【学习笔记—eat_pytorch_in_20_days】结构化数据建模流程范例
1.1准备数据
本项目使用的数据可在作者公众号‘算法美食屋 ’获取
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
dftrain_raw = pd.read_csv('./eat_pytorch_in_20_days-master/eat_pytorch_datasets/titanic/train.csv')
dftest_raw = pd.read_csv('./eat_pytorch_in_20_days-master/eat_pytorch_datasets/titanic/test.csv')
dftrain_raw.head(10)
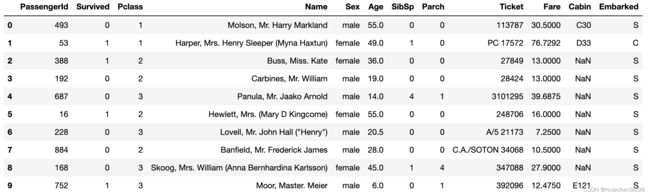
字段说明:
Survived:0代表死亡,1代表存活【y标签】
Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
Name:乘客姓名 【舍去】
Sex:乘客性别 【转换成bool特征】
Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
Parch:乘客父母/孩子的个数(整数值)【数值特征】
Ticket:票号(字符串)【舍去】
Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
1.2.数据预处理
def preprocessing(dfdata):
dfresult= pd.DataFrame()
#Pclass
dfPclass = pd.get_dummies(dfdata['Pclass'])
dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ]
dfresult = pd.concat([dfresult,dfPclass],axis = 1)
#Sex
dfSex = pd.get_dummies(dfdata['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
#Age
dfresult['Age'] = dfdata['Age'].fillna(0)
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')
#SibSp,Parch,Fare
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
x_train = preprocessing(dftrain_raw).values
y_train = dftrain_raw[['Survived']].values
x_test = preprocessing(dftest_raw).values
y_test = dftest_raw[['Survived']].values
print("x_train.shape =", x_train.shape )
print("x_test.shape =", x_test.shape )
print("y_train.shape =", y_train.shape )
print("y_test.shape =", y_test.shape )
1.3.使用DataLoader和TensorDataset封装成可以迭代的数据管道
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),
shuffle = True, batch_size = 8)
dl_val = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),
shuffle = False, batch_size = 8)
2.定义模型
此处选择使用最简单的nn.Sequential,按层顺序模型
def create_net():
net = nn.Sequential()
net.add_module("linear1",nn.Linear(15,20))
net.add_module("relu1",nn.ReLU())
net.add_module("linear2",nn.Linear(20,15))
net.add_module("relu2",nn.ReLU())
net.add_module("linear3",nn.Linear(15,1))
return net
net = create_net()
print(net)
3.训练模型
Pytorch通常需要用户编写自定义训练循环,训练循环的代码风格因人而异。
有3类典型的训练循环代码风格:脚本形式训练循环,函数形式训练循环,类形式训练循环。
此处介绍一种较通用的仿照Keras风格的脚本形式的训练循环。
该脚本形式的训练代码与 torchkeras 库的核心代码基本一致。
torchkeras详情: https://github.com/lyhue1991/torchkeras
import os,sys,time
import numpy as np
import pandas as pd
import datetime
from tqdm import tqdm
import torch
from torch import nn
from copy import deepcopy
from torchkeras.metrics import Accuracy
def printlog(info):
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print(str(info)+"\n")
loss_fn = nn.BCEWithLogitsLoss()
optimizer= torch.optim.Adam(net.parameters(),lr = 0.01)
metrics_dict = {"acc":Accuracy()}
epochs = 20
ckpt_path='checkpoint.pt'
#early_stopping相关设置
monitor="val_acc"
patience=5
mode="max"
history = {}
for epoch in range(1, epochs+1):
printlog("Epoch {0} / {1}".format(epoch, epochs))
# 1,train -------------------------------------------------
net.train()
total_loss,step = 0,0
loop = tqdm(enumerate(dl_train), total =len(dl_train))
train_metrics_dict = deepcopy(metrics_dict)
for i, batch in loop:
features,labels = batch
#forward
preds = net(features)
loss = loss_fn(preds,labels)
#backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
#metrics
step_metrics = {"train_"+name:metric_fn(preds, labels).item()
for name,metric_fn in train_metrics_dict.items()}
step_log = dict({"train_loss":loss.item()},**step_metrics)
total_loss += loss.item()
step+=1
if i!=len(dl_train)-1:
loop.set_postfix(**step_log)
else:
epoch_loss = total_loss/step
epoch_metrics = {"train_"+name:metric_fn.compute().item()
for name,metric_fn in train_metrics_dict.items()}
epoch_log = dict({"train_loss":epoch_loss},**epoch_metrics)
loop.set_postfix(**epoch_log)
for name,metric_fn in train_metrics_dict.items():
metric_fn.reset()
for name, metric in epoch_log.items():
history[name] = history.get(name, []) + [metric]
# 2,validate -------------------------------------------------
net.eval()
total_loss,step = 0,0
loop = tqdm(enumerate(dl_val), total =len(dl_val))
val_metrics_dict = deepcopy(metrics_dict)
with torch.no_grad():
for i, batch in loop:
features,labels = batch
#forward
preds = net(features)
loss = loss_fn(preds,labels)
#metrics
step_metrics = {"val_"+name:metric_fn(preds, labels).item()
for name,metric_fn in val_metrics_dict.items()}
step_log = dict({"val_loss":loss.item()},**step_metrics)
total_loss += loss.item()
step+=1
if i!=len(dl_val)-1:
loop.set_postfix(**step_log)
else:
epoch_loss = (total_loss/step)
epoch_metrics = {"val_"+name:metric_fn.compute().item()
for name,metric_fn in val_metrics_dict.items()}
epoch_log = dict({"val_loss":epoch_loss},**epoch_metrics)
loop.set_postfix(**epoch_log)
for name,metric_fn in val_metrics_dict.items():
metric_fn.reset()
epoch_log["epoch"] = epoch
for name, metric in epoch_log.items():
history[name] = history.get(name, []) + [metric]
# 3,early-stopping -------------------------------------------------
arr_scores = history[monitor]
best_score_idx = np.argmax(arr_scores) if mode=="max" else np.argmin(arr_scores)
if best_score_idx==len(arr_scores)-1:
torch.save(net.state_dict(),ckpt_path)
print("<<<<<< reach best {0} : {1} >>>>>>".format(monitor,
arr_scores[best_score_idx]),file=sys.stderr)
if len(arr_scores)-best_score_idx>patience:
print("<<<<<< {} without improvement in {} epoch, early stopping >>>>>>".format(
monitor,patience),file=sys.stderr)
break
net.load_state_dict(torch.load(ckpt_path))
dfhistory = pd.DataFrame(history)