微信AI从识物到通用图像搜索的探索揭秘

作者:lincolnlin,腾讯 WXG 专家研究员
微信识物是一款主打物品识别的 AI 产品,通过相机拍摄物品,更高效、更智能地获取信息。2020 年,微信识物拓展了更多识别场景,上线了微信版的图片搜索。本篇文章将与大家分享微信识物从识物拓展到通用图像搜索领域的发展过程。
微信识物
以上小视频简单介绍了识物的产品形态,它对微信扫一扫的扫封面能力进行了升级。打开微信扫一扫,左滑切换到“识物”功能,对准想要了解的物品正面,可以获取对应的物品信息,包括物品百科、相关资讯、相关商品。在微信识物发布不久,也快速地支持了像识花、识车这些实用的识别能力。

从一个 query 到结果,识物引擎是如何完成一次图像识别全过程呢?
首先我们会对 query 的图片做目标检测,去除背景干扰。
然后以图像主体进行检索,拿到图像召回的列表。
最后一步是进行信息提炼,得到商品的标题,品牌,主体,主图等。

从一个识别天地一号的例子来讲,可以看到从检测、图像召回、信息提炼后,我们得到了这是一个天地一号的苹果醋,再关联更多的搜索结果。
我们的识别效果究竟如何,我们也跟公司内外的识别引擎作了一些对比发现,基于微信自研的识物引擎和微信小程序商城海量的商品数据,我们取得了一流的识别效果。
跟业界同类产品相比,微信识图无论是在体验、识别效果、内容和商品上,都更具有微信的特色。
微信图像搜索

微信图片搜索是我们最近刚刚上线的,大家应该能看到,在微信会话和朋友圈中,图片多了一个搜一搜的入口。
识物搜索的现状
那么讲起图像搜索,大家肯定马上想到 google、baidu。这些搜索引擎在 10 年前就上线了图像搜索,并且经过多年经营,已经成了一个很大的入口。
微信识图又是怎么样的,如何基于微信的场景做出差异化?这是我们首先思考的问题。
微信识图
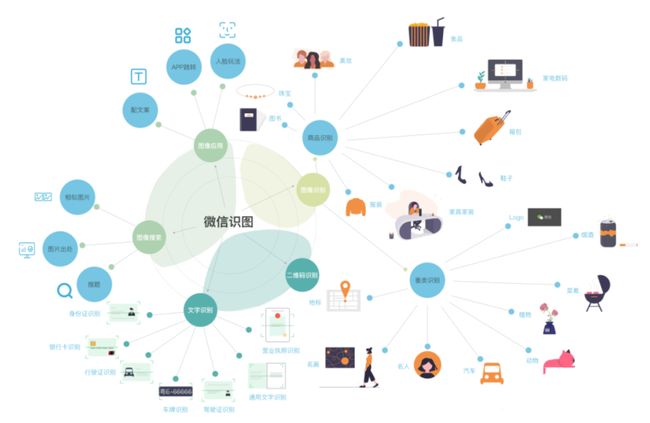
接下来这个图,是我对微信识图的一个设计蓝图。我们期望微信识图是这样的一个产品形态:
微信图像识别的入口,拓展各类识别能力,包含图像识别、图像搜索、二维码识别、文字提取,以及各种图像的应用及玩法。
接下来,我会介绍一下识图的一些具体应用场景。
商品识别

社群中经常会看到商家在推荐商品,我们直接通过搜一搜,可以快速了解商品信息,看看是否真是物有所值,价廉物美。
细分类识别

群聊中有时候看到一些豪车不认识时,长按搜一搜,避免被忽悠。
有些同事经常会在朋友发一些花草,尤其春夏季节。但可能发表者自己都不认识花的名字,搜一搜可以帮你快速知道植物的所有细节。
前几天我看到一个北大同学发湖的图片,我猜测是未名湖,但不太确实。这时候果断搜一搜,感觉评论的时候就自信多了。

我们还支持动物识别、菜品识别、红酒识别、名画识别等细分类识别能力。
菜品识别对一些正在减肥健身的人群,了解食品的热量是个强需求。长按识别菜品我们很快会支持查热量,我们支持常见的菜肴、水果蔬菜、包装食品等。
以图搜图的拓展

