LaneATT 源码解读与复现常见问题总结
纯干货,不废话
目录
一、源码解读
1.1 项目结构
二、复现常见问题汇总
1.LaneATT是否可以在纯CPU上跑?
2.如何用LaneATT测试自己的图片?(main.py 测试提示没有label_json)
3.CUDA 11 编译NMS失败 (待解决)
4.LaneATT,输出车道线类别(实线、虚线)
一、源码解读
1.1 项目结构
- cfgs: 默认/预设配置文件
- lib
- datasets
- culane.py: culane数据集加载器
- lane_dataset.py: 将来自LaneDatasetLoader中的未经过处理的 annotations 转换为模型可以使用的形式
- lane_dataset_loader.py: 每个数据集加载器实现的抽象类
- llamas.py: llamas数据集加载器
- nolabel_dataset.py: 加载不需注释的的数据集
- tusimple.py: tusimple数据集加载器
- models:
- laneatt.py: LaneATT模型的实现
- matching.py: 用于gt和proposal匹配的效用函数
- resnet.py: resnet 实现部分
- nms: LaneATT模型的实现
- config.py: LaneATT模型的实现
- experiment.py: 跟踪和存储有关每个实验的信息
- focal_loss.py: focal loss的实现
- lane.py: 车道线表示
- runner.py: 训练和测试循环
- datasets
- utils:
- culane_metric.py: 非官方的CULane数据集度量实现
- gen_anchor_mask.py: 计算数据集中要在锚点筛选步骤中使用的每个锚点的频率(论文提到锚点的数量会限制速度,所以挑选使用频率最大的部分锚点)
- gen_video.py: 从模型预测生成视频
- llamas_metric.py llamas数据集的实用程序函数
- speed.py: 测量模型的效率相关指标
- tusimple_metric.py: tusimple数据集图片度量的官方实现
- viz_dataset.py: 显示从数据集采样的图像(增强后)
- main.py: 运行实验的训练或测试阶段
二、复现常见问题汇总
1.LaneATT是否可以在纯CPU上跑?
cpu版NMS
答案是可以的。运行main.py报错的主要原因是NMS没有编译。LaneATT之所以运行速度快,主要是采用了CUDA加速的NMS。不用CUDA加速的NMS是否可以?可以,自己实现,并在cpu上运行,缺点就是慢。另外不能使用torchvision中自带的nms进行替换,torchvision带的nms是针对iou的,line proposal的度量方式不是Iou。
在lib/models/laneatt.py中,增加下述两个方法:
def Lane_nms(self,proposals,scores,overlap=50, top_k=4):
keep_index = []
print(scores)
sorted_score, indices = torch.sort(scores, descending=True) # from big to small
r_filters = np.zeros(len(scores))
for i,indice in enumerate(indices):
if r_filters[i]==1: # continue if this proposal is filted by nms before
continue
keep_index.append(indice)
if len(keep_index)>top_k: # break if more than top_k
break
if i == (len(scores)-1):# break if indice is the last one
break
sub_indices = indices[i+1:]
for sub_i,sub_indice in enumerate(sub_indices):
r_filter = self.Lane_IOU(proposals[indice,:],proposals[sub_indice,:],overlap)
if r_filter: r_filters[i+1+sub_i]=1
num_to_keep = len(keep_index)
keep_index = list(map(lambda x: x.item(), keep_index))
return torch.tensor(keep_index), num_to_keep, None
def Lane_IOU(self,parent_box, compared_box, threshold):
'''
calculate distance one pair of proposal lines
return True if distance less than threshold
'''
start_a = (parent_box[2] * self.n_strips + 0.5).int() # add 0.5 trick to make int() like round
start_b = (compared_box[2] * self.n_strips + 0.5).int()
start = torch.max(start_a,start_b)
end_a = start_a + parent_box[4] - 1 + 0.5 - (((parent_box[4] - 1)<0).int())
end_b = start_b + compared_box[4] - 1 + 0.5 - (((compared_box[4] - 1)<0).int())
end = torch.min(torch.min(end_a,end_b),torch.tensor(self.n_offsets-1))
# end = torch.min(torch.min(end_a,end_b),torch.FloatTensor(self.n_offsets-1, device = torch.device('cpu')))
if (end - start)<0:
return False
dist = 0
for i in range(5+start,5 + end.int()):
# if i>(5+end):
# break
if parent_box[i] < compared_box[i]:
dist += compared_box[i] - parent_box[i]
else:
dist += parent_box[i] - compared_box[i]
return dist < (threshold * (end - start + 1))在nms中,替换为自己的实现方式(大概在130行):
![]() 除了慢,没别的毛病。
除了慢,没别的毛病。
2.如何用LaneATT测试自己的图片?(main.py 测试提示没有label_json)
测试自己的数据集
作者的模型test是和GT进行对比,所以需要test_label.json即GT的标注。但是我们有时候需要的仅仅是模型对车道线检测的可视化输出,怎么办?
