break;
default:
tm_getPng(argv[i]);
break;
}
}
return 0;
}
top_call.c为顶层调用文件,负责统筹调用其他各文件。同时添加了–help使用手册查询功能。
判断调用文件的主要逻辑是:先运行起来程序,使其被加载到内存成为一个进程,后面跟上需要识别的五元组/ 七元组txt文件。
首先进行for loop,使用argv[i]获取输入的txt文件字符串,进而调用get_fileKind()函数进行自动机类型的识别,进而打印出对应自动机的png文件。

generic.c
#include "generic.h"
//获取文件的种类
Kind get_fileKind(char *fileName)
{
FILE *file = fopen(fileName, "r");
if (file == NULL)
{
perror("get_fileKind");
exit(-1);
}
char term[MAX_STRLEN];
int i = 0;
do
{
my_fscanf(file, "%s", term);
if (strcmp(term, "[") == 0)
break;
i++;
} while (1);
//经过循环后i为读到[(转移向量开始输入标记)之前读取的行数
//如果读取到的是fa,状态转移函数位于5-1=4行
if (i == 4)
{
fclose(file);
return FA_FILE;
}
//否则读取到的是pda或者turing machine
//读取一个状态转移向量来判断是图灵机还是下推自动机
my_fscanf(file, "%s", term);
int len = strlen(term);
//如果读取到的是图灵机
if ((term[len - 1] == 'R' || term[len - 1] == 'L') && term[len - 2] == ',')
{
fclose(file);
return TM_FILE;
}
//如果不是图灵机又不是有穷自动机则是下推自动机
fclose(file);
return PDA_FILE;
}
//如果该字符串s以//开头,则说明它和它后面同行字符都是注释,则返回1,否则返回0
int is_comment(char *s)
{
if (strlen(s) >= 2 && s[0] == '/' && s[1] == '/')
{
return 1;
}
return 0;
}
//从文件输入流读取一行字符串(当输入参数为std时为从控制台读取一行字符串,可包含空格)
void str_readline(FILE *path)
{
while (!feof(path))
{
char add = fgetc(path);
if (add == EOF)
break;
if (add == '\n')
break;
if (add == '\r')
break;
}
}
//带忽略注释地读取一个字符串
void my_fscanf(FILE *file, char *mode, char *target)
{
while (1)
{
fscanf(file, mode, target);
if (is_comment(target))
str_readline(file);
else
break;
}
}
// help_info
void help_info()
{
printf("*****************************\n");
printf("1. finite automaton\n");
printf("2. pushdown automaton\n");
printf("3. turing machine\n");
printf("*****************************\n");
//选择展示自动机的格式
int choice = 0;
scanf("%d", &choice);
switch (choice) {
case 1:
printf("******************************FA Tutorail****************************\n");
printf("A,B,C,D //第一行是状态集合\n");
printf("1,2,3 //第二行是字母表,用,隔开\n");
printf("A //第三行是开始状态,只能是一个字符\n");
printf("C,D //第四行是终结状态集合,能够输入多个,一般来说不能和开始状态重复\n");
printf("[ A,1,B A,3,D B,2,C B,3,D ]\n");
printf(" //第五行开始是状态转移输入,用[开始,空一个再开始输入状态转移\n");
printf(" //每个状态转移方程的输入格式如右,开始状态,遇到字符,跳转状态\n");
printf(" //每个输入的状态之间空一格\n");
printf(" //完成输入状态之后,需要空一格,输入]标记结束输入状态\n");
printf("*********************************************************************\n");
break;
case 2:
printf("******************************PDA Tutorail***************************\n");
printf("A,B,C,D //第一行是状态集合\n");
printf("1,2,3 //第二行是字母表,用,隔开\n");
printf("F,Z,M,N //第三行是栈符合集\n");
printf("A //第四行是开始状态,只能是一个字符\n");
printf("C,D //第五行是终结状态集合\n");
printf("Z //第六行是初始栈底符号\n");
printf("[ A>B:2,Z/1Z B>C:3,N/e A>D:2,1/M1 ]\n");
printf(" //状态转移向量输入同样是以[开头,空一格开始\n");
printf(" //以空一格加]结束\n");
printf(" //每个状态转移向量以一个空格隔开\n");
printf("*********************************************************************\n");
break;
case 3:
printf("******************************TM Tutorail****************************\n");
printf("A,B,C,D //第一行是状态集合\n");
printf("1,2,3 //第二行是字母表,用,隔开\n");
printf("M,Q,Z //第三行是带符号集合,它总是包含字母表\n");
printf("e //第四行是空白带符号定义\n");
printf("A //第五行是开始状态\n");
printf("C,D //第六行是终止带符号\n");
printf("[ A>B:M/Q,L B>C:Q/Z,R ]\n");
printf(" //第七行状态转移向量,中间用空格隔开\n");
printf("*********************************************************************\n");
break;
default:
printf("Sorry, your input is incorrect, the program exits\n");
break;
}
}
该文件主要是对一些分散的功能做一个简单的封装,也是其他文件中常被用到的一些功能。例如对文件进行容错性处理,识别并跳过字符串,跳过空行等。主要想法是增加程序的鲁棒性。

my_fscanf()函数主要是is_comment()以及str_readline()进行一个封装,循环读取文件中的数据,并将读取到的每行数据写到target指针指向的空间中。当读取到 //时,也就是读到了注释时,调用str_readline()进行该行的忽略,直到读取到一个既不是空行也不是注释的行才跳出break。

fa.c
#include "fa.h"
//从文件中读取一个自动机
FA fa_fget(FILE *file)
{
FA out = {0};
char str[300] = {0};
//读取状态集合
my_fscanf(file, "%s", str);
int len = strlen(str);
out.numOfConditions = len / 2 + 1;
char term[300];
for (int i = 0; i < out.numOfConditions; i++)
{
sscanf(str, "%c,%s", &out.conditions[i], term);
strcpy(str, term);
}
//读取字母表
my_fscanf(file, "%s", str);
len = strlen(str);
out.numOfLetters = len / 2 + 1;
for (int i = 0; i < out.numOfLetters; i++)
{
sscanf(str, "%c,%s", &out.letters[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//读取开始状态
my_fscanf(file, "%s", str);
char st;
sscanf(str, "%c", &st);
//读取终止状态或者接受状态
char finals[300];
my_fscanf(file, "%s", str);
len = strlen(str);
int lenOfFinals = len / 2 + 1;
for (int i = 0; i < lenOfFinals; i++)
{
sscanf(str, "%c,%s", &finals[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//根据读到的开始状态或者接受状态对状态种类进行标记
for (int i = 0; i < out.numOfConditions; i++)
{
if (out.conditions[i] == st)
{
out.conditionKinds[i] = 1;
continue;
}
else
{
for (int j = 0; j < lenOfFinals; j++)
{
if (out.conditions[i] == finals[j])
{
out.conditionKinds[i] = 2;
break;
}
}
}
}
//读取状态转移,先读取到开始符号为止
do
{
my_fscanf(file, "%s", str);
if (strcmp(str, "[") == 0)
break;
} while (1);
//读取状态转移向量
out.numOfMoves = 0;
do
{
my_fscanf(file, "%s", str);
if (strcmp(str, "]") == 0)
break;
sscanf(str, "%c,%c,%c", &out.move[out.numOfMoves][0], &out.move[out.numOfMoves][1], &out.move[out.numOfMoves][2]);
out.numOfMoves++;
} while (1);
return out;
}
//把自动机以dot脚本的形式写入文件
void fa_fputDot(FILE *file, FA fa)
{
fprintf(file, "digraph FiniteAutomaton{\n");
fprintf(file, "rankdir=LR\n");
//随着节点数量调整画布大小
int size = fa.numOfConditions * 2;
fprintf(file, "size=%d", size);
//打印节点
for (int i = 0; i < fa.numOfConditions; i++)
{
//如果是普通状态
if (fa.conditionKinds[i] == 0)
{
fprintf(file, "\n%c[shape=circle]", fa.conditions[i]);
}
//如果是终止状态或者接受状态
else if (fa.conditionKinds[i] == 2)
{
fprintf(file, "\n%c[shape=doublecircle]", fa.conditions[i]);
}
//如果是开始状态
else if (fa.conditionKinds[i] == 1)
{
