【从零开始学习深度学习】3. 基于pytorch手动实现一个线性回归模型并进行min--batch训练
【从零开始学习深度学习】系列文章主要介绍以pytorch为基础的深度学习相关知识、神经网络模型等内容,感兴趣的小伙伴欢迎关注,共同学习交流哦~
上一篇文章我们讲了如何使用pytorch求解梯度,这篇文章介绍如何使用梯度计算自己手动实现一个线性回归模型。
目录
- 1.1 线性回归简介
-
- 1.1 线性回归的基本要素
-
- 1.1.1 模型定义
- 1.1.2 模型训练
-
- (1) 训练数据
- (2) 损失函数
- (3) 优化算法
- 1.1.3 模型预测
- 1.2 线性回归的表示方法
-
- 1.2.1 神经网络图
- 1.2.2 矢量计算表达式
- 2.2 线性回归的从零开始实现
-
- 2.2.1 生成数据集
- 2.2.2 读取数据
- 2.2.3 初始化模型参数
- 2.2.4 定义模型
- 2.2.5 定义损失函数
- 2.2.6 定义优化算法
- 2.2.7 训练模型
- 小结
1.1 线性回归简介
线性回归输出是一个连续值,因此适用于回归问题。回归问题在实际中很常见,如预测房屋价格、气温、销售额等连续值的问题。与回归问题不同,分类问题中模型的最终输出是一个离散值。我们所说的图像分类、垃圾邮件识别、疾病检测等输出为离散值的问题都属于分类问题的范畴。softmax回归则适用于分类问题。
由于线性回归和softmax回归都是单层神经网络,它们涉及的概念和技术同样适用于大多数的深度学习模型。我们首先以线性回归为例,介绍大多数深度学习模型的基本要素和表示方法。
1.1 线性回归的基本要素
我们以一个简单的房屋价格预测作为例子来解释线性回归的基本要素。这个应用的目标是预测一栋房子的售出价格(元)。我们知道这个价格取决于很多因素,如房屋状况、地段、市场行情等。为了简单起见,这里我们假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)。接下来我们希望探索价格与这两个因素的具体关系。
1.1.1 模型定义
设房屋的面积为 x 1 x_1 x1,房龄为 x 2 x_2 x2,售出价格为 y y y。我们需要建立基于输入 x 1 x_1 x1 和 x 2 x_2 x2 来计算输出 y y y 的表达式,也就是模型(model)。顾名思义,线性回归假设输出与各个输入之间是线性关系:
y ^ = x 1 w 1 + x 2 w 2 + b \hat{y} = x_1 w_1 + x_2 w_2 + b y^=x1w1+x2w2+b
其中 w 1 w_1 w1 和 w 2 w_2 w2 是权重(weight), b b b 是偏差(bias),且均为标量。它们是线性回归模型的参数(parameter)。模型输出 y ^ \hat{y} y^ 是线性回归对真实价格 y y y 的预测或估计。我们通常允许它们之间有一定误差。
1.1.2 模型训练
接下来我们需要通过数据来寻找特定的模型参数值,使模型在数据上的误差尽可能小。这个过程叫作模型训练(model training)。下面我们介绍模型训练所涉及的3个要素。
(1) 训练数据
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
假设我们采集的样本数为 n n n,索引为 i i i 的样本的特征为 x 1 ( i ) x_1^{(i)} x1(i) 和 x 2 ( i ) x_2^{(i)} x2(i),标签为 y ( i ) y^{(i)} y(i)。对于索引为 i i i 的房屋,线性回归模型的房屋价格预测表达式为
y ^ ( i ) = x 1 ( i ) w 1 + x 2 ( i ) w 2 + b \hat{y}^{(i)} = x_1^{(i)} w_1 + x_2^{(i)} w_2 + b y^(i)=x1(i)w1+x2(i)w2+b
(2) 损失函数
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。它在评估索引为 i i i 的样本误差的表达式为
ℓ ( i ) ( w 1 , w 2 , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 \ell^{(i)}(w_1, w_2, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2 ℓ(i)(w1,w2,b)=21(y^(i)−y(i))2
其中常数 1 2 \frac 1 2 21 使对平方项求导后的常数系数为1,这样在形式上稍微简单一些。显然,误差越小表示预测价格与真实价格越相近,且当二者相等时误差为0。给定训练数据集,这个误差只与模型参数相关,因此我们将它记为以模型参数为参数的函数。在机器学习里,将衡量误差的函数称为损失函数(loss function)。这里使用的平方误差函数也称为平方损失(square loss)。
通常,我们用训练数据集中所有样本误差的平均来衡量模型预测的质量,即
