pytorch深度学习实践
pytorch深度学习实践
- 线性模型
- 梯度下降
- 反向传播(pytorch实现)
-
- 一元模型
- 二元模型
- 用pytorch实现线性回归
- sifgmoid函数
- 多维度输入
- 加载数据集
- softmax_classifier
- 卷积神经网络基础
- minist 数据集训练
线性模型

# coding=utf-8
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x * w # x是单个值,这里不需要提前准备w的值,后续用到有值就行
def loss(x, y):
y_pred = forward(x) # y也是单个值
return (y_pred - y) ** 2
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
w_list.append(w)
mse_list.append(l_sum / len(x_data))
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()

梯度下降
一般使用随机梯度下降,防止出现鞍点导致学习不能进行。

x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y - y_pred) ** 2
def gradient(x, y):
return 2 * (x * w - y) * x
print("Predict(Before Training)", 4, forward(4))
for epoch in range(100):
for x_val, y_val in zip(x_data, y_data):
grad = gradient(x_val, y_val)
w = w - 0.1 * grad
l = loss(x_val, y_val)
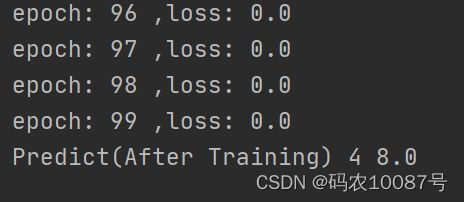
print("epoch:", epoch, ",loss:", l)
print("Predict(After Training)", 4, forward(4))

反向传播(pytorch实现)
一元模型
1.forward和loss 函数不是简单的计算,而是在构建计算图。在构建计算图的时候,使用张量来计算
2.在更新权重的时候,使用data来计算。
3.计算loss的时候,如果求和,必须用其data属性,否则是计算图的叠加;如:sum += l;(tensor在进行加法运算的时候)会构建计算图。
4.取值计算用.data,只取值用.item(),这两种情况下使用的都是标量;否则为张量。
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w # 不是简单的乘法运算,而是计算图
def loss(x, y):
y_hat = forward(x)
return (y_hat - y) ** 2 # 得到的结果是一个张量
def gradient(x, y):
return 2 * x * (x * w - y)
print('Predict (before training)', 4, forward(4))
epoch_list = []
loss_list = []
for epoch in np.arange(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward() # 通过调用backward函数,可以计算出计算图上的每一个梯度,并且存到相对应的变量里,然后释放计算图
print('\tgrad:', x, y, w.grad.item())
w.data -= 0.01 * w.grad.data # grad也是Tensor,所以要取到data值,这样的话不会建立计算图
epoch_list.append(epoch)
loss_list.append(l.item()) # 往列表里添加的内容,不可是tensor类型,或者item(),或者.detach().numpy()取出来
w.grad.data.zero_() # 必须清零,否则梯度会累加
print('process:', epoch, l.item())
print('Predict(after training)', 4, forward(4).item())
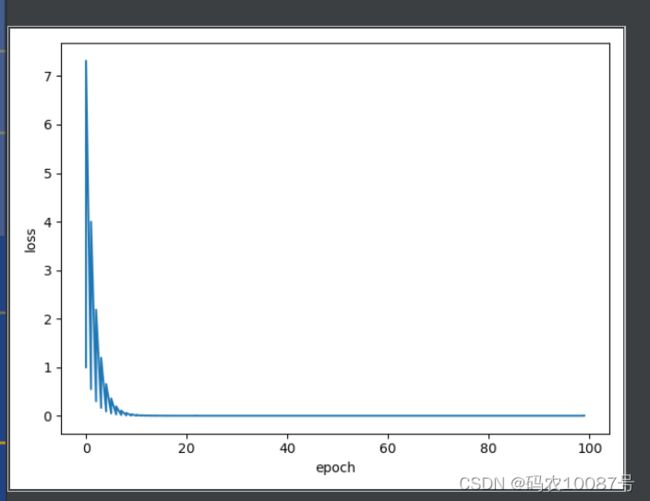
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
二元模型

