Pandas系列(四):数据处理
Pandas系列目录
文章目录
- 一、 简介
- 二、 思维导图
- 三、 Pandas数据处理
-
- 1. 排序
- 2. 数据整理
-
- 2.1 数据重塑
-
- 2.1.1 改变形状
- 2.1.2 合并拼接
- 2.1.3 数据透视
- 3. 分组、聚合及窗口函数
-
- 3.1 分组
- 3.2 聚合
- 3.3 窗口函数
- 3.4 上下限规整
- 3. 函数应用
-
- 3.1 transform(对每个元素执行函数)
- 3.2 apply(沿行或列执行函数)
- 3.3 map(只能对Series执行函数)
- 3.4 applymap(只能对DataFrame执行函数)
- 3.5 pipe(运算时可以指定参数)
- 3.6 eval
- 4. 统计
-
- 4.1 简单统计量
- 4.2 统计量
- 4.3 相关性
一、 简介
对数据进行排序、数据形状重塑(转置、合并、拼接),进行分组、聚合、统计等操作。
Pandas系列将Pandas的知识和重点API,编制成思维导图和重点笔记形式,方便记忆和回顾,也方便应用时参考,初学者也可以参考逐步深入学习。
二、 思维导图
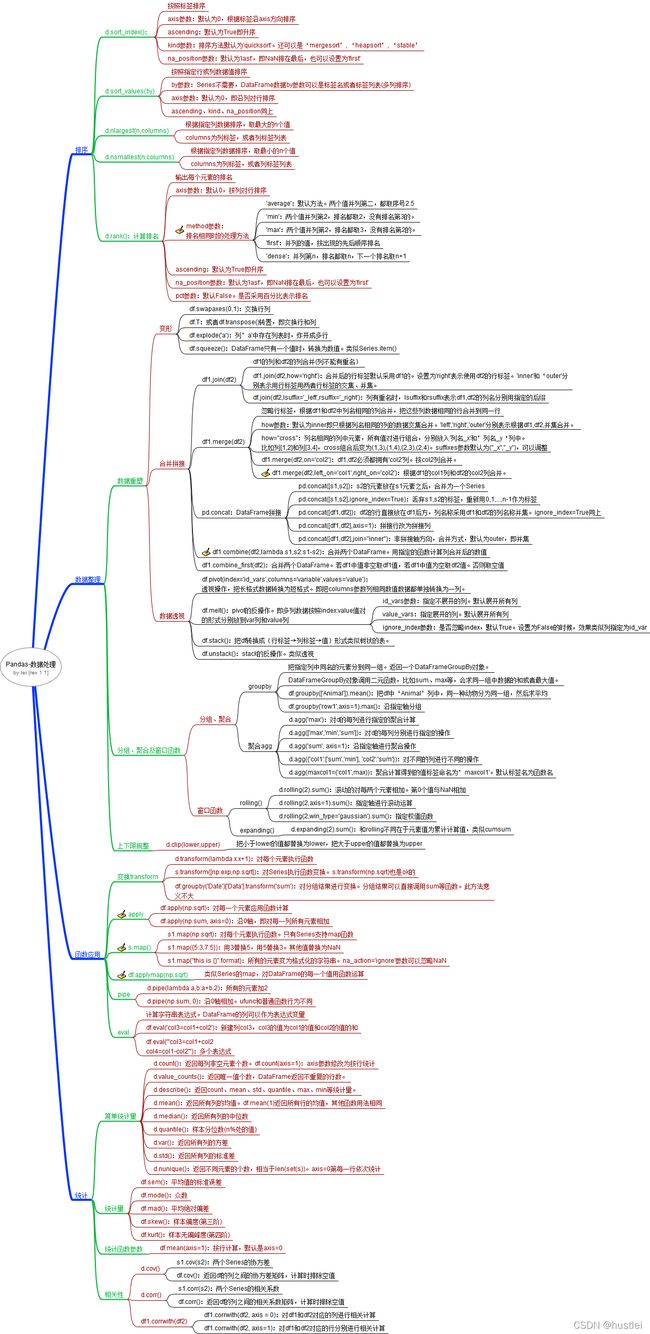
三、 Pandas数据处理
1. 排序
排序
- d.sort_index():按照标签排序
- axis参数:根据标签沿axis方向排序。默认为0,即对行排序。
- ascending:默认为True即升序
- kind参数:排序方法默认为’quicksort’。还可以是‘mergesort’, ‘heapsort’, ‘stable’
- na_position参数:默认为’last’,即NaN排在最后,也可以设置为’first’
d.sort_values(by):按照指定行或列数据值排序- by参数:行或列的名称。Series不需要指定。默认为列名称,可以是标签列表(多列排序)
- axis参数:默认为0,即沿列对行排序
- ascending、kind、na_position同上
d.nlargest(n,columns):根据指定列数据排序,取最大的n个值- columns为列标签,或者列标签列表
d.nsmallest(n,columns):根据指定列数据排序,取最小的n个值- columns为列标签,或者列标签列表
>>> df2
0 1
0 6 5
1 5 8
2 1 9
3 6 5
>>> df2.sort_values(0)
0 1
2 1 9
1 5 8
0 6 5
3 6 5
>>> df2.sort_index()
0 1
0 6 5
1 5 8
2 1 9
3 6 5
>>> df2.nlargest(1,columns=0)
0 1
0 6 5
排名计算
d.rank():计算排名,输出每个元素的排名- axis参数:默认0,按列对行排序
- method参数: 排名相同时的处理方法
- 默认是’average’,但是现实中最常用的是’min’,也有用’dense’的
- ‘average’:默认方法。两个值并列第二,都取序号2.5
- ‘min’:两个值并列第2,排名都取2,没有排名第3的。
- ‘max’:两个值并列第2,排名都取3,没有排名第2的。
- ‘first’:并列的值,按出现的先后顺序排名
- ‘dense’:并列第n,排名都取n,下一个排名取n+1
- ascending:默认为True即升序
- na_position参数:默认为’last’,即NaN排在最后,也可以设置为’first’
- pct参数:默认False。是否采用百分比表示排名