ℓ ( w 1 , w 2 , b ) = 1 n ∑ i = 1 n ℓ ( i ) ( w 1 , w 2 , b ) = 1 n ∑ i = 1 n 1 2 ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) 2 \ell(w_1, w_2, b) =\frac{1}{n} \sum_{i=1}^n \ell^{(i)}(w_1, w_2, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right)^2 ℓ(w1,w2,b)=n1i=1∑nℓ(i)(w1,w2,b)=n1i=1∑n21(x1(i)w1+x2(i)w2+b−y(i))2
在模型训练中,我们希望找出一组模型参数,记为 w 1 ∗ , w 2 ∗ , b ∗ w_1^*, w_2^*, b^* w1∗,w2∗,b∗,来使训练样本平均损失最小:
w 1 ∗ , w 2 ∗ , b ∗ = arg min w 1 , w 2 , b ℓ ( w 1 , w 2 , b ) w_1^*, w_2^*, b^* = \underset{w_1, w_2, b}{\arg\min} \ell(w_1, w_2, b) w1∗,w2∗,b∗=w1,w2,bargminℓ(w1,w2,b)
(3) 优化算法
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch) B \mathcal{B} B,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
在训练本节讨论的线性回归模型的过程中,模型的每个参数将作如下迭代:
w 1 ← w 1 − η ∣ B ∣ ∑ i ∈ B ∂ ℓ ( i ) ( w 1 , w 2 , b ) ∂ w 1 = w 1 − η ∣ B ∣ ∑ i ∈ B x 1 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) , w 2 ← w 2 − η ∣ B ∣ ∑ i ∈ B ∂ ℓ ( i ) ( w 1 , w 2 , b ) ∂ w 2 = w 2 − η ∣ B ∣ ∑ i ∈ B x 2 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) , b ← b − η ∣ B ∣ ∑ i ∈ B ∂ ℓ ( i ) ( w 1 , w 2 , b ) ∂ b = b − η ∣ B ∣ ∑ i ∈ B ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) . \begin{aligned} w_1 &\leftarrow w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial w_1} = w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\ w_2 &\leftarrow w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial w_2} = w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\ b &\leftarrow b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial b} = b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right). \end{aligned} w1w2b←w1−∣B∣ηi∈B∑∂w1∂ℓ(i)(w1,w2,b)=w1−∣B∣ηi∈B∑x1(i)(x1(i)w1+x2(i)w2+b−y(i)),←w2−∣B∣ηi∈B∑∂w2∂ℓ(i)(w1,w2,b)=w2−∣B∣ηi∈B∑x2(i)(x1(i)w1+x2(i)w2+b−y(i)),←b−∣B∣ηi∈B∑∂b∂ℓ(i)(w1,w2,b)=b−∣B∣ηi∈B∑(x1(i)w1+x2(i)w2+b−y(i)).
在上式中, ∣ B ∣ |\mathcal{B}| ∣B∣ 代表每个小批量中的样本个数(批量大小,batch size), η \eta η 称作学习率(learning rate)并取正数。需要强调的是,这里的批量大小和学习率的值是人为设定的,并不是通过模型训练学出的,因此叫作超参数(hyperparameter)。我们通常所说的“调参”指的正是调节超参数,例如通过反复试错来找到超参数合适的值。在少数情况下,超参数也可以通过模型训练学出。
1.1.3 模型预测
