调参侠级机器学习之股票预测初级阶段
由于复习考研,高数英语占日常学习比例较大,最近按照论文的格式,把期末作业整理了一下,以下为正文:
摘要:
股票预测是指:对股市具有深刻了解的证券分析人员根据股票行情的发展进行的对未来股市发展方向以及涨跌程度的预测行为。这种预测行为只是基于假定的因素为既定的前提条件为基础的。
——百度百科
机器学习的普及前所未有。它广泛应用于基于数据决策的领域,在投资领域亦是如此。只需要在谷歌中同时搜索“机器学习”和“股票预测”,便可以得到大量关于时间序列预测和循环神经网络的内容。尽管股票价格对于这类算法来说是绝佳的数据选择,但是我们仍应当谨慎行事,尤其是涉及到钱的时候。
预测股市将如何变化历来是最困难的事情之一。这个预测行为中包含着如此之多的因素—包括物理或心理因素、理性或者不理性行为因素等等。所有这些因素结合在一起,使得股价波动剧烈,很难准确预测。股票投资的系统风险和非系统风险错综复杂,各个影响因素之间的数量关系难以提取分析,这就使得通过传统的方法所预测的结果往往不尽人意。因此,寻找有效的股票预测方法有其重要的理论意义和现实意义。
- 研究目的和现有技术介绍
研究目的:
将各种数学理论、数据挖掘技术应用到股票分析软件中,并且通过对历史交易数据的研究,从而得到股票的在走势规律。通过机器学习的方式,可以在运用过程中依据数据的不断学习优化,完善预测模型,来达到成功预测股票涨幅,进而达到盈利的目的
技术介绍:
Numpy,pandas进行数据预处理;
支持向量机SVC算法进行机器学习;
StandardScaler算法进行数据规范化;
Matplot进行数据可视化,画图分析;
预测:
是指从已知事件测定未知事件。预测理论作为一种通用的方法论,既可以应用于研究自然现象,也可以应用于研究社会现象。将预测理论应用于各个领域,就产生了预测的各个分支,如人口预测、经济预测、气象预测等。股市预测,是经济预测的一个重要分支。它对股票市场所反映的各种资讯进行收集、整理、综合等工作,从股市的历史、现状和规律性出发,对股市未来发展前景进行测定。大致来说,对于股市的预测,有两种研究方法。一种是从基本的经济原理出发,建立金融时间序列的数学模型,像Markovitz的投资组合理论、资本资产定价模型(CAPM)、套利定价理论(APT)、期权定价模型等。这些理论,在理论上很成功(有三项获得诺贝尔经济学奖),但它们都是建立在很理想的假设上,而这些假设与市场的实际情况有很大差距,所以这些理论在实际效果中并不理想。
另一种方法是从统计角度对金融时间序列进行研究。这种方法直接从实际数据出发,应用概率统计方法推断出市场未来的变化规律。虽然这种方法从经济学角度来讲缺乏理论性,但是在实际应用中效果较好。而且,统计方法还可以对经济模型的好坏进行检验和评价。近年来,随着人工智能理论的发展成熟,其在模式识别和复杂系统控制等方面已经取得了巨大的成功,并开始在经济、金融领域得到应用。有不少学者开始用混沌和分形理论、人工神经网络来研究股市,并取得了一些成果。支持向量机是从统计学习理论中发展出来的一种新的通用学习机器,它有完备的理论基础和严格的理论体系,具有稳定性强、全局最优、避免“过学习”和“维数灾难”等优点。因此,已有一些科研人员开始用其进行股票市场的研究。
- 数据介绍和预处理方法
数据来自于外汇市场近6年的交易数据,两组数据里面分别有三万条往期股票价格走势具体数据,来用于模型的训练和测试。通过对往期数据的训练,来预测股票的价格走势。股票波动是按照小时为单位,每小时股票的高点、低点、开盘时间、开盘点等一一列出。使用numpy、pandas将数据导入,并分为不同的数组,以及将新数据写入表格。
首先要对数据预处理(数据清洗),包括数据的归一化,去除重复数据,修改错误数据,填充无效数据,抽象数据表示,筛选特征值,分配权重等等,以得到更准确的数据和更有效的结果。
- 使用的模型介绍
分类——样本属于两个或多个类别,我们希望通过从已标记类别的数据学习,来预测未标记数据的分类。例如,识别手写数字就是一个分类问题,其目标是将每个输入向量对应到有穷的数字类别。从另一种角度来思考,分类是一种有监督学习的离散(相对于连续)形式,对于n个样本,一方有对应的有限个类别数量,另一方则试图标记样本并分配到正确的类别。
回归——如果希望的输出是一个或多个连续的变量,那么 这项任务被称作回归,比如用年龄和体重的函数来预测三文鱼的长度。
SVC支持向量机是一种分类算法,但是也可以做回归,根据输入的数据不同可做不同的模型,是数据挖掘中的一项新技术,是借助于最优化方法解决机器学习问题的新工具。通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,能获得良好统计规律的目的。SVC能非常成功地处理回归问题(时间序列分析)和模式识别(分类问题、判别分析)等诸多问题,并可推广于预测和综合评价等领域。因此,可应用于工科、理科和管理学科等多种学科。目前,无论是在国内还是国际上,有关向量机的理论研究和应用研究都正处于飞速发展阶段。
- 结果与分析
现在有两个csv文件,我把它分为train与test,他们包括了外汇市场近6年的交易数据,下面我开始对于这些数据的预处理、可视化、规范化、调参以及训练机器学习模型:
(1)对于train.csv表格数据可以得知七个初始信息,即日期、时间、收盘价、开盘价、成交量、最高价与最低价,并为之分别命名为data,time,close,open,num,high,low。
首先画出close与open的走势图:

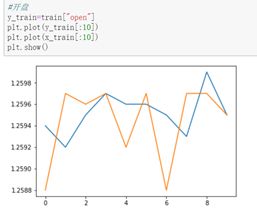
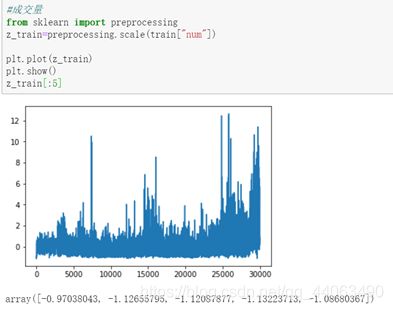
然后画出num的走势图:
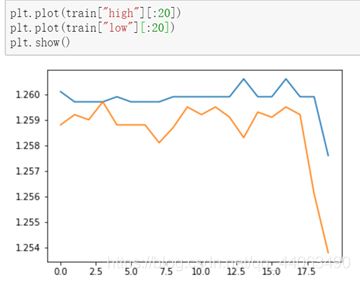
最后画出high、low的走势图,至此,csv中的所有指标已经全部用图表画出:
因为num数值普遍过大,此处用preprocessing.scale()对其进行规范化,变成利于计算机处理的数值。后来发现此处规范不规范不影响准确率。
其次,统计每个时间段的股票涨跌情况,此处的方法为用close减去open的值,若为正数则为涨,为负数则跌,并取前15000个数据作为训练集,后14000个数据作为测试集。
另外,由于我在csv表格中加入了表头,所以我的取值范围为表格里第二行开始到29000,分隔训练集与测试集:
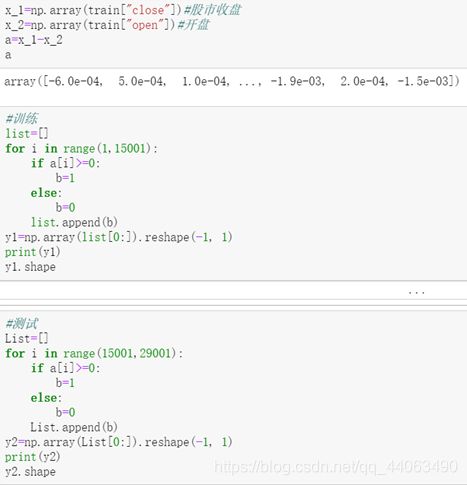
在X中写入表格中现有的特征值:


我选择的是支持向量机模型并对其进行训练,通过StandardScaler对两者数据进行规范化,然后进行fit:
得到结果为0.5352(忘了截图)。
(2)我们还可以添加自己的一组特性,我们认为这些特性与预测相关。为了进一步提高模型的准确程度,我加入了更多的股票指标:
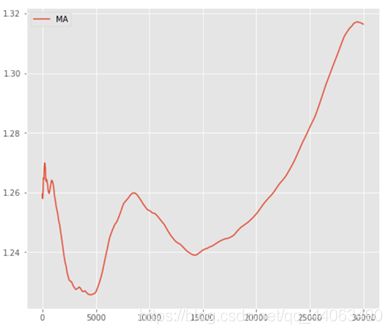
- 均值EMA
公式:EMA(12)=前一日EMA(12)×11/13+今日收盘价×2/13
求出所有的EMA值,并通过pd.to_csv将其写入表格,列头命名为EMA。

最终结果仅提升至0.5453。
画出均值的图像:
- 离差值DIF
公式:DIF=今日EMA(12)-今日EMA(26)
画出dif图像:

3. macd指标
要求macd首先要知道DIF的数值,
DIF公式:DIF=今日EMA(12)-今日EMA(26)
通过代码求出数值后写入csv文件:

下一步就可以求出macd数值,
macd公式:今日DEA(MACD)=前一日DEA×8/10+今日DIF×2/10

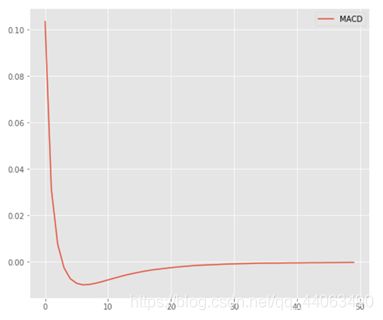
目前为止得到的最终结果,提升到0.56xxxxx。
继续添加更多的股票指标。
- kdj指标
计算K值,需要用到RSV,所以先计算该数值:
RSV=(收盘价-最低价)÷(最高价-的最低价)×100

接下来计算出K值:
K值:当日K值=2/3×前一日K值+1/3×当日RSV


接下来的D,K值用同样的方法计算得到全部数值,就不贴代码了,仅画个图像吧。
D值:当日D值=2/3×前一日D值+1/3×当日K值

J值:J值=3当日K值-2当日D值

至此,KDJ值已全部计算出。
最后画一个总体kdj图像:

(3)但所求得的各大指标中包含空值以及无穷数,我将这些在后期导致程序错误信息的数值用平均值替换:
1.替换空值:

2.替换无穷数:

将得到的指标写入X中,并分为测试集,和训练集,并进行训练测试:

最终测试结果提升至0.77707。
画出X的图表:

- 结论
最后我计算一下总收益,如果预测的是涨,则买入,用收盘价减去开盘价;
如果预测跌,则买出:
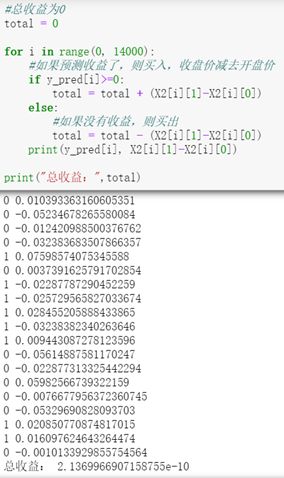
最后,我们能得到2.13个单位的收益。
同样的,在对test.csv进行预测,过程此处省略
SVC模型可以对各种参数进行调优,但其预测是否足以确定股票价格将上涨还是下跌?当然不行!由于股价受到公司新闻和其他因素的影响,如公司的非货币化或合并/分拆,还有一些无形的因素往往是无法事先预测的。
股票的预测要考虑的因素实在太多,这些指标可能仅仅是很小很小的一部分因素,并且我对于股票走势图实在是不敏感,无法洞察出更多的提升空间,机器学习也只是刚入门的程度,我相信经过以后更加深入的学习,我会对于数据科学更加娴熟,并认识到更多模型在处理问题上的相应优势。