DETR:End-to-End Object Detection with Transformers
DETR:End-to-End Object Detection with Transformers
- 端到端目标检测
- 摘要
-
- 贡献
- 特点
- 引言
-
- 训练过程简述:
- 预测过程简述:
- 相关工作:
-
- .1 集合预测
-
- 原文
- .2 Transformer 和并行解码
- DETR模型
-
- 3.1 目标检测集合预测损失
- 整体网络框架
- 伪代码
- 实验
原文链接: DETR:End-to-End Object Detection with Transformers.
代码链接:GitHub官方代码
B站视频:DETR 论文精读【论文精读】_哔哩哔哩_bilibili.
端到端目标检测
意义:目标检测里很少有端到端的学习方法,大都在最后加一个后处理操作,如nms(非极大值抑制)。不论是anchor base 、anchor free 、proposal base等 ,都会生成很多预测框,最后需要nms去除冗余框,模型在调参上非常复杂,而且部署困难,nms不是所有硬件都支持。
DETR既没有proposal也没有anchor,利用了Transformer对全局信息的处理能力,把目标检测看成一个集合预测的问题。
摘要
每个图片所对应的集合不一样,所要达到的目的是给定一张图片,把集合预测出来(本文设置的集合元素个数为超参数100)。DETR把之前依赖人先验知识的部分删除掉了,特别是nms和生成anchor的部分。
贡献
- 提出了一个新的目标函数,通过二分图匹配的方式,强制模型输出一组独一无二的预测(无冗余框)
- 使用Transformer当中的encoder和decoder的架构 。在Transformer解码器处添加额外的learned object queries
特点
- 简单,代码上不需要特殊的库支持(普通的libraries即可支持)
- 性能上,与FasterRCNN几乎打成平手
引言
前人工作多是基于proposals、anchor 或者 物体中心点(non-anchor) 。在性能上很大受限于后处理操作(nms操作),主要是因为上述方法皆会产生大量冗余重复的框。
transformer的编解码结构通过全局特征解决了一个目标产生冗余框的问题。
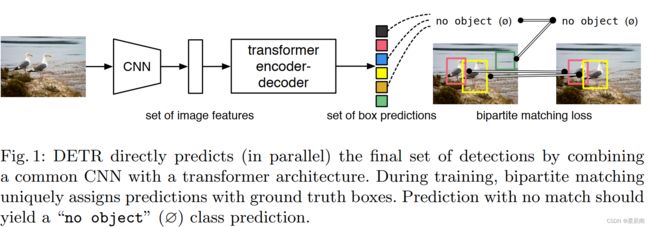
训练过程简述:
图一可以简单概述训练过程为4步骤:
- CNN抽取图像特征
- Transformer的Encoder学习全局特征
- Transformer的Decoder生成100个预测框
- 生成的预测框与ground truth做匹配,在匹配的框中去算目标检测loss
预测过程简述:
- CNN抽取图像特征
- Transformer的Encoder学习全局特征
- Transformer的Decoder生成100个预测框
- 阈值卡一下输出置信度大于0.7的
相关工作:
我们的工作建立在几个领域的先前工作的基础上:集合预测的二分图匹配损失、基于Transformer 的encoder和decoder架构、并行解码以及目标检测方法。
先是简单的引入了文章所提方法都源自哪一板块的先前工作。
.1 集合预测
原文
目前还没有一个规范的深度学习模型直接预测集合。基本的集合预测任务是多标签分类(例如,[40,33]用于计算机视觉环境的参考文献),对这些问题,基准方法单对单,不能用于检测元素之间的底层结构(例如:靠近的预测框)。这些任务的第一个困难就是避免类似的重复。目前大多数检测器使用诸如非极大值抑制(nms)等后处理来解决这个问题,但直接集合预测是不需要的。他们需要全局推断架构来模拟所有预测元素之间的交互,以避免冗余。对于等大小集预测,稠密的全连接网络[9]是足够的,但成本较高。一般的方法是使用自回归序列模型,如循环神经网络[48]。在所有情况下,损失函数应该是不变的排列的预测。通常的解决方案是在匈牙利算法[20]的基础上设计一个损失,在ground truth和预测值之间找到二分图匹配。这强制了排列不变性,并保证每个目标元素都有唯一的匹配。我们遵循二部匹配损失方法。然而,与之前的大多数工作相比,我们不再使用自回归模型,而是使用带有并行解码的变压器,我们将在下面描述。
.2 Transformer 和并行解码
Transformer是由Vaswani等人介绍的,[47]作为一种新的基于注意力的机器翻译模块。注意机制[2]是神经网络层,它从整个输入序列中聚合信息。Transformer引入了自注意力层,类似于[49]的Non-Local神经网络,扫描序列的每个元素,并通过聚合整个序列的信息来更新它。注意模型的主要优点是具有全局计算能力和良好的记忆能力,这使其比RNN系列更适用于长序列。在自然语言处理、语音处理和计算机视觉的许多问题上,Transformer正在取代RNN系列[8,27,45,34,31]。
Transformer首先在自回归模型当中使用,遵循早期的seq-to-seq序列模型[44],逐一生成输出序列中的元素。然而,在音频[29]、机器翻译[12,10]、词表示学习[8]以及最近的语音识别[6]等领域,由于推理成本高(与输出长度成正比,且难以批量处理),导致并行序列生成的发展。我们还将变压器和并行解码结合起来,以便在计算成本和执行集合预测所需的全局计算能力之间进行适当的权衡。
DETR模型
3.1 目标检测集合预测损失
DETR模型最后的输出是一个固定大小的集合,N个输出(100个框),一般来说一张图片100个框足够了。
问题引出:100个框与ground truth的匹配问题?
