1. 关于特征提取
0x1:什么是特征提取
特征提取研究的主要问题是,如何在数据集未明确表示结果的前提下,从中提取出重要的潜在特征来。和无监督聚类一样,特征提取算法的目的不是为了预测,而是要尝试对数据进行特征识别,以此得到隐藏在数据背后的深层次意义。
回想一下聚类算法的基本概念,聚类算法将数据集中的每一行数据分别分配给了某个组(group)或某个点(point),每一项数据都精确对应于一个组,这个组代表了组内成员的平均水平。
特征提取是这种聚类思想更为一般的表现形式,它会尝试从数据集中寻找新的数据行,将这些新找到的数据行加以组合,就可以重新构造出数据集。和原始数据集不一样,位于新数据集中的每一行数据并不属于某个聚类,而是由若干特征的组合构造而成的。
从特征提取的这个原理来看,特征提取也可以理解为一种泛化的降维概念。
在这篇文章中,笔者会尝试从底层的数学原理出发,阐述这些概念之间的联系和区别。其实不论是特征提取、降维、聚类,都只是从不用的角度解决同一类问题,其背后的原理都是共通的。
0x2:独立特征提取的典型应用场景
1. 鸡尾酒宴会问题
这是一个如何在多人谈话时鉴别声音。人类听觉系统的一个显著特征就是:在一个人声鼎沸屋子里,尽管有许多不同的声音混杂在一起涌入我们的耳朵,可我们还是能够从中鉴别出某个声音来,大脑非常擅长于从听到的所有噪声中分离出单独的声音。
同样的目标,通过本文将要讨论的独立特征提取技术,计算机就有可能完成同样的任务。
2. 新闻主题分类
独立特征提取的一个重要应用是,对重复出现于一组文档中的单词使用组合进行模式识别(word-usage pattern recognition),这可以帮助我们有效地识别出,以不同组合形式出现于各个文档中的主题。从文档中提取出的这些主题,就可以作为一个泛化的一般化特征,用于概括一整类文旦。同时,通过对文档进行独立特征识别,我们会发现,一篇文章可以包含不止一个主题,同时,同一个主题也可以用于不止一篇文章。
例如,对于某个重大新闻,往往会有多家报社从不同角度都进行了报道,虽然各家报社的侧重点各有不同,但是不可避免会有一些公共主题是交叉的。具体来说,例如美国大选特朗普当选总统,CNN和纽约时报都进行了报道,两家报纸的侧重点各有不同,但是都不约而同地谈到了特朗普过去的从商经历等。
需要特别注意的是,必须要保证要搜索的文档中存在内容重叠的主题(acrossover topic),如果没有任何文档存在共同之处,那么算法将很难从中提取出重要的通用特征,如果强行提取则最终得到的特征将会变得毫无意义(这也体现了独立特征提取技术的降维和聚类本质)。
3. 股票市场数据分析
股票市场是一个集体智慧共同作用的典型场景,在股市经济活动中,每一个自然人都遵循最大收益原则开展活动(凯恩斯的开不见的手宏观经济理论),通俗地说就是,每个投资者做每项投资的目的都是为了使自己的收益最大化。整个社会千千万万个投资者共同形成了一个股票市场。
基于这个前提下,我们假设股票市场数据背后潜藏着诸多原因,正是这些原因共同组成的结果,导致了证券市场的结果。我们可以将独立特征提取算法应用于这些数据,寻找数据背后的原因,以及它们各自对结果所构成的影响。
独立特征提取技术可以用来对股市的成交量进行分析。所谓成交量,就是指在某一给定时间段内所买卖的股票份数,下图是Yahoo!股票的走势图,
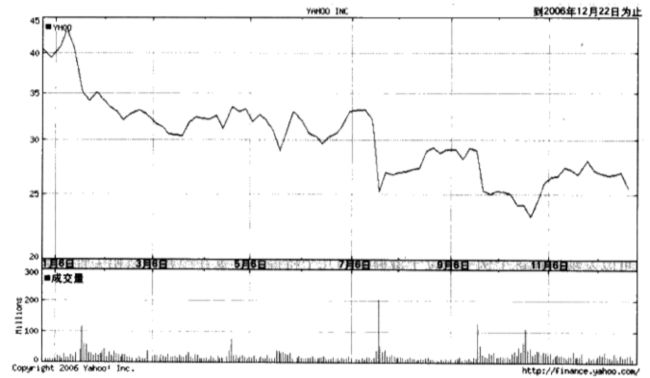
位于最上方的线代表了收盘价,下面的柱状图则给出了成交量。
我们发现,当股票价格有较大变化时,成交量在那几天往往就会变得很高。这通常会发生在公司发表重要声明或发布财务报告的时候。此外,当有涉及公司或业界新闻报道时,也会导致价格出现”突变“。在缺少外部事件影响的情况下,对于某只股票而言,成交量通常(但不总是)保持不变的。
从成交量中提取出的独立特征,基本上就是明面上或者背后的某些”利好“或”不好“事件。
Relevant Link:
《集体智慧编程》Toby segaran - 第10章
2. 非负矩阵因式分解(non-negative matrix factorization,NMF)
0x1:以文章矩阵为例简要说明NMF
NMF是一个非常数学化的概念,我们本章会详细讨论其底层数学原理,不过,笔者希望通过一个简单易懂的例子来为读者朋友先建立一个感性的直观概念,为之后的原理讨论作铺垫。
假设我们现在通过词频语言模型,已经将一个文档集(很多篇文章)转换为了一个【M,N】矩阵,M代表有M篇文章,N代表有N个词,元素的数值代表该单词在对应文章中的词频计数。
我们的目标是要对着个矩阵进行因式分解,即,找到两个更小的矩阵,使得二者相乘以得到原来的矩阵。这两个矩阵分别是特征矩阵和权重矩阵。
【特征矩阵】
在该矩阵中,每个特征对应一行,每个单词对应一列。矩阵中的数字代表了某个单词相对于某个特征的重要程度。
由于每个特征都应该对应于在一组文章中出现的某个主题,因此假如有一篇文章报道了一个新的电视秀节目,那么也许我们会期望这篇文章相对于单词”television“能够有一个较高的权重值。

一个特征矩阵示例
由于矩阵中的每一行都对应于一个由若干单词联合组成的特征,因此很显然,只要将不同数量的特征矩阵按行组合起来,就有可能重新构造出文章矩阵来。
而如何组合不同的特征矩阵,用多少特征矩阵来组合,就是由权重矩阵来控制。
【权重矩阵】
该矩阵的作用是,将特征映射到文章矩阵,其中每一行对应于一篇文章每一列对应于一个特征。矩阵中的数字代表了每个特征应用于每篇文章的程度。

一个权重矩阵示例
下图给出了一个文章矩阵的重构过程,只要将权重矩阵与特征矩阵相乘,就可以重构出文章矩阵,

遵照矩阵乘法法则,特征矩阵的行数和权重矩阵的列数必须要相等。如果特征数量与文章数量恰好相等,那么最理想的结果就是能够为每一篇文章都找到一个与之完美匹配的特征。
在独立特征提取领域中,使用矩阵因式分解的面对,是为了缩减观测数据(例如文章)的集合规模,并且保证缩减之后足以反映某些共性特征。理想情况下,这个较小的特征集能够与不同的权重值相结合,从而完美地重新构造出原始的数据集。但实际情况中,这种可能性是非常小的,因此算法的目标是要尽可能地重新构造出原始数据集来。
笔者思考:
笔者这里带领大家用形象化的思维来理解一下矩阵因式分解,我们将其想象为我们吃月饼,从中间将其掰开为两半,一半是特征矩阵,一半是权重矩阵。特征矩阵和权重矩阵原本都不存在,因为我们一掰,凭空出现了2个小的月饼。那接下来的问题来了,我们能否随意的掰这个月饼呢?答案是不行!这个月饼有自己的法则,只允许我们按照有限几种方案来掰,因为该法则要求掰开后的两半还必须能够完美的拼回一个完整的月饼。
回到矩阵因式分解上来,矩阵的因式分解类似于大数的质因分解,一个矩阵只存在少量几种因式分解方法。而要找到这几种分解方案,就需要使用一些非常精巧的算法,例如本文要介绍的乘法更新法则(multiplicative update rules)。
0x2:乘法更新法则(multiplicative update rules)- 寻找矩阵因式分解的一种算法
我们的目标很明确,希望找到两个矩阵(满足M和N的约束即可),这两个矩阵相乘要尽可能接近原始目标矩阵,我们也建立了损失函数difcost,通过计算最佳的特征矩阵和权重矩阵,算法尝试尽最大可能来重新构造文章矩阵。我们通过difcost函数来度量最终的结果与理想结果的接近程度。
一种可行的优化方法是将其看作是一个优化问题,借助模拟退火或者遗传算法搜索到一个满意的题解,但是这么做的搜索成本可能过于庞大(随着原始矩阵尺寸的上升),一个更为有效的方法是,使用乘法更新法则(multiplicative update rules)。
这些法则产生了4个更新矩阵(update matrices),这里我们将最初的文章矩阵称为数据矩阵。
- hn:经转置后的权重矩阵与数据矩阵相乘得到的矩阵
- hd:经转置后的权重矩阵与原权重矩阵相乘,再与特征矩阵相乘得到的矩阵
- wn:数据矩阵与经转置后的特征矩阵相乘得到的矩阵
- wd:权重矩阵与特征矩阵相乘,再与经转置后的特征矩阵相乘得到的矩阵
为了更新特征矩阵和权重矩阵,算法需要做如下几个操作,
- 首先将上述所有矩阵都转换成数组
- 然后将特征矩阵中的每一个值域hn中的对应值相乘,并除以hd中的对应值
- 再将权重矩阵中的每一个值域wn中的对应值相乘,并除以wd中的对应值
from numpy import * import numpy as np def difcost(a,b): dif=0 for i in range(shape(a)[0]): for j in range(shape(a)[1]): # Euclidean Distance dif+=pow(a[i,j]-b[i,j],2) return dif def factorize(v,pc=10,iter=50): ic=shape(v)[0] fc=shape(v)[1] # Initialize the weight and feature matrices with random values w=matrix([[random.random() for j in range(pc)] for i in range(ic)]) h=matrix([[random.random() for i in range(fc)] for i in range(pc)]) # Perform operation a maximum of iter times for i in range(iter): wh=w*h # Calculate the current difference cost=difcost(v,wh) if i%10==0: print cost # Terminate if the matrix has been fully factorized if cost==0: break # Update feature matrix hn=(transpose(w)*v) hd=(transpose(w)*w*h) h=matrix(array(h)*array(hn)/array(hd)) # Update weights matrix wn=(v*transpose(h)) wd=(w*h*transpose(h)) w=matrix(array(w)*array(wn)/array(wd)) return w,h if __name__ == '__main__': l1 = [[1,2,3], [4,5,6]] m1 = matrix(l1) m2 = matrix([[1,2], [3,4], [5,6]]) print "np.shape(m1*m2): ", np.shape(m1*m2) w, h = factorize(m1*m2, pc=3, iter=100) print "w: ", w print "h: ", h print "w*h: ", w*h print "m1*m2: ", m1*m2