使用nolabel_dataset
修改测试使用模型下的yml文件(experiments文件夹下),比如laneatt_llamas_resnet34.yml
test:
type: LaneDataset
parameters:
S: *S
# ---------- modified lines START here ----------
dataset: nolabel_dataset
img_h: 720 # Set your test images height here
img_w: 1280 # Set your test images width here
root: "path/to/images" # Path to the root directory of your images
img_ext: ".png" # The loader will load every image with extension `img_ext` inside `root`
max_lanes: *max_lanes # You should use the same number that the model was trained with (i.e., leave it as it is)
normalize: false
aug_chance: 0
augmentations:
# ---------- modified lines END here ----------找到相应位置,进行替换,每个字段代表的意思见后面注释,不再赘述。
另外使用ssh远程连接服务器调试是不能显示图片的(貌似),因为我得服务器是无桌面版,所以不能弹出检测结果,所以我讲检测结果保存为图片。
具体方法为使用 参数--view all,修改runner.py 下面的eval(),找到 if self.veiw
if self.view:
img = (images[0].cpu().permute(1, 2, 0).numpy() * 255).astype(np.uint8)
img, fp, fn = dataloader.dataset.draw_annotation(idx, img=img, pred=prediction[0])
if self.view == 'mistakes' and fp == 0 and fn == 0:
continue
cv2.imwrite(str(idx)+'.jpg', img)另外,如果你觉得麻烦,直接拿加载模型,处理模型的输出更直接。
参考下面的文章,测试自己的视频,测试图片稍微改改,frame->img就好了
3.CUDA 11 编译NMS失败 (待解决)
CUDA 11 GTX3090 编译NMS
因为作者的NMS是在CUDA 10(10.2)下编写的,所以CUDA 10下按照下面命令编译应该是没问题的:
python setup.py install在远程服务器上GTX2080Ti,CUDA10.1 是直接编译成功的
此问题主要针对GTX30系显卡,貌似GTX30以上显卡最低支持CUDA11,所以直接用上述命令编译时会出问题,一个GTX3090的朋友在编译前先输入下述命令编译成功。
export TORCH_CUDA_ARCH_LIST="8.0"但是我的电脑3050 ,CUDA11.3,在该条件下并未成功,仍报错,目前正在研究。尝试过把编译成功的NMS文件替换掉,但是结果是不行的。有实现成功的小伙伴欢迎在下面介绍方法。
4.LaneATT,输出车道线类别(实线、虚线)
LaneATT输出的车道线格式是类似Tusimple的标注格式:
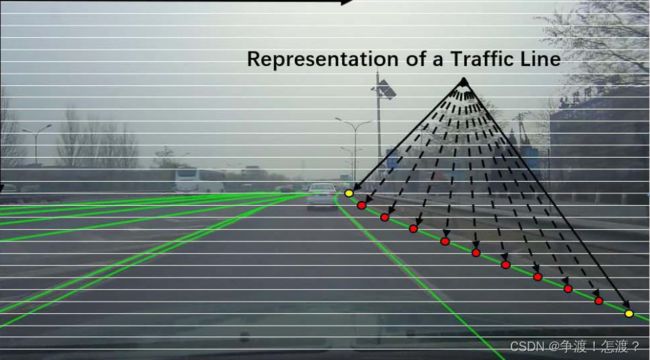
是一个个点,在源码中可视化输出用drawLane的直接连接两个端点。所以不管什么类型的车道线最后数据都是没有做判别的。那么是否可以利用该模型输出类型?可以!不过要加心得东西进去:
1.Create a new layer that will predict a probability for each class in the dataset here (e.g., classes_layer)
2.Use classes_layer to predict using the features here
3.Add those predictions to the list of outputs (e.g., apply the NMS filter on it, as done for the outputs of regression and binary classification)说白了,多加一层用于判断类别。
5.训练不同尺寸的数据集(相对于默认的360*640)
ref:Training on original image sizes · Issue #110 · lucastabelini/LaneATT · GitHub
只需要修改cfgs下面的yaml文件中的img_w和img_h,其他不需要改变。但是有一点需要注意,也许随着尺寸的增大,锚可能变得过于分离。比如,在原始设置中,垂直方向上每5个像素就有一个锚定,但在尺寸变大时,这可能会使一些车道在训练期间丢失。可以尝试增加此处生成的锚数量,然后使用脚本重新生成锚掩码。
~~~~边学边做,持续更新吧。