Android 源码分析 NNAPI MM部分
-
简介
NNAPI 是 Android 用于机器学习的 API 简称。主要定位机器学习、机器算法导出的模型,在 Android运行相应的 Op算子,并且选择不同的运行策略实现加速的逻辑推理的过程。整体的软件结构包括如下:

-
Executor 与 Operations
所有硬件平台的算法固化模式,都是以 FPGA / DSP 固化代码实现硬件算子单元,以此达到加速运行算法的目的。比如Open CL / Open GL,上层业务方或者系统集成 SOC 方都仅仅是使用芯片提供的基础接口能力,实现自己的算法。这里的概念有两个,基本算子单元(Operations)和运行器(Executor)。
Executor:可以简单的理解是算法的执行器。
Operations: 换而言之是基本的算子集成计算单元。
一般的模型都会配置特殊的特征矩阵、计算的图、计算基本算子等等。机器学习的端执行主要是翻译模型中保存的计算图、向量、特征,并把输入的序列化数据,再放入到运行环境中的模型执行器中按图运算。最终得出计算结果的一个过程。
这里的 Executor 是一个算子执行器。
// Information we maintain about each operand during execution that
// may change during execution.
struct RunTimeOperandInfo {
// TODO Storing the type here is redundant, as it won't change during execution.
OperandType type;
// The type and dimensions of the operand. The dimensions can
// change at runtime. We include the type because it's useful
// to pass together with the dimension to the functions implementing
// the operators.
std::vector dimensions;
float scale;
int32_t zeroPoint;
// Where the operand's data is stored. Check the corresponding
// location information in the model to figure out if this points
// to memory we have allocated for an temporary operand.
uint8_t* buffer;
// The length of the buffer.
uint32_t length;
// Whether this is a temporary variable, a model input, a constant, etc.
OperandLifeTime lifetime;
// Keeps track of how many operations have yet to make use
// of this temporary variable. When the count is decremented to 0,
// we free the buffer. For non-temporary variables, this count is
// always 0.
uint32_t numberOfUsesLeft;
Shape shape() const {
return Shape{.type = type, .dimensions = dimensions, .scale = scale, .offset = zeroPoint};
}
};
// Used to keep a pointer to each of the memory pools.
//
// In the case of an "mmap_fd" pool, owns the mmap region
// returned by getBuffer() -- i.e., that region goes away
// when the RunTimePoolInfo is destroyed or is assigned to.
class RunTimePoolInfo {
public:
// If "fail" is not nullptr, and construction fails, then set *fail = true.
// If construction succeeds, leave *fail unchanged.
// getBuffer() == nullptr IFF construction fails.
explicit RunTimePoolInfo(const hidl_memory& hidlMemory, bool* fail);
explicit RunTimePoolInfo(uint8_t* buffer);
// Implement move
RunTimePoolInfo(RunTimePoolInfo&& other);
RunTimePoolInfo& operator=(RunTimePoolInfo&& other);
// Forbid copy
RunTimePoolInfo(const RunTimePoolInfo&) = delete;
RunTimePoolInfo& operator=(const RunTimePoolInfo&) = delete;
~RunTimePoolInfo() { release(); }
uint8_t* getBuffer() const { return mBuffer; }
bool update() const;
private:
void release();
void moveFrom(RunTimePoolInfo&& other);
hidl_memory mHidlMemory; // always used
uint8_t* mBuffer = nullptr; // always used
sp mMemory; // only used when hidlMemory.name() == "ashmem"
};
bool setRunTimePoolInfosFromHidlMemories(std::vector* poolInfos,
const hidl_vec& pools);
// This class is used to execute a model on the CPU.
class CpuExecutor {
public:
// Executes the model. The results will be stored at the locations
// specified in the constructor.
// The model must outlive the executor. We prevent it from being modified
// while this is executing.
int run(const V1_0::Model& model, const Request& request,
const std::vector& modelPoolInfos,
const std::vector& requestPoolInfos);
int run(const V1_1::Model& model, const Request& request,
const std::vector& modelPoolInfos,
const std::vector& requestPoolInfos);
private:
bool initializeRunTimeInfo(const std::vector& modelPoolInfos,
const std::vector& requestPoolInfos);
// Runs one operation of the graph.
int executeOperation(const Operation& entry);
// Decrement the usage count for the operands listed. Frees the memory
// allocated for any temporary variable with a count of zero.
void freeNoLongerUsedOperands(const std::vector& inputs);
// The model and the request that we'll execute. Only valid while run()
// is being executed.
const Model* mModel = nullptr;
const Request* mRequest = nullptr;
// We're copying the list of all the dimensions from the model, as
// these may be modified when we run the operatins. Since we're
// making a full copy, the indexes used in the operand description
// stay valid.
// std::vector mDimensions;
// Runtime information about all the operands.
std::vector mOperands;
};
// Class for setting reasonable OpenMP threading settings. (OpenMP is used by
// the Eigen matrix library.)