>>> df2
0 1
0 6 5
1 5 8
2 1 9
3 6 5
>>> df2.rank()
0 1
0 3.5 1.5
1 2.0 3.0
2 1.0 4.0
3 3.5 1.5
>>> df2.rank(method='min')
0 1
0 3.0 1.0
1 2.0 3.0
2 1.0 4.0
3 3.0 1.0
2. 数据整理
2.1 数据重塑
2.1.1 改变形状
- df.swapaxes(0,1):交换行列
- df.T:或者df.transpose()转置,即交换行和列
- df.squeeze():DataFrame只有一个值时,转换为数值。类似Series.item()
>>> df
0
0 5
>>> df.squeeze()
5
- df.explode(‘a’):列’a’中存在列表时,炸开成多行
>>> df
col1 col2
0 [1, 2] 4
1 [2, 4] 5
2 3 6
>>> df.explode('col1')
col1 col2
0 1 4
0 2 4
1 2 5
1 4 5
2 3 6
2.1.2 合并拼接
join按列合并
- df1.join(df2):df1的列和df2的列合并(列不能有重名)
- df1.join(df2,how=‘right’):合并后的行标签默认采用df1的。设置为’right’表示使用df2的行标签。'inner’和‘outer’分别表示用行标签用两者行标签的交集、并集。
- df.join(df2,lsuffix=’_left’,rsuffix=’_right’):列有重名时,lsuffix和rsuffix表示df1,df2的列名分别用指定的后缀
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df2
col3 col4
0 1 4
1 2 5
2 3 6
>>> df1.join(df2)
col1 col2 col3 col4
0 1 4 1 4
1 2 5 2 5
2 3 6 3 6
>>>
>>> df1.join(df3,lsuffix='_left')
col1 col2 0 1
0 1 4 6 5
1 2 5 5 8
2 3 6 1 9
>>> df1.join(df1,lsuffix='_left')
col1_left col2_left col1 col2
0 1 4 1 4
1 2 5 2 5
2 3 6 3 6
merge按列合并
- df1.merge(df2):忽略行标签,根据df1和df2中列名相同的列合并,把这些列数据相同的行合并到同一行
- how参数:默认为inner即只根据列名相同的列的数据交集合并。‘left’,‘right’,'outer’分别表示根据df1,df2,并集合并。
- how=“cross”:列名相同的列中元素,所有值对进行组合,分别放入’列名_x’和’列名_y‘列中。
- 比如列
[1,2]和列[3,4],cross组合后变为(1,3),(1,4),(2,3),(2,4)。suffixes参数默认为("_x","_y"),可以调整
- how参数:默认为inner即只根据列名相同的列的数据交集合并。‘left’,‘right’,'outer’分别表示根据df1,df2,并集合并。
- df1.merge(df2,on=‘col2’):df1,df2必须都拥有’col2’列。按col2列合并。
- df1.merge(df2,left_on=‘col1’,right_on=‘col2’):根据df1的col1列和df2的col2列合并。