可以看到,算法成功地找到了权重矩阵和特征矩阵,使得这两个矩阵相乘的结果与原始矩阵几乎完美匹配。
值得注意的是,MUR方法要求我们明确指定希望找到的特征数。例如,在一段录音中的两个声音,或者是当天的5大新闻主题。
0x3:理论概述
1. 算法形式化描述
有了前两节的铺垫,现在我们来讨论一些NMF的理论概念。
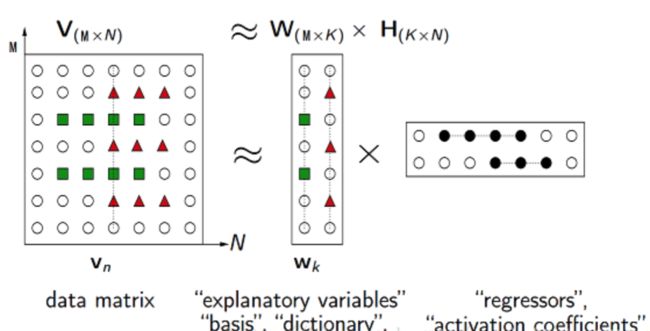
NMF(Non-negative matrix factorization),即对于任意给定的一个非负矩阵V,其能够寻找到一个非负矩阵W和一个非负矩阵H,满足条件V=W*H。从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。其中,
- V矩阵中每一列代表一个观测(observation),每一行代表一个特征(feature)
- W矩阵称为基矩阵,即特征矩阵
- H矩阵称为系数矩阵或权重矩阵,这时用系数矩阵H代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵,从而减少存储空间(从【M*N】降到【M*K】维)
分解过程如下图所示,
2. 损失函数形式
对于如何衡量因式分解的效果,有3种损失函数形式,其中第一种我们上前面的例子中已经使用到了简化版本。
【squared frobenius norm】
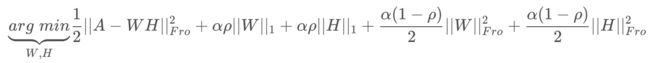
其中:
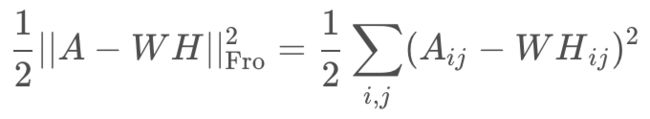
α为L1&L2正则化参数,?为L1正则化占总正则化项的比例,||*||_1为L1范数。
我们前面章节中的difcost函数,就是当α和?都为0的的时候的一种损失函数特例。
【Kullback-Leibler (KL)】
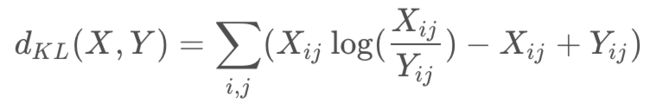
【Itakura-Saito (IS)】
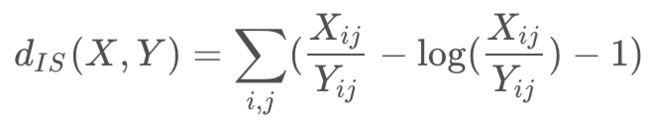
实际上,上面三个公式是beta-divergence family中的三个特殊情况(分别是当β=2,1,0),其原型是:
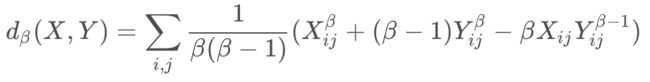
0x4:使用NMF对鸢尾花数据进行独立特征提取
这里我们不使用手写函数了,直接用sklearn封装好的NMF库。
# -*- coding: utf-8 -*- from sklearn.decomposition import NMF from sklearn.datasets import load_iris X, _ = load_iris(True) # can be used for example for dimensionality reduction, source separation or topic extraction nmf = NMF(n_components=4, # k value,默认会保留全部特征 init=None, # W H 的初始化方法,包括'random' | 'nndsvd'(默认) | 'nndsvda' | 'nndsvdar' | 'custom'. solver='cd', # 'cd' | 'mu' beta_loss='frobenius', # {'frobenius', 'kullback-leibler', 'itakura-saito'},一般默认就好 tol=1e-4, # 停止迭代的极限条件 max_iter=200, # 最大迭代次数 random_state=None, alpha=0., # 正则化参数 l1_ratio=0., # 正则化参数 verbose=0, # 冗长模式 shuffle=False # 针对"cd solver" ) # -----------------函数------------------------ print('params:', nmf.get_params()) # 获取构造函数参数的值,也可以nmf.attr得到,所以下面我会省略这些属性 nmf.fit(X) W = nmf.fit_transform(X) W = nmf.transform(X) nmf.inverse_transform(W) # -----------------属性------------------------ H = nmf.components_ # H矩阵 print('reconstruction_err_', nmf.reconstruction_err_) # 损失函数值 print('n_iter_', nmf.n_iter_) # 实际迭代次数 # -----------------输出------------------------ # H即为降维后的新矩阵(维度4是我们通过参数指定的) print "H: ", H print "W: ", W
再看一个更具体的图像处理的例子,使用NMF对图像进行降维,提取出图像中的关键元素,
已知Olivetti人脸数据共400个,每个数据是64*64大小,原始数据维度4096。
NMF分解得到的W矩阵相当于从原始矩阵中提取的特征,那么就可以使用NMF对400个人脸数据进行特征提取。
通过设置k的大小,设置提取的特征的数目。在本实验中设置k=6,随后将提取的特征以图像的形式展示出来。
# -*- coding: utf-8 -*- from time import time from numpy.random import RandomState import matplotlib.pyplot as plt from sklearn.datasets import fetch_olivetti_faces from sklearn import decomposition n_row, n_col = 2, 3 n_components = n_row * n_col image_shape = (64, 64) rng = RandomState(0) # ############################################################################# # Load faces data dataset = fetch_olivetti_faces('./', True, random_state=rng) faces = dataset.data n_samples, n_features = faces.shape print("Dataset consists of %d faces, features is %s" % (n_samples, n_features)) def plot_gallery(title, images, n_col=n_col, n_row=n_row, cmap=plt.cm.gray): plt.figure(figsize=(2. * n_col, 2.26 * n_row)) plt.suptitle(title, size=16) for i, comp in enumerate(images): plt.subplot(n_row, n_col, i + 1) vmax = max(comp.max(), -comp.min()) plt.imshow(comp.reshape(image_shape), cmap=cmap, interpolation='nearest', vmin=-vmax, vmax=vmax) plt.xticks(()) plt.yticks(()) plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 0.04, 0.) # ############################################################################# estimators = [ ('Non-negative components - NMF', decomposition.NMF(n_components=n_components, init='nndsvda', tol=5e-3)) ] # ############################################################################# # Plot a sample of the input data plot_gallery("First centered Olivetti faces", faces[:n_components]) # ############################################################################# # Do the estimation and plot it for name, estimator in estimators: print("Extracting the top %d %s..." % (n_components, name)) t0 = time() data = faces estimator.fit(data) train_time = (time() - t0) print("done in %0.3fs" % train_time) components_ = estimator.components_ print('components_:', components_.shape, '\n**\n', components_) plot_gallery('%s - Train time %.1fs' % (name, train_time), components_) plt.show()

原始400图像中的前6张(普通人脸)

NMF从原始400张图像中提取出的6个独立通用特征
这个例子非常形象直观地说明了NMF提取出的特征矩阵的含义。对于人脸图像来说,输入NMF算法的是代表了原始图像的像素矩阵,而矩阵因式分解得到的权重矩阵W则代表了一种像素权重重新分配分配方案。
具体地说,上述6张特征向量,每个向量的维度都等于原始图像(4096)维,但区别在于,每个特征中,各个像素的值是不同的,它们分别代表了不同的特征。有的特征侧重于对鼻子部分的特征提取,所以在鼻子区域的像素权重分配的就会多,其他的以此类推。
0x5:能否用模拟退火算法或遗传算法这类随机优化算法得到和NMF因式分解近似的效果呢?
这个小节,我们来看一个有趣的想法,能够用随机优化技术直接得到矩阵的因式分解结果呢?我们来写一个实验代码看看结果:
# -*- coding: utf-8 -*- from numpy import * import numpy as np def difcost(a, b): dif = 0 for i in range(shape(a)[0]): for j in range(shape(a)[1]): # Euclidean Distance dif += pow(a[i, j] - b[i, j], 2) return dif def factorize(v, pc=10, iter=50): ic = shape(v)[0] fc = shape(v)[1] # Initialize the weight and feature matrices with random values w = matrix([[random.random() for j in range(pc)] for i in range(ic)]) h = matrix([[random.random() for i in range(fc)] for i in range(pc)]) # Perform operation a maximum of iter times for i in range(iter): wh = w * h # Calculate the current difference cost = difcost(v, wh) #if i % 10 == 0: # print cost # Terminate if the matrix has been fully factorized if cost == 0: break # Update feature matrix hn = (transpose(w) * v) hd = (transpose(w) * w * h) h = matrix(array(h) * array(hn) / array(hd)) # Update weights matrix wn = (v * transpose(h)) wd = (w * h * transpose(h)) w = matrix(array(w) * array(wn) / array(wd)) return w, h def difcost_2d(a, b): dif = 0 for i in range(shape(a)[0]): for j in range(shape(a)[1]): # Euclidean Distance dif += pow(a[i, j]-b[i, j], 2) return dif def hillclimb_2d(v, pc=2, costf=difcost_2d): ic = shape(v)[0] fc = shape(v)[1] # Initialize the weight and feature matrices with random values w = np.array([[random.random() for j in range(pc)] for i in range(ic)]) h = np.array([[random.random() for i in range(fc)] for i in range(pc)]) # Create a random solution sol_w = [] sol_h = [] for x_axi in v: sol_w.append([random.randint(0, y_axi) for y_axi in x_axi]) sol_h.append([random.randint(0, y_axi) for y_axi in x_axi]) # Main loop for w min_cost, current_cost, last_round_cost = 9999999999, 0, 0 patient_count = 0 while 1: best_tmp_w = [] best_tmp_h = [] for j in range(len(w)): # an tmp copy of x for w tmp_w = w # One away in each direction if sol_w[j][0] > w[j][0]: tmp_w[j][0] = sol_w[j][0] else: tmp_w[j][0] = w[j][0] if sol_w[j][1] > w[j][1]: tmp_w[j][1] = sol_w[j][1] else: tmp_w[j][1] = w[j][1] # record the candidate best_tmp_w.append(tmp_w) # now update h matrix for i in range(len(h)): # an tmp copy of x for h tmp_h = h # One away in each direction if sol_h[i][0] > h[i][0]: tmp_h[i][0] = sol_h[i][0] else: tmp_h[i][0] = h[i][0] if sol_h[i][1] > h[i][1]: tmp_h[i][1] = sol_h[i][1] else: tmp_h[i][1] = h[i][1] # record the candidate best_tmp_h.append(tmp_h) # hill climb one dimension one time # See what the best solution amongst the neighbors is i_w, j_h = 0, 0 for i in range(len(best_tmp_w)): for j in range(len(best_tmp_h)): current_cost = costf(v, best_tmp_w[i] * best_tmp_h[j]) if current_cost <= min_cost: i_w = i j_h = j min_cost = current_cost # update w, h w = best_tmp_w[i_w] h = best_tmp_h[j_h] # If there's no improvement, then we've reached the top if min_cost == last_round_cost and patient_count >= 99: print "min_cost == last_round_cost" break else: last_round_cost = min_cost patient_count += 1 print "patient_count: ", patient_count print "min_cost: ", min_cost print "last_round_cost: ", last_round_cost #print "w: ", w #print "h: ", h return w, h if __name__ == '__main__': m1 = np.array([[1, 2, 3], [4, 5, 6]]) m2 = np.array([[1, 2], [3, 4], [5, 6]]) v = np.dot(m1, m2) print "np.shape(v): ", np.shape(v) print "v: ", v print " " w_optimization, h_optimization = hillclimb_2d(v=v, pc=2, costf=difcost_2d) print "w_optimization: ", w_optimization print "h_optimization: ", h_optimization print " " print "w_optimization * h_optimization: ", w_optimization * h_optimization