//
// Currently sets a low blocktime: the time OpenMP threads busy-wait for more
// work before going to sleep. See b/79159165, https://reviews.llvm.org/D18577.
// The default is 200ms, we set to 20ms here, see b/109645291. This keeps the
// cores enabled throughout inference computation without too much extra power
// consumption afterwards.
//
// The OpenMP settings are thread-local (applying only to worker threads formed
// from that thread), see https://software.intel.com/en-us/node/522688 and
// http://lists.llvm.org/pipermail/openmp-dev/2016-July/001432.html. This class
// ensures that within the scope in which an object is instantiated we use the
// right settings (scopes may be nested), as long as no other library changes
// them. (Note that in current NNAPI usage only one instance is used in the
// CpuExecutor thread).
//
// TODO(mikie): consider also setting the number of threads used. Using as many
// threads as there are cores results in more variable performance: if we don't
// get all cores for our threads, the latency is doubled as we wait for one core
// to do twice the amount of work. Reality is complicated though as not all
// cores are the same. Decision to be based on benchmarking against a
// representative set of workloads and devices. I'm keeping the code here for
// reference.
class ScopedOpenmpSettings {
public:
ScopedOpenmpSettings();
~ScopedOpenmpSettings();
DISALLOW_COPY_AND_ASSIGN(ScopedOpenmpSettings);
private:
int mBlocktimeInitial;
#if NNAPI_LIMIT_CPU_THREADS
int mMaxThreadsInitial;
#endif
};
namespace {
template
T getScalarData(const RunTimeOperandInfo& info) {
// TODO: Check buffer is at least as long as size of data.
T* data = reinterpret_cast(info.buffer);
return data[0];
}
inline bool IsNullInput(const RunTimeOperandInfo *input) {
return input->lifetime == OperandLifeTime::NO_VALUE;
}
inline int NumInputsWithValues(const Operation &operation,
std::vector &operands) {
const std::vector &inputs = operation.inputs;
return std::count_if(inputs.begin(), inputs.end(),
[&operands](uint32_t i) {
return !IsNullInput(&operands[i]);
});
}
inline int NumOutputs(const Operation &operation) {
return operation.outputs.size();
}
inline size_t NumDimensions(const RunTimeOperandInfo *operand) {
return operand->shape().dimensions.size();
}
inline uint32_t SizeOfDimension(const RunTimeOperandInfo *operand, int i) {
return operand->shape().dimensions[i];
}
inline RunTimeOperandInfo *GetInput(const Operation &operation,
std::vector &operands,
int index) {
return &operands[operation.inputs[index]];
}
inline RunTimeOperandInfo *GetOutput(const Operation &operation,
std::vector &operands,
int index) {
return &operands[operation.outputs[index]];
}
} // anonymous namespace
} // namespace nn
} // namespace android
#endif // ANDROID_ML_NN_COMMON_CPU_EXECUTOR_H
Executor 中包含了几个定义:
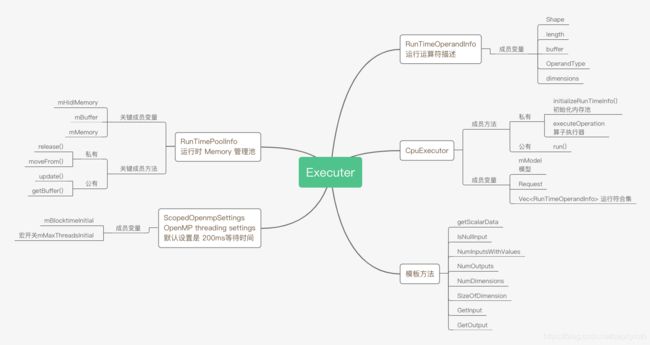
这里有一个 RunTimePoolInfo 来管理内存,可能做过 Open CL和 Open GL的都清楚,在运算过程中,存在一步操作是将 CPU 的 Memory copy 到显存中,结果再从显示空间 copy 到内存。这样的过程主要是Android Kerrnl 和 user space 属于同一块 RAM 分区,显存实际用的物理地址也是外挂 RAM 的一个分区,GPU 工作所需的内存空间都会在显存空间中。同理,推理过程中,可能所需要的是不同的计算处理单元,也就由此设计了一个管理内存的工具便于管理模型执行过程中的内存。
原生的 Operations 支持以下几个,囊括了 简单经典的算子合集。如 RNN、SVD( 奇异值分解算法)、LSTM( long short term memory(LSTM),即LSTM算法全称)、Conv2D(2维数据卷积)等等。针对每个使用场景、一般而言,算法提供商都会有对应的算子实现容器。以 Conv2D cpu 版本为例,简单阐述下他具体的做法:
bool convFloat32(const float* inputData, const Shape& inputShape,
const float* filterData, const Shape& filterShape,
const float* biasData, const Shape& biasShape,
int32_t padding_left, int32_t padding_right,
int32_t padding_top, int32_t padding_bottom,
int32_t stride_width, int32_t stride_height,
int32_t activation,
float* outputData, const Shape& outputShape) {
ANDROID_NN_CONV_PARAMETERS(float)
float output_activation_min, output_activation_max;
CalculateActivationRangeFloat(activation, &output_activation_min,
&output_activation_max);
// Prevent concurrent executions that may access the scratch buffer.