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df2
col1 col4
0 1 4
1 2 5
2 3 6
>>> df1.merge(df2)
col1 col2 col4
0 1 4 4
1 2 5 5
2 3 6 6
无同名的列时。
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df2
col3 col4
0 1 4
1 2 5
2 3 6
>>> df1.merge(df2,left_on='col1',right_on='col3')
col1 col2 col3 col4
0 1 4 1 4
1 2 5 2 5
2 3 6 3 6
注意当df1的col1列和df2的col2列有重复值时的情况。
concat拼接
- Series拼接
pd.concat([s1,s2]):s2的元素放在s1元素之后,合并为一个Seriespd.concat([s1,s2],ignore_index=True):丢弃s1,s2的标签,重新用0,1,…,n-1作为标签
- DataFrame拼接
pd.concat([df1,df2]):df2的行直接放在df1后方,列名称采用df1和df2的列名称并集。ignore_index=True同上pd.concat([df1,df2],axis=1):拼接行改为拼接列pd.concat([df1,df2],join="inner"):非拼接轴方向,合并方式,默认为outer,即并集
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df2
col3 col4
0 1 4
1 2 5
2 3 6
>>> pd.concat([df1,df2])
col1 col2 col3 col4
0 1.0 4.0 NaN NaN
1 2.0 5.0 NaN NaN
2 3.0 6.0 NaN NaN
0 NaN NaN 1.0 4.0
1 NaN NaN 2.0 5.0
2 NaN NaN 3.0 6.0
>>> pd.concat([df1,df2],axis=1)
col1 col2 col3 col4
0 1 4 1 4
1 2 5 2 5
2 3 6 3 6
>>> pd.concat([df1,df2],join='inner') #合并轴为行,列方向df1、df2的列名并集为空
Empty DataFrame
Columns: []
Index: [0, 1, 2, 0, 1, 2]
注意只能通过pd调用concat方法,参数为列表
combine合并
df1.combine(df2,lambda s1,s2:s1-s2):用指定函数运算,合并两个DataFrame。- 函数的输入输出都是Series,对同名列进行运算得到新数据。必须指定函数
df1.combine_first(df2):合并两个DataFrame。若df1中值非空取df1值,若df1中值为空取df2值。否则取空值
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.combine(df1, np.add)
col1 col2
0 2 8
1 4 10
2 6 12
简单函数实际上和数学计算等效。
combine_first实际上也能够用df.where函数实现。
2.1.3 数据透视
对于同一中数据,我们在记录或者表示的时候,会经常遇到两种完全不同的形式:
1) 长格式
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121
.. ... ... ...