fprintf(file, "\n%c[shape=circle]", fa.conditions[i]);
fprintf(file, "\nstart[label=\"\",shape=none]");
fprintf(file, "\nstart->%c[label=\"start\"]", fa.conditions[i]);
}
}
//打印线
for (int i = 0; i < fa.numOfMoves; i++)
{
fprintf(file, "\n%c->%c[label=%c]", fa.move[i][0], fa.move[i][2], fa.move[i][1]);
}
fprintf(file, "\n}");
}
//读取s指定路径的文件,并输出相应的自动机图表
void fa_getPng(char *s)
{
printf("%s\'s png generated!\n", s);
char termName[500];
char base[100] = {0};
strncpy(base, s, strlen(s) - 4);
FILE *file = fopen(s, "r");
if (file == NULL)
{
perror("fa_getPng");
exit(-1);
}
int i = 0;
while (!feof(file))
{
FA fa = fa_fget(file);
//生成对应dot文档
//先获取dot文档文件名
sprintf(termName, "%s_%d.dot", base, i);
FILE *fp = fopen(termName, "w");
if (fp == NULL)
{
perror("fa_getPng");
exit(-1);
}
fa_fputDot(fp, fa);
fclose(fp);
//生成控制生成图片的脚本编译命令
char cmd[300] = {0};
sprintf(cmd, "dot -Tpng %s_%d.dot -o %s_%d.png", base, i, base, i);
system(cmd);
i++;
}
fclose(file);
}
//在控制台上打印自动机的信息以检测正误
void fa_show(FA fa)
{
printf("\nconditions:");
for (int i = 0; i < fa.numOfConditions - 1; i++)
{
printf("%c,", fa.conditions[i]);
}
if (fa.numOfConditions >= 1)
printf("%c", fa.conditions[fa.numOfConditions - 1]);
printf("\nletters:");
for (int i = 0; i < fa.numOfLetters - 1; i++)
{
printf("%c,", fa.letters[i]);
}
if (fa.numOfLetters >= 1)
printf("%c", fa.letters[fa.numOfLetters - 1]);
printf("\nstart condition:");
for (int i = 0; i < fa.numOfConditions; i++)
{
if (fa.conditionKinds[i] == 1)
{
printf("%c", fa.conditions[i]);
break;
}
}
printf("\nfinal conditions:");
int first = 0;
for (int i = 0; i < fa.numOfConditions; i++)
{
if (fa.conditionKinds[i] == 2)
{
if (first == 0)
{
first = 1;
printf("%c", fa.conditions[i]);
}
else
printf(",%c", fa.conditions[i]);
}
}
printf("\nmove vectors:"); //状态转移向量
for (int i = 0; i < fa.numOfMoves; i++)
{
printf("\n%c,%c,%c", fa.move[i][0], fa.move[i][1], fa.move[i][2]);
}
}
fa_fet()函数主要是从txt文件中对DFA,NFA,ε-NFA进行五元组的获取,该五元组文件需事先定义好,且有固定的格式。
五元组的txt文件格式如下:
//DFA
A,B,C,D
1,2,3
A
C,D
[ A,1,B A,2,B A,3,D B,2,C B,3,D ]
//NFA
A,B,C,D,E
1,2,3
A
C
[ A,1,B A,1,C A,3,D B,2,C B,3,D D,2,E E,1,C ]
//NFA-e
A,B,C,D,E
1,2,3,e
A
C
[ A,1,B A,1,C A,3,D B,2,C B,3,D D,2,E E,1,C E,e,C ]
简单解释一下,文件中可以包含多个自动机五元组,且可以是DFA,NFA,ε-NFA三种的任意一种,因为这三种自动机的逻辑基本类似,都属于有穷自动机。
每一行数据的具体含义:
- 有限状态符号集
- 字母表(能接受语言的字符串集)
- 开始状态
- 终结状态或者接受状态
- 状态转移函数
A,B,C,D //第一行是状态集合
1,2,3 //第二行是符号集合,用,隔开
A //第三行是开始状态,只能是一个字符
C,D //第四行是终结状态集合,能够输入多个,不过一般来说不能和开始状态重复
[ A,1,B A,3,D B,2,C B,3,D ]
//第五行开始是状态转移输入,用[开始,空一个再开始输入状态转移,
//每个状态转移方程的输入格式如右,开始状态,遇到字符,跳转状态
//每个输入的状态之间空一格
//完成输入状态之后,需要空一格,输入]标记结束输入状态
ps:状态转移输入允许换行,允许注释
//文件中允许出现注释,能够识别注释并处理
//可以在任何地方加入 //注释,注释后面的语句会被忽略
//上图的转态转移允许输入格式如下
[ A,1,B A,3,D
B,2,C B,3,D ]
以fa_fget读取前两行为例,首先定义一个自动机结构体来存放读取的自动机,调用my_scanf()函数将注释跟空行都跳过,知道读取到第一行数据存放到str中,strlen()得到读取行的长度,得到除逗号外的有效字符的个数,遍历式地将各个状态存放在自动机结构体变量的对应位置,sscanf()函数 遇到空格或者回车停止,所以需要将后续字符串拷贝到term中循环读取,直到读取结束。 读取字母表跟后续行的逻辑类似,这里不再展开。

