机器学习实验三---使用朴素贝叶斯进行垃圾消息分类--python
机器学习实验三---使用朴素贝叶斯进行垃圾邮件分类
- 前言
- 一、朴素贝叶斯分类器
- 二、数据集处理
- 代码
-
- 1.训练算法:从词向量计算概率
- 2.朴素贝叶斯分类函数:
- 总结
-
- 问题及解决
- 实验小结:
- 参考文献
前言
机器学习的一个重要应用就是文档的自动分类,朴素贝叶斯是贝叶斯分类器的一个拓展,是用于文档分类的常用算法。
一、朴素贝叶斯分类器
朴素贝叶斯分类器采用了"属性条件独立性假设",对已知类别,假设所有属性相互独立。
基于属性条件独立性假设,可列式:
其中d为属性数目,xi为x在第i个属性上的取值。
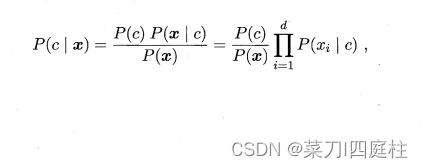
由于对所有类别来说P(x)相同,因此基于贝叶斯判定准则有:
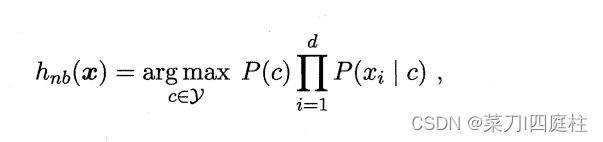
这就是朴素贝叶斯分类器的表达式。
朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率P( c ),并为每个属性估计条件概率P(xi | c)。
二、数据集处理
数据集来自自己手机内短信消息,选择垃圾消息和非垃圾消息各10条,共二十条,并使用翻译软件翻译成英文,垃圾消息数据展示(每一条消息为一行,由于短信消息较短还是可以接受的):

非垃圾消息和垃圾消息格式相同,由于内容隐私就不展示了
将数据集处理,将没条消息存为单个列表,并用空格切词,将开头大写改为小写(大小写英文单词统计时有差异)
将标签类别存入列表classVec中[0,0,0,1,1,1…]其中0表示非垃圾消息,1表示垃圾消息
def loadDataSet():
f1=open("./ch3/data/1.txt")
f0=open("./ch3/data/0.txt")
f0_list=f0.readlines()
f1_list=f1.readlines()
postingLost=[]
classVec=[]
#非垃圾消息
for line in f0_list:
line_split=line.split(' ')
line_split[-1]=line_split[-1][:-1]#去除回车
for i,x in enumerate(line_split):
low=x.lower()
line_split[i]=low
postingLost.append(line_split)
classVec.append(0)
#垃圾消息
for line in f1_list:
line_split=line.split(' ')
line_split[-1]=line_split[-1][:-1]#去除回车
for i,x in enumerate(line_split):
low=x.lower()#开头大写转化为小写
line_split[i]=low
postingLost.append(line_split)
classVec.append(1)
return postingLost,classVec
def createVocabList(dataset):
v=set([])
for doc in dataset:
v=v|set(doc) #用于求两个集合的并集
return v
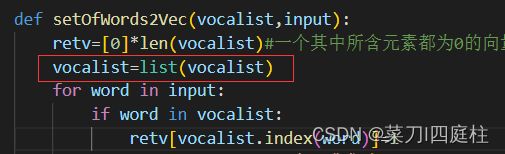
def setOfWords2Vec(vocalist,input):
retv=[0]*len(vocalist)#一个其中所含元素都为0的向量
vocalist=list(vocalist)
for word in input:
if word in vocalist:
retv[vocalist.index(word)]=1
else:print("词: %s 不在词典集中"%word)
return retv
if __name__=='__main__':
listOp,listclass=loadDataSet()
myVocabList=createVocabList(listOp)
print(myVocabList)
运行上述代码,会发现这里不会出现重复的单词

代码
1.训练算法:从词向量计算概率
为代码如下:
计算每个类别中的文档数目 :
对每篇训练文档:
如果词条出现在文档中–>增加改词条的计数值
增加所有词条的计数值
对每个类别:
对每个词条:
将该词条数目除以总词条数目得到概率条件
返回每个类别的条件概率
使用代码实现上述伪代码:
#朴素贝叶斯分类器训练函数
def trainNB0(trainM,trainC):
numTrain=len(trainM)
numWords=len(trainM[0])
pspam=sum(trainC)/float(numTrain)#初始化概率
#降低乘数为0的影响
p0num=ones(numWords)
p1num=ones(numWords)
p0denom=2.0
p1denom=2.0
for i in range(numTrain):
if trainC[i]==1:
p1num+=trainM[i]
p1denom+=sum(trainM[i])
else:
p0num+=trainM[i]
p0denom+=sum(trainM[i])
p1v=log10(p1num/p1denom)
p0v=log10(p0num/p0denom)
return p0v,p1v,pspam
利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类型的概率,及计算p(w0|1)p(w1|1)p(w2|1).如果其中一个概率值为0,那么最后的乘积也为0,为降低这种影响,可以将所有单词的出现数初始化为1,并将分母初始化为2。
2.朴素贝叶斯分类函数:
#朴素贝叶斯分类函数
def classifyNB(vec2classify,p0v,p1v,pClass1):
p1=sum(vec2classify*p1v)+log10(pClass1)
p0=sum(vec2classify*p0v)+log10(1.0-pClass1)
if p1>p0:
return 1
else:
return 0
测试代码(使用相同发件员的消息作为测试)
def testingNB():
listOPosts,listClasses=loadDataSet()
myVocList=createVocabList(listOPosts)
trainMat=[]
for postionDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocList,postionDoc))
p0v,p1v,pAb=trainNB0(array(trainMat),array(listClasses))
testEntry=['your', 'takeaway', 'delivered', 'designated',\
'place.', 'please', 'pick', 'it', 'up', 'as', 'soon', 'possible.', 'rider', 'phone']
thisDoc=array(setOfWords2Vec(myVocList,testEntry))
print(testEntry,"测试分类为:",classifyNB(thisDoc,p0v,p1v,pAb))
testEntry=['hi,', 'platform', 'presents', 'you', 'with', \
'single', 'model', 'lightweight', 'service', 'coupon,', 'valid', 'days,', 'please', 'go', 'to', 'use', 'it']
thisDoc=array(setOfWords2Vec(myVocList,testEntry))
print(testEntry,"测试分类为:",classifyNB(thisDoc,p0v,p1v,pAb))
if __name__=='__main__':
testingNB()
测试结果:

总结
问题及解决
- ‘set’ object has no attribute ‘index’
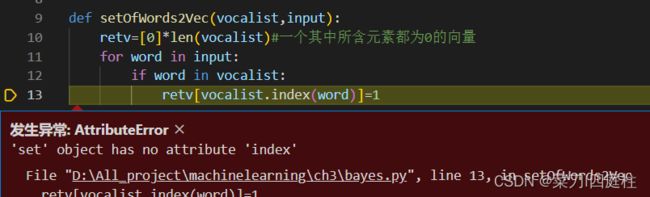
类型强转为list类型
实验小结:
1.计算p(w0|1)p(w1|1)…p(wn|1)时可能会导致下溢出,从而得到不正确的答案,解决办法就是对乘积结果取对数。
2.实验不足,数据量不足,结果不准确,改进方法:进行交叉验证
参考文献
<<机器学习实战>>—Peter Harrington