深度学习Review【三】序列、RNN、LSTM(GRU)、DRNN
课程地址
动手学深度学习笔记【三】
- 一、序列模型
-
- 马尔科夫假设
- 潜变量
- 二、RNN 循环神经网络
-
- 衡量语言模型
- 梯度剪裁
- torch实现
- 三、GRU 门控循环单元
-
- 思路
- torch实现
- 四、LSTM
-
- torch实现
- 五、Deep RNN 深度循环
-
- torch实现
- 六、BRNN双向循环网络
-
- torch实现
一、序列模型
序列数据:实际中很多数据是随着时间变化而变化。
根据条件概率一直x1到xT的概率可以算出x的概率。

自回归模型:用的数据,预测现在的数据
马尔科夫假设
当前数据只和t个过去的数据相关

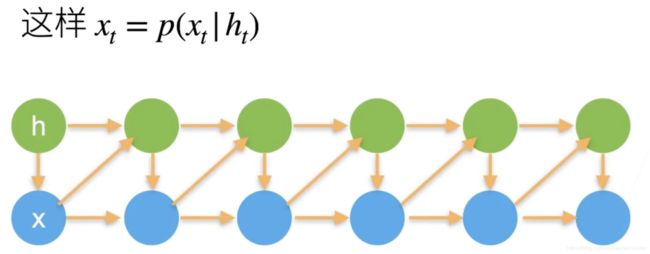
潜变量
引入潜变量h来表示过去的信息
绿色代表不同的潜变量h,每次在改变x后计算新的潜变量h
二、RNN 循环神经网络
适用于100以内的序列
用当前时刻的输入预测下一时刻的输出,“你好世界”,输出的“好”是由输入的“你”和“好”预测出来的。

W[hx]表示从x到h的权重
衡量语言模型
- 平均交叉熵
- 困惑度:指数(1表示完美,无穷表示垃)
梯度剪裁
可以防止梯度爆炸,如果梯度长度超过某个值,就拖回到这个值。

torch实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35 #句子长度为35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
#一个具有256个隐藏单元的单隐藏层的循环神经网络层 rnn_layer
num_hiddens = 256
rnn_layer = rnn.RNN(num_hiddens)
rnn_layer.initialize()
class RNNModel(nn.Module):
"""循环神经网络模型。"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer #不包括输出层
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),`num_directions`应该是2,否则应该是1。
# 构造输出层
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state) # 中间隐藏层的Y
# 全连接层首先将`Y`的形状改为(`时间步数`*`批量大小`, `隐藏单元数`)。
# 它的输出形状是 (`时间步数`*`批量大小`, `词表大小`)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))#把时间和批量这两个维度和到一起
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# `nn.GRU` 以张量作为隐藏状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# `nn.LSTM` 以张量作为隐藏状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,
use_random_iter=False):
"""训练模型(定义见第8章)。"""
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(
net, train_iter, loss, updater, device, use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
三、GRU 门控循环单元
是LSTM的简化,正常情况下效果差不多。
思路
由于并不是每个值都是同等重要的,所以设置更新门(关注的机制)和重置门(遗忘机制)来只记住相关的值(关键字、关键点、切换场景时的帧 )。

R和Z本质是用sigmoid对全连接层做激活
R(重置门):0到1之间的数,若为0表示之前的东西全不要
Z(更新门):0到1之间的数,若为1表示不用之前的东西更新
改进:多了几个可以计算的权重
~H是候选隐含状态:根据X、R和W、之前的H输出当前候选隐含状态
H是隐含状态:根据Z、~H、之前的H的值输出新的隐含状态

torch实现
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
四、LSTM
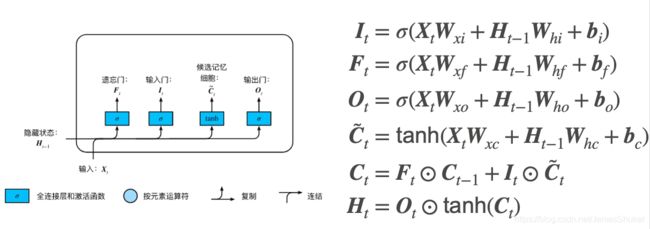
先于GRU提出,四套W权重
遗忘门F:将值收缩为0
输入门I:决定是否忽略输入数据
输出门O:决定是否使用隐含状态( 当前的C)
候选记忆单元~C:包括了 前一个状态的H(相当于GRU中的 当前状态的H)
记忆单元C:C的数值区间比较大,是否使用 之前的C 和 ~C
隐含状态H:将C的值稳定在1和-1之间,根据O控制要不要输出
torch实现
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
五、Deep RNN 深度循环
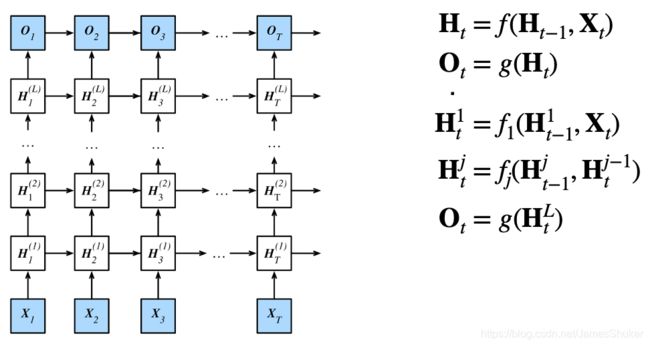
输入-隐藏层-输出
通过增加隐藏层的个数,来加深RNN,获得更多的非线性性,增大可处理的序列长度。
后一个隐藏层的输出是上一个隐藏层的输出,同时下一个时刻的输入是上一个时刻的输出。
torch实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
#num layers是隐藏层的个数
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
# Pytorch的LSTM不带输出层
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
六、BRNN双向循环网络
一个词取决于过去和未来的上下文,所以不能用于推测下一个词,只能做完词填空,对一个句子做特征提取,Eg:翻译、改写。
一个前向RNN隐藏层,一个后向RNN隐藏层,合并(concat)两个隐状态得到输出,两个隐藏层为一组,这两组隐藏层的权重不共享。

torch实现
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置'bidirective=True'来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)