k-means/k-means++算法的笔记及scala实现
前言
自己看博客也有很长一段时间了,突然想尝试着自己写一写,这段时间一直在入门机器学习的算法同时也参考了一些书籍,博客文章(无奈小白一枚,这些内容我会列在最后),现在做一个学习的总结,算是笔记吧,与君共勉~
一、小谈聚类与分类
聚类分类不同,简单来说,分类是在已知类别(事先定义好类别)的情况下,从一堆带有标签的数据集中训练出一个分类器,预测未知标签数据的所属类别;而聚类是在未知类别(事先没有定义类别,类别数不确定)的情况下,将不带标签的数据集划分为几类(簇)的过程。聚类的目的就是把不同的数据点按照它们的相似与相异度分割成不同的簇(注意:簇就是把数据划分后的子集),确保每个簇中的数据都是尽可能相似,而不同的簇里的数据尽可能的相异。。
二、基本k-means算法
2.1 概述
k-means算法的基本思想是随机初始化k个簇中心,k需要事先人为指定即所期望的簇的个数,将每个样本点指派到离自己最近的簇中心,指派到同一个簇中心的所有点集形成一个簇,然后更新每个簇的中心,重复指派和更新两个步骤,直到簇中心不再有大的变化。
2.2 代价函数
在程序中,我指定所有点到其所属簇中心的距离的平方和即误差的平方和(sum of the squared error,SSE)作为代价函数,我们的目标是通过迭代更新簇中心来最小化这个代价函数。
SSE = ∑ i = 1 K ∑ x ϵ C i ∣ ∣ x , c i ∣ ∣ 2 \displaystyle\sum_{i=1}^{K}\sum_{x\epsilon C_i} ||x,c_i||^2 i=1∑KxϵCi∑∣∣x,ci∣∣2
| 符号 | 描写 |
|---|---|
| x | 样本点 |
| C i \ C_i Ci | 第i个簇 |
| c i \ c_i ci | 簇 c i \ c_i ci的中心 |
| m | 数据集中样本点的个数 |
| K | 簇的个数 |
2.3 算法主要步骤
k-means算法主要步骤如下:
1: 随机选取k个点作为簇中心
2: repeat
3: 计算每个样本点到各簇中心的距离,并聚类到离自己最近的簇中心
4: 对每个簇类中的点计算平均值,将均值作为新的簇中心
5: until 代价函数不发生大的变化
Tips:
随机初始化k个点时一定要保证k个点互异,程序中我随机生成k个整数(代表样本集数组中的下标),并判断其是否重复,若不加控制会生成重复的随机数即实际上初始化的中心点个数
上述的步骤3和4试图直接最小化代价函数SSE,步骤3通过将点指派到最近的簇中心形成聚类,固定簇心集的情况下最小化SSE,步骤4重新选择簇心,进一步最小化SSE,每一次的迭代都在减小SSE。然而只能确保找到关于SSE的局部最优解,因为每次迭代都针对选定的簇心和簇,而不是对所有可能的选择来最小化。
2.4 选择初始簇心
在运行k-means算法前,我们首先要选择适当的初始簇心点,这是算法过程的关键步骤,常见的方法是按以下原则随机地初始化簇心点:
- 我们应该选择K
- 随机选择K个样本点作为初始簇中心点
但是这样的随机初始化簇心可能会使聚类效果不好,即让SSE停留在一个局部最小值处,这里我用《数据挖掘导论》中的例图来说明(自己实在是难以画图…)

图1中有四类点集,分别以不同形状表示,第一次迭代时,随机初始四个点作为簇中心,最后得到比较好的聚类效果,四类不同形状的点集都单独作为一类。
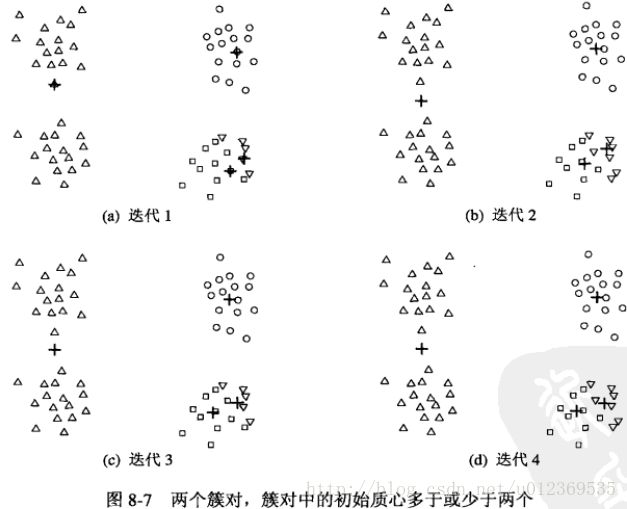
图2中相同的四类点集,第一次迭代时随机选择四个簇中心,可以看到此时四个中心点在分布上较图1中有所不同,迭代数次后,最后得到的聚类效果较差,把本该是两类的点集合并为一个类,本该是一类的点集分裂成了两类。
2.5 聚类数的选择
对于聚类数K值的选取,并没有所谓最好的方法,通常是需要根据不同的问题,人工进行选择,我们会用一个所谓的“肘部法则”来帮助选择K值的大小,这里我借用一下Ng公开课的PPT。

横坐标是不同的K值,纵坐标则是我们的代价函数即SSE,每选取一个K值,运行一次k-means算法,得到SSE的收敛值,可以看出K等于某一个值时,图中出现一个明显的拐点,在这个拐点之前,代价函数值下降得很快,在该点之后,代价函数值下降得很慢,则选取这个拐点作为K的大小,这是一种合理的方法,然而并非总是有效的。
2.6 代码实现
package KMeans
import scala.collection.mutable
import scala.io.Source
import scala.util.Random
object Kmeans {
val k = 2 //类个数
val dim = 3 //数据集维度
val shold = 0.0000000001 //阈值,用于判断聚类中心偏移量
val centers = new Array[Vector[Double]](k) //聚类中心点(迭代更新)
def main(args: Array[String]): Unit = {
//处理输入数据
val fileName = "D:\\kmeans_data.txt"
val lines = Source.fromFile(fileName).getLines()
val points = lines.map(line => {//数据预处理
val parts = line.split(" ").map(_.toDouble)
var vector = Vector[Double]()
for(i <- 0 to dim - 1)
vector ++= Vector(parts(i))
vector