接下来介绍以图搜图的一些拓展能力:
包含图片内容:溯源。当图片是某个电影里的截图,你想要知道它的出处。或者你想知道你的原创图片是否被他人转载或者盗用。又或者有一个长得很漂亮的美女主动加你微信,说头像是本人。这时候通过图片搜索,我们很容易一探究竟。
相似图片:找一些相同风格的图片。
搜索物料:通过识别 logo+ocr 的方法,可以实现内容提取并跳转的能力。
以图搜图的系统实现
前面是一些产品介绍,接下来我详细聊一下以图搜图的系统实现,核心讲三个东西:分类、检测、检索。
分类篇 | 图片内容标签体系
图像分类是 CV 的基础,为了更好地理解微信内图片的类型分布,我们构建了一套图片内容标签体系。从图上来源上,我们主要分为广告、拍照、手机截屏这三种。从图片的内容标签上,我们划分成 9 个一级类目,42 个二级类目。这是一个多标签、多任务的分类任务。
分类篇 | 多标签分类

之所以是多标签,是因为多标签分类更加适合复杂的图像场景,比如上面图 1,同时有美女、服装、植物、户外场景等标签。所以我们的做法是来源和标签两种任务共享 backbone 网络,通过一个 slice 层、一个 Batch 训来源和标签两种分类任务。

上图像来源这块的分类结果示例,不同来源的图片,特征差异明显。
分类篇 | 细分类的应用
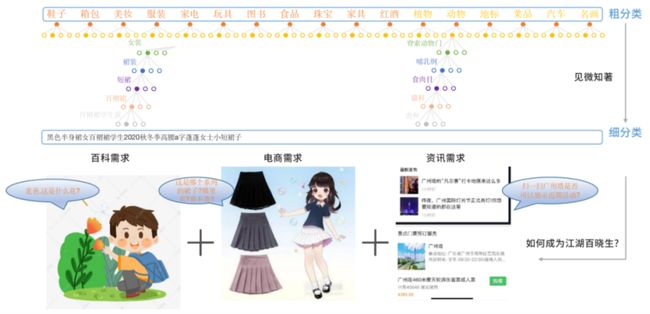
前面提到的图像标签,是一个粗分类的方法。我们只需要知道是一只狗,但不需要知道是蛤蟆狗,还是哈士奇。要真的能见微知著,通过一些细节来分辨物体具体的款式,这也是计算机视觉擅长的领域。实现细分类,总的来说,我们有两种做法。
电商场景:我们要识别的集合是无限大的,而且还是动态的。所以我们是通过动态图像召回。从召回的结果上推断出商品的具体款式。
动植物汽车这种场景:集合是相对固定的。而且需要一些专业的数据库。我们采用分类+检索的方法,在具体的处理逻辑上,也依据具体的场景不同而不同。目前我们支持了动物/植物/菜品/地标/汽车/名画/红酒识别。
检测篇 | 移动端主体检测

在微信识物中,我们需要在移动端构建一套图像采集的 SDK。首先我们基于运动估计中的光流追踪方法,先判断用户手机是否处于静止状态,如果已经静止则会从 camera 的图片序列中,根据图像梯度的方法,选出较为清晰的帧,再用深度模型进行主体检测,如果检测到有物品,进行裁剪后再发送到后台,后台返回后还会做一些纠正后处理。整个过程中难点在于实现一个轻量级的移动端物体检测模型。
我们基于 centernet 的方法,并基于移动端的场景进行专项优化,如大感受野、轻检测头、改进可形变卷积在移动端的实现等。最终我们的方法与主流方法在 ms-coco 上对比,在 MAP 相当的情况下,参数量只有 1M,大大降低。在 iphone 下测试,每帧只需 25ms.。从上图可以看出,扫描模型改进版,有效提高了扫描速度,节省 3 倍流量。
检测篇 | 服务端物品检测

移动端是 objness 的无类别主体检测,服务端则更倾向于 class-wise 的目标检测。我们既要支持商品类目,又需同时识别出各种自然场景。故我们基于 maskrcnn 的训练框架,改进 RetinaNet 成为双流的 RetinaNet, 一条流用于商品的精确位置和类别输出,一条流只用于分类自然场景图片,以便快速拓展更新模型。
检测篇 | 目标检测的应用

在微信界面中,我们看到识别的主体上,有个小绿点。这个就是目标框的中心点。在识图中,我们看到 query 头部,有多个主体,这是更直接的目标检测出来的 bbox。
目标检测算法对于 Query 理解,去除背景干扰,理解多主体,还有压缩源数据的基础算法能力。