模型训练完成后,我们将模型参数 w 1 , w 2 , b w_1, w_2, b w1,w2,b 在优化算法停止时的值分别记作 w ^ 1 , w ^ 2 , b ^ \hat{w}_1, \hat{w}_2, \hat{b} w^1,w^2,b^。注意,这里我们得到的并不一定是最小化损失函数的最优解 w 1 ∗ , w 2 ∗ , b ∗ w_1^*, w_2^*, b^* w1∗,w2∗,b∗,而是对最优解的一个近似。然后,我们就可以使用学出的线性回归模型 x 1 w ^ 1 + x 2 w ^ 2 + b ^ x_1 \hat{w}_1 + x_2 \hat{w}_2 + \hat{b} x1w^1+x2w^2+b^ 来估算训练数据集以外任意一栋面积(平方米)为 x 1 x_1 x1、房龄(年)为 x 2 x_2 x2的房屋的价格了。这里的估算也叫作模型预测、模型推断或模型测试。
1.2 线性回归的表示方法
我们已经阐述了线性回归的模型表达式、训练和预测。下面我们解释线性回归与神经网络的联系,以及线性回归的矢量计算表达式。
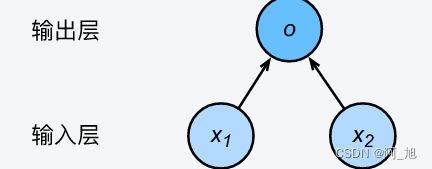
1.2.1 神经网络图
在深度学习中,我们可以使用神经网络图直观地表现模型结构。为了更清晰地展示线性回归作为神经网络的结构,图1.1使用神经网络图表示本节中介绍的线性回归模型。神经网络图隐去了模型参数权重和偏差。
1.2.2 矢量计算表达式
在模型训练或预测时,我们常常会同时处理多个数据样本并用到矢量计算。在介绍线性回归的矢量计算表达式之前,让我们先考虑对两个向量相加的两种方法。
下面先定义两个1000维的向量。
import torch
from time import time
a = torch.ones(1000)
b = torch.ones(1000)
向量相加的一种方法是,将这两个向量按元素逐一做标量加法。
start = time()
c = torch.zeros(1000)
for i in range(1000):
c[i] = a[i] + b[i]
print(time() - start)
输出:
0.02039504051208496
向量相加的另一种方法是,将这两个向量直接做矢量加法(向量对应元素相加)。
start = time()
d = a + b
print(time() - start)
输出:
0.0008330345153808594
结果很明显,后者比前者更省时。因此,我们应该尽可能采用矢量计算,以提升计算效率。
让我们再次回到本节的房价预测问题。如果我们对训练数据集里的3个房屋样本(索引分别为1、2和3)逐一预测价格,将得到
y ^ ( 1 ) = x 1 ( 1 ) w 1 + x 2 ( 1 ) w 2 + b , y ^ ( 2 ) = x 1 ( 2 ) w 1 + x 2 ( 2 ) w 2 + b , y ^ ( 3 ) = x 1 ( 3 ) w 1 + x 2 ( 3 ) w 2 + b . \begin{aligned} \hat{y}^{(1)} &= x_1^{(1)} w_1 + x_2^{(1)} w_2 + b,\\ \hat{y}^{(2)} &= x_1^{(2)} w_1 + x_2^{(2)} w_2 + b,\\ \hat{y}^{(3)} &= x_1^{(3)} w_1 + x_2^{(3)} w_2 + b. \end{aligned} y^(1)y^(2)y^(3)=x1(1)w1+x2(1)w2+b,=x1(2)w1+x2(2)w2+b,=x1(3)w1+x2(3)w2+b.
现在,我们将上面3个等式转化成矢量计算。设
y ^ = [ y ^ ( 1 ) y ^ ( 2 ) y ^ ( 3 ) ] , X = [ x 1 ( 1 ) x 2 ( 1 ) x 1 ( 2 ) x 2 ( 2 ) x 1 ( 3 ) x 2 ( 3 ) ] , w = [ w 1 w 2 ] \boldsymbol{\hat{y}} = \begin{bmatrix} \hat{y}^{(1)} \\ \hat{y}^{(2)} \\ \hat{y}^{(3)} \end{bmatrix},\quad \boldsymbol{X} = \begin{bmatrix} x_1^{(1)} & x_2^{(1)} \\ x_1^{(2)} & x_2^{(2)} \\ x_1^{(3)} & x_2^{(3)} \end{bmatrix},\quad \boldsymbol{w} = \begin{bmatrix} w_1 \\ w_2 \end{bmatrix} y^=⎣⎡y^(1)y^(2)y^(3)⎦⎤,X=⎣⎢⎡x1(1)x1(2)x1(3)x2(1)x2(2)x2(3)⎦⎥⎤,w=[w1w2]
对3个房屋样本预测价格的矢量计算表达式为 y ^ = X w + b , \boldsymbol{\hat{y}} = \boldsymbol{X} \boldsymbol{w} + b, y^=Xw+b, 其中的加法运算使用了广播机制(参见2.2节)。例如:
a = torch.ones(3)
b = 10
print(a + b)
输出:
tensor([11., 11., 11.])