}).toArray
initialCenters(points)
kmeans(points,centers)
printResult(points,centers)
}
//-------------------------------------随机初始化聚类中心---------------------------------------------------
def initialCenters(points:Array[Vector[Double]]) = {
val pointsNum = points.length//数据集个数
//寻找k个随机数(作为数据集的下标)
val random = new Random()
var index = 0
var flag = true
var temp = 0
var array = new mutable.LinkedList[Int]()//保存随机下标号
while(index < k ){
temp = new Random().nextInt(pointsNum)
flag = true
if (array.contains(temp)){//在数组中存在
flag = false
}
else {
if (flag){
array = array :+ temp
index+=1
}
}//else-end
}//while-end
for(i <- 0 to centers.length - 1){
centers(i) = points(array(i))
println("初始化中心点如下:")
println(array(i))
println(centers(i))
}
}
//---------------------------迭代做聚类-------------------------------------
def kmeans(points:Array[Vector[Double]],centers:Array[Vector[Double]]) = {
var bool = true
var newCenters = Array[Vector[Double]]()
var move = 0.0
var currentCost = 0.0 //当前的代价函数值
var newCost = 0.0
//根据每个样本点最近的聚类中心进行groupBy分组,最后得到的cluster是Map[Vector[Double],Array[Vector[Double]]]
//Map中的key就是聚类中心,value就是依赖于该聚类中心的点集
while(bool){//迭代更新聚类中心,直到最优
move = 0.0
currentCost = computeCost(points,centers)
val cluster = points.groupBy(v => closestCenter(centers,v))
newCenters =
centers.map(oldCenter => {
cluster.get(oldCenter) match {//找到该聚类中心所拥有的点集
case Some(pointsInThisCluster) =>
//均值作为新的聚类中心
vectorDivide(pointsInThisCluster.reduceLeft((v1,v2) => vectorAdd(v1,v2)),pointsInThisCluster.length)
case None => oldCenter
}
})
for(i <- 0 to centers.length - 1){
//move += math.sqrt(vectorDis(newCenters(i),centers(i)))
centers(i) = newCenters(i)
}
/* if(move <= shold){
bool = false
}*/
newCost = computeCost(points,centers)//新的代价函数值
println("当前代价函数值:" + currentCost)
println("新的代价函数值:" + newCost)
if(math.sqrt(vectorDis(Vector(currentCost),Vector(newCost))) < shold)
bool = false
}//while-end
println("寻找到的最优中心点如下:")
for(i <- 0 to centers.length - 1){
println(centers(i))
}
}
//--------------------------输出聚类结果-----------------------------
def printResult(points:Array[Vector[Double]],centers:Array[Vector[Double]]) = {
//将每个点的聚类中心用centers中的下标表示,属于同一类的点拥有相同的下标
val pointsNum = points.length
val pointsLabel = new Array[Int](pointsNum)
var closetCenter = Vector[Double]()
println("聚类结果如下:")
for(i <- 0 to pointsNum - 1){
closetCenter = centers.reduceLeft((c1,c2) => if (vectorDis(c1,points(i)) < vectorDis(c2,points(i))) c1 else c2)
