Registration based Few-Shot Anomaly Detection
Registration based Few-Shot Anomaly Detection
paper:https://arxiv.org/abs/2207.07361
code:https://github.com/MediaBrain-SJTU/RegAD
摘要
目前为止,现有的FSAD研究遵循标准AD使用的每类别一个模型的学习范式,并且尚未探索类别间的共性。受人类如何检测异常的启发,通常将图像与正常图像进行比较,利用配准来训练类别无关的异常检测模型。测试时通过比较测试图像的配准特征和正常图像来识别异常。本文是第一个FSAD方法,训练单个可推广模型,不需要对新类别进行重新训练或微调。比目前方法AUC高3%~8%。
介绍
异常检测具有广泛的应用,由于异常的定义不明确,不可能用一组详尽的异常样本进行训练。
大多数现有的AD方法都集中于为每个类别训练专用模型。然而,在缺陷检测等现实场景中,鉴于要处理数百种工业产品,为每种产品收集大量培训集并不划算。
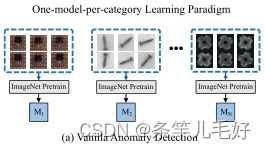
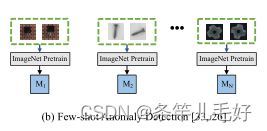
异常检测的少镜头学习已通过减少对训练样本需求的策略来实现,例如使用多重变换进行激进数据扩充,或使用更轻的正态分布估计估计器。然而,这种方法仍然遵循每类一个模型的学习范式,无法利用类间的共性。
本文旨在探索一种新的FSAD范式,通过学习多个类别之间共享的通用模型,也可推广到新类别,并受到人类如何检测异常的启发。当要求人类搜索图像中的异常时,一种简单的策略是将样本与正常样本进行比较,以找出差异。只要知道如何比较两个图像,图像的实际语义就不再重要。为了实现这种类似人类的比较过程,我们求助于配准,将不同图像转换为一个坐标系以进行更好的比较。
为了训练一个类别无关的异常检测模型,我们利用配准任务,使用具有三个空间变换网络块的孪生神经网络进行配准。为了获得更好的鲁棒性,没有像典型的配准方法对像素配准,而是通过最大化同一类的余弦相似性,在特征级进行配准。