广义上讲,当数据样本数为 n n n,特征数为 d d d 时,线性回归的矢量计算表达式为
y ^ = X w + b \boldsymbol{\hat{y}} = \boldsymbol{X} \boldsymbol{w} + b y^=Xw+b
其中模型输出 y ^ ∈ R n × 1 \boldsymbol{\hat{y}} \in \mathbb{R}^{n \times 1} y^∈Rn×1 批量数据样本特征 X ∈ R n × d \boldsymbol{X} \in \mathbb{R}^{n \times d} X∈Rn×d,权重 w ∈ R d × 1 \boldsymbol{w} \in \mathbb{R}^{d \times 1} w∈Rd×1, 偏差 b ∈ R b \in \mathbb{R} b∈R。相应地,批量数据样本标签 y ∈ R n × 1 \boldsymbol{y} \in \mathbb{R}^{n \times 1} y∈Rn×1。设模型参数 θ = [ w 1 , w 2 , b ] ⊤ \boldsymbol{\theta} = [w_1, w_2, b]^\top θ=[w1,w2,b]⊤,我们可以重写损失函数为
ℓ ( θ ) = 1 2 n ( y ^ − y ) ⊤ ( y ^ − y ) \ell(\boldsymbol{\theta})=\frac{1}{2n}(\boldsymbol{\hat{y}}-\boldsymbol{y})^\top(\boldsymbol{\hat{y}}-\boldsymbol{y}) ℓ(θ)=2n1(y^−y)⊤(y^−y)
小批量随机梯度下降的迭代步骤将相应地改写为
θ ← θ − η ∣ B ∣ ∑ i ∈ B ∇ θ ℓ ( i ) ( θ ) , \boldsymbol{\theta} \leftarrow \boldsymbol{\theta} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \nabla_{\boldsymbol{\theta}} \ell^{(i)}(\boldsymbol{\theta}), θ←θ−∣B∣ηi∈B∑∇θℓ(i)(θ),
其中梯度是损失有关3个为标量的模型参数的偏导数组成的向量:
∇ θ ℓ ( i ) ( θ ) = [ ∂ ℓ ( i ) ( w 1 , w 2 , b ) ∂ w 1 ∂ ℓ ( i ) ( w 1 , w 2 , b ) ∂ w 2 ∂ ℓ ( i ) ( w 1 , w 2 , b ) ∂ b ] = [ x 1 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) x 2 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ] = [ x 1 ( i ) x 2 ( i ) 1 ] ( y ^ ( i ) − y ( i ) ) \nabla_{\boldsymbol{\theta}} \ell^{(i)}(\boldsymbol{\theta})= \begin{bmatrix} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial w_1} \\ \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial w_2} \\ \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial b} \end{bmatrix} = \begin{bmatrix} x_1^{(i)} (x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}) \\ x_2^{(i)} (x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}) \\ x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)} \end{bmatrix}= \begin{bmatrix} x_1^{(i)} \\ x_2^{(i)} \\ 1 \end{bmatrix} (\hat{y}^{(i)} - y^{(i)}) ∇θℓ(i)(θ)=⎣⎢⎢⎡∂w1∂ℓ(i)(w1,w2,b)∂w2∂ℓ(i)(w1,w2,b)∂b∂ℓ(i)(w1,w2,b)⎦⎥⎥⎤=⎣⎢⎡x1(i)(x1(i)w1+x2(i)w2+b−y(i))x2(i)(x1(i)w1+x2(i)w2+b−y(i))x1(i)w1+x2(i)w2+b−y(i)⎦⎥⎤=⎣⎢⎡x1(i)x2(i)1⎦⎥⎤(y^(i)−y(i))
2.2 线性回归的从零开始实现
在了解了线性回归的背景知识之后,现在我们可以动手实现它了。尽管强大的深度学习框架可以减少大量重复性工作,但若过于依赖它提供的便利,会导致我们很难深入理解深度学习是如何工作的。因此,本节将介绍如何只利用Tensor和autograd来实现一个线性回归的训练。
首先,导入本节中实验所需的包或模块,其中的matplotlib包可用于作图,且设置成嵌入显示。
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
2.2.1 生成数据集
我们构造一个简单的人工训练数据集,它可以使我们能够直观比较学到的参数和真实的模型参数的区别。设训练数据集样本数为1000,输入个数(特征数)为2。给定随机生成的批量样本特征 X ∈ R 1000 × 2 \boldsymbol{X} \in \mathbb{R}^{1000 \times 2} X∈R1000×2,我们使用线性回归模型真实权重 w = [ 2 , − 3.4 ] ⊤ \boldsymbol{w} = [2, -3.4]^\top w=[2,−3.4]⊤ 和偏差 b = 4.2 b = 4.2 b=4.2,以及一个随机噪声项 ϵ \epsilon ϵ 来生成标签
y = X w + b + ϵ \boldsymbol{y} = \boldsymbol{X}\boldsymbol{w} + b + \epsilon y=Xw+b+ϵ
其中噪声项 ϵ \epsilon ϵ 服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰。下面,让我们生成数据集。
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)
注意,features的每一行是一个长度为2的向量,而labels的每一行是一个长度为1的向量(标量)。
print(features[0], labels[0])
输出:
tensor([0.8557, 0.4793]) tensor(4.2887)
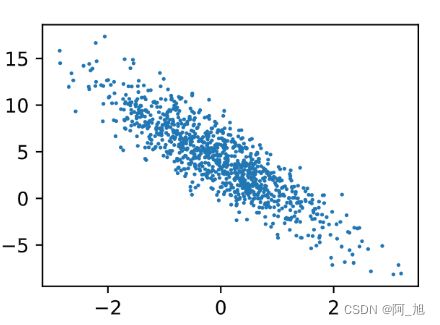
通过生成第二个特征features[:, 1]和标签 labels 的散点图,可以更直观地观察两者间的线性关系。
def use_svg_display():