fa_fputDot()函数是对已经读取到的自动机进行以dot语言格式的输出到对应的dot文件中,提前指定了rankdir与size,逻辑上状态分为三种,普通状态(跳转的中间状态),开始状态,接受状态。各个状态所给的圆圈的格式不同,模拟了实际的自动机状态转移图。

fa_getPng()函数是将生成的dot文件进行编译,生成对应的png文件,该函数作用方式为循环读取,直到文件结束,这也是实现一个文件中多个自动机的基础,最重要的命令是 sprintf(cmd, "dot -Tpng %s_%d.dot -o %s_%d.png", base, i, base, i); system(cmd);
此语句为dot语言的编译语句。

pda.c
#include "pda.h"
/* pda相关函数定义*/
void pda_getPng(char *s)
{
printf("%s\'s png generated!\n", s);
char termName[500];
char base[100] = {0};
strncpy(base, s, strlen(s) - 4);
FILE *file = fopen(s, "r");
if (file == NULL)
{
perror("pda_getPng");
exit(-1);
}
int i = 0;
while (!feof(file))
{
PDA pda = pda_fget(file);
//生成对应dot文档
//先获取dot文档文件名
sprintf(termName, "%s_%d.dot", base, i);
FILE *fp = fopen(termName, "w");
if (fp == NULL)
{
perror("pda_getPng");
exit(-1);
}
pda_fputDot(fp, pda);
fclose(fp);
//生成控制生成图片的脚本编译命令
char cmd[300] = {0};
sprintf(cmd, "dot -Tpng %s_%d.dot -o %s_%d.png", base, i, base, i);
system(cmd);
i++;
}
fclose(file);
}
//初始化转移条件表
void pda_initMoveSE(PDAP pda)
{
for (int i = 0; i < MAX_SIZE; i++)
{
for (int j = 0; j < MAX_SIZE; j++)
{
pda->moveSE[i][j] = -1;
}
}
}
//从文件中读取一个自动机
PDA pda_fget(FILE *file)
{
PDA out = {0};
char str[300] = {0};
// TODO 初始化moveCases
pda_initMoveSE(&out);
//读取状态集合
my_fscanf(file, "%s", str);
int len = strlen(str);
out.numOfConditions = len / 2 + 1;
char term[300];
for (int i = 0; i < out.numOfConditions; i++)
{
sscanf(str, "%c,%s", &out.conditions[i], term);
strcpy(str, term);
}
//读取字母表
my_fscanf(file, "%s", str);
len = strlen(str);
out.numOfLetters = len / 2 + 1;
for (int i = 0; i < out.numOfLetters; i++)
{
sscanf(str, "%c,%s", &out.letters[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//读取栈符号集合
my_fscanf(file, "%s", str);
len = strlen(str);
out.numOfStacks = len / 2 + 1;
for (int i = 0; i < out.numOfStacks; i++)
{
sscanf(str, "%c,%s", &out.stacks[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//读取开始状态
char st;
my_fscanf(file, "%s", str);
sscanf(str, "%c", &st);
//读取终止状态或者接受状态
char finals[300];
my_fscanf(file, "%s", str);
len = strlen(str);
int lenOfFinals = len / 2 + 1;
for (int i = 0; i < lenOfFinals; i++)
{
sscanf(str, "%c,%s", &finals[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//根据读到的开始状态或者接受状态对状态种类进行标记
for (int i = 0; i < out.numOfConditions; i++)
{
if (out.conditions[i] == st)
{
out.conditionKinds[i] = 1;
continue;
}
else
{
for (int j = 0; j < lenOfFinals; j++)
{
if (out.conditions[i] == finals[j])
{
out.conditionKinds[i] = 2;
break;
}
}
}
}
// 读取初始栈底符号
my_fscanf(file, "%s", str);
out.firstStack = str[0];
// 读取状态转移,先读取到开始符号为止
do
{
my_fscanf(file, "%s", str);
if (strcmp(str, "[") == 0)
break;
} while (1);
//读取状态转移向量
out.numOfMoves = 0;
do
{
my_fscanf(file, "%s", str);
if (strcmp(str, "]") == 0)