解答:**最优二分图匹配问题,**如何分配一些工人干多个任务,abc就是工人,xyz就是任务,cost矩阵(可以是任意大小的矩阵)中的元素代表是某工人做某任务的消耗。最后能找到一个唯一解能够使得cost最小的分配方法。匈牙利算法是比较有名且高效的算法。
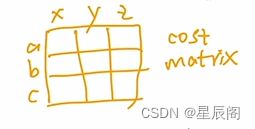
对于目标检测来说,cost矩阵当中的每一个元素其实就是ground truth与预测框之间的损失(分类损失和预测框损失之和)。
整体网络框架
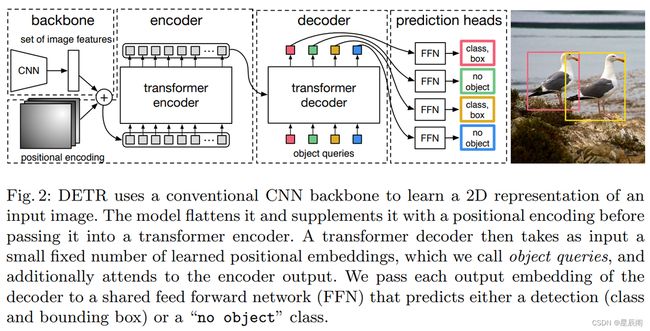
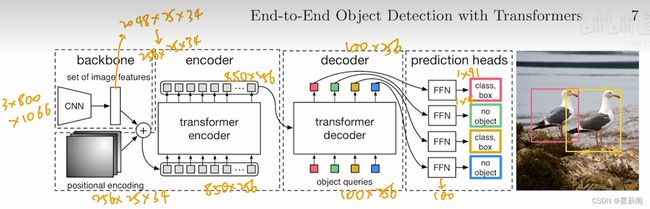
小细节: 每个Decoder(共6个)后面加了一个auxiliary loss,额外的目标函数,是一个分割上非常常见的trick,检测也可以做。
伪代码
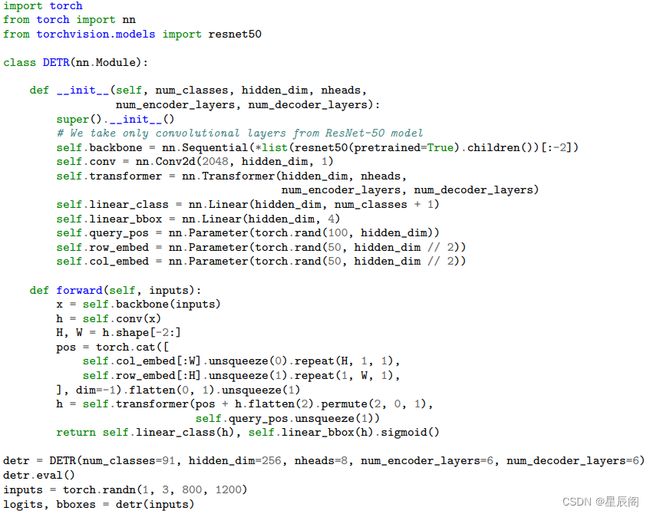
实验
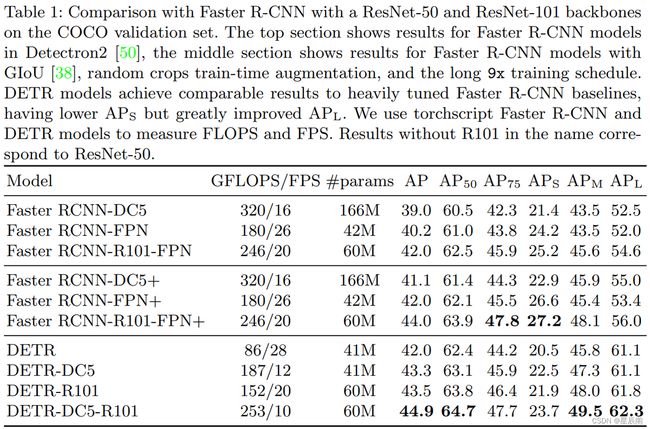
注意:
- 训练策略对结果的影响还是蛮大的
- GFLOPS和FPS没有直接关系
- 实验结果关注一下大物体的结果要远远好于FasterRCNN(分析是因为Transformer的编解码关注全局特征)

因为DETR在涨点方面并不是很能打,所以作者另辟蹊径尝试多做消融实验来证明方法的优点,同时还可视化了encoder和decoder的结果,充分说明模块的可用性。