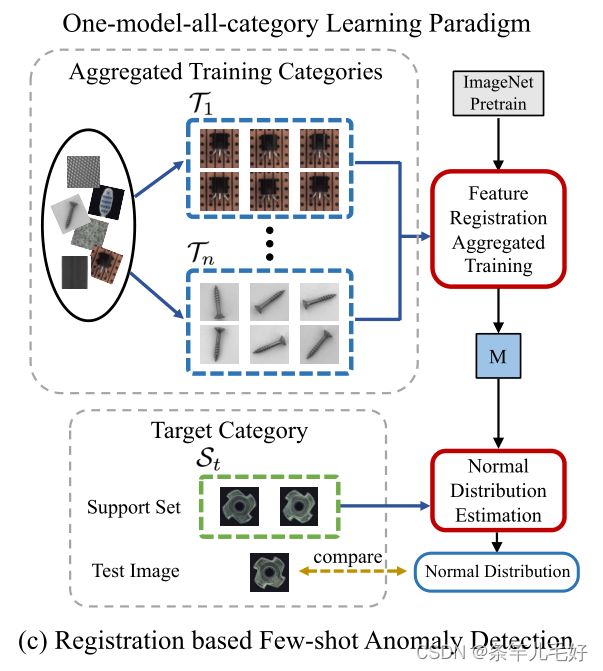
测试时,为样本提供由正常样本组成的支持集,使用基于统计的分布估计器估计目标的配准特征的正态分布,超出统计正态分布的测试样本被视为异常。这样,模型通过简单估计其正态特征分布而无需任何参数微调,从而快速适应新类别。
本文的贡献主要如下:
- 引入特征配准作为少样本异常检测(FSAD)的一种类别无关方法。据我们所知,这是第一种FSAD方法,可以训练单一的可推广模型,并且不需要对新类别进行再训练或参数微调。
- 在最近的基准数据集上进行的大量实验表明,所提出的RegAD在异常检测和异常定位任务上都优于最先进的FSAD方法。
相关工作
异常检测
少样本学习
少样本异常检测
FSAD旨在指示只有少数正常样本作为目标类别支持图像的异常。TDG[36]提出了一种分层生成模型,用于捕获每个支持图像的多尺度补丁分布。他们使用多个图像变换并优化鉴别器来区分真实和虚假的面片,以及应用于面片的不同变换。通过聚集正确变换的基于补丁的投票来获得异常得分。DiffNet[29]利用卷积神经网络提取的特征的描述性,使用归一化流估计其密度,这是一种非常适合从几个支持样本估计分布的工具。Metaformer[39]可以应用于FSAD,尽管在其整个元训练过程中(参数预训练之外)应使用额外的大规模数据集MSRA10K[7],以及额外的像素级注释。在本文中,我们设计了基于配准的FSAD来学习类别无关特征配准,使模型能够在给定一些正常图像的情况下检测新类别中的异常,而无需进行微调。
问题设置
对于FSAD,我们尝试仅使用少数正常图像作为支持集,从看不见/新类别的测试样本中检测异常。关键挑战在于:
- Ttrain只能访问来自多个已知类别(例如,不同对象或纹理)的正常样本,而没有任何图像级或像素级注释
- 测试数据来自一个看不见/新颖类别
- 只有来自目标类别ct的少数正常样本可用,使得难以估计目标类别ct的正态分布。
方法
在训练过程中,我们利用无异常特征配准网络学习类别无关特征配准。在测试过程中,给定几个正态图像的支持集,使用基于统计的分布估计器估计目标类别的配准特征的正态分布。超出学习的统计正态分布的测试样本被视为异常。