std::unique_lock lock(executionMutex);
//调度算法 具体在 TensorFlow Lite Delegate Api 定义的 Conv 方法
tflite::optimized_ops::Conv(
inputData, convertShapeToDims(inputShape),
filterData, convertShapeToDims(filterShape),
biasData, convertShapeToDims(biasShape),
stride_width, stride_height, paddingWidth, paddingHeight,
output_activation_min, output_activation_max,
outputData, convertShapeToDims(outputShape),
im2colData, im2colDim);
return true;
}
32位数据和 8位数据的卷积还是使用了 TensorFlow Lite Delegate API 所提供的 Conv 方法。
-
BlobCache 与 nnCache
这两个 class 主要是 Cache管理类,首先看提供了那些 东西。
首先是操作内存的两个选择指令:
enum class Select {
RANDOM, // evict random entries
LRU, // evict least-recently-used entries
DEFAULT = RANDOM,
};
这里定义了两种内存操作方式,一种是 LRU 还有一种是随机的申请方式,默认是随机的使用方式。其次还有一个是 Capacity 枚举。
enum class Capacity {
// cut back to no more than half capacity; new/replacement
// entry still might not fit
HALVE,
// cut back to whatever is necessary to fit new/replacement
// entry
FIT,
// cut back to no more than half capacity and ensure that
// there's enough space for new/replacement entry
FIT_HALVE,
DEFAULT = HALVE,
};
这里是对内存申请的三种策略,砍掉一半内存还是看到非必要的内存,亦或者是砍掉不超过一半的内存申请空间,以满足足够空间置换的方式。之后是一个内存清空的策略,在内存不足的情况下,如何清除缓存。
typedef std::pair Policy;
static Policy defaultPolicy() { return Policy(Select::DEFAULT, Capacity::DEFAULT); }
之后是 Blob 类和 CacheEntry以及Header之间的关系。

在 BlobCache类上层,是一个调用者NNCache,为了便于管理,这里被设计成为了一个单例类。里面定义了一些 BlobCache 的引用,提供申请内存、释放策略等接口函数。

-
sample 定义类
重点看下 SampleDriver 这个类,在对比其他几个和这个的区别。SampleDriver 继承于 IDevice 类。内部提供了每个 Device 的基础OP算子支持函数列表。接下来过一遍:
SampleDriverAll / SampleDriverFloatFast / SampleDriverFloatSlow 等等都继承于 SampleDriver ,但是他们挂钩底层 kernel 的服务是存在不同的,举例 Fast和 Slow两个Driver.
// Driver 定义
class SampleDriver : public IDevice {
public:
SampleDriver(const char* name) : mName(name) {}
~SampleDriver() override {}
//获取
Return getCapabilities(getCapabilities_cb cb) override;
Return getSupportedOperations(const V1_0::Model& model,
getSupportedOperations_cb cb) override;
Return prepareModel(const V1_0::Model& model,
const sp& callback) override;
Return prepareModel_1_1(const V1_1::Model& model, ExecutionPreference preference,
const sp& callback) override;
Return getStatus() override;
// Starts and runs the driver service. Typically called from main().
// This will return only once the service shuts down.
int run();
protected:
std::string mName;
};
// fixme 模型定义
class SamplePreparedModel : public IPreparedModel {
public:
SamplePreparedModel(const Model& model) : mModel(model) {}
~SamplePreparedModel() override {}
bool initialize();
Return execute(const Request& request,
const sp& callback) override;
private:
void asyncExecute(const Request& request, const sp& callback);
Model mModel;
std::vector mPoolInfos;
};
} // namespace sample_driver
} // namespace nn
} // namespace android
可以从上面的头文件发现,可以获取相应的支持算子列表、导入模型、运行函数的基本函数。并且模型预测函数的代码看,这里是一个异步的设计,和 CL 的调用方式大同小异。
Return SamplePreparedModel::execute(const Request& request,
const sp& callback) {
VLOG(DRIVER) << "execute(" << SHOW_IF_DEBUG(toString(request)) << ")";
if (callback.get() == nullptr) {
LOG(ERROR) << "invalid callback passed to execute";
return ErrorStatus::INVALID_ARGUMENT;
}
if (!validateRequest(request, mModel)) {
callback->notify(ErrorStatus::INVALID_ARGUMENT);
return ErrorStatus::INVALID_ARGUMENT;
}
// This thread is intentionally detached because the sample driver service
// is expected to live forever.
std::thread([this, request, callback]{ asyncExecute(request, callback); }).detach();
return ErrorStatus::NONE;
}
service neuralnetworks_hal_service_sample_float_fast /vendor/bin/hw/[email protected]
class hal
user system
group system
service neuralnetworks_hal_service_sample_float_slow /vendor/bin/hw/[email protected]
class hal
user system
group system
其余接口和功能方法都类似。