从结果可以看到,随机优化的结果并不好,之所以号称”万能优化算法“的随机优化算法,在这个场景下不管用了,主要原因如下:
- 随机优化技术(爬山法、模拟退火、遗传算法、SGD)本质上都是一种梯度导向(或近似梯度导向)的迭代式优化算法,它们要求待优化的损失函数具有连续可微的特性。通俗地说就是,每次仅仅轻微修改某一个维度中的少量值,损失函数就能获得一定程度的轻微优化。但是矩阵的因式分解这个任务对应的损失函数可能是完全不规则的损失曲线,轻微的修改带来的损失值的变更是无法预料的,可能很小,也可能突然非常大,这非常不利于损失函数进行迭代优化
- 矩阵的因式分解对应的损失函数可能是一个非常不规则的损失曲线,因此随机优化算法很容易陷入局部最优值而无法跳出
反过来也看到,那什么场景适合用随机优化算法呢?
- 图像检测与识别:图像的像素之间是渐变的,模型的权重调整也是连续渐变的
- 文本检测与分类:以恶意邮件检测为例,要判断一篇文档是否是恶意的,和该文档中出现的词(word)以及词频(word frequency)有关,好的文档和坏的文档之间的差距往往就是某些词是否出现,以及某些词出现多少次这些因素决定,因此,损失函数也是连续可微的,非常适合用随机优化算法来得到近似全局最优解
Relevant Link:
https://en.wikipedia.org/wiki/Non-negative_matrix_factorization https://blog.csdn.net/jeffery0207/article/details/84348117 http://latex.91maths.com/ 《Learning the parts of objects by non-negative matrix factorization》D.D.Lee,H.S.Seung
3. PCA(Principal Component Analysis)
广义上来说,PCA是一种基于线性降维的特征提取方法。
我们还是用人脸图像来阐述这个概念,我们的目的是利用PCA算法从一堆人脸图像数据中,找到一组共同特征,即所谓的大众脸特征,
# -*- coding: utf-8 -*- import logging from time import time from numpy.random import RandomState import matplotlib.pyplot as plt from sklearn.datasets import fetch_olivetti_faces from sklearn.cluster import MiniBatchKMeans from sklearn import decomposition # Display progress logs on stdout logging.basicConfig(level=logging.INFO, format='%(asctime)s %(levelname)s %(message)s') n_row, n_col = 2, 3 n_components = n_row * n_col image_shape = (64, 64) rng = RandomState(0) # ############################################################################# # Load faces data dataset = fetch_olivetti_faces(shuffle=True, random_state=rng) faces = dataset.data n_samples, n_features = faces.shape # global centering faces_centered = faces - faces.mean(axis=0) # local centering faces_centered -= faces_centered.mean(axis=1).reshape(n_samples, -1) print("Dataset consists of %d faces" % n_samples) def plot_gallery(title, images, n_col=n_col, n_row=n_row, cmap=plt.cm.gray): plt.figure(figsize=(2. * n_col, 2.26 * n_row)) plt.suptitle(title, size=16) for i, comp in enumerate(images): plt.subplot(n_row, n_col, i + 1) vmax = max(comp.max(), -comp.min()) plt.imshow(comp.reshape(image_shape), cmap=cmap, interpolation='nearest', vmin=-vmax, vmax=vmax) plt.xticks(()) plt.yticks(()) plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 0.04, 0.) # ############################################################################# # PCA estimators = [ ('Eigenfaces - PCA using randomized SVD', decomposition.PCA(n_components=n_components, svd_solver='randomized', whiten=True), True) ] # ############################################################################# # Plot a sample of the input data plot_gallery("First centered Olivetti faces", faces_centered[:n_components]) # ############################################################################# # Do the estimation and plot it for name, estimator, center in estimators: print("Extracting the top %d %s..." % (n_components, name)) t0 = time() data = faces if center: data = faces_centered estimator.fit(data) train_time = (time() - t0) print("done in %0.3fs" % train_time) # print the components_ components_ = estimator.components_ print('components_:', components_.shape, '\n**\n', components_) if hasattr(estimator, 'cluster_centers_'): components_ = estimator.cluster_centers_ else: components_ = estimator.components_ # Plot an image representing the pixelwise variance provided by the # estimator e.g its noise_variance_ attribute. The Eigenfaces estimator, # via the PCA decomposition, also provides a scalar noise_variance_ # (the mean of pixelwise variance) that cannot be displayed as an image # so we skip it. if (hasattr(estimator, 'noise_variance_') and estimator.noise_variance_.ndim > 0): # Skip the Eigenfaces case plot_gallery("Pixelwise variance", estimator.noise_variance_.reshape(1, -1), n_col=1, n_row=1) plot_gallery('%s - Train time %.1fs' % (name, train_time), components_[:n_components]) plt.show()

原始人脸图像中的前6张(普通人脸)

PCA从原始图像中提取出的6个独立通用特征(大众脸特征)

主成分矩阵
从运行结果中可以看到,PCA并没有任何关于人脸的先验信息,但是PCA分解后的主成分矩阵,还是基本呈现了一个人脸的轮廓,也就是说,PCA降维后得到的主成分矩阵,代表了原始人脸图像数据集中的通用特征。
主成分矩阵的每一行的维数都和原始图像的维数相同,区别在于不同像素点的权重分配不同,这点和NMF是一样的。
笔者提醒:
严格来说,PCA是一种降维算法,并不是一种独立特征提取算法,但是在满足特定前提假设条件下,PCA可以作为一种独立特征提取算法,
- 数据集中不同特征之间是彼此线性无关,或线性相关度不大的
- 数据集中包含的噪音数据不能太大,否则PCA很可能将噪音数据当做特征提取出来
Relevant Link:
https://www.cnblogs.com/LittleHann/p/6558575.html#_label3_1_4_1 https://scikit-learn.org/stable/auto_examples/decomposition/plot_faces_decomposition.html#sphx-glr-auto-examples-decomposition-plot-faces-decomposition-py
4. SVD与NMF之间的异同分析
前面我们已经各自讨论了SVD和NMF算法的原理和应用,从表面形式上看,它们二者似乎都是在做矩阵分解,这章我们来梳理总结一下它们二者各自的异同。
0x1:特征矩阵可解释性方面的差异
一般把SVD和NMF分解得到的U矩阵中的列称为特征向量,从形式上看,二者的特征向量有明显的区别:
- NMF的特征向量由于有非负的特点,因此不同向量之间的内积比大于零,不可能完全正交,说明NMF分解的特征向量存在一定信息冗余。同时非负性也带来了很好的物理解释性,比如
- 图像领域,一个非负特征向量可以解释为一副特征图,每个元素代表一个像素
- 文本领域,一个非负特征向量可以解释为一个”主题“,每个元素代表某个单词在主题中的重要程度
- SVD分解的特征向量彼此正交,但失去了非负的特点,可解释性变差
0x2:特征矩阵提供对原数据的近似逼近能力的差异
- SVD分解的特征向量在不同的维度都能够对样本向量做最好的近似,使近似后的结果与样本的误差在欧氏距离定义下达到全局最小
- NMF在分解过程中基数目需要预定确定,每次分解只是在一个确定维度下对样本的局部近似,其与样本的近似程度只能在欧式距离上达到局部最小,并且受初始值影响明显
0x3:样本特征提取效率方面的差异
- 在体现样本特征方面,SVD所抽取的ui对应最大奇异值σi,则样本在ui上的投影能量综合为Ei = (XTui)T(XTui) = σi2。很明显,对应奇异值越大的向量具有更大的样本投影能量,不同的特征ui在体现样本特征重要性方面有逐次之分
- NMF所抽取的特征向量彼此间重要程度差别不大,无主次之分
总体来说,在Forebenius范数意义下,SVD分解具有全局最优意义上的处理能力,但数据的可解释性不强;而NMF需要迭代计算,运算速度较慢,但分解的可解释性强,带有辅助约束的算法可使分解的矩阵有更大的稀疏性。另外,NMF分解针对不同类型的数据进行处理性能差异明显。
Relevant Link:
http://xueshu.baidu.com/usercenter/paper/show?paperid=2e99407850fe26f810cd1ddfa556caff&site=xueshu_se
5. 独立成分分析(Independent component analysis,ICA)
0x1:从鸡尾酒会问题(cocktail party problem)说起
鸡尾酒问题是一个经典的盲源信号分离(blind signal separation)问题。
假设在一个开party的房间里有两个人同时说话,房间里两个不同的位置上各放一个麦克风,各自记录了一段声音(时间信号),x1(t)和x2(t),这两段声音信号都包含了两个人说的话的混合,我们怎样得到他们分别说了什么话呢?
记源信号是s1(t)和s2(t),这个问题可以用以下等式描述:
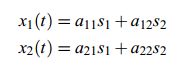
如果s1,s2是统计独立的随机信号,那么就可以用x1,x2去还原。ICA正是利用统计上的独立性从混合信号中分解出源信号的。
在讨论混合矩阵、权重特征这些具体概念,我们先将aij形象地理解是说话者跟麦克风的距离,如下图,