特征配准网络
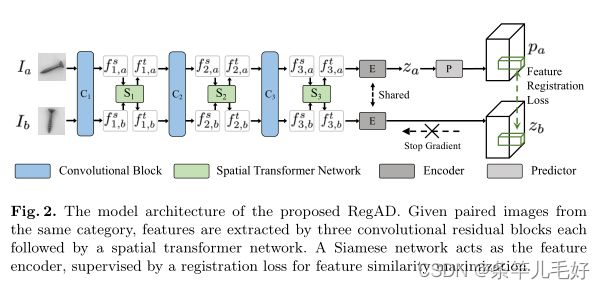
给定从训练集Ttrain的同一类别中随机选择的一对图像Ia和Ib,利用ResNet型卷积网络作为特征提取器。具体而言,如图2所示,采用ResNet的前三个卷积残差块C1、C2和C3,并丢弃ResNet原始设计中的最后一个卷积块,以确保最终特征仍保留空间信息。空间变换网络(STN)作为特征变换模块插入每个块中,以使模型能够灵活地学习特征配准。具体而言,变换函数Si(i=1,2,3)应用于输入特征f-Si:
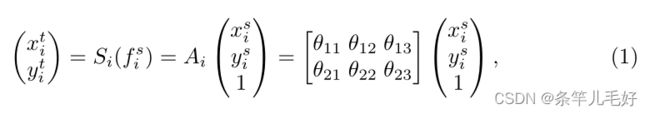
其中(xti,yti)是输出特征f ti的目标坐标,(xsi,ysi)是输入特征f si的源坐标中的相同点,Ai是仿射变换矩阵。模块Si用于从卷积块Ci的特征中学习映射。
给定成对提取的特征ft3a和ft3b作为最终变换输出,我们将特征编码器设计为孪生网络。孪生网络是应用于多输入的参数共享神经网络。特征ft3a和ft3b由相同的编码器网络E处理,然后在一个分支上应用预测头P,在另一个分支上停止梯度操作,防止此类崩溃。
表示pa≜ P(E(f3,a))和zb≜ 应用负余弦相似性损失:
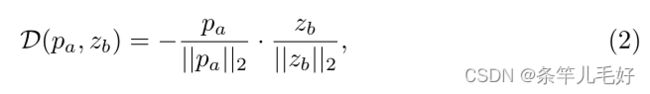
最后特征配准损失定义为:
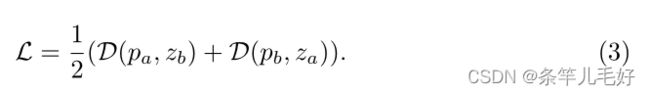
正态分布估计
由于孪生网络的两个分支完全相同,因此仅使用一个分支特征进行正态分布估计。在获得配准特征后,使用基于统计的估计器来估计目标类别特征的正态分布,该估计器使用多元高斯分布来获得正态类的概率表示。
假设图像被划分为(i,j)的网格∈ [1,W]×[1,H]位置,其中W×H是用于估计正态分布的特征的分辨率。在每个贴片位置(i,j),设Fij={f kij,k∈ [1,N]}是来自N个增强支持图像的注册特征。fij是贴片位置(i,j)处的聚合特征,通过将相应位置处的三个STN输出与上采样操作连接以匹配其大小来实现。假设Fij由N(µij,∑ij)生成,样本协方差为:
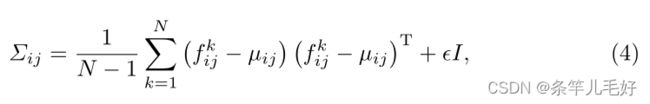
其中µij是Fij的样本均值,正则化项ϵI使样本协方差矩阵满秩且可逆。最后,每个可能的面片位置都与多元高斯分布相关联。
在本文中,我们强调数据扩充在扩展支持集方面起着非常重要的作用,这有利于正态分布估计。具体而言,我们对支持集St中的每个图像采用了增强,包括旋转、平移、翻转和灰度化。
推理
在推断过程中,超出正态分布的测试样本被视为异常。对于Ttest中的每个测试图像,我们使用马氏距离M(fij)为位置(i,j)的贴片给出异常分数,其中:
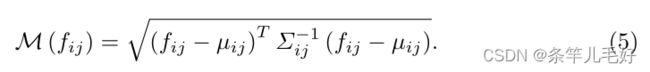
马氏距离矩阵M=(M(fij))形成异常图。对该异常图应用对应于三个STN模块的三个逆仿射变换,以获得与原始图像对齐的最终异常得分图。该图中的高分表示异常区域。整个图像的最终异常分数是异常图的最大值。
实验
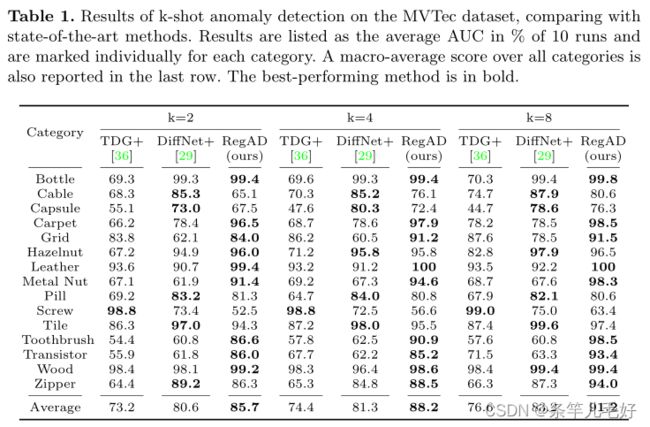
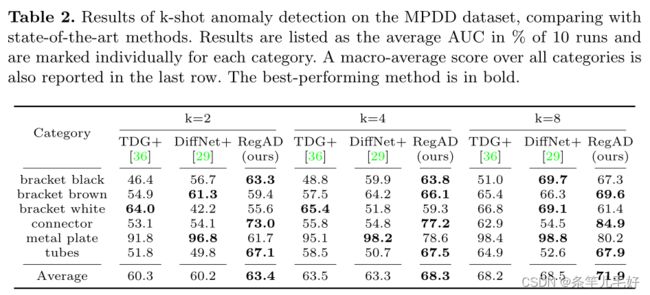
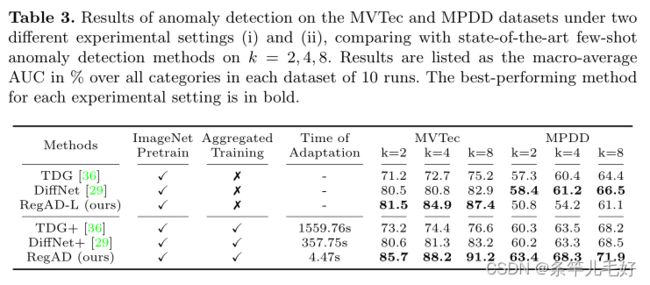
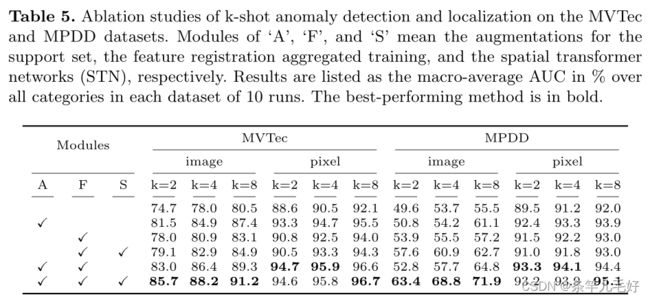
在MVTec和MPDD数据集上进行k-shot异常检测和定位的消融研究。“A”、“F”和“S”模块分别表示支持集、特征注册聚合训练和空间变换网络(STN)的增强。在10次运行的每个数据集中,结果以所有类别的宏观平均AUC%列出。表现最好的方法是粗体。
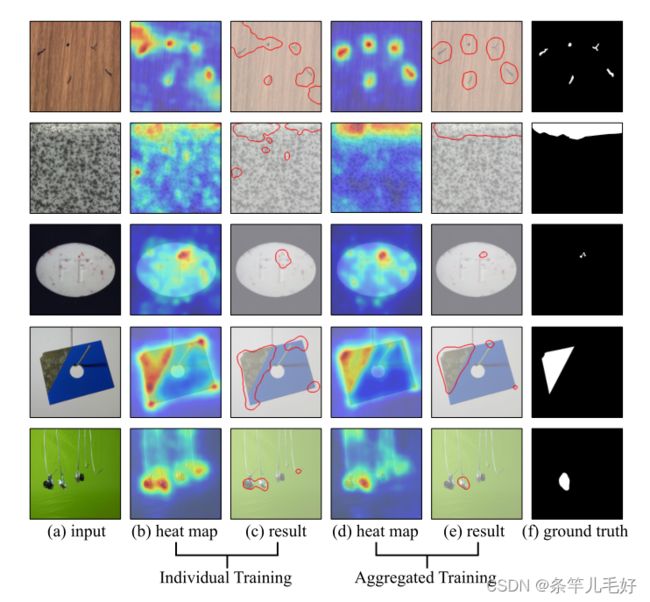

结论
本文提出了一种FSAD方法,利用配准实现跨类别概括特征,我们使用聚合数据训练类别无关的特征配准网络,可以直接推广到新类别,无需重新训练或参数微调,通过比较测试图像及其对应的支持图像的配准特征来识别异常。对于异常检测和异常定位,该方法显示出了竞争力。