【数学建模】2022亚太赛A题 结晶器熔炼结晶过程序列图像特征提取与建模分析
2022亚太赛A题
- 1 前言
- 2 问题重述
- 3 问题一
-
- 3.1 数据处理
-
- 3.1.1 图像裁剪
- 3.1.2 提取红色部分
- 3.2 汉字提取
-
- 3.2.1 失败的例子
- 3.2.2 正确的例子
- 4 问题二
-
- 4.1 颜色特征提取
- 4.2 相邻序列图之间的动态差异
- 5 问题三
-
- 5.1 数据探索
- 5.2 回归分析
- 小结
- 附件
竞赛题目: 结晶器熔炼结晶过程序列图像特征提取与建模分析
Feature Extraction of Sequence Images and Modeling Analysis of Mold Flux Melting and Crystallization
1 前言
本文档主要包括了2022年亚太赛A题的求解过程,包含了代码以及运行成果的讲解
2 问题重述
**问题1:**利用图像分割识别或其他技术,自动提取每张图像左上角1号热电偶和2号热电偶的温度,并自动导入到附件2 3中对应的表格中(请编写分步技术操作文档),并制作温度-时间曲线图(1#丝温-2#丝温-时间图;1#导线平均温度-2#导线平均温度-时间图)。此外,1#线或2 #线的测试结果不准确。请指出并解释
问题2:根据图1中的6个节点图像,运用数字图像处理技术,研究并量化结晶器熔炼结晶过程中相邻序列图像之间的动态差异。在此基础上,对量化后的不同特性进行时间序列建模,并根据数学模型的仿真结果讨论结晶器熔炼结晶过程曲线
**问题3:**给定温度和时间的变化,以及问题2的研究结果,请建立数学模型,讨论温度和时间变化之间的函数关系以及结晶器熔炼结晶过程,并根据数值模拟结果讨论结晶器熔炼结晶动力学(温度、熔炼速率和结晶速率的关系)
3 问题一
附件1有562张结晶器熔剂熔化结晶的序列图像。采集实验开始时第110~671秒的序列图像。文件序列号按照采集时间顺序排列,每1秒采集一次图像。如下图所示,每幅图像的左上角标有图像对应的时间以及1号热电偶和2号热电偶的温度值。我们打印图像0110.bmp的大小为(1792,1316),图像的格式为BMP。
# 获取当前图片的大小和尺寸等信息
file_path = './Attachment 1/0110.bmp'
img = Image.open(file_path)
imgSize = img.size #大小/尺寸
w = img.width #图片的宽
h = img.height #图片的高
f = img.format #图像格式
print(imgSize) # 打印图像大小
print(w, h, f) # 打印宽、高、格式

3.1 数据处理
3.1.1 图像裁剪
为了方便提取图像中的温度信息,我们将图像进行了裁剪,裁剪后的尺寸为(72,128)。裁剪后的图像如下图所示。
# 尝试截图图片
img = cv2.imread('./Attachment 1/0110.bmp',1)
cutimg = img[0:72,0:128]
cv2.imshow('origin',img)
cv2.imshow('image',cutimg)
cv2.imwrite('cut.jpg',cutimg)
k=cv2.waitKey(0)
if k==27:
cv2.destroyAllWindows()

然后裁剪所有的图片,并保存到cut文件夹中(需要自己先创建一个叫cut的文件夹)
# 切割带有温度数据的部分并保存
img_path ='./Attachment 1/'
filelist = os.listdir(img_path)
for imagename in filelist:
image_path = img_path + imagename
img = cv2.imread(image_path, 1)
cutimg = img[0:72,0:128] # 高从0-72、宽从0-128
save_path = './cut/' + str(imagename)[:-4]+ '-v.bmp'
cv2.imwrite(save_path, cutimg)
3.1.2 提取红色部分
因为文字都是红色的,所以这里尝试将红色部分的文字单独提取出来。
我们将红色作为图像中的主要颜色,采用的阈值如下表所示:
| Hmin | Hmax | Smin | Smax | Vmin | Vmax |
|---|---|---|---|---|---|
| 0 | 10 | 45 | 255 | 46 | 255 |
提取后的图片如下图所示:

因为后续没有用到这个步骤,所以这部分大家就做个参考就行
3.2 汉字提取
3.2.1 失败的例子
pytesseract是基于Python的OCR工具,底层使用的是Google的Tesseract-OCR引擎,支持识别图片中的文字,支持jpeg, png, gif, bmp, tiff等图片格式,本文尝试使用pytesseract进行文字提取[文献1]。如下图所示,因为图片中含有中文,尽管已经安装了“chi_smi”中文语言包,但是识别效果仍然十分不理想。提取结果如下图所示

可以看到,存在着严重的乱码,而且后续有部分图片识别不出来,所以这部分操作就先不放出来了,后续我整理一下单独写一篇文档介绍如何使用这款开源工具,它的英文字符识别能力还是很强大的。
3.2.2 正确的例子
因此这里考虑使用一些比较成熟的OCR工具,比如下面的百度OCR
关于这个工具的本地安装和使用,未来会考虑更新教程
#测试百度在线图片文本识别包
#导入百度的OCR包
import time
from aip import AipOcr
if __name__ == "__main__":
#此处填入在百度云控制台处获得的appId, apiKey, secretKey的实际值
appId, apiKey, secretKey =['xxxx','xxxx','xxxx']
#注意appId, apiKey, secretKey需要自己设置,每个人不同
#创建ocr对象
ocr = AipOcr(appId, apiKey, secretKey)
img_path ='./cut/'
filelist = os.listdir(img_path)
for imagename in filelist:
image_path = img_path + imagename
with open(image_path, 'rb') as fin:
img = fin.read()
res = ocr.basicGeneral(img)
words_result = res['words_result']
result_txt=result_txt.append(pd.DataFrame({'words_result':[words_result],}),ignore_index=True)
time.sleep(1) # 不能调用太频繁,不然会报错
程序共计运行需要等待一段时间,识别结果如下图所示
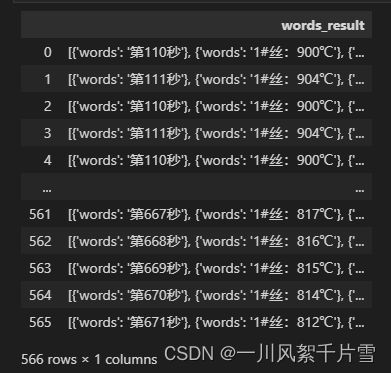
可以看到,该工具的识别效果是比较好的,将识别后的结果存在csv文件中,然后用excel自行提取需要的温度数据,需要该数据的同学可以私聊。
绘制2个热电偶的温度-时间曲线图,如下图所示
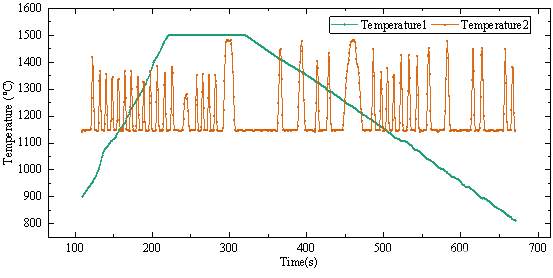
问题一的分析暂时到此结束。
4 问题二
4.1 颜色特征提取
在本文中分别计算了RGB每个通道的一阶、二阶、三阶颜色矩阵共计9个特征,其公式如下图所示。