139 1960 Aug 606
140 1960 Sep 508
141 1960 Oct 461
142 1960 Nov 390
143 1960 Dec 432
- 短格式
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
year
1949 112 118 132 129 121 135 148 148 136 119 104 118
1950 115 126 141 135 125 149 170 170 158 133 114 140
1951 145 150 178 163 172 178 199 199 184 162 146 166
1952 171 180 193 181 183 218 230 242 209 191 172 194
1953 196 196 236 235 229 243 264 272 237 211 180 201
1954 204 188 235 227 234 264 302 293 259 229 203 229
1955 242 233 267 269 270 315 364 347 312 274 237 278
1956 284 277 317 313 318 374 413 405 355 306 271 306
1957 315 301 356 348 355 422 465 467 404 347 305 336
1958 340 318 362 348 363 435 491 505 404 359 310 337
1959 360 342 406 396 420 472 548 559 463 407 362 405
1960 417 391 419 461 472 535 622 606 508 461 390 432
两种格式数据表示内容相同,但是形式差异很大。在pandas中可以用pivot和melt格式对两种格式进行转换。
- df.pivot(index=‘id_vars’,columns=‘variable’,values=‘value’):透视操作,把长格式数据转换为短格式。
- 即把index参数列作为新数据的行标签(index),columns参数列相同数值数据作为一列。
- index参数:指定新数据的index。如果不指定,用原来数据的index。
- columns参数:必须指定。是要转换为行标签的列。
- values参数:要合并的数据列,不指定则转换所有列。(columns的列名赋值给新数据的columns.name)
df.pivot(index='year',columns='month',values='passengers')可以把前述长格式转为透视图,即短格式
- df.melt():pivot的反向操作,即把短格式转换为长格式。
- 即多列数据按照columnname:value值对的形式分别放到var列和value列
- id_vars参数:指定不展开的列。默认展开所有列
- ignore_index参数:是否忽略index,默认True。设置为False的时候,效果类似列指定为id_var
- value_vars:指定展开的列。默认展开所有列
- var_name和value_name是自定义设置对应的列名
df.melt(ignore_index=False, value_name="passengers")可以把前述短格式转为长格式
>>> df
col1 col2
0 1 4
1 2 5
2 3 6
>>> df.melt(ignore_index=False)
variable value
0 col1 1
1 col1 2
2 col1 3
0 col2 4
1 col2 5
2 col2 6
>>> _.pivot(columns='variable',values='value')
variable col1 col2
0 1 4
1 2 5
2 3 6
>>> df.melt()
variable value
0 col1 1
1 col1 2
2 col1 3
3 col2 4
4 col2 5
5 col2 6
>>> _.pivot(columns='variable',values='value')
variable col1 col2
0 1.0 NaN
1 2.0 NaN
2 3.0 NaN
3 NaN 4.0
4 NaN 5.0
5 NaN 6.0
- df.stack():把df转换成(行标签→列标签→值)形式类似树状的表。
- df.unstack():stack的反操作,类似透视。
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.stack()
0 col1 1
col2 4
1 col1 2
col2 5
2 col1 3
col2 6
dtype: int64
>>> _.unstack()
col1 col2
0 1 4
1 2 5
2 3 6
3. 分组、聚合及窗口函数
3.1 分组
分组函数groupby把指定列中同名的元素分到同一组。返回一个DataFrameGroupBy对象。DataFrameGroupBy对象调用二元函数,会对每一组进行汇总计算。比如sum、max等,会求同一组中数据的和或者最大值。
df.groupby(['animal']).mean():把df中‘Animal’列中,同一种动物分为同一组,然后求平均df.groupby('row1',axis=1).max():沿指定轴分组df.groupby(['animal'])['age'].mean():只计算指定列