pointsLabel(i) = centers.indexOf(closetCenter)
println(points(i) + "-----------" + pointsLabel(i))
}
}
//--------------------------找到某样本点所属的聚类中心-----------------------------
def closestCenter(centers:Array[Vector[Double]],v:Vector[Double]):Vector[Double] = {
centers.reduceLeft((c1,c2) =>
if(vectorDis(c1,v) < vectorDis(c2,v)) c1 else c2
)
}
//--------------------------计算代价函数(每个样本点到聚类中心的距离之和不再有很大变化)-----------------------------
def computeCost(points:Array[Vector[Double]],centers:Array[Vector[Double]]):Double = {
//cluster:Map[Vector[Double],Array[Vector[Double]]
val cluster = points.groupBy(v => closestCenter(centers,v))
var costSum = 0.0
//var subSets = Array[Vector[Double]]()
for(i <- 0 to centers.length - 1){
cluster.get(centers(i)) match{
case Some(subSets) =>
for(j <- 0 to subSets.length - 1){
costSum += (vectorDis(centers(i),subSets(j)) * vectorDis(centers(i),subSets(j)))
}
case None => costSum = costSum
}
}
costSum
}
//--------------------------自定义向量间的运算-----------------------------
//--------------------------向量间的欧式距离-----------------------------
def vectorDis(v1: Vector[Double], v2: Vector[Double]):Double = {
var distance = 0.0
for(i <- 0 to v1.length - 1){
distance += (v1(i) - v2(i)) * (v1(i) - v2(i))
}
distance = math.sqrt(distance)
distance
}
//--------------------------向量加法-----------------------------
def vectorAdd(v1:Vector[Double],v2:Vector[Double]):Vector[Double] = {
var v3 = v1
for(i <- 0 to v1.length - 1){
v3 = v3.updated(i,v1(i) + v2(i))
}
v3
}
//--------------------------向量除法-----------------------------
def vectorDivide(v:Vector[Double],num:Int):Vector[Double] = {
var r = v
for(i <- 0 to v.length - 1){
r = r.updated(i,r(i) / num)
}
r
}
}
所用的数据集如下(简单的不能再简单的数据集了-_-):
0.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
…省略…
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
运行结果如下:
随机初始化中心点如下:
12
Vector(4.0, 4.0, 4.0)
26
Vector(8.2, 8.2, 8.2)
18
Vector(6.0, 6.0, 6.0)
当前代价函数值:277.38
新的代价函数值:108.55218750000003
当前代价函数值:108.55218750000003
新的代价函数值:92.00698224852073
当前代价函数值:92.00698224852073
新的代价函数值:83.08516875
当前代价函数值:83.08516875
新的代价函数值:81.60000000000001
当前代价函数值:81.60000000000001
新的代价函数值:81.60000000000001
寻找到的最优中心点如下:
Vector(1.6000000000000003, 1.6000000000000003, 1.6000000000000003)
Vector(8.1, 8.1, 8.1)
Vector(5.1, 5.1, 5.1)
聚类结果如下:
Vector(0.0, 0.0, 0.0)-----------0
Vector(0.1, 0.1, 0.1)-----------0
Vector(0.2, 0.2, 0.2)-----------0