import torch
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w1 = torch.Tensor([1.0])
w2 = torch.Tensor([1.0])
b = torch.Tensor([1.0])
w1.requires_grad = True
w2.requires_grad = True
b.requires_grad = True
epoch_list = []
loss_list = []
def forward(x):
return x ** 2 * w1 + x * w2 + b
def loss(x, y):
y_pred = forward(x)
return (y - y_pred) ** 2
print('Predict(after training)', 4, forward(4).item())
for epoch in range(100):
for x_val,y_val in zip(x_data,y_data):
l = loss(x_val, y_val)
l.backward()
print("grad", x_val, y_val, w1.grad.item(), w2.grad.item(), b.grad.item)
w1.data -= 0.01*w1.grad.data
w2.data -= 0.01 * w2.grad.data
b.data -= 0.01 * b.grad.data
epoch_list.append(epoch)
loss_list.append(l.item())
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print('process:', epoch, l.item())
print('Predict(after training)', 4, forward(4).item())
plt.plot(epoch_list,loss_list)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()

用pytorch实现线性回归

import matplotlib.pyplot as plt
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]]) # 必须是矩阵才行
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
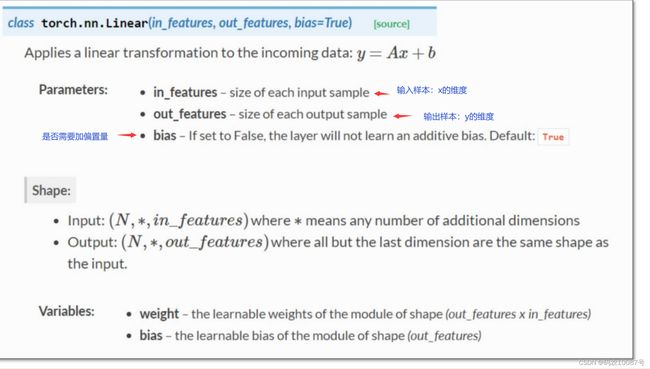
self.linear = torch.nn.Linear(1, 1) # 在构造对象,Liner包含weight和bias
def forward(self, x):
y_hat = self.linear(x) # 对象后面加括号,表示对象可调用
return y_hat
model = LinearModel() # module是一个可以调用的对象,model(x):调用forward函数
criterion = torch.nn.MSELoss(size_average=False) # 对整个数据而言,是否求均值,影响不大
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 实例化,优化器不会构建计算图
# module.parameters()会检查所有的成员,加到训练的参数集合上
loss_list = []
epoch_list = []
for epoch in range(1000):
y_hat = model(x_data)
loss = criterion(y_hat, y_data)
print(epoch, loss) # 打印的时候会自动调用__str__()函数,所以不会产生计算图
optimizer.zero_grad() # 训练前梯度归零
loss.backward()
optimizer.step() # step函数是用来进行更新的
epoch_list.append(epoch)
loss_list.append(loss.item())
print('w =', model.linear.weight.item()) # weight虽然只是一个值,但是是一个矩阵,为了显示数值,只能是.item()
print('b =', model.linear.bias.item())
x_test = torch.Tensor([[4.0]]) # 与x的模式是一样的是1*1的矩阵
y_test = model(x_test)
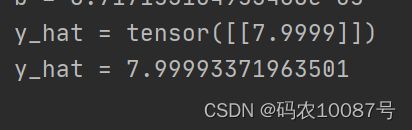
print('y_hat =', y_test.data)
print('y_hat =', y_test.item())
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
训练100次的结果为7.4
训练1000次的结果为7.9999
但是也不是说训练的次数越多越好,很有可能过拟合了。
sifgmoid函数
sigmoid函数用交叉熵算loss

import torch
import matplotlib.pyplot as plt
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModule(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModule, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
module = LogisticRegressionModule()
epoch_list = []
loss_list = []
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(module.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = module(x_data)
l = criterion(y_pred,y_data)
optimizer.zero_grad() # 训练前梯度归零
l.backward()
optimizer.step() # step函数是用来进行更新的
epoch_list.append(epoch)
loss_list.append(l.item())
x_test = torch.Tensor([[4.0]]) # 与x的模式是一样的是1*1的矩阵
y_test = module(x_test)
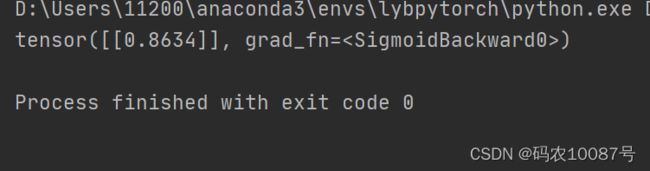
print(y_test)
多维度输入