break;
char curMoveCase[100]; //跳转条件
char moveS; //跳转开始状态
char moveE; //跳转结束状态
sscanf(str, "%c>%c:%s", &moveS, &moveE, curMoveCase);
//先判断这个方向和首位的跳转是否已经存在
//如果该线条不存在,添加该线条
if (out.moveSE[(int)moveS][(int)moveE] == -1)
{
out.move[out.numOfMoves][0] = moveS;
out.move[out.numOfMoves][1] = moveE;
out.moveSE[(int)moveS][(int)moveE] = out.numOfMoves;
//当前线条的下标
int indexOfCurMove = out.numOfMoves;
//当前线条的条件数量(新增条件的下标)
int indexOfCurCon = out.numOfMoveCases[indexOfCurMove];
//传递读取到的条件到该位置
strcpy(out.moveCases[indexOfCurMove][indexOfCurCon], curMoveCase);
//更新条件下标和线条下标
out.numOfMoveCases[out.numOfMoves]++;
out.numOfMoves++;
}
//如果该线条存在,往对应条件中添加
else
{
//获取当前线条的下标
int indexOfCurMove = out.moveSE[(int)moveS][(int)moveE];
//当前线条的条件数量(新增条件的下标)
int indexOfCurCon = out.numOfMoveCases[indexOfCurMove];
//传递读取到的条件到该位置
strcpy(out.moveCases[indexOfCurMove][indexOfCurCon], curMoveCase);
//更新条件下标
out.numOfMoveCases[indexOfCurMove]++;
}
} while (1);
return out;
}
//把自动机以dot脚本的形式写入文件
void pda_fputDot(FILE *file, PDA pda)
{
fprintf(file, "digraph PushdownAutomaton{\n");
//设置节点排布方式为从左到右
fprintf(file, "rankdir=LR\n");
//根据节点数量调节文件大小
int size = (pda.numOfConditions + pda.numOfLetters + pda.numOfStacks) * 2;
fprintf(file, "size=%d\n", size);
//打印节点
for (int i = 0; i < pda.numOfConditions; i++)
{
//如果是普通状态
if (pda.conditionKinds[i] == 0)
{
fprintf(file, "\n%c[shape=circle]", pda.conditions[i]);
}
//如果是终止状态或者接受状态
else if (pda.conditionKinds[i] == 2)
{
fprintf(file, "\n%c[shape=doublecircle]", pda.conditions[i]);
}
//如果是开始状态
else if (pda.conditionKinds[i] == 1)
{
fprintf(file, "\n%c[shape=circle]", pda.conditions[i]);
fprintf(file, "\nstart[label=\"\",shape=none]");
fprintf(file, "\nstart->%c[label=\"start\"]", pda.conditions[i]);
}
}
//打印跳转
for (int i = 0; i < pda.numOfMoves; i++)
{
char moveS = pda.move[i][0];
char moveE = pda.move[i][1];
int numOfCurCases = pda.numOfMoveCases[i];
//加上字符串的拼接
char curMoveCase[500] = {0};
pda_casescat(curMoveCase, pda.moveCases[i], numOfCurCases);
//以拼接好的条件写入字符串
fprintf(file, "\n%c->%c[label=\"%s\"]", moveS, moveE, curMoveCase);
}
fprintf(file, "\n}");
}
//按照一定的格式拼接条件字符串
void pda_casescat(char *dir, char sarr[MAX_CON_SIZE][MAX_STRLEN], int size)
{
if (size < 1)
{
printf("wrong input in pda_casescat");
return; //保证程序稳健性的意外处理
}
int len = 0;
for (int i = 0; i < size - 1; i++)
{
int j = 0;
while (sarr[i][j] != '\0')
{
dir[len++] = sarr[i][j];
j++;
}
dir[len++] = '\\';
dir[len++] = 'n';
}
int j = 0;
while (sarr[size - 1][j] != '\0')
{
dir[len++] = sarr[size - 1][j];
j++;
}
dir[len] = '\0';
}
pda_fget()函数主要是从txt文件中对pda进行七元组的获取,该七元组文件需事先定义好,且有固定的格式。
七元组的txt文件格式如下:
A,B,C,D
1,2,3
F,Z,M,N
A
C,D
Z
[
A>B:2,Z/1Z
B>C:3,N/e
A>D:2,1/M1 ]
简单说明一下,该txt文件中只能是pda的七元组,为了与有穷自动机区分开来,但是数量依旧可以多个。
每一行数据的具体含义:
- 状态集合
- 字母表
- 栈符号集
- 开始状态
- 终止状态或者接受状态集合
- 初始栈符号集合
- 状态转移向量