现在假设声源信号分别为”sinusoidal signal“和”square signal“,将其混合为一个混合信号,并加入一定的噪音干扰,来看一下PCA和ICA信号分解的结果,
import numpy as np import matplotlib.pyplot as plt from scipy import signal from sklearn.decomposition import FastICA, PCA # ############################################################################# # Generate sample data np.random.seed(0) n_samples = 2000 time = np.linspace(0, 8, n_samples) s1 = np.sin(2 * time) # Signal 1 : sinusoidal signal s2 = np.sign(np.sin(3 * time)) # Signal 2 : square signal S = np.c_[s1, s2] S += 0.2 * np.random.normal(size=S.shape) # Add noise S /= S.std(axis=0) # Standardize data # Mix data A = np.array([[1, 1], [0.5, 2]]) # Mixing matrix X = np.dot(S, A.T) # Generate observations # print X print "X: ", X # Compute ICA ica = FastICA(n_components=2) S_ = ica.fit_transform(X) # Reconstruct signals A_ = ica.mixing_ # Get estimated mixing matrix # We can `prove` that the ICA model applies by reverting the unmixing. assert np.allclose(X, np.dot(S_, A_.T) + ica.mean_) # For comparison, compute PCA pca = PCA(n_components=2) H = pca.fit_transform(X) # Reconstruct signals based on orthogonal components # ############################################################################# # Plot results plt.figure() models = [X, S, S_, H] names = ['Observations (mixed signal)', 'True Sources', 'ICA recovered signals', 'PCA recovered signals'] colors = ['red', 'steelblue', 'orange'] for ii, (model, name) in enumerate(zip(models, names), 1): plt.subplot(4, 1, ii) plt.title(name) for sig, color in zip(model.T, colors): plt.plot(sig, color=color) plt.subplots_adjust(0.09, 0.04, 0.94, 0.94, 0.26, 0.46) plt.show()
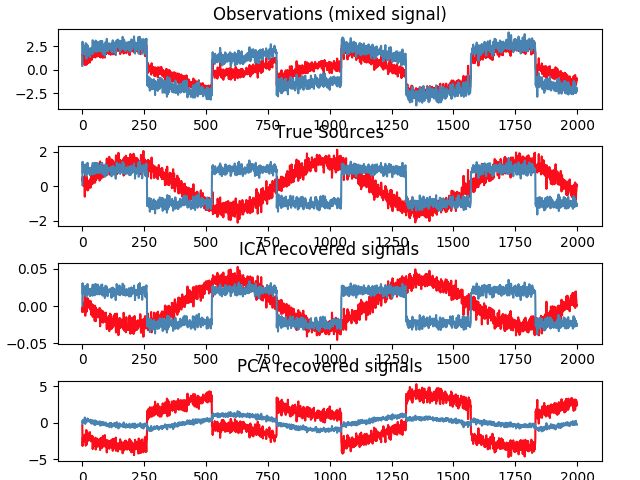
可以看到,ICA和PCA都成功地对原始混合信号进行了信号分解,得到了原始的信源分信号。
0x2:ICA算法形式化定义
类似于EM算法的思想,我们用隐变量模型(latent variables model)来描述ICA:
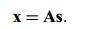
- x:由n个观测信号x1,x2,...,xn组成,x是可观测的信号序列
- s:由n个独立信号成分s1,s2,...,sn组成,s是不可观测的隐变量序列
- A:n*n的混合矩阵,用于对隐变量序列进行混合叠加,即

ICA模型成立的基本假设如下:
- si之间是统计独立的,它们是隐含变量,不能被直接观测到,A和s都是未知的
- si服从非高斯分布
- 混合矩阵A可逆
ICA算法的核心目标就是,基于观测得到的x序列,估计A矩阵和s隐序列。
0x3:ICA算法的基本前提
ICA可分解的前提是,隐变量序列si彼此独立,而高斯的不相关和独立是等价的,所以我们这里讨论高斯不相关性。
假设混合矩阵是方阵,如果s1和s2都是服从高斯分布,那么x1,x2也是高斯的,且不相关,方差为1 。联合概率密度如下:
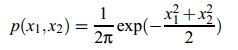
概率分布图如下,
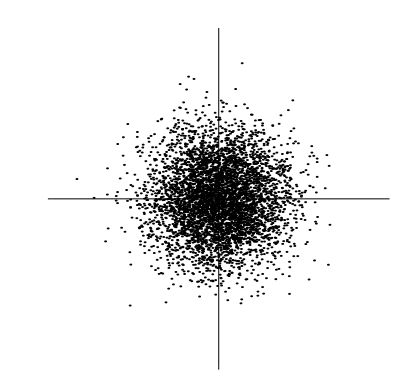
从图中可以看出,分布是对称的,这样就失去了方向信息,也就是A的列向量的信息。A也就预测不出来了。所谓的矩阵分解,本质就是在提取矩阵中的特征向量的方向信息。
可以证明,一个高斯分布经过正交变换以后仍然是那个高斯分布,而且变量之间仍是独立的,所以如果变量都是高斯分布的,我们只能知道A是一个正交变换,不能完全确定A。
所以,对数据集进行ICA分解的大前提是,数据集独立信号之间需要彼此独立。
0x4:ICA估计的理论推导
我们假设每个si有概率密度ps,那么给定时刻原信号(未知)的联合分布就是,


现在,我们必须对si假设一个概率分布函数F(x),才能继续求解W和s(EM算法中的E步骤)。但是F(x)不能是随机任意形式的,要满足两个性质:
- 单调递增和在[0,1]区间内
- 不能是高斯分布的概率密度,ICA可分解的大前提就是,si序列彼此之间互相独立
研究表明,sigmoid函数很合适,它的定义域为负无穷到正无穷,值域为0到1,同时还是一个对称函数(即期望/均值为0)。


现在 我们就求W了(EM算法中的M步骤),在给定训练样本{x(i)(x(i)1,x(i)2,x(i)3,...,,x(i)n);i = 1,...,m}后,对W的对数似然估计如下:
我们就求W了(EM算法中的M步骤),在给定训练样本{x(i)(x(i)1,x(i)2,x(i)3,...,,x(i)n);i = 1,...,m}后,对W的对数似然估计如下:
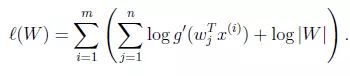
最后求导之后的结果公式如下,

0x5:算法运行流程
- 数据前置预处理
- 中心化:将数据零均值化,使数据处于坐标中心
- 白化/球化:白化是一种重要的预处理过程,其目的是为了降低输入数据的冗余性,使得经过白化处理的输入数据(i)特征之间相关性较低 (ii)所有特征具有相同的方差
- Expectation(E步骤)
- 假定si的概率密度ps,给定某时刻原信号的联合概率分布
- 求解p(x)
- 假定si的累计分布函数形式,例如sigmoid
- maximization(M步骤)
- 基于对si的函数形式假设,对W进行最大似然估计
- 似然函数对W求偏导,得到梯度
0x6:FastICA/固定点(Fixed-Point)算法 - ICA的衍生优化算法
我们知道,ICA算法的核心目的是从观测序列中得到一组彼此相对独立的si序列。因此度量si序列提取效果的好坏是衡量其独立性。
根据中心极限定理,若一随机变量X由许多相互独立的随机变量Si(i=1,2,...,N)之和混合组成,只要Si具有有限的均值和方差,则不论其为何种分布,随机变量X较Si更接近高斯分布。因此,在分离过程汇总,可通过对分离结果的非高斯性度量来表示分离结果间的互相独立性,当非高斯性度量达到最大时,则表明已完成对各个独立分量的分离。
度量费高斯性的方法有如下几种:
- 峭度
- 似然最大
- 负熵最大
Relevant Link:
https://blog.csdn.net/u014485485/article/details/78452820 https://danieljyc.github.io/2014/06/13/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A015-3--%E7%8B%AC%E7%AB%8B%E6%88%90%E5%88%86%E5%88%86%E6%9E%90ica%EF%BC%88independent-component-analysis%EF%BC%89/ https://www.dataivy.cn/blog/%E7%8B%AC%E7%AB%8B%E6%88%90%E5%88%86%E5%88%86%E6%9E%90independent-component-analysis_ica/ https://www.cnblogs.com/Determined22/p/6357291.html https://scikit-learn.org/stable/auto_examples/decomposition/plot_ica_blind_source_separation.html#sphx-glr-auto-examples-decomposition-plot-ica-blind-source-separation-py https://www.jianshu.com/p/de396e8cce15
6. 自动编码器(Auto-Encoder)
一言以蔽之,自动编码器是一种无监督的神经网络模型,它可以用于像
- 学习输入数据隐含特征(编码(coding))
- 独立特征提取:自动编码器学习到的新特征可以送入有监督学习模型中
- 特征降维:类似主成分分析PCA
- 生成与训练样本不同的新数据:这样自动编码器(变分自动编码器,Variational Autoencoders)即为生成式模型
- 数据降噪:通过保留核心有效特征,将原始数据中的噪点去除
之类的目的,同时AE用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。
一个最基本的AE架构如下图,包括编码和解码两个过程,
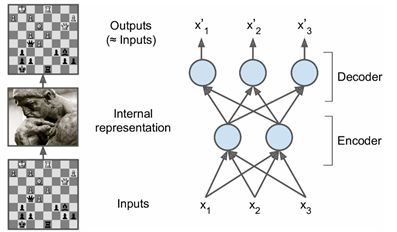
自动编码器的编码与解码
自动编码器是将输入 进行编码,得到新的特征 ,并且希望原始的输入 能够从新的特征 重构出来。编码过程如下:
可以看到,和神经网络结构一样,其编码过程本质上线性组合之后加上非线性的激活函数。
同时,利用新的特征 ,可以对输入 重构,即解码过程:
我们希望重构出的 和尽可能一致,可以采用最小化负对数似然的损失函数来训练这个模型:
一般情况下,我们会对自动编码器加上一些限制,常用的是使 ,这称为绑定权重(tied weights),本文所有的自动编码器都加上这个限制。有时候,我们还会给自动编码器加上更多的约束条件,去噪自动编码器以及稀疏自动编码器就属于这种情况,因为大部分时候单纯地重构原始输入并没有什么意义,我们希望自动编码器在近似重构原始输入的情况下能够捕捉到原始输入更有价值的信息,在这方面,embedding词向量嵌入有类似的思想。
这章我们介绍几种不同类型的Auto-Encoder,从不同角度理解AE的思想内涵。
0x1:全连接神经网络自编码器
# -*- coding: utf-8 -*- from keras.layers import Input, Dense from keras.models import Model from keras.datasets import mnist import numpy as np import matplotlib.pyplot as plt ######################## 先建立一个全连接的编码器和解码器 ######################## # this is the size of our encoded representations encoding_dim = 32 # 32 floats -> compression of factor 24.5, assuming the input is 784 floats # this is our input placeholder input_img = Input(shape=(784,)) # "encoded" is the encoded representation of the input encoded = Dense(encoding_dim, activation='relu')(input_img) # "decoded" is the lossy reconstruction of the input decoded = Dense(784, activation='sigmoid')(encoded) # this model maps an input to its reconstruction autoencoder = Model(input=input_img, output=decoded) ######################## 可以单独的使用编码器和解码器 # this model maps an input to its encoded representation encoder = Model(input=input_img, output=encoded) # create a placeholder for an encoded (32-dimensional) input encoded_input = Input(shape=(encoding_dim,)) # retrieve the last layer of the autoencoder model decoder_layer = autoencoder.layers[-1] # create the decoder model decoder = Model(input=encoded_input, output=decoder_layer(encoded_input)) ######################## 训练自编码器,来重构MNIST中的数字,这里使用逐像素的交叉熵作为损失函数,优化器为adam autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 准备MNIST数据,将其归一化和向量化,然后训练 (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:]))) x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:]))) print x_train.shape print x_test.shape autoencoder.fit(x_train, x_train, nb_epoch=50, batch_size=256, shuffle=True, validation_data=(x_test, x_test)) ######################## 可视化一下重构出来的输出 # encode and decode some digits # note that we take them from the *test* set encoded_imgs = encoder.predict(x_test) decoded_imgs = decoder.predict(encoded_imgs) n = 10 # how many digits we will display plt.figure(figsize=(20, 4)) for i in range(1, n): # display original ax = plt.subplot(2, n, i) plt.imshow(x_test[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) # display reconstruction ax = plt.subplot(2, n, i + n) plt.imshow(decoded_imgs[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()
AE解码后的结果如下,