输入的维度是8维,输出的维度是1维(维度为列数)
import numpy as np
import torch
import matplotlib.pyplot as plt
xy = np.loadtxt('D:/Users/11200/PycharmProjects/pytorchPractice/dataset/diabetes.csv', delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # 所有行,只要最后一列
# 需要一个矩阵,,所有,又加了一个中括号
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,2)
self.linear2 = torch.nn.Linear(2,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
model = Model()
# 二分类的任务
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
total_loss = []
total_epoch = []
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# 损失函数绘图
total_loss.append(loss.detach().numpy())
total_epoch.append(epoch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#损失函数绘图
plt.plot(total_epoch, total_loss)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()

加载数据集
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) # 文件是N行m列的
self.len = xy.shape[0] # xy的形状是(N,m)
self.x_data = torch.from_numpy(xy[:, :-1])
# 全部都取,但是不取最后一列
self.y_data = torch.from_numpy(xy[:, [-1]]) # 全部都取,但是不取最后一列
# 只取最后一列,且以矩阵的形式返回
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('../dataset/diabetes.csv')
train_loader = DataLoader(dataset=dataset,
batch_size=32, # 小批量处理是 32
shuffle=True, # 打乱顺序
num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1、导入数据
inputs, labels = data
# 2、前向传播
y_hat = model(inputs)
loss = criterion(y_hat, labels)
print(epoch, i, loss.item())
# 3、反向传播
optimizer.zero_grad()
loss.backward()
# 4、更新权重
optimizer.step()
if epoch % 30 == 1:
y_pred_label = torch.where(y_hat >= 0.5, torch.tensor([1.0]), torch.tensor([0.0]))
accuracy = torch.eq(y_pred_label, labels).sum().item() / labels.size(0)
print("loss = ", loss.item(), "acc = ", accuracy)
# torch.where(condition, x, y):
# condition:判断条件
# x:若满足条件,则取x中元素
# y:若不满足条件,则取y中元素
softmax_classifier
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # 变成1维来处理
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 增加一个参数更好的学习
def train(epoch):
running_loss = 0.0
for batch_size, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad() # 在优化器优化之前,进行权重清零;
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_size % 300 == 299: # 每300下算一次running_loss
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_size + 1, running_loss / 300))
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
# _表示不关心的值,dim=1表示行的最大值,dim=0表示列的最大值
total += labels.size(0) # 总共的标签数
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(100):
train(epoch)
test()

卷积神经网络基础

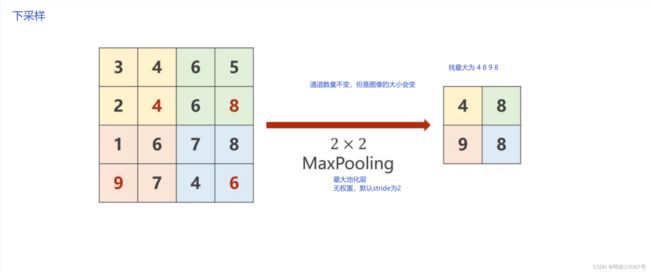
当kernel_size为2的时候,默认stride = 2, W和H各减半。
minist 数据集训练
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # (可有可无)
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size,
)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size,
)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0')
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_index, (inputs, labels) in enumerate(train_loader, 0):
inputs, labels = inputs.to(device), labels.to(device)
y_hat = model(inputs)
loss = criterion(y_hat, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_size % 10 == 9:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_index + 1, running_loss / 300))
def test():
correct = 0
total = 0
with torch.no_grad():
for (images, labels) in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, pred = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (pred == labels).sum().item()
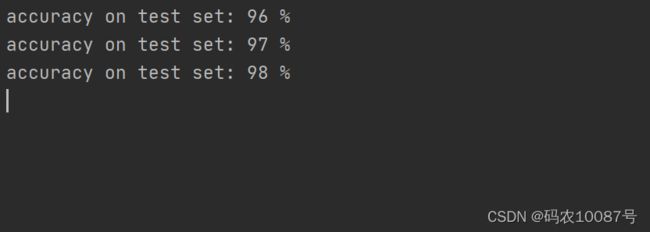
print('accuracy on test set: %d %%' % (100 * correct / total))
return correct / total
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()