A,B,C,D //第一行是状态集合
1,2,3 //第二行是字母表
F,Z,M,N //第三行是栈符合集
A //第四行是开始状态,只能是一个字符
C,D //第五行是终结状态集合
Z //初始栈底符号
[ A>B:2,Z/1Z B>C:3,N/e A>D:2,1/M1 ]
//状态转移向量输入同样是以[开头,空一格开始,
//以空一格加]结束。
//每个状态转移向量以一个空格隔开
ps:状态转移函数的意义
-----
A>B:2,Z/1Z
表示当前状态为A,当前栈顶元素为Z,遇到了字母2,则取出Z后
再依次放入Z,1。操作完成后栈顶元素为1,并且状态跳转为B
B>C:3,N/e
其中e表示空符号,这个转移向量表示空转移。
当前状态为B,栈顶为符号为N,遇到3则取出N,放入空号,也就是
消去了N,并且状态跳转到C
pda.c的实现逻辑与fa.c大同小异,主体上的思路大致相同,不过pda相同来说比较难实现一点。
这里简单讲一下pda_fget的思路:pda是七元组,比fa多出来了栈符号集跟栈底符号。所以其结构体的定义也相对来说复杂一些。
读取下推自动机跟流程跟有穷自动机基本相同,唯一不同的是pda的状态转移函数逻辑复杂了很多:
首先需要将转移前后的状态存到moveS/E中,转移条件读取到curMoveCase中,判断对应跳转是否存在,不存在初始值为-1。

当moveSE[][] == -1,即不存在时,将状态转移条件拷贝到moveCases三维数组中,并且更新条件下标跟线条的下标,每加入一个条件后加一。

turing.c
#include "turing.h"
//读取s指定路径的文件,并输出相应的自动机图表
void tm_getPng(char *s)
{
printf("%s\'s png generated!\n", s);
char termName[500];
char base[100] = {0};
strncpy(base, s, strlen(s) - 4);
FILE *file = fopen(s, "r");
if (file == NULL)
{
perror("tm_getPng");
exit(-1);
}
int i = 0;
while (!feof(file))
{
TM tm = tm_fget(file);
//生成对应dot文档
//先获取dot文档文件名
sprintf(termName, "%s_%d.dot", base, i);
FILE *fp = fopen(termName, "w");
if (fp == NULL)
{
perror("tm_getPng");
exit(-1);
}
tm_fputDot(fp, tm);
fclose(fp);
//生成控制生成图片的脚本编译命令
char cmd[300] = {0};
sprintf(cmd, "dot -Tpng %s_%d.dot -o %s_%d.png", base, i, base, i);
system(cmd);
i++;
}
fclose(file);
}
//初始化转移条件表
void tm_initMoveSE(TMP tm)
{
for (int i = 0; i < MAX_SIZE; i++)
{
for (int j = 0; j < MAX_SIZE; j++)
{
tm->moveSE[i][j] = -1;
}
}
}
//从文件中读取一个自动机
TM tm_fget(FILE *file)
{
TM out = {0};
char str[300] = {0};
// TODO 初始化moveCases
tm_initMoveSE(&out);
//读取状态集合
my_fscanf(file, "%s", str);
int len = strlen(str);
out.numOfConditions = len / 2 + 1;
char term[300];
for (int i = 0; i < out.numOfConditions; i++)
{
sscanf(str, "%c,%s", &out.conditions[i], term);
strcpy(str, term);
}
//读取字母表
my_fscanf(file, "%s", str);
len = strlen(str);
out.numOfLetters = len / 2 + 1;
for (int i = 0; i < out.numOfLetters; i++)
{
sscanf(str, "%c,%s", &out.letters[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//读取带符号集合
my_fscanf(file, "%s", str);
len = strlen(str);
out.numOfTapeLetters = len / 2 + 1;
for (int i = 0; i < out.numOfTapeLetters; i++)
{
sscanf(str, "%c,%s", &out.tapeLetters[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//读取空白带符号定义
my_fscanf(file, "%s", str);
sscanf(str, "%c", &out.emptyTapeLetter);
//读取开始状态
char st;
my_fscanf(file, "%s", str);
sscanf(str, "%c", &st);
//读取终止状态或者接受状态
char finals[300];
my_fscanf(file, "%s", str);
len = strlen(str);
int lenOfFinals = len / 2 + 1;
for (int i = 0; i < lenOfFinals; i++)
{
sscanf(str, "%c,%s", &finals[i], term);
strcpy(str, term); //把term的字符串复制给st
}
//根据读到的开始状态或者接受状态对状态种类进行标记
for (int i = 0; i < out.numOfConditions; i++)
{
if (out.conditions[i] == st)
{
out.conditionKinds[i] = 1;
continue;
}
else
{