可以看到,该全连接神经网络成功地从784维的图像矩阵中提取出了有效的32维低维特征信息,并且基于这32维特征,几乎无损地重建出了原始的输入图像。从这个例子中,我们可以感受到一些深度学习可解释性方面的内涵。
0x2:稀疏自编码器:为码字加上稀疏性约束
上一节中我们的隐层有32个神经元,这种情况下,一般而言自编码器学到的是PCA的一个近似。但是如果我们对隐层单元施加稀疏性约束(正则化约束)的话,会得到更为紧凑的表达,只有一小部分神经元会被激活。在Keras中,我们可以通过添加一个activity_regularizer达到对某层激活值进行约束的目的:
# -*- coding: utf-8 -*- from keras.layers import Input, Dense from keras.models import Model from keras.datasets import mnist from keras import regularizers import numpy as np import matplotlib.pyplot as plt ######################## 先建立一个全连接的编码器和解码器 ######################## # this is the size of our encoded representations encoding_dim = 64 # 64 floats -> compression of factor 24.5, assuming the input is 784 floats input_img = Input(shape=(784,)) # add a Dense layer with a L1 activity regularizer encoded = Dense(encoding_dim, activation='relu', kernel_regularizer=regularizers.l1(10e-5))(input_img) decoded = Dense(784, activation='sigmoid')(encoded) autoencoder = Model(input=input_img, output=decoded) ######################## 可以单独的使用编码器和解码器 # this model maps an input to its encoded representation encoder = Model(input=input_img, output=encoded) # create a placeholder for an encoded (32-dimensional) input encoded_input = Input(shape=(encoding_dim,)) # retrieve the last layer of the autoencoder model decoder_layer = autoencoder.layers[-1] # create the decoder model decoder = Model(input=encoded_input, output=decoder_layer(encoded_input)) ######################## 训练自编码器,来重构MNIST中的数字,这里使用逐像素的交叉熵作为损失函数,优化器为adam autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 准备MNIST数据,将其归一化和向量化,然后训练 (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:]))) x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:]))) print x_train.shape print x_test.shape autoencoder.fit(x_train, x_train, epochs=100, batch_size=256, shuffle=True, validation_data=(x_test, x_test)) ######################## 可视化一下重构出来的输出 # encode and decode some digits # note that we take them from the *test* set encoded_imgs = encoder.predict(x_test) decoded_imgs = decoder.predict(encoded_imgs) n = 10 # how many digits we will display plt.figure(figsize=(20, 4)) for i in range(1, n): # display original ax = plt.subplot(2, n, i) plt.imshow(x_test[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) # display reconstruction ax = plt.subplot(2, n, i + n) plt.imshow(decoded_imgs[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()

隐层设置为32维

隐层设置为64维
可以看到,隐层的维数越高,AE解码还原后的图像辨识度就相对越高。但总的来说,增加了稀疏约束后,编码出来的码字(隐层特征向量)都会更加稀疏。
在保持32维隐层的情况下,稀疏自编码器的在10000个测试图片上的码字均值为3.33,而之前的为7.30。
0x3:深度自编码器(DAE):堆叠自动编码器
我们可以将多个自编码器叠起来,本质上是提高深度神经网络的复杂度,提升特征提取效率,
# -*- coding: utf-8 -*- from keras.layers import Input, Dense from keras.models import Model from keras.datasets import mnist from keras import regularizers import numpy as np import matplotlib.pyplot as plt ######################## 先建立一个全连接的编码器和解码器 ######################## # this is the size of our encoded representations encoding_dim = 32 # 64 floats -> compression of factor 24.5, assuming the input is 784 floats input_img = Input(shape=(784,)) encoded = Dense(128, activation='relu')(input_img) encoded = Dense(64, activation='relu')(encoded) encoded = Dense(32, activation='relu')(encoded) decoded = Dense(64, activation='relu')(encoded) decoded = Dense(128, activation='relu')(decoded) decoded = Dense(784, activation='sigmoid')(decoded) autoencoder = Model(input=input_img, output=decoded) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 训练自编码器,来重构MNIST中的数字,这里使用逐像素的交叉熵作为损失函数,优化器为adam autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 准备MNIST数据,将其归一化和向量化,然后训练 (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:]))) x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:]))) print x_train.shape print x_test.shape autoencoder.fit(x_train, x_train, epochs=100, batch_size=128, shuffle=True, validation_data=(x_test, x_test)) ######################## 可视化一下重构出来的输出 # encode and decode some digits # note that we take them from the *test* set decoded_imgs = autoencoder.predict(x_test) n = 10 # how many digits we will display plt.figure(figsize=(20, 4)) for i in range(1, n): # display original ax = plt.subplot(2, n, i) plt.imshow(x_test[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) # display reconstruction ax = plt.subplot(2, n, i + n) plt.imshow(decoded_imgs[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()

效果比AE要好一些,当然,训练时间也增加了。
0x4:卷积自编码器:用卷积层搭建自编码器
当输入是图像时,使用卷积神经网络基本是一个较好的策略,在工程项目中,用于处理图像的自动编码器几乎都是卷积自动编码器。
- 卷积自编码器的编码器部分由卷积层和MaxPooling层构成
- MaxPooling负责空域下采样
- 卷积层负责提取细节特征信息
- 而解码器由卷积层和上采样层构成
- 卷积层负责信息传递
- 上采样层负责将卷积信息反卷回原始信号
# -*- coding: utf-8 -*- from keras.layers import Input, Dense from keras.models import Model from keras.datasets import mnist import numpy as np from keras.layers import Input, Dense, Convolution2D, MaxPooling2D, UpSampling2D from keras.models import Model import matplotlib.pyplot as plt ######################## 先建立一个编码器和解码器 ######################## input_img = Input(shape=(1, 28, 28)) x = Convolution2D(16, 3, 3, activation='relu', border_mode='same')(input_img) x = MaxPooling2D((2, 2), border_mode='same')(x) x = Convolution2D(8, 3, 3, activation='relu', border_mode='same')(x) x = MaxPooling2D((2, 2), border_mode='same')(x) x = Convolution2D(8, 3, 3, activation='relu', border_mode='same')(x) encoded = MaxPooling2D((2, 2), border_mode='same')(x) # at this point the representation is (8, 4, 4) i.e. 128-dimensional x = Convolution2D(8, 3, 3, activation='relu', border_mode='same')(encoded) x = UpSampling2D((2, 2))(x) x = Convolution2D(8, 3, 3, activation='relu', border_mode='same')(x) x = UpSampling2D((2, 2))(x) x = Convolution2D(16, 3, 3, activation='relu')(x) x = UpSampling2D((2, 2))(x) decoded = Convolution2D(1, 3, 3, activation='sigmoid', border_mode='same')(x) autoencoder = Model(input_img, decoded) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 训练自编码器,来重构MNIST中的数字,这里使用逐像素的交叉熵作为损失函数,优化器为adam autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 准备MNIST数据,将其归一化和向量化,然后训练 (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = np.reshape(x_train, (len(x_train), 1, 28, 28)) x_test = np.reshape(x_test, (len(x_test), 1, 28, 28)) print x_train.shape print x_test.shape #print "x_test: ", x_test autoencoder.fit(x_train, x_train, nb_epoch=100, batch_size=128, shuffle=True, validation_data=(x_test, x_test) ) ######################## 可视化一下重构出来的输出 # encode and decode some digits # note that we take them from the *test* set decoded_imgs = autoencoder.predict(x_test) n = 10 # how many digits we will display plt.figure(figsize=(20, 4)) for i in range(1, n): # display original ax = plt.subplot(2, n, i) plt.imshow(x_test[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) # display reconstruction ax = plt.subplot(2, n, i + n) plt.imshow(decoded_imgs[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()
0x5:AE隐层的特征向量可视化
这个小节,不介绍新的AE,我们来看看中间的码字长什么样,我们将中间码字reshape成4*32,
# -*- coding: utf-8 -*- from keras.layers import Input, Dense from keras.models import Model from keras.datasets import mnist from keras import regularizers import numpy as np import matplotlib.pyplot as plt ######################## 先建立一个编码器和解码器 ######################## # this is the size of our encoded representations encoding_dim = 128 # 64 floats -> compression of factor 24.5, assuming the input is 784 floats input_img = Input(shape=(784,)) # add a Dense layer with a L1 activity regularizer encoded = Dense(encoding_dim, activation='relu', kernel_regularizer=regularizers.l1(10e-5))(input_img) decoded = Dense(784, activation='sigmoid')(encoded) autoencoder = Model(input=input_img, output=decoded) ######################## 可以单独的使用编码器和解码器 # this model maps an input to its encoded representation encoder = Model(input=input_img, output=encoded) # create a placeholder for an encoded (32-dimensional) input encoded_input = Input(shape=(encoding_dim,)) # retrieve the last layer of the autoencoder model decoder_layer = autoencoder.layers[-1] # create the decoder model decoder = Model(input=encoded_input, output=decoder_layer(encoded_input)) ######################## 训练自编码器,来重构MNIST中的数字,这里使用逐像素的交叉熵作为损失函数,优化器为adam autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') ######################## 准备MNIST数据,将其归一化和向量化,然后训练 (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:]))) x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:]))) print x_train.shape print x_test.shape autoencoder.fit(x_train, x_train, epochs=100, batch_size=256, shuffle=True, validation_data=(x_test, x_test)) ######################## 可视化一下中间码字 # encode and decode some digits # note that we take them from the *test* set encoded_imgs = encoder.predict(x_test) decoded_imgs = decoder.predict(encoded_imgs) n = 10 # how many digits we will display plt.figure(figsize=(20, 8)) for i in range(1,n): ax = plt.subplot(1, n, i) plt.imshow(encoded_imgs[i].reshape(4, 4 * 8).T) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()