式中Pij代表第i个颜色通道中第j个像素的像素值;N代表第i个颜色通道中像素的数量。
色差一般指的是由于色值不同或者放大率不同所造成的视觉颜色上的差异,本文将在Lab颜色空间对检索图片进行CIE色差计算。
from matplotlib import pyplot as plt
from skimage import data, exposure
import numpy as np
from scipy import stats
import os
from PIL import Image
from tqdm import tqdm
import cv2
import pandas as pd
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
im1 = Image.open("./example/red-0110.bmp")
print("im1的色彩模式为{}".format(im1.mode))
输出结果:im1的色彩模式为L
由于本文中的图像只包含了亮度一个颜色分量,因此将图像转换为RGB通道进行分析。
# 将图像转换为rgb格式
img_path = './Attachment 1/' #填入图片所在文件夹的路径
img_Topath = './rgb/' #填入图片转换后的文件夹路径
filelist = os.listdir(img_path)
for img_name in filelist:
image_path=img_path+img_name
img=Image.open(image_path)
img = img.convert("RGB")
img=np.array(img)
# print(img_name)
# print(img.shape)
cv2.imwrite(img_Topath +'/'+img_name,img)
下图为转换后的效果


# 计算三阶矩
def var(x=None):
mid = np.mean(((x - x.mean()) ** 3))
return np.sign(mid) * abs(mid) ** (1/3)
# 计算三阶矩
def var(x=None):
mid = np.mean(((x - x.mean()) ** 3))
return np.sign(mid) * abs(mid) ** (1/3)
def getimagedata(img_path2):
filelist2 = os.listdir(img_path2)
n = len(filelist2)
feature = np.zeros([n,9])
for i in range(n):
image_path2 = img_path2+filelist2[i]
image = Image.open(image_path2)
M,N = image.size
r,g,b = image.split()
rd = np.asarray(r)
gd = np.asarray(g)
bd = np.asarray(b)
feature[i,0] = rd.mean();feature[i,1] = gd.mean();feature[i,2] = bd.mean()
feature[i,3] = rd.std();feature[i,4] = gd.std();feature[i,5] = bd.std()
feature[i,6] = var(rd);feature[i,7] = var(gd);feature[i,8] = var(bd)
# 保存feature
return feature
img_path2 = './rgb/' #填入图片所在文件夹的路径
a = getimagedata(img_path2)
将提取的颜色特征存入csv文件
df = pd.DataFrame(a)
df.columns = ['r1','g1','b1','r2','g2','b2','r3','g3','b3' ]
df.to_csv('./data/rgb_3.csv', index=False)

4.2 相邻序列图之间的动态差异
为了比较每个状态之间各特征的差异性,将110s的数据记为State1,将141s的数据记为State2,将149s的数据记为State3,将150s的数据记为State4,将671s的数据记为State5。绘制各特征在各个状态之间的变化趋势,如下图所示。
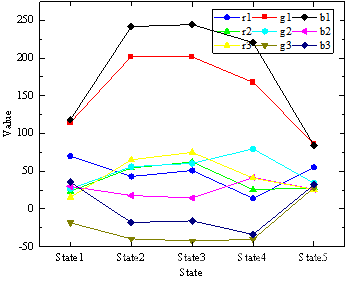
同理,将每一时刻的9个特征进行可视化,如下图所示。

然后各位同学就可以利用上述特征进行进一步分析了
5 问题三
5.1 数据探索
关于这部分的分析,之前已经进行讲解过了,所以此处仅放出了部分重要代码
2022数维杯国际赛C题 如何利用脑结构特征和认知行为特征诊断阿尔茨海默病
读取问题二中的保存的“rgb_3_temp.xlsx”文件,数据的形状为:562 rows × 12 columns。计算除Time列之外的各列数据的平均值、标准差等统计量信息如下图所示。

我们绘制该数据的箱线图,检查数据的异常值分布,如下图。

从上图中可以可以看到,特征r3存在着较多的异常值。绘制每个特征的直方图与Q-Q图,检查数据是否近似符合正态分布。

将Temperature2删除,构建颜色特征和热电偶1的数据集train_data1,同理将Temperature1删除,构建颜色特征和热电偶2的数据集train_data2。分别检查各颜色特征与温度的线性关系,如下图所示。