for (int j = 0; j < lenOfFinals; j++)
{
if (out.conditions[i] == finals[j])
{
out.conditionKinds[i] = 2;
break;
}
}
}
}
// 读取状态转移,先读取到开始符号为止
do
{
my_fscanf(file, "%s", str);
if (strcmp(str, "[") == 0)
break;
} while (1);
//读取状态转移向量
out.numOfMoves = 0;
do
{
my_fscanf(file, "%s", str);
if (strcmp(str, "]") == 0)
break;
char curMoveCase[100]; //跳转条件
char moveS; //跳转开始状态
char moveE; //跳转结束状态
sscanf(str, "%c>%c:%s", &moveS, &moveE, curMoveCase);
//先判断这个方向和首位的跳转是否已经存在
//如果该线条不存在,添加该线条
if (out.moveSE[(int)moveS][(int)moveE] == -1)
{
out.move[out.numOfMoves][0] = moveS;
out.move[out.numOfMoves][1] = moveE;
out.moveSE[(int)moveS][(int)moveE] = out.numOfMoves;
//当前线条的下标
int indexOfCurMove = out.numOfMoves;
//当前线条的条件数量(新增条件的下标)
int indexOfCurCon = out.numOfMoveCases[indexOfCurMove];
//传递读取到的条件到该位置
strcpy(out.moveCases[indexOfCurMove][indexOfCurCon], curMoveCase);
//更新条件下标和线条下标
out.numOfMoveCases[out.numOfMoves]++;
out.numOfMoves++;
}
//如果该线条存在,往对应条件中添加
else
{
//获取当前线条的下标
int indexOfCurMove = out.moveSE[(int)moveS][(int)moveE];
//当前线条的条件数量(新增条件的下标)
int indexOfCurCon = out.numOfMoveCases[indexOfCurMove];
//传递读取到的条件到该位置
strcpy(out.moveCases[indexOfCurMove][indexOfCurCon], curMoveCase);
//更新条件下标
out.numOfMoveCases[indexOfCurMove]++;
}
} while (1);
return out;
}
//把自动机以dot脚本形式的形式写入文件
void tm_fputDot(FILE *file, TM tm)
{
fprintf(file, "digraph TuringMachine{\n");
//设置节点排布方式为从左到右
fprintf(file, "rankdir=LR\n");
//根据节点数量调节文件大小
int size = tm.numOfConditions * 2;
fprintf(file, "size=%d\n", size);
//打印节点
for (int i = 0; i < tm.numOfConditions; i++)
{
//如果是普通状态
if (tm.conditionKinds[i] == 0)
{
fprintf(file, "\n%c[shape=circle]", tm.conditions[i]);
}
//如果是终止状态或者接受状态
else if (tm.conditionKinds[i] == 2)
{
fprintf(file, "\n%c[shape=doublecircle]", tm.conditions[i]);
}
//如果是开始状态
else if (tm.conditionKinds[i] == 1)
{
fprintf(file, "\n%c[shape=circle]", tm.conditions[i]);
fprintf(file, "\nstart[label=\"\",shape=none]");
fprintf(file, "\nstart->%c[label=\"start\"]", tm.conditions[i]);
}
}
//打印跳转
for (int i = 0; i < tm.numOfMoves; i++)
{
char moveS = tm.move[i][0];
char moveE = tm.move[i][1];
int numOfCurCases = tm.numOfMoveCases[i];
//加上字符串的拼接
char curMoveCase[500] = {0};
tm_casescat(curMoveCase, tm.moveCases[i], numOfCurCases);
//以拼接好的条件写入字符串
fprintf(file, "\n%c->%c[label=\"%s\"]", moveS, moveE, curMoveCase);
}
fprintf(file, "\n}");
}
//按照一定的格式拼接条件字符串
void tm_casescat(char *dir, char sarr[MAX_CON_SIZE][MAX_STRLEN], int size)
{
if (size < 1)
{
printf("wrong input in tm_casescat");
return; //保证程序稳健性的意外处理
}
int len = 0;
for (int i = 0; i < size - 1; i++)
{
int j = 0;
while (sarr[i][j] != '\0')
{
dir[len++] = sarr[i][j];
j++;
}
dir[len++] = '\\';
dir[len++] = 'n';
}
int j = 0;
while (sarr[size - 1][j] != '\0')
{
dir[len++] = sarr[size - 1][j];
j++;
}
dir[len] = '\0';
}