0x6:使用自动编码器进行图像去噪
从神经网络结构的角度看,AE本质上是一个"matrix-to-matrix"的”结构的滤波器,我们在很多语言翻译神经网络中也会看到类似结构。基于这种滤波器结构的AE网络,我们可以实现图像降噪方面的目的。
我们把训练样本用噪声污染,然后使解码器解码出干净的照片,以获得去噪自动编码器。首先我们把原图片加入高斯噪声,然后把像素值clip到0~1。

可以看到,降噪效果很不错,AE起到了滤波器的作用。
笔者思考:
在实际工程项目中,数据集中的噪点是一个很常见的问题,例如
- 图像中的白噪点
- 文本文档中出现的一些不常见词
- 由于采样过程引入的系统性噪点数据
当然,算法本身也有一些缓解手段来应对噪点问题(例如SVM中的soft-boundary),但是依旧无法完全规避数据噪点带来的过拟合和欠拟合问题。一个可行的做法是,对原始数据先通过AE进行降噪处理后,再输出机器学习模型(例如决策树),这样会得到更好的模型性能。
0x7:变分自编码器(Variational autoencoder,VAE):编码数据集的概率分布
我们已经知道,AE是一个独立特征提取的神经网络,在前面的章节中,我们介绍了通过AE直接在隐层得到码字特征向量,这是一种一步到位的做法。这小节,我们对前面的AE进行一些小修改,使得编码器学习到输入数据的隐变量模型(概率分布模型)。隐变量模型是连接显变量集和隐变量集的统计模型,隐变量模型的假设是显变量是由隐变量的状态控制的,各个显变量之间条件独立。
简单来说,变分编码器学习数据概率分布的一组参数(编码阶段)。并通过在这个概率分布中采样,你可以生成新的输入数据(解码阶段),即变分编码器是一个生成模型。
变分编码器的简要工作过程如下:
- 首先,编码器网络将输入样本x转换为隐空间的两个参数,记作z_mean和z_log_sigma,得到了这2个参数,就等于得到了隐藏的正态分布,z = z_mean + exp(z_log_sigma)*epsilon,epsilon是一个服从正态分布的张量。
- 然后,我们随机从隐藏的正态分布中采样得到数据点z。
- 最后,使用解码器网络将隐空间映射到显空间,即将z转换回原来的输入数据空间。
参数藉由两个损失函数来训练,
- 重构损失函数,该函数要求解码出来的样本与输入的样本相似(与之前的自编码器相同)
- 学习到的隐分布与先验分布的KL距离,作为一个正则化选项是可选的,它对学习符合要求的隐空间和防止过拟合有帮助
# -*- coding: utf-8 -*- from __future__ import absolute_import from __future__ import division from __future__ import print_function from keras.layers import Lambda, Input, Dense from keras.models import Model from keras.datasets import mnist from keras.losses import mse, binary_crossentropy from keras.utils import plot_model from keras import backend as K import numpy as np import matplotlib.pyplot as plt import argparse import os # reparameterization trick # instead of sampling from Q(z|X), sample epsilon = N(0,I) # z = z_mean + sqrt(var) * epsilon def sampling(args): """Reparameterization trick by sampling from an isotropic unit Gaussian. # Arguments args (tensor): mean and log of variance of Q(z|X) # Returns z (tensor): sampled latent vector """ z_mean, z_log_var = args batch = K.shape(z_mean)[0] dim = K.int_shape(z_mean)[1] # by default, random_normal has mean = 0 and std = 1.0 epsilon = K.random_normal(shape=(batch, dim)) return z_mean + K.exp(0.5 * z_log_var) * epsilon def plot_results(models, data, batch_size=128, model_name="vae_mnist"): """Plots labels and MNIST digits as a function of the 2D latent vector # Arguments models (tuple): encoder and decoder models data (tuple): test data and label batch_size (int): prediction batch size model_name (string): which model is using this function """ encoder, decoder = models x_test, y_test = data #os.makedirs(model_name, exist_ok=True) filename = os.path.join(model_name, "vae_mean.png") # display a 2D plot of the digit classes in the latent space z_mean, _, _ = encoder.predict(x_test, batch_size=batch_size) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y_test) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.savefig(filename) plt.show() filename = os.path.join(model_name, "digits_over_latent.png") # display a 30x30 2D manifold of digits n = 30 digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) # linearly spaced coordinates corresponding to the 2D plot # of digit classes in the latent space grid_x = np.linspace(-4, 4, n) grid_y = np.linspace(-4, 4, n)[::-1] for i, yi in enumerate(grid_y): for j, xi in enumerate(grid_x): z_sample = np.array([[xi, yi]]) x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size) figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) start_range = digit_size // 2 end_range = (n - 1) * digit_size + start_range + 1 pixel_range = np.arange(start_range, end_range, digit_size) sample_range_x = np.round(grid_x, 1) sample_range_y = np.round(grid_y, 1) plt.xticks(pixel_range, sample_range_x) plt.yticks(pixel_range, sample_range_y) plt.xlabel("z[0]") plt.ylabel("z[1]") plt.imshow(figure, cmap='Greys_r') plt.savefig(filename) plt.show() # MNIST dataset # 使用MNIST库来训练变分编码器 (x_train, y_train), (x_test, y_test) = mnist.load_data() image_size = x_train.shape[1] original_dim = image_size * image_size x_train = np.reshape(x_train, [-1, original_dim]) x_test = np.reshape(x_test, [-1, original_dim]) x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255 # network parameters input_shape = (original_dim, ) intermediate_dim = 512 batch_size = 128 latent_dim = 2 epochs = 50 # VAE model = encoder + decoder # build encoder model # 建立编码网络,将输入影射为隐分布的参数: inputs = Input(shape=input_shape, name='encoder_input') x = Dense(intermediate_dim, activation='relu')(inputs) z_mean = Dense(latent_dim, name='z_mean')(x) z_log_var = Dense(latent_dim, name='z_log_var')(x) # use reparameterization trick to push the sampling out as input # note that "output_shape" isn't necessary with the TensorFlow backend # 从这些参数确定的分布中采样,这个样本相当于之前的隐层值 z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var]) # instantiate encoder model encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder') encoder.summary() plot_model(encoder, to_file='vae_mlp_encoder.png', show_shapes=True) # build decoder model # 将采样得到的点映射回去重构原输入 latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(intermediate_dim, activation='relu')(latent_inputs) outputs = Dense(original_dim, activation='sigmoid')(x) # instantiate decoder model decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() plot_model(decoder, to_file='vae_mlp_decoder.png', show_shapes=True) # instantiate VAE model # 到目前为止我们做的工作需要实例化三个模型: # 1. 一个端到端的自动编码器,用于完成输入信号的重构 # 2. 一个用于将输入空间映射为隐空间的编码器 # 3. 一个利用隐空间的分布产生的样本点生成对应的重构样本的生成器 outputs = decoder(encoder(inputs)[2]) vae = Model(inputs, outputs, name='vae_mlp') if __name__ == '__main__': parser = argparse.ArgumentParser() help_ = "Load h5 model trained weights" parser.add_argument("-w", "--weights", help=help_) help_ = "Use mse loss instead of binary cross entropy (default)" parser.add_argument("-m", "--mse", help=help_, action='store_true') args = parser.parse_args() models = (encoder, decoder) data = (x_test, y_test) # VAE loss = mse_loss or xent_loss + kl_loss if args.mse: reconstruction_loss = mse(inputs, outputs) else: reconstruction_loss = binary_crossentropy(inputs, outputs) reconstruction_loss *= original_dim kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var) kl_loss = K.sum(kl_loss, axis=-1) kl_loss *= -0.5 vae_loss = K.mean(reconstruction_loss + kl_loss) vae.add_loss(vae_loss) vae.compile(optimizer='adam') vae.summary() plot_model(vae, to_file='vae_mlp.png', show_shapes=True) if args.weights: vae.load_weights(args.weights) else: # train the autoencoder vae.fit(x_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, None)) vae.save_weights('vae_mlp_mnist.h5') plot_results(models, data, batch_size=batch_size, model_name="vae_mlp") x_test_encoded = encoder.predict(x_test, batch_size=batch_size) plt.figure(figsize=(6, 6)) plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test) plt.colorbar() plt.show() # display a 2D manifold of the digits n = 15 # figure with 15x15 digits digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) # we will sample n points within [-15, 15] standard deviations grid_x = np.linspace(-15, 15, n) grid_y = np.linspace(-15, 15, n) for i, yi in enumerate(grid_x): for j, xi in enumerate(grid_y): z_sample = np.array([[xi, yi]]) * [1.0, 1.0] x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size) figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) plt.imshow(figure) plt.show()

编码器网络结构

解码器网络结构

总体VAE网络结构
因为我们的隐空间只有两维,所以我们可以可视化一下。我们来看看2D平面中不同类的近邻分布:

上图每种颜色代表一个数字,相近聚类的数字代表他们在结构上相似。
因为变分编码器是一个生成模型,我们可以用它来生成新数字。我们可以从隐平面上采样一些点,然后生成对应的显变量,即MNIST的数字:

可以看到,和上面的2D概率是对应的,不同的数字占据了不同的概率分布区域。
笔者思考:
从这个实验中,我们可以更加深刻的理解深度神经网络的可解释性的内涵,基本上来说,深度神经网络强大的拟合能力来源于它的高维非线性,同时因为正则化约束的存在,隐层中间态码字的权重分配会倾向于集中。这样,神经网络就可以同时具备对复杂问题和简单问题的拟合能力,总体上上说,深度神经网络的策略是:”尽量精确匹配,但是够用就行“。所以在MNIST这个问题上,AE只需要很少的隐层码字就可以提取出MNIST手写数字中的主要特征,但是如果面对的是一个更复杂的问题,AE就相对地需要更多的码字来进行有效编码。
相关的思想,田渊栋博士在它的论文《Luck Matters: Understanding Training Dynamics of Deep ReLU Networks》中进行了详细讨论,论文非常精彩,推荐读者朋友们。
Relevant Link:
https://blog.csdn.net/a819825294/article/details/53516980 https://zhuanlan.zhihu.com/p/31742653 https://zhuanlan.zhihu.com/p/67782029 https://github.com/keras-team/keras/blob/master/examples/variational_autoencoder.py https://keras-cn.readthedocs.io/en/latest/legacy/blog/autoencoder/
7. AE(Auto-Encoder)和PCA(principle component analysis)在降维效果方面的对比
这个章节,我们来做一个有趣的实验,通过图像处理这个具体问题,来探究AE和PCA在降维和独立特征提取方面性能的优劣。
0x1:AE和PCA各自的理论区别
- AE的理论基础是低维复合非线性函数对高维数据流形的近似逼近
- PCA的理论基础是最大熵定理,通过寻找熵值最大的top K个特征向量基,从而得到一个新的K维向量空间,将原始数据集投影到该新向量空间中,从而实现降维
从线性代数角度来看,这两种技术似乎有些异曲同工之妙,我们来通过实验验证一下这个猜想。
0x2:PCA和AE对MNIST手写数字的降维的效果对比
我们分别调用PCA和AE的API,将MNIST手写数字数据测试集降维到128维,并观察前10个降维后的图像,
# -*- coding: utf-8 -*- import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt from sklearn.decomposition import PCA from keras.datasets import mnist from keras.layers import Input, Dense from keras.models import Model from keras import regularizers if __name__ == '__main__': # load mnist data (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:]))) x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:]))) print x_train.shape print x_test.shape # 1. PCA: dimensionality reduction into 128 dim pca = PCA(n_components=128, whiten=True) pca.fit(x_train, x_train) X_train_pca = pca.transform(x_train) x_test_pca = pca.transform(x_test) print "x_test_pca: ", x_test_pca print "np.shape(x_test_pca): ", np.shape(x_test_pca) # show top100 sample which is been pca reduction samples = x_test_pca[:8] plt.figure(figsize=(12, 18)) for i in range(len(samples)): plt.subplot(10, 10, i + 1) plt.imshow(samples[i].reshape(32, 4), cmap='gray') plt.axis('off') plt.show() # 2. AE: dimensionality reduction into 128 dim encoding_dim = 128 input_img = Input(shape=(784,)) encoded = Dense(encoding_dim, activation='relu')(input_img) decoded = Dense(784, activation='sigmoid')(encoded) autoencoder = Model(input=input_img, output=decoded) encoder = Model(input=input_img, output=encoded) encoded_input = Input(shape=(encoding_dim,)) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') autoencoder.fit(x_train, x_train, epochs=100, batch_size=256, shuffle=True, validation_data=(x_test, x_test)) encoded_imgs = encoder.predict(x_test) n = 10 # how many digits we will display plt.figure(figsize=(20, 8)) for i in range(1, n): ax = plt.subplot(1, n, i) plt.imshow(encoded_imgs[i].reshape(4, 32).T) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()
PCA降维结果

