【点云系列】PointContrast:Unsupervised Pre-training for 3D point cloud understanding
文章目录
- 1. 概要
- 2. Motivation
- 3. 思想
- 4. 算法
-
- 4.1 回顾全卷积几何特征(FCGF)
- 4.2 PointContrast
- 4.3 对比学习损失设计
- 4.3 稀疏残差U-Net作为共享骨架
- 5. 实验结果
-
- 5.1 ShapeNet:
- 5.2 S3DIS分割
- 5.3 SUN RGB-D检测
- 5.4 Synthia4D 分割
- 5.5 ScanNet:分割和检测
- 6. 总结与思考
1. 概要
题目:PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding
论文:https://arxiv.org/abs/2007.10985
代码:暂未公布
2. Motivation
迁移学习,在图像领域, 先用模型在一个比较大的的数据集(例如ImaegNet)做预训练,然后用预训练好的参数作为模型初始值,在特定任务的小数据集上训练,有助于提升性能。
这个经验,本质上相当于用大的数据集,先训练出来一个“比较好的、通用一点的”的特征提取器,然后在小数据集上对特征提取器进行微调修正让其能在小数据集上表现的更好。
但是在3D点云理解还所知甚少。因此,是否其在3D点云理解当中也一样有效?也即想要在3D表达学习当中尝试看,一个预训练的非监督学习在微调的监督度学习智商,是否有助于提升性能。
3. 思想
目的:通过在深度学习中对在有监督的微调之上的无监督的预训练进行研究,推动对3D场景理解的研究。因此需要4个重要元素:
- 选择可以预训练的大规模数据集;
—>ScanNet - 识别骨架结构,可以被许多不同的任务来共享;
—> 稀疏残差 U-Net - 评估骨干网络预训练的两个无监督指标;
—> Hardest-contrastive loss + PointInfoNCE loss - 定义对一组不同小型/子数据集和任务的评估协议。-
–>语义分割:S3DIS,ScanNetV2,ShapeNetPart,Synthia 4D
–>目标检测: SUN RGB-D, ScanNetV2
主体依赖于全卷积几何特征(FCGF),以及无监督学习3D表达的思想,
在此基础上重新设计并提出来PointInfoNCE Loss + U-net 框架
4. 算法

从上图似乎可以发现,shapenet预训练对于downstream没有帮助,可能原因有两点:
- 原域和目标域差距:由于ShapeNet中的物体是合成的,在尺度上归一化过,动作都是校准后的,缺乏场景上下文。这使得预训练和精细调参后的数据分布明显不同;
- 点级别的表示:在3D深度学习中,局部集合特征,例如局部点和其临近点都对3D类任务非常有效。但直接在目标实例上获取全局特征可能还是不够的;
问题1可以通过改用scannet数据集来得到解决;
问题2呢?即PointContrast
4.1 回顾全卷积几何特征(FCGF)
对于FCGF[10],其用来学习低层任务(例如:校准)的几何特征。
其有两个关键元素实现好结果:
- 全卷积设计;
- 点级别的学习;
但是FCGF关注与低层次任务的局部描述子的学习,其是否可以在高层次3D理解里面依然使用FCGF?
4.2 PointContrast
高层级策略:对比学习-点级别的-在两个转换的点云中。
如图所示,
- 在ScanNet的某个场景中,通过两个不同的视角 x 1 x^1 x1和 x 2 x^2 x2,坐标对齐, 然后计算两者对应映射 M M M, 如果 ( i , j ) ∈ M (i,j)\in M (i,j)∈M, 则 x i 1 x^1_i xi1与 x j 2 x^2_j xj2是两个视图中匹配点对。得到两个点云。两个点云要保证至少30%的点重合。
- 采样得出两个变换矩阵,调整点云。只包含刚体变换(缩放、旋转、移动)。
- 用一个共享的CNN网络,对两个点云,计算出每个点的局部特征。
- 通过对比两个点云中,匹配点的特征、非匹配点的特征,构建一个Point Contrast loss,“匹配点对”之间的特征接近、“非匹配点对”之间的特征远离。

转换的作用:使得pretext更具挑战性。一般有:旋转、平移、缩放

4.3 对比学习损失设计
最小化 匹配点
最大化不匹配点
最难-对比损失:借鉴FCGF【10】

其中 P P P是来自两个视图 x 1 x^1 x1和 x 2 x^2 x2中的 匹配对,而 f i 1 f^1_i fi1与 f j 2 f^2_j fj2是匹配对里两个点特征。 N \mathcal{N} N是随机采样的非匹配对点用作最难负挖掘,定义为 L 2 L_2 L2特征范式中距离匹配对中最近的样本。 [ x ] + [x]_+ [x]+是函数 m a x ( 0 , x ) max(0,x) max(0,x), m p = 0.1 m_p=0.1 mp=0.1, m n = 1.4 m_n=1.4 mn=1.4是对应匹配对和非匹配对的margins。
PointInfoNCE loss:
来源于InfoNCE【42】,其广泛应用于2D视觉理解当中的非监督关系学习。建模对比学习框架为一个字典查找表的过程,InfoNCE将对比学习看成是一个分类问题,且使用Softmax 损失来实现。特别地,损失促使队列 q q q与其正值 k + k^+ k+相似而与其负值 k − k^- k−不相似。其中一个挑战是负值的尺度。
3D当中面临不同的问题:点数众多,实例很少。因而,我们提出了基于点级别的信息损失 PointInfoNCE:

其中, P P P是所有匹配对。该公式考察拥有至少一个匹配且不需要额外非匹配点的这些点。
对于匹配点对 ( i , j ) ∈ P (i,j)\in P (i,j)∈P, 特征 f i 1 f^1_i fi1作为队列, f j 2 f^2_j fj2作为匹配正样本值 k + k^+ k+。通常我们采样4096个点为了快速训练。
该损失与最难对比损失类似,但是有更少的参数。且对于模型坍塌更具鲁棒性。且在训练中我们发现最难对比损失是不稳定的且难以训练。
4.3 稀疏残差U-Net作为共享骨架
34层U-Net[51],其中21个卷积层为编码层,13个卷积层为解码层。遵从2DResNet级别块设计原则,使用BN,和ReLU激活。
在这里主要是为了探索是否该框架可以作为统一设计,对于预训练任务和其他精修任务有效。

5. 实验结果
大量的实验,非常充实
首先开篇就给出了在多个子任务中使用PointContrast都有一定程度的提升。

5.1 ShapeNet:
设置:ShapNet是有55个类的合成3D目标,从开源3D仓库中使用CAD模型收集到的。[77]给ShapeNet中一个子集分割了2-5个部分。本文使用ShapeNetCore(SHREC 15 split)来做分类,ShapeNet part数据集做分割。我们从每个分类数据集的每个模型中均匀采样1024个点,部件分割中采样2048个点。
结果:在ShapeNet分类上,可以发现使用较少训练数据,提升幅度较大。ShapeNet当中类别不均衡,个别类很少见,会导致不均衡的表现,使用预训练的部分后明显减弱了这种不均衡情况。

在分割上也有类似的效果
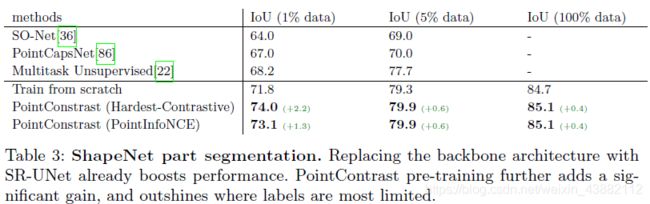
5.2 S3DIS分割
设置:Standford Large-Scale 3D Indoor Spaces(S3DIS)[2]数据集包括6大类来自3个建筑物的室内场景。点云表示,用13个物理类别来标注语义信息。这里评估方式与ScanNet类似。
区别:240样本用来训练。其中,使用了[9]做预训练,标准数据来做数据增强。
结果:更换骨架网络后,效果依然较好。

5.3 SUN RGB-D检测
设置:现在我们尝试不同高层级3D理解任务:目标检测。与分割任务需要点的标签相比,3D目标检测预测边框(位置)和对应目标标签(识别)。这就需要修改框架,由于SR-UNet不输出边框。 这里使用VoteNet[45]作为好的候选框,原因:
- VoteNet 直接应用于点云,不需要其他输入;
- VoteNet使用PointNet++作为骨架来提取特征。将这部分使用SR-UNet来替代需要小的修改,使得提取框流程完整。可以冲使用相同超参数;
- VoteNet是当前仅使用几何特征,来做校准。
SUNRGB_D 是手机单视角RGB-D图像,37个类别。包括5K图像,标注边框,
结果:使用SR-UNet框架较为原始使用PointNet++的VoteNet要差一些。但是通过PointContrast,效果有所提升。

5.4 Synthia4D 分割
设置:Synthia4D[52]是大型合成数据集,用于促进在驾驶场景中进行视觉推断的深度神经网络训练。逼真的效果图来自虚拟城市,有13个语义标注类,密集且准确。使用[9]的设置。由于其余我们的与训练集相差甚远(室外 vs 室内,合成 vs真实)。我们使用3D SR-UNet逐针检测性能。
结果:可以看出使用PointInfoNCE损失要比Hardest-Contrative损失好。增加非监督预训练,整体效果均有所提升。注意到[9]当中提出,增加时域性学习(e.g.使用4D网络而不是3D)能带来增益。对于4D网络,我们可以将问题简化为简单膨胀卷积核,想2D视频识别里面一样[6],留作后续工作。

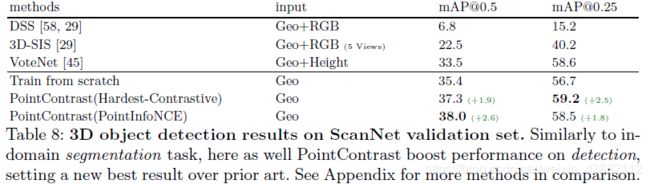
5.5 ScanNet:分割和检测
设置: 分割中:使用SR-UNet直接预测点标签;
检测中,遵循VoteNet[45],使用SR-UNet简单转换原始骨架来检测头部。
结果:如图7和8,使用PointContrast都有效果提升。

6. 总结与思考
- 表征学习最大motivation:能够很好的迁移到其他不同下属任务当中,所以学习一个强有力的表达,可以作为后续一直沿用的部分来使用。
- 关于监督学习:应该投入资源在构建大规模3D数据集来做预训练;如果要在缩放数据集大小和标注之间选择,应该选择增大数据及也即前者。
- 关于更久训练时长:大多数3D数据集都会崩塌[24],但预训练却有助于提升性能;
- 对PointContrast而言,整体场景作为一个单一视角:效果并不比多视角要好很多,这表明在PointContrast中多视角设置是至关中啊哟的。可能原因包括:多余的训练样本;由于相机不稳定带来的自然噪声等[81]。
- 整篇文章思路清晰,且实验充足。