tm_fget()函数主要是从txt文件中对turing machine进行七元组的获取,该七元组文件需事先定义好,且有固定的格式。
七元组的txt文件格式如下:
A,B,C,D
1,2,3
M,Q,Z
e
A
C,D
[
A>B:M/Q,L
B>C:Q/Z,R
]
简单说明一下,该txt文件中只能是turing machine的七元组,为了与有穷自动机和pda区分开来,但是数量依旧可以多个。
每一行数据的具体含义:
- 有穷状态集
- 有穷输入符号集
- 有穷带符号集
- 初始状态
- 接受状态集
- 空格/空白符号
- 状态转移向量
A,B,C,D //第一行是状态集合
1,2,3 //第二行是字母表
M,Q,Z //第三行是带符号集合,它总是包含字母表
e //第四行是空白带符号定义
A //第五行是开始状态
C,D //第六行是终止带符号
[ A>B:M/Q,L B>C:Q/Z,R ] //第七行状态转移向量
ps:关于状态转移向量的解释
----
A>B:M/Q,L
当前状态A,且当前读写头所在带符号为M,
则把当前位置带符号改写为Q,然后往左移动一格
并且状态跳转到B
B>C:Q/Z,R
当前状态B,且当前读写头所在带符号为Q
则把当前位置带符号改写为Z,然后往右移动一个,
并且状态跳转到C
turing.c与pda.c基本上只有自动机结构体,状态转移函数的读取,dot语言的生成方式有所不同,其他都是大同小异。这里只简单讲讲tm_fget()读取带符号集合跟空白带的实现方法。
跳过空行与注释,读取带符号集合数据存放到str中,strlen()得到读取行的长度,得到除逗号外的有效字符的个数,遍历式地将各个状态存放在自动机结构体变量的对应位置,sscanf()函数遇到空格或者回车停止,所以需要将后续字符串拷贝到term中循环读取,直到读取结束。
源码的简单分析到这里基本结束。
1.16 Makefile编写:
CC = gcc
CFLAGS = -std=c99 -Wall -ggdb -finput-charset=utf-8 -fexec-charset=utf-8
TARGET = top_call
OBJS = *.c
FILENAME = ./toReadFile/*.txt
PNG = *.png
DOT = *.dot
all:
mkdir ./build/
mkdir ./dotFile/
mkdir ./pngFile/
$(CC) $(CFLAGS) $(OBJS) -o $(TARGET)
./$(TARGET) $(FILENAME)
cp $(TARGET) ./build/
cp ./toReadFile/$(PNG) ./pngFile/
rm ./toReadFile/$(PNG) -rf
cp ./toReadFile/$(DOT) ./dotFile/
rm ./toReadFile/$(DOT) -rf
# sxiv ./pngFile/*
clean:
rm -rf $(TARGET) ./build/
rm -rf ./pngFile
rm -rf ./dotFile
install:
sudo cp $(TARGET) /usr/bin
uninstall:
sudo rm -rf /usr/bin/$(TARGET)
使用makefile将生成的各类文件简单地归类,将png文件存放在./pngFile中,将dot文件存放在./dotFile中,将编译生成的可执行文件存放在./build中。生成上述文件的命令为make,使用make clean将上述文件清理,使用make install将可执行文件拷贝到PATH路径中的/usr/bin目录,使其具有像ls,cp,mv等命令行指令不需要带路径就可以执行,使用make uninstall将拷贝到PATH中的可执行文件删除。
1.17 编写静态库:
编写静态库基本指令:
gcc -c fa.c pda.c turing.c generic.c #将除main文件的所有c文件生成.o可重定向二进制文件
ar src libpackage.a *.o #使用ar指令将.o文件生成.lib库文件
gcc top_call.c -o top_call -L . -lpackage #gcc使用 -L选项指定静态库处于哪个文件夹下
#-l选项指定静态库文件除lib跟.a生成的文件名,例如静态库的名称是libpackage.a,则-l package
由main文件链接到静态库生成的可执行文件可以直接运行,不需要链接其他库。
2. 项目产品工具
本项目的开发环境:
项目运行环境:Linux-Ubuntu20.04 / Centos7.9
文本格式:UTF-8
编译器:gcc/g++ python3 dot
编辑器:vscode vim wsl
3. 项目使用说明
注:本项目请使用linux环境
git clone https://github.com/iwannabewater/BUPT_Summer_Camp.git #使用git工具将远程仓库中的代码拉取到本地
cd BUPT_Summer_Camp/ #进入到项目中
ls -l #查看当前文件夹下的文件信息

# 可以使用cat指令 LICENSE 及 README.md 例如:cat README.md
cd C_2_DOT/ #进入到c文件夹中、
ll #使用ll指令查看当前文件夹中文件的详细信息

#可以看到有多个.c文件,多个.h头文件,一个makefile文件
#直接使用make指令进行编译
make #执行makefile中的逻辑
ll #查看生成的文件信息


#生成的png文件存放在pngFIle文件夹中,生成的dot文件存放在dotFile文件夹中,可执行文件在build中也存了一份
#查看生成的自动机png图片
sxiv *.png #centos
#在wsl-vscode-ubuntu中可以直接查看图片
ε-NFA:

PDA:
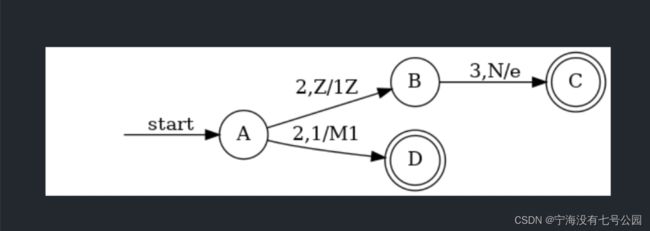
Turing Machine:

#可以自行在toReadFile中创建txt文件,文件的格式见part1项目报告
#也可以使用makefile进行半自动化编译,运行命令为:
./top_call ./toReadFile/fa.txt #fa.txt可以换成指定的txt文件,还可以指定多个txt文件(格式需要正确
#可以使用如下命令查看各自动机对应的格式
./top_call --help

#ps:详细细节可以查看readme
cat README.md
over~