AE降维结果
从肉眼上看,两种技术的降维效果差不多。那怎么定量评估这两种方案的实际效果(保真度和可还原度)呢?我们可以将它们降维后的数据集输入有监督学习算法(例如SVC),并评估有监督模型的预测性能,以此来评价前置降维算法的性能优劣。
# -*- coding: utf-8 -*- import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt from sklearn.decomposition import PCA from keras.datasets import mnist from keras.layers import Input, Dense from keras.models import Model from keras import regularizers from sklearn.svm import SVC from sklearn.metrics import accuracy_score if __name__ == '__main__': # load mnist data (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_test = x_test.astype('float32') / 255. x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:]))) x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:]))) print x_train.shape print "y_train: ", y_train print x_test.shape print "y_test: ", y_test # 1. PCA: dimensionality reduction into 128 dim pca = PCA(n_components=128, whiten=True) pca.fit(x_train, y_train) X_train_pca = pca.transform(x_train) x_test_pca = pca.transform(x_test) print "x_test_pca: ", x_test_pca print "np.shape(x_test_pca): ", np.shape(x_test_pca) # show top100 sample which is been pca reduction samples = x_test_pca[:8] plt.figure(figsize=(12, 18)) for i in range(len(samples)): plt.subplot(10, 10, i + 1) plt.imshow(samples[i].reshape(32, 4), cmap='gray') plt.axis('off') plt.show() # crate supervised learning model svc = SVC(kernel='rbf') svc.fit(X_train_pca, y_train) print 'accuracy for PCA: {0}'.format(accuracy_score(y_test, svc.predict(x_test_pca))) # 2. AE: dimensionality reduction into 128 dim encoding_dim = 128 input_img = Input(shape=(784,)) encoded = Dense(encoding_dim, activation='relu')(input_img) decoded = Dense(784, activation='sigmoid')(encoded) autoencoder = Model(input=input_img, output=decoded) encoder = Model(input=input_img, output=encoded) encoded_input = Input(shape=(encoding_dim,)) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') print "x_train: ", x_train autoencoder.fit(x_train, x_train, epochs=100, batch_size=256, shuffle=True, validation_data=(x_test, x_test)) X_train_ae = encoder.predict(x_train) x_test_ae = encoder.predict(x_test) n = 10 # how many digits we will display plt.figure(figsize=(20, 8)) for i in range(1, n): ax = plt.subplot(1, n, i) plt.imshow(X_train_ae[i].reshape(4, 32).T) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show() # crate supervised learning model svc = SVC(kernel='rbf') svc.fit(X_train_ae, y_train) print 'accuracy for AE: {0}'.format(accuracy_score(y_test, svc.predict(x_test_ae)))
分别用PCA和AE降维后的训练集训练得到的SVC有监督模型,对同样降维后测试集进行预测(降维算法这里充当一个前置样本预处理器),结果如下,
- PCA降维后的预测精确度:0.9782
- AE降维后的预测精确度:0.9779
从实验结果来看,AE和PCA的降维效果不相上下,不存在谁比谁有质的飞跃。读者朋友还可以用DAE代替PCA做同样的实验,结果也差不多,DAE的效果有轻微提升,但没有质的飞跃。
从这个实验中可以看出,我们不需要盲目崇拜深度学习,虽然现在深度学习是最热门的一个前沿论文领域,但是有着坚实理论基础的传统机器学习算法,依然有着强大的生命力以及不输深度学习的效果。我们学习要注重学习底层原理,不要盲目追新。
8. 独立特征提取在细分领域的衍生算法
本文介绍的几种独立特征提取算法基本上是和具体细分领域无关的通用算法。其实在文本降维、文本语义理解、话题提取、图像处理、音频信号处理等领域还有很多衍生的独立特征提取算法,例如:
- 图像处理领域
- 方向梯度直方图(Histogram of Oriented Gradient, HOG)特征:种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征
- SIFT(尺度不变特征变换):在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出、不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等
- SURF:SURF主要是把SIFT中的某些运算作了简化。SURF把SIFT中的高斯二阶微分的模板进行了简化,使得卷积平滑操作仅需要转换成加减运算,这样使得SURF算法的鲁棒性好且时间复杂度低
- ORB:ORB特征基于FAST角点的特征点检测与描述技术,具有尺度与旋转不变性,同时对噪声及透视仿射也具有不变性,良好的性能使得用ORB在进行特征描述时的应用场景十分广泛
- LBP(Local Binary Pattern):局部二值模式是一种描述图像局部纹理的特征算子,具有旋转不变性与灰度不变性等显著优点。LBP特征描述的是一种灰度范围内的图像处理操作技术,针对的是输入源为8位或16位的灰度图像
- 语义提取
- PLSA
- LDA
- HDP
- 向量空间模型(VSM):通过为语义单元赋予不同的权重以反映它们在语义表达能力上的差异,将文本看作有一组正交词条构成的矢量空间,将文本的语义单元看作是高维空间的维度
- wordembedding(词向量)。VSM背后的数学基础还是矩阵因式分解理论
- 概率模型:概率模型基于特征的概率分布表示文本数据,同时也考虑特征之间的概率依赖关系。例如二元独立概率模型、二元一阶相关概率模型、双柏松分布概率模型以及概率网络信息模型等
- 音频信号处理
- 过零率:过零率体现的是信号过零点的次数,体现的是频率特性。因为需要过零点,所以信号处理之前需要中心化处理
- 短时平均幅度差:音频具有周期特性,平稳噪声情况下利用短时平均幅度差可以更好地观察周期特性
9. 矩阵因式分解(独立特征提取)在安全领域的应用
本章内容由于涉及到一些工作上的内容和实验结果,笔者这里只放置一些简要思路,详细的实验过程和实验结果,有兴趣的朋友可以给我发邮件或者微信,我们可以离线交流。
0x1:基于Webshell文档独立特征提取的模型可解释性研究
- 通过对词向量矩阵进行因式分解,得到webshell黑样本的整体核心特征(特征矩阵的列向量),以此获得webshell检测模型可解释性方面的描述,即哪些词(word)占据了主要的权重分配
- 通过对词向量矩阵进行因式分解,得到每篇文档的特征主题(权重矩阵),将每篇文档(黑样本/白样本)都转换为一个主题列表,用一个更高维抽象的视角来看webshell黑白样本
代码里的blacksamples是笔者自己准备的一份webshell黑样本,读者朋友请自行准备。
# -*- coding: utf-8 -*- from time import time from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer from sklearn.decomposition import NMF, LatentDirichletAllocation from sklearn.datasets import fetch_20newsgroups from sklearn.externals import joblib import os import pickle import pandas import numpy as np n_samples = 2000 n_features = 1000 n_components = 10 n_top_words = 20 def print_top_words(model, feature_names, n_top_words): for topic_idx, topic in enumerate(model.components_): message = "Topic #%d: " % topic_idx message += " ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]) print(message) print() def load_webshell_apidata(): op_dict = { 'apicalls': [], 'path': [] } rootDir = "./blacksamples" for lists in os.listdir(rootDir): if lists == '.DS_Store': continue pickle_path = os.path.join(rootDir, lists, "vector.pickle") if os.path.exists(pickle_path): op = pickle.load(open(pickle_path, 'rb')) op_dict['apicalls'].append(' '.join(op['apicalls'])) # add as a apicall string "api api" op_dict['path'].append(op['path']) df = pandas.DataFrame(data=op_dict) return df print("Loading dataset...") t0 = time() dataset_apiifo = load_webshell_apidata() dataset = dataset_apiifo['apicalls'].values.tolist() dataset_path = dataset_apiifo['path'].values.tolist() #print "dataset: ", dataset data_samples = dataset[:n_samples] print "data_samples[:10]: ", data_samples[:10] print("done in %0.3fs." % (time() - t0)) print(" ") # Use tf-idf features for NMF. print("Extracting tf-idf features for NMF...") tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=n_features, stop_words='english') t0 = time() tfidf = tfidf_vectorizer.fit_transform(data_samples) print("done in %0.3fs." % (time() - t0)) print(" ") # Use tf (raw term count) features for LDA. print("Extracting tf features for LDA...") tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=n_features, stop_words='english') t0 = time() tf = tf_vectorizer.fit_transform(data_samples) print("done in %0.3fs." % (time() - t0)) print(" ") # Fit the NMF model print("Fitting the NMF model (Frobenius norm) with tf-idf features, " "n_samples=%d and n_features=%d..." % (n_samples, n_features)) t0 = time() nmf = NMF(n_components=n_components, random_state=1, alpha=.1, l1_ratio=.5).fit(tfidf) print("done in %0.3fs." % (time() - t0)) print(" ") print("\nTopics in NMF model (Frobenius norm):") tfidf_feature_names = tfidf_vectorizer.get_feature_names() print_top_words(nmf, tfidf_feature_names, n_top_words) # Fit the NMF model print("Fitting the NMF model (generalized Kullback-Leibler divergence) with " "tf-idf features, n_samples=%d and n_features=%d..." % (n_samples, n_features)) t0 = time() nmf = NMF(n_components=n_components, random_state=1, beta_loss='kullback-leibler', solver='mu', max_iter=1000, alpha=.1, l1_ratio=.5).fit(tfidf) print("done in %0.3fs." % (time() - t0)) print(" ") print("\nTopics in NMF model (generalized Kullback-Leibler divergence):") tfidf_feature_names = tfidf_vectorizer.get_feature_names() print_top_words(nmf, tfidf_feature_names, n_top_words) print("Fitting LDA models with tf features, " "n_samples=%d and n_features=%d..." % (n_samples, n_features)) lda = LatentDirichletAllocation(n_components=n_components, max_iter=5, learning_method='online', learning_offset=50., random_state=0) t0 = time() lda.fit(tf) print("done in %0.3fs." % (time() - t0)) print(" ") print("\nTopics in LDA model:") tf_feature_names = tf_vectorizer.get_feature_names() print_top_words(lda, tf_feature_names, n_top_words)
实验结果如下:
Topics in NMF model (Frobenius norm): Topic #0: stristr eval preg_match headers_sent error_reporting base64_decode gzinflate mail isref explode include defined require trim getcwd getenv getdir getfakedownloadpath get_info getdoccomment Topic #1: stripos eval gzuncompress setcookie time base64_decode header require_once dirname defined gzinflate require mail explode trim str_ireplace file_exists ini_get rtrim ltrim Topic #2: function_exists eval create_function preg_match gzdecode ob_start header defined error_reporting base64_decode gzinflate mail __lambda_func explode require_once block_bot chr set_time_limit strrev strtr Topic #3: base64_encode eval ini_set error_reporting stream_context_create implode strpos md5 base64_decode file_get_contents gzinflate mail preg_match explode fwrite getfilename fileperms filesize getfakedownloadpath getextension Topic #4: strlen __lambda_func str_repeat ceil str_replace create_function base64_decode xor_data__mut rtrim ltrim str_split trim mt_rand assert getcwd getextension getenv getdir getfakedownloadpath getfilename Topic #5: file_get_contents base64_decode eval mail gzinflate explode date_default_timezone_set strrev set_time_limit trim assert strtr getcwd getdir ymsumrlfso get_magic_quotes_gpc getenv getextension getfakedownloadpath getfilename Topic #6: ord chr strlen array_map eval preg_replace base64_decode range krzbnlqhvt getcwd getextension getenv getdoccomment getfakedownloadpath getfilename gethostbyname getdir get_current_user get_magic_quotes_gpc get_info Topic #7: define eval gzinflate __lambda_func set_time_limit get_magic_quotes_gpc islogin md5 header base64_decode mb_ereg_replace loginpage ob_start error_reporting dirname file_exists isref gethostbyname set_magic_quotes_runtime version_compare Topic #8: substr ltrim trim rtrim sizeof qfyuecrkyr ymsumrlfso str_replace str_split assert md5 stripos strlen wzgygjawpn __lambda_func error_reporting array_flip preg_replace strrpos get_info Topic #9: ini_set strlen set_time_limit unserialize xor_data__mut set_magic_quotes_runtime session_start printlogin md5 base64_decode wsologin implode get_magic_quotes_gpc assert clearstatcache defined ignore_user_abort error_reporting eval getdir () Fitting the NMF model (generalized Kullback-Leibler divergence) with tf-idf features, n_samples=2000 and n_features=1000... done in 0.111s. Topics in NMF model (generalized Kullback-Leibler divergence): Topic #0: eval error_reporting stristr preg_match defined gzuncompress base64_decode define require require_once headers_sent ini_get readdir opendir basename function_exists include header time create_function Topic #1: stripos gzuncompress setcookie time require_once set_error_handler dirname file_exists str_ireplace array_map version_compare unlink chdir gmdate ymsumrlfso get_magic_quotes_gpc getcwd getdir getdoccomment getenv Topic #2: create_function function_exists header gzdecode defined ob_start preg_match base64_decode __lambda_func chdir error_reporting pack xor_data__mut getfilename getfakedownloadpath gethostbyname getextension getenv getdoccomment ymsumrlfso Topic #3: stream_context_create base64_encode file_get_contents ini_set strpos md5 implode error_reporting function_exists eval gethostbyname getfilename getcwd getfakedownloadpath getinfo getextension getenv getdoccomment getdir ymsumrlfso Topic #4: str_replace strlen ceil str_repeat base64_decode __lambda_func substr string_n_random stream_context_create strrpos explode file_get_contents reads file_read mt_rand session_start get_magic_quotes_gpc version_compare md5 extension_loaded Topic #5: base64_decode file_get_contents strrev gzinflate mail strtr explode str_rot13 header set_time_limit date_default_timezone_set php_uname eval get_current_user __construct in_array htmlspecialchars html_n file_exists extension_loaded Topic #6: strlen unserialize ord filesize chr fclose is_file gzinflate base64_decode fopen ini_set range set_time_limit xor_data__mut fread mt_rand strstr function_exists explode readdir Topic #7: define strtolower mb_ereg_replace set_time_limit require urldecode get_magic_quotes_gpc md5 dirname strpos file_exists explode require_once ob_start islogin include strdir rand header ini_get Topic #8: substr trim assert str_split rtrim preg_replace sizeof array_flip wzgygjawpn ltrim md5 getwritingscriptpath gzcompress removeoldlogs isbot ymsumrlfso gmdate strrpos var_dump getfakedownloadpath Topic #9: ini_set set_time_limit strpos implode set_magic_quotes_runtime block_bot is_array class_exists unserialize ignore_user_abort wsologin xor_data__mut dirname microtime preg_match str_ireplace printlogin file_put_contents session_start clearstatcache () Fitting LDA models with tf features, n_samples=2000 and n_features=1000... done in 0.553s. Topics in LDA model: Topic #0: ymsumrlfso substr sizeof mt_rand string_n_random preg_replace wzgygjawpn chr eval strstr function_exists str_replace explode strtolower dirname reads base64_encode require_once file_read file_get_contents Topic #1: strlen ord stripos base64_decode eval gzuncompress xor_data__mut preg_replace __lambda_func str_replace chr create_function ltrim trim rtrim str_split ceil str_repeat substr ini_set Topic #2: mb_ereg_replace urldecode assert explode array_map loginpage array_flip print_r chr ini_get fopen ord eval is_callable in_array str_replace strrpos set_magic_quotes_runtime var_dump substr Topic #3: time is_dir filemtime fileowner fileperms filegroup posix_getpwuid is_link posix_getgrgid filesize basename str_replace urlencode realpath function_exists round define htmlspecialchars readdir is_file Topic #4: eval base64_encode ini_set error_reporting file_get_contents md5 base64_decode implode preg_match strpos stream_context_create strdir set_time_limit chop define str_replace getinfo set_magic_quotes_runtime session_start unserialize Topic #5: array_map ord chr krzbnlqhvt substr sizeof strlen xor_data__mut preg_replace base64_decode eval function_exists error_reporting str_replace str_split __lambda_func explode ini_set create_function unserialize Topic #6: makename trydir getfilename exists file_exists getdir call_user_func removeoldlogs remove md5 substr file_put_contents write gmdate strtotime read dds_debug round str_replace __construct Topic #7: is_file readdir filesize round preg_match strrev str_rot13 strtr basename is_dir posix_getgrgid posix_getpwuid is_link fileperms filegroup fileowner filemtime base64_decode count str_replace Topic #8: qfyuecrkyr strpos substr sizeof header ord define isref checkrequest strlen trim _runmagicquotes preg_replace chr base64_decode run clientip is_array function_exists isallowdip Topic #9: eval wzgygjawpn base64_decode stristr gzinflate function_exists preg_match create_function stripos error_reporting define header defined substr ob_start strtolower headers_sent gzdecode __lambda_func gzuncompress ()
我们打印了NMF提取出的10个独立主题其对应的top权重词,可以看到,例如eval、base64_decode这种词是经常出现的词。这也符合我们的先验预期,毕竟如果一个文件中经常出现这些词,则有很大可能说明该文件是一个黑文件。
0x2:基于ICA/NMF滤波器的异常登录流量检测
我们知道,一个时间区间内服务器的登录流水(ssh/rdp)有可能同时包含有恶意攻击者和合法管理员的登录行为,为了降噪的目的,我们可以在登录流水日志进入检测模块之前,进行ICA/NMF因式分解,从原始流量中先分解出攻击流量和正常流量(类似文章前面提到的MNIST手写数字降噪),之后对分别对攻击流量和正常流量的检测就会变得更容易。
Relevant Link:
https://scikit-learn.org/stable/modules/decomposition.html#nmf https://scikit-learn.org/stable/auto_examples/applications/plot_topics_extraction_with_nmf_lda.html#sphx-glr-auto-examples-applications-plot-topics-extraction-with-nmf-lda-py