Vector(1.0, 1.0, 1.0)-----------0
Vector(1.1, 1.1, 1.1)-----------0
Vector(1.2, 1.2, 1.2)-----------0
Vector(2.0, 2.0, 2.0)-----------0
Vector(2.1, 2.1, 2.1)-----------0
Vector(2.2, 2.2, 2.2)-----------0
Vector(3.0, 3.0, 3.0)-----------0
Vector(3.1, 3.1, 3.1)-----------0
Vector(3.2, 3.2, 3.2)-----------0
Vector(4.0, 4.0, 4.0)-----------2
Vector(4.1, 4.1, 4.1)-----------2
Vector(4.2, 4.2, 4.2)-----------2
Vector(5.0, 5.0, 5.0)-----------2
Vector(5.1, 5.1, 5.1)-----------2
Vector(5.2, 5.2, 5.2)-----------2
Vector(6.0, 6.0, 6.0)-----------2
Vector(6.1, 6.1, 6.1)-----------2
Vector(6.2, 6.2, 6.2)-----------2
Vector(7.0, 7.0, 7.0)-----------1
Vector(7.1, 7.1, 7.1)-----------1
Vector(7.2, 7.2, 7.2)-----------1
Vector(8.0, 8.0, 8.0)-----------1
Vector(8.1, 8.1, 8.1)-----------1
Vector(8.2, 8.2, 8.2)-----------1
Vector(9.0, 9.0, 9.0)-----------1
Vector(9.1, 9.1, 9.1)-----------1
Vector(9.2, 9.2, 9.2)-----------1
三、k-means++算法
3.1 概述
对于初始化簇中心点,我们可以在输入的数据集中随机地选择k个点作为中心点,但是随机选择初始中心点可能会造成聚类的结果和数据的实际分布相差很大。k-means++就是选择初始中心点的一种算法,其基本思想就是:初始的聚类中心之间的相互距离要尽可能远。
3.2 算法主要步骤
1)从输入的数据点集合中随机选择一个点作为第一个聚类中心
2)repeat
3) 对于数据集中的每一个样本点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
4) 选择一个新的数据点作为下一个聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
5)until k个聚类中心被选出来
6)利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述可以看到,算法的关键是第4步,如何将D(x)反映到点被选择的概率上。一种算法如下:
1)随机从点集中选择一个点作为初始中心点
2)repeat
3) 计算每一个点到最近中心点的距离 S i S_i Si,对所有 S i S_i Si求和得到sum
4) 然后再取一个随机值,用权重的方式计算下一个“种子点”。取随机值random(0
5)until k个聚类中心被选出来
6)利用这k个初始的聚类中心来运行标准的k-means算法
Tips:
执行步骤4的过程中,我添加了i是否重复的判断,保证取到的中心点互异,否则循环再生成一个随机值,计算判断,直到i不同
这里的random可以这么取:random = sum * r,r ϵ \epsilon ϵ(0,1),程序中一定要保证r的范围是大于0且小于1,否则r有可能取0,影响下一个中心点的选取(自己当时也没有注意这个小细节,以致于运行程序时发现选择的初始中心点相互之间距离非常近)
关于D(x)较大的点,被选为下一个中心点的概率较大,可以用如下图解释(借用七月课程PPT)

上图中,有5个样本点,Dc1和Dc2为已知的两个聚类中心点,计算出各点到最近的中心点的距离后,可以看到 x 2 x_2 x2对应的距离最大,其相应的权重最大,被选到的作为下一个中心点的概率也最大,更直观点的话如下图

random=11,循环到i=2时,random=-2<0,则 x 2 x_2 x2为下一个中心点
3.3 代码实现
//---------------------------k-means++初始化聚类中心-------------------------------------
def kmeansppInitial(points:Array[Vector[Double]]) = {
val pointsNum = points.length//数据集个数
val random = new Random()
var kSum = 1
var flag = true
var temp = random.nextInt(pointsNum)//选择第一个随机数(下标)
var array = new mutable.LinkedList[Int]()//保存随机下标号
var updatedCenters = new mutable.LinkedList[Vector[Double]]()//迭代添加元素的聚类中心数组
var sum = 0.0
var randomSeed = 0.0
var pointsAndDist = Array[Double]()//保存每个样本点对应到各自聚类中心的距离