>>> df5
animal count age
0 dog 1 3
1 cat 2 2
2 dog 3 4
3 cat 1 2
4 dog 2 5
>>> df5.groupby('animal').sum()
count age
animal
cat 3 4
dog 6 12
>>> df5.groupby('animal').max()
count age
animal
cat 2 2
dog 3 5
>>> df5.groupby('animal')['age'].max()
animal
cat 2
dog 5
Name: age, dtype: int64
3.2 聚合
聚合函数agg类似于python的reduce,会把Series中所有数据依次进行计算。
d.agg('max'):对d的每列进行指定的聚合计算d.agg(['max','min','sum']):对d进行多个聚合操作d.agg('sum', axis=1):沿指定轴进行聚合操作d.agg({'col1':['sum','min'], 'col2':'sum'}):对不同的列进行不同的操作d.agg(maxcol1=('col1',max)):聚合计算得到的值标签命名为’maxcol1’。默认标签名为函数名
和reduce函数相同,函数参数都必须是双输入单输出函数。
>>> df5
animal count age
0 dog 1 3
1 cat 2 2
2 dog 3 4
3 cat 1 2
4 dog 2 5
>>> df5.agg('max')
animal dog
count 3
age 5
dtype: object
>>> df5.agg(['max','min'])
animal count age
max dog 3 5
min cat 1 2
>>> df5.agg(maxage=('age',max))
age
maxage 5
函数名称参数,可以用字符串,也可以直接写函数名。即df.agg(max)和df.agg(‘max’)相同
3.3 窗口函数
窗口函数用数值n表示窗口,即对任意连续的n个数值进行聚合计算。
- rolling滚动窗口计算
d.rolling(2).sum():对每一列数据,滚动的对每两个元素相加。第0个值与NaN相加d.rolling(2,axis=1).sum():指定轴进行滚动运算d.rolling(2,win_type='gaussian').sum():指定权值函数
- expanding累加窗口计算
d.expanding(2).sum():和rolling不同在于元素值为累计计算值,类似cumsum
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.rolling(2).sum()
col1 col2
0 NaN NaN
1 3.0 9.0
2 5.0 11.0
>>> df1.expanding(2).sum()
col1 col2
0 NaN NaN
1 3.0 9.0
2 6.0 15.0
3.4 上下限规整
d.clip(lower,upper):把小于lower的值都替换为lower,把大于upper的值都替换为upper
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.clip(2,5)
col1 col2
0 2 4
1 2 5
2 3 5
3. 函数应用
3.1 transform(对每个元素执行函数)
transform主要用于对每个元素用指定的函数计算。
d.transform(lambda x:x+1):对每个元素执行函数s.transform([np.exp,np.sqrt]):对Series执行函数变换。s.transform(np.sqrt)也是ok的df.groupby('animal')['age'].transform('sum'):对分组结果进行变换。分组结果可以直接调用sum等函数。此方法意义不大
groupby后的transform参数为双输入单输出函数。
其他transform函数只能是单输入单输出函数。
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.transform(np.exp)
col1 col2
0 2.718282 54.598150
1 7.389056 148.413159
2 20.085537 403.428793
>>> df1.transform([np.exp,np.sqrt])
col1 col2
exp sqrt exp sqrt
0 2.718282 1.000000 54.598150 2.000000
1 7.389056 1.414214 148.413159 2.236068
2 20.085537 1.732051 403.428793 2.449490
3.2 apply(沿行或列执行函数)
沿行或列执行函数
- df.apply(np.sqrt):对每一个元素应用函数计算
- df.apply(np.sum, axis=0):沿0轴,即对每一列所有元素相加
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.apply(np.sqrt)
col1 col2
0 1.000000 2.000000
1 1.414214 2.236068
2 1.732051 2.449490
