opencv:用最邻近插值和双线性插值法实现上采样(放大图像)与下采样(缩小图像)
上采样与下采样
概念:
上采样:
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的 是放大原图像,从而可以显示在更高分辨率的显示设备上。
下采样:
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的 有两个:
1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
实现方法:
上采样原理:内插值
下采样原理:(M/s) * (N/s)(同比例缩小)
插值方法:
一:最邻近插值The nearest interpolation
设i+u, j+v(i, j为正整数, u, v为大于零小于1的小数,下同)为待求象素坐标,则待求象素灰 度的值 f(i+u, j+v) 如下图所示:

若我们在A区域插入像素,该像素值与(i,j)的值相同,同理若是在B区域插入像素,这该像素值与(i+1,j)的值相同。
缺点:
如果在A区域插入过多的像素,可能造成图像锯齿状。(导致在某一区域的像素值相同,导致失真)
代码实现:
import cv2
import numpy as np
def function(img):
height,width,channels =img.shape
emptyImage=np.zeros((800,800,channels),np.uint8) #建立一个空图像
sh=800/height
sw=800/width
for i in range(800):
for j in range(800):
x=int(i/sh)
y=int(j/sw)
emptyImage[i,j]=img[x,y]
return emptyImage
img=cv2.imread("lenna.png")
print(img.shape)
zoom=function(img)
print(zoom.shape)
cv2.imshow("nearest interp",zoom)
cv2.imshow("image",img)
cv2.waitKey(0)
输出结果:
原图像为512×512,输出图像为800×800
二:双线性插值
公式:
f(i+u, j+v) = (1-u) * (1-v) * f(i, j) + (1-u) * v * f(i, j+1) + u * (1-v) * f(i+1, j) + u * v * f(i+1, j+1)

看着有点懵?
我们可以先看看单线性插值:

公式:

其实就是一个比例关系:我们想要输入的值是y(像素值),已知的位置点是x(位置)。y和y0的距离差与x和x0的距离差的比值应等于y1和y0的距离差与x1与x0的距离差的比值。从而推导出在单线性的情况下,y的推导公式:
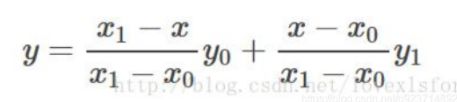
了解了单线性插值,我们推导双线性插值


先从x方向做两次单线性插值,得R1和R2,然后再在y方向做单线性插值:
因为在图像计算中,x1和x2,y1和y2都是相邻的点,导致x2-x1=1,y2-y1=1
最后得到的结果其实就是:
f(i+u, j+v) = (1-u) * (1-v) * f(i, j) + (1-u) * v * f(i, j+1) + u * (1-v) * f(i+1, j) + u * v * f(i+1, j+1)
注意:插值算法并不是只能用在放大,在插入像素点的同时,忽略原图周围点即为缩小。
双线性插值有个额外的步骤:中心对齐(能够对双向插值的图像精度的提升)

注意:在默认的双线性插值时,始终以左上角像素点进行对齐,这就导致最右边的点始终没有参与插值。可能造成精度损失。
应用中心对齐后的双线性插值的代码实现:
import numpy as np
import cv2
'''
实现双线性插值
'''
def bilinear_interpolation(img,out_dim):
src_h, src_w, channel = img.shape
dst_h, dst_w = out_dim[1], out_dim[0]
print ("src_h, src_w = ", src_h, src_w)
print ("dst_h, dst_w = ", dst_h, dst_w)
if src_h == dst_h and src_w == dst_w:
return img.copy()
#如果输入大小与原图大小相同,则返回原图
dst_img = np.zeros((dst_h,dst_w,3),dtype=np.uint8)
#建立一个预输出的全0图像
scale_x, scale_y = float(src_w) / dst_w, float(src_h) / dst_h
for i in range(3):
for dst_y in range(dst_h):
for dst_x in range(dst_w):
#使用几何中心对称
#如果使用直接方式,src_x=dst_x*scale_x
#scale是比例,通过同比例缩小/放大实现中心对齐
src_x = (dst_x + 0.5) * scale_x - 0.5
src_y = (dst_y + 0.5) * scale_y - 0.5
#找到将用于计算插值的点的坐标
src_x0 = int(np.floor(src_x))
src_x1 = min(src_x0 + 1 ,src_w - 1)
src_y0 = int(np.floor(src_y))
src_y1 = min(src_y0 + 1, src_h - 1)
# 计算插值
temp0 = (src_x1 - src_x) * img[src_y0,src_x0,i] + (src_x - src_x0) * img[src_y0,src_x1,i]
temp1 = (src_x1 - src_x) * img[src_y1,src_x0,i] + (src_x - src_x0) * img[src_y1,src_x1,i]
dst_img[dst_y,dst_x,i] = int((src_y1 - src_y) * temp0 + (src_y - src_y0) * temp1)
return dst_img
if __name__ == '__main__':
img = cv2.imread('lenna.png')
cv2.imshow('original picture',img)
dst = bilinear_interpolation(img,(700,700)) #放大
#dst = bilinear_interpolation(img,(200,200)) #缩小
cv2.imshow('bilinear interp',dst)
cv2.waitKey()
输出结果:
中心对齐代码解读:
src_x = (dst_x + 0.5) * scale_x - 0.5
src_y = (dst_y + 0.5) * scale_y - 0.5

以这个图为例,可以明显看出,中心点在(i+0.5,j+0.5),也就是说,先将原图的中心点找到,然后按照放大/缩小的倍数,最后还需要减去0.5的偏差值。
这里我参考了其他的博客:
将公式变形,srcX=dstX* (srcWidth/dstWidth)+0.5*(srcWidth/dstWidth-1) 相当于我们在原始的浮点坐标上加上了0.5*(srcWidth/dstWidth-1)这样一个控制因子,这项的符号可正可负,与srcWidth/dstWidth的比值也就是当前插值是扩大还是缩小图像有关,有什么作用呢?看一个例子:假设源图像是33,中心点坐标(1,1)目标图像是99,中心点坐标(4,4),我们在进行插值映射的时候,尽可能希望均匀的用到源图像的像素信息,最直观的就是(4,4)映射到(1,1)现在直接计算srcX=4*3/9=1.3333!=1,也就是我们在插值的时候所利用的像素集中在图像的右下方,而不是均匀分布整个图像。现在考虑中心点对齐,srcX=(4+0.5)*3/9-0.5=1,刚好满足我们的要求.