各变量与温度1的线性关系
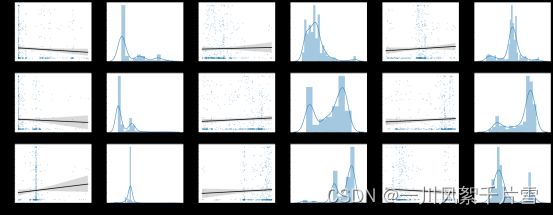
变量与温度2的线性关系
可以看到,各特征与温度并没有明显的线性关系,也就是说,直接采用颜色特征对温度进行回归不会取得太好的效果,下面的实验也验证了我们这一猜想。分别绘制个各特征与温度1和温度2的相关性,如下图所示。


从上图可以看到,温度2与各个特征的相关性非常小,因此我们绘制与温度1中相关性大于0.5的特征,如下图所示

将train_data1进行归一化,归一化的各特征结果如下图所示:

5.2 回归分析
本文中选择了5种机器学习模型,分别为线性回归、K近邻回归、决策树回归、随机森林回归,LightGMB回归分析。预测结果以Mean Squared Error(MSE)作为评判标准,结果如下所示:
# 多元线性回归模型
clf = LinearRegression()
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("LinearRegression: ", score)
# knn
clf = KNeighborsRegressor(n_neighbors=3) # 最近三个
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("KNeighborsRegressor: ", score)
# Decision Tree
clf = DecisionTreeRegressor()
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("DecisionTreeRegressor: ", score)
# RandomForest
clf = RandomForestRegressor(n_estimators=200) # 200棵树模型
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("RandomForestRegressor: ", score)
# lgb回归模型
clf = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=5000,
boosting_type='gbdt',
random_state=2019,
objective='regression',
)
# 训练模型
clf.fit(
X=train_data, y=train_target,
eval_metric='MSE',
verbose=50
)
score = mean_squared_error(test_target, clf.predict(test_data))
print("lightGbm: ", score)
| 模型 | MSE |
|---|---|
| LR | 4484.33 |
| KNN | 693.87 |
| Decision Tree | 371.34 |
| Random Forest | 130.13 |
| LGB | 88.88 |
此外本文尝试了对LGB进行网格调优
# lgb回归 网格寻优
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import (cross_val_score, train_test_split,
GridSearchCV, RandomizedSearchCV)
from sklearn.metrics import r2_score
from lightgbm.sklearn import LGBMRegressor
hyper_space = {'n_estimators': [5000, 1500, 2000, 2500],
'max_depth': [4, 5, 8, -1],
'num_leaves': [15, 31, 63, 127],
# 'subsample': [0.6, 0.7, 0.8, 1.0],
# 'colsample_bytree': [0.6, 0.7, 0.8, 1.0],
'learning_rate' : [0.01,0.02,0.03,0.01]
}
est = LGBMRegressor(n_jobs=-1, random_state=2018)
gs = GridSearchCV(est, hyper_space, scoring='r2', cv=4, verbose=1)
gs_results = gs.fit(train_data, train_target)
print("BEST PARAMETERS: " + str(gs_results.best_params_))
print("BEST CV SCORE: " + str(gs_results.best_score_))
输出结果为:BEST PARAMETERS: {‘learning_rate’: 0.03, ‘max_depth’: 4, ‘n_estimators’: 5000, ‘num_leaves’: 15} BEST CV SCORE: 0.9950322167558974
最终的MSE为:81.1520849401167,可以看到相较于上文中的模型,性能得到了些许提升。
可以看到,即使是效果最好的LGB模型,MSE也有将近90的取值。这说明仅仅靠颜色特征并不能很好地对温度进行预测。因此还需要查阅相关专业文献,构建效果更为良好的模型模型。
小结
本文的一些中间过程,以及处理结果,在竞赛结果公布之后会上传到这里共享。
由于问题较为专业,本文仅仅进行了一些初步的探索,如有疑问可以一起交流思路
由于文章中不能放联系方式,如对上述问题有疑问可私信
转载请注明出处
附件
待整理