# 用矢量图显示
display.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
# # 在../d2lzh_pytorch里面添加上面两个函数后就可以这样导入
# import sys
# sys.path.append("..")
# from d2lzh_pytorch import *
set_figsize()
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
2.2.2 读取数据
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
# 参数0表示以行为标准进行选择
yield features.index_select(0, j), labels.index_select(0, j)
让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
输出:
tensor([[-1.4239, -1.3788],
[ 0.0275, 1.3550],
[ 0.7616, -1.1384],
[ 0.2967, -0.1162],
[ 0.0822, 2.0826],
[-0.6343, -0.7222],
[ 0.4282, 0.0235],
[ 1.4056, 0.3506],
[-0.6496, -0.5202],
[-0.3969, -0.9951]])
tensor([ 6.0394, -0.3365, 9.5882, 5.1810, -2.7355, 5.3873, 4.9827, 5.7962,
4.6727, 6.7921])
2.2.3 初始化模型参数
我们将权重初始化成均值为0、标准差为0.01的正态随机数,偏差则初始化成0。
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们要让它们的requires_grad=True。
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
2.2.4 定义模型
下面是线性回归的矢量计算表达式的实现。我们使用mm函数做矩阵乘法。
def linreg(X, w, b):
return torch.mm(X, w) + b
2.2.5 定义损失函数
我们使用上一节描述的平方损失来定义线性回归的损失函数。在实现中,我们需要把真实值y变形成预测值y_hat的形状。以下函数返回的结果也将和y_hat的形状相同。
def squared_loss(y_hat, y):
# 注意这里返回的是向量
return (y_hat - y.view(y_hat.size())) ** 2 / 2
2.2.6 定义优化算法
以下的sgd函数实现了上一节中介绍的小批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
2.2.7 训练模型
在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征X和标签y),通过调用反向函数backward计算小批量随机梯度,并调用优化算法sgd迭代模型参数。由于我们之前设批量大小batch_size为10,每个小批量的损失l的形状为(10, 1)。回忆一下自动求梯度一节。由于变量l并不是一个标量,所以我们可以调用.sum()将其求和得到一个标量,再运行l.backward()得到该变量有关模型参数的梯度。注意在每次更新完参数后不要忘了将参数的梯度清零。
在一个迭代周期(epoch)中,我们将完整遍历一遍data_iter函数,并对训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设3和0.03。在实践中,大多超参数都需要通过反复试错来不断调节。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。而有关学习率对模型的影响,我们会在后面“优化算法”一章中详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期
# 在每一个迭代周期中,会使用训练数据集中所有样本一次(假设样本数能够被批量大小整除)。X
# 和y分别是小批量样本的特征和标签
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum() # l是有关小批量X和y的损失
l.backward() # 小批量的损失对模型参数求梯度
sgd([w, b], lr, batch_size) # 使用小批量随机梯度下降迭代模型参数
# 不要忘了梯度清零
w.grad.data.zero_()
b.grad.data.zero_()
# 计算第一个迭代周期的损失
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
输出:
epoch 1, loss 0.028127
epoch 2, loss 0.000095
epoch 3, loss 0.000050
训练完成后,我们可以比较学到的参数和用来生成训练集的真实参数。它们应该很接近。
print(true_w, '\n', w)
print(true_b, '\n', b)
输出:
[2, -3.4]
tensor([[ 1.9998],
[-3.3998]], requires_grad=True)
4.2
tensor([4.2001], requires_grad=True)
小结
- 可以看出,仅使用
Tensor和autograd模块就可以很容易地实现一个模型。接下来,会在此基础上描述更多深度学习模型,并介绍怎样使用更简洁的代码(见下一节)来实现它们。
如果内容对你有帮助,感谢点赞+关注哦!
更多干货内容持续更新中…