爬虫(三)-笔记
scrapy的概念和流程
1. scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了
Twisted异步网络框架,可以加快下载速度。
Scrapy文档地址
2. scrapy框架的作用
少量的代码,就能够快速的抓取
3. scrapy的工作流程
3.1 回顾之前的爬虫流程
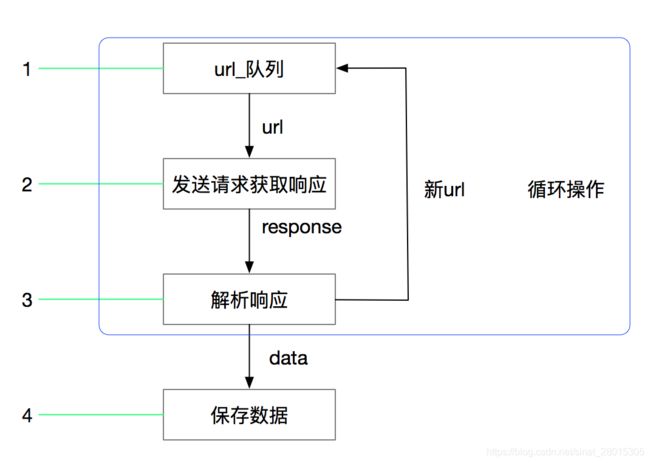
3.2 上面的流程可以改写为

3.3 scrapy的流程

其流程可以描述如下:
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
spiders模块中,解析数据为以下两种- 若解析出来数据,构造items对象,交由引擎进行数据提取,步骤5
- 若解析出来是新的url,则步骤4
- 爬虫提取数据—>引擎—>管道处理和保存数据
注意:
- 图中中文是为了方便理解后加上去的
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
3.4 scrapy的三个内置对象
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
3.5 scrapy中每个模块的具体作用

注意:
- 爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等
小结
- scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
- scrapy框架的运行流程以及数据传递过程:
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
spiders模块中,解析数据为以下两种- 若解析出来数据,构造items对象,交由引擎进行数据提取,步骤5
- 若解析出来是新的url,则步骤4
- 爬虫提取数据—>引擎—>管道处理和保存数据
- scrapy框架的作用:通过少量代码实现快速抓取
- 掌握scrapy中每个模块的作用:
引擎(