在我们离线构建检索库的过程中,检测器会检出非常多的目标,这里会包含很多的噪声目标,如图中还会检出鞋子、上衣等。我们最后会根据标题 NER 后的主体,还有所有 bbox 之的聚类结果,来决定商品最后的 bbox 是哪些。
以图搜图本质上是寻找度量图像之间距离的方法,这个距离的表示有很多维度。

所以这里的核心工作之一,就是寻找一个强大的特征表达,可以跨越不同视角,不同装扮下的 gap,让我们探寻事物的本质,更靠近任务的目标。一开始在重复图任务上,我们还会使用 ORB,SIFT,SURF 这些局部特征,再使用像 BOW、VLAD、Fisher Vector 这些方法,把多个局部特征聚合成一个统一维度的向量表示,以利于检索的工程化。但当我们积累了足够多的同款数据后,CNN 的方法在平面图上的表达能力,也已远超传统的图像方法。
关于 CNN 特征学习的探索,在《微信扫一扫识物技术的从 0 到 1》一文中已有全面的论述。我们的另一块核心工作,是解决大规模数据下带来的挑战。
检索篇 | 大规模检索系统之分库实现

以微信图片搜索为例,每天新入库图片达 500w 张,我们收录半年的数据,就有近 9 亿张图片。我们的思路是多机多库的拆解方法,先把数据在离线阶段分成多个库,在线召回为了减少检索耗时,我们只检索其中几个库,这时候需要做智能的路由。最后根据召回的结果,进行类目预测。
检索篇 | 识物引擎系统框架

1.分库:以微信识物为例,这里的分库比较简单,直接按商品大类划分,比如箱包、美妆、食品这些,一共有 12 大类。
检索篇 | 识物引擎之分库路由

2.路由:那么当一个 query 到来时候,我们去检测哪个库呢?这就涉及到路由的逻辑。
前面提到服务端的检测是带有类别的,比如图中输出鞋子,那么我们就走鞋子的专用检索模型提取特征,再到鞋子库中检索。这是最朴素的版本。然而现实场景中的真实的数据分布往往是离散,且存在较大交叉边界的,这会导致以下问题。
检索的开集问题,比如未出现过的子类容易分错;
类间混淆性,从视觉上存在歧义。
检索篇 | 识物引擎之类目预测

基于我们前面提到的数据分布,我们首先从分类好的商品库中,采样出图片进行聚类,通过聚类堆中包含商品类目的多少,把所有的堆分成 clean cluster 和 dirty clean。如上图所示,clean cluster 代表商品图是容易从视觉上分类的,都是鼠标。而 dirty clean 则代表不容易视觉区分,都是一些相似的瓶瓶罐罐。相应的,clean 的图一般只需检索 1-2 个类目库,而 dirty 的图需要检索 4-5 个类目库。简单讲,我们实现了一个动态 topk 检索的优化。从最终优化效果看,在平均检索次数更低的情况下,实现了更高的类别准确率。
3.类目预测:由于每个库都是专有模型,特征之间是可以度量的。于是我们引入了一个精排模型,可以度量所有商品图片的距离,统一对多库召回的结果作归一化。最后我们会结合 query 图的分类检测结果,召回结果的图像精排特征,以及相关的结果图像及结果一致性,通过一个 MLP 网络进行类目预测,同款归纳等后处理。
检索篇 | 通用以图搜图之无监督的分库

上面提到的是识物的检索方案实现,回到通用的以图搜图场景,我们无法简单的把图片定义成 N 个库出来,所以我们用了无监督的分库方法。
1.分库:基于 moco 这种无监督的对比学习方法,得到图片一个向量表示。再通过聚类的方法产生伪标签,如下面的 16 个标签。可以看出,相同 topic 的图片,会被尽量分到同一个库中。
检索篇 | 图搜流程框架
2.路由:在离线流程中,我们把所有的图片通过上述的分库方法,分成了 16 个库。在线检索的时候,路由层会预测 query 图的标签,只走 top3 的分库。最后通过一个统一多库精排模型,把召回结果融合到一起。
结语
从识物到识图,我们不断扩大计算机视觉所能感知的范围。从技术上我们日趋完善,逐渐搭建起从数据采集->半自动化清洗->训练->上线->反馈优化的 pipeline,从基础的分类检测到各类应用层的算法,从移动端部署到大规模 GPU 集群。另一方面,基于微信的图片应用场景,我们开拓出了微信识物、长按识图等新的尝试入口。相信紧贴用户场景,通过技术的不断沉淀积累,一定可以孕育出更多的智能产品。