Python实现K-Means、DBSCAN聚类降噪并对比
1.导包
import csv
import numpy as np
import matplotlib.pyplot as plt
import random
import pywt
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN2.导数据
#特征
pack=[]
#num
number=[]
csv_file = csv.reader(open('data8.csv'))
for content in csv_file:
content=list(map(float,content))
if len(content)!=0:
pack.append(content[0:1])
packs=[]
for i in pack:
packs.append(i[0])
for i in range(len(pack)):
number.append(i+1)3.看数据格式
fig = plt.gcf()
fig.set_size_inches(20, 5)
ax = plt.axes()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.rcParams['xtick.direction'] = 'in'#将x周的刻度线方向设置向内
plt.rcParams['ytick.direction'] = 'in'#将y轴的刻度方向设置向内
plt.tick_params(labelsize=22)
plt.plot(packs,linewidth=3.0)
plt.xlim(0,900)
plt.xlabel('Serial Number',fontsize = 22,fontweight='bold')
plt.ylabel('Packs Price',fontsize = 22,fontweight='bold')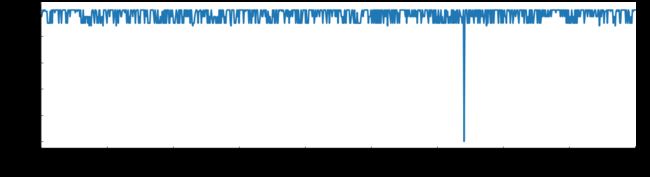
可以明显地看出有异常数据
plt.boxplot(packs)
plt.show()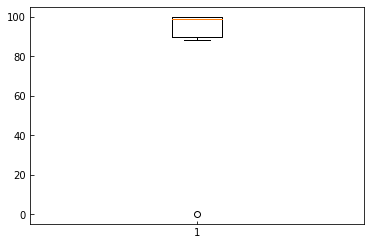
4.使用K-Means聚类
#Kmeans
kmeans = KMeans(n_clusters=3, random_state=10).fit(pack)
pack=np.array(pack)
plt.scatter(number,pack[:, 0],c=kmeans.labels_)
plt.title('K-means')
fig = plt.gcf()
fig.set_size_inches(30, 10.5)
plt.show() 
5.去除噪声节点
res1 = pack[(kmeans.labels_ == 0)]
res2 = pack[(kmeans.labels_ == 0)]
res=[]
for i in res1:
res.append(i[0])
for i in res2:
res.append(i[0])fig = plt.gcf()
fig.set_size_inches(20, 5)
ax = plt.axes()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.rcParams['xtick.direction'] = 'in'#将x周的刻度线方向设置向内
plt.rcParams['ytick.direction'] = 'in'#将y轴的刻度方向设置向内
plt.tick_params(labelsize=22)
plt.plot(res,linewidth=3.0)
plt.xlim(0,900)
plt.xlabel('Serial Number',fontsize = 22,fontweight='bold')
plt.ylabel('Packs Price',fontsize = 22,fontweight='bold')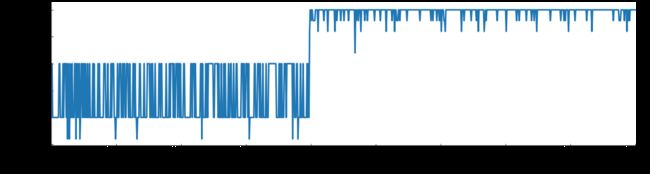
plt.boxplot(res)
plt.show()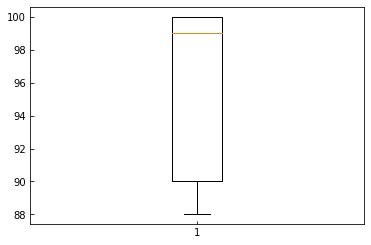
可以看出,使用K-Means聚类降噪可以去除噪音节点,但是分了过多的类别,导致想保留顺序需要一列辅助的编号列,比较麻烦。
6.使用DBSCAN聚类降噪
此次需要自行调参
dbscan = DBSCAN(eps=10,min_samples=2).fit(pack)
plt.scatter(number,pack[:, 0],c=dbscan.labels_)
plt.title('DBSCAN')
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.show()
7.去除噪音节点
r1 = pack[(dbscan.labels_ == 0)]
fig = plt.gcf()
fig.set_size_inches(20, 5)
ax = plt.axes()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.rcParams['xtick.direction'] = 'in'#将x周的刻度线方向设置向内
plt.rcParams['ytick.direction'] = 'in'#将y轴的刻度方向设置向内
plt.tick_params(labelsize=22)
plt.plot(r1,linewidth=3.0)
plt.xlim(0,900)
plt.xlabel('Serial Number',fontsize = 22,fontweight='bold')
plt.ylabel('Packs Price',fontsize = 22,fontweight='bold')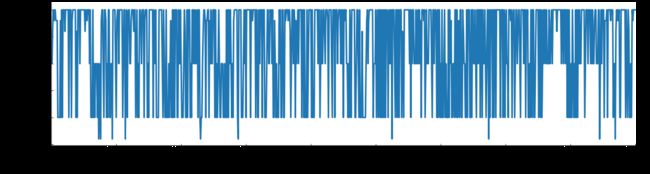
较好的保留了顺序,两组即可区分出异常点位。
8.结论
对数据去噪而言,DBSCAN相比较K-Means有更好的区分噪音能力,但需要人工调整eps范围,而这一点需要对数据特性非常了解才可以。