>>> df1.apply(np.sum)
col1 6
col2 15
dtype: int64
3.3 map(只能对Series执行函数)
s.map(np.sqrt):对每个元素执行函数。s.map({5:3,7:5}):用3替换5,用5替换3。其他值替换为NaNs1.map("this is {}".format):所有的元素变为格式化的字符串。na_action='ignore’参数可以忽略NaN
3.4 applymap(只能对DataFrame执行函数)
df.applymap(np.sqrt):对DataFrame每一个元素执行函数。
类似Series的map,对DataFrame的每一个值用函数运算
3.5 pipe(运算时可以指定参数)
- python函数(对每个元素执行运算)
d.pipe(lambda a,b:a+b,2):所有的元素加2。2作为函数的参数,使得二参数函数变为单参数函数
- numpy的ufunc函数
d.pipe(np.sum, 0):沿0轴相加。ufunc和python函数行为不同
3.6 eval
计算字符串表达式。DataFrame的列可以作为表达式变量
df.eval('col3=col1+col2'):新建列col3,col3的值为col1的值和col2的值的和
计算多个表达式
`df.eval('''col3=col1+col2
col4=col1-col2''')`
4. 统计
4.1 简单统计量
- d.count():返回每列非空元素个数。df.count(axis=1):axis参数修改为按行统计
- d.value_counts():返回唯一值个数,DataFrame返回不重复的行数。
- d.describe():返回count、mean、std、quantile、max、min等统计量。
- d.mean():返回所有列的均值。df.mean(1)返回所有行的均值,其他函数用法相同
- d.median():返回所有列的中位数
- d.quantile(0.5):样本分位数(指定比例处的值)
- d.var():返回所有列的方差
- d.std():返回所有列的标准差
- d.nunique():返回不同元素的个数,相当于len(set(s))。axis=0第每一行依次统计
对于DataFrame数据,所有统计函数都可以用axis指定统计方向。df.mean(axis=1):按行计算,默认是axis=0
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.count()
col1 3
col2 3
dtype: int64
>>> df1.describe()
col1 col2
count 3.0 3.0
mean 2.0 5.0
std 1.0 1.0
min 1.0 4.0
25% 1.5 4.5
50% 2.0 5.0
75% 2.5 5.5
max 3.0 6.0
>>> df1.mean()
col1 2.0
col2 5.0
dtype: float64
>>> df1.nunique()
col1 3
col2 3
dtype: int64
4.2 统计量
- df.sem():平均值的标准误差
- df.mode():众数
- df.mad():平均绝对偏差
- df.skew():样本偏度(第三阶)
- df.kurt():样本无偏峰度(第四阶)
>>> df1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.sem()
col1 0.57735
col2 0.57735
dtype: float64
>>> df1.mode()
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.mad()
col1 0.666667
col2 0.666667
dtype: float64
>>> df1.skew()
col1 0.0
col2 0.0
dtype: float64
>>> df1.kurt()
col1 NaN
col2 NaN
dtype: float64
4.3 相关性
- 协方差
- s1.cov(s2):两个Series的协方差
- df.cov():返回df的列之间的协方差矩阵,计算时排除空值
- 相关系数
- s1.corr(s2):两个Series的相关系数
- df.corr():返回df的列之间的相关系数矩阵,计算时排除空值
- df1.corrwith(df2):对df1和df2对应的列进行相关计算
- df1.corrwith(df2, axis=1):对df1和df2对应的行分别进行相关计算
相关性计算是Series之间的计算
>>> df1 #两列都是线性的,斜率相同,所以相关协方差和相关系数都是1
col1 col2
0 1 4
1 2 5
2 3 6
>>> df1.cov()
col1 col2
col1 1.0 1.0
col2 1.0 1.0
>>> df1.corr()
col1 col2
col1 1.0 1.0
col2 1.0 1.0
>>> df1.corrwith(df1)
col1 1.0
col2 1.0
dtype: float64
Pandas系列目录
个人总结,部分内容进行了简单的处理和归纳,如有谬误,希望大家指出,持续修订更新中。
修订历史版本见:https://github.com/hustlei/AI_Learning_MindMap
未经允许请勿转载。