var j = 0
array = array :+ temp
updatedCenters = updatedCenters :+ points(temp)//将随机选择的点作为第一个聚类中心
while(kSum < k ){
pointsAndDist = points.map(v => //计算每个样本点与它所属的聚类中心的距离
vectorDis(v,closestCenter(updatedCenters.toArray,v))
)
sum = pointsAndDist.reduceLeft((a,b) => a + b)
println("sum=="+ sum)
flag = true
while(flag){
randomSeed = sum * (random.nextInt(100) + 1) / 100
breakable{
for(i <- 0 to pointsAndDist.length - 1){
randomSeed -= pointsAndDist(i)
if(randomSeed < 0){
j = i
break
}
}
}
if(array.contains(j)){//求得的新中心点的下标在数组中存在
flag= true
}else{
array = array :+ j
updatedCenters = updatedCenters :+ points(j)
flag = false
kSum += 1
}
}
}//while-end
println("kmean++初始化中心点如下:")
for(i <- 0 to updatedCenters.length - 1){
centers(i) = updatedCenters(i)
println(array(i))
println(centers(i))
}
}
运行结果如下:
kmean++初始化中心点如下:
0
Vector(0.0, 0.0, 0.0)
16
Vector(5.1, 5.1, 5.1)
27
Vector(9.0, 9.0, 9.0)
当前代价函数值:143.97000000000006
新的代价函数值:83.33745099852068
当前代价函数值:83.33745099852068
新的代价函数值:81.59999999999998
当前代价函数值:81.59999999999998
新的代价函数值:81.59999999999998
寻找到的最优中心点如下:
Vector(1.1000000000000003, 1.1000000000000003, 1.1000000000000003)
Vector(4.6000000000000005, 4.6000000000000005, 4.6000000000000005)
Vector(8.1, 8.1, 8.1)
聚类结果如下:
Vector(0.0, 0.0, 0.0)-----------0
Vector(0.1, 0.1, 0.1)-----------0
Vector(0.2, 0.2, 0.2)-----------0
Vector(1.0, 1.0, 1.0)-----------0
Vector(1.1, 1.1, 1.1)-----------0
Vector(1.2, 1.2, 1.2)-----------0
Vector(2.0, 2.0, 2.0)-----------0
Vector(2.1, 2.1, 2.1)-----------0
Vector(2.2, 2.2, 2.2)-----------0
Vector(3.0, 3.0, 3.0)-----------1
Vector(3.1, 3.1, 3.1)-----------1
Vector(3.2, 3.2, 3.2)-----------1
Vector(4.0, 4.0, 4.0)-----------1
Vector(4.1, 4.1, 4.1)-----------1
Vector(4.2, 4.2, 4.2)-----------1
Vector(5.0, 5.0, 5.0)-----------1
Vector(5.1, 5.1, 5.1)-----------1
Vector(5.2, 5.2, 5.2)-----------1
Vector(6.0, 6.0, 6.0)-----------1
Vector(6.1, 6.1, 6.1)-----------1
Vector(6.2, 6.2, 6.2)-----------1
Vector(7.0, 7.0, 7.0)-----------2
Vector(7.1, 7.1, 7.1)-----------2
Vector(7.2, 7.2, 7.2)-----------2
Vector(8.0, 8.0, 8.0)-----------2
Vector(8.1, 8.1, 8.1)-----------2
Vector(8.2, 8.2, 8.2)-----------2
Vector(9.0, 9.0, 9.0)-----------2
Vector(9.1, 9.1, 9.1)-----------2
Vector(9.2, 9.2, 9.2)-----------2
----参考文献-----
1: 《数据挖掘导论》
2: 《Spark MLlib机器学习》
3: http://blog.csdn.net/u014512572/article/details/53096465
4: https://www.cnblogs.com/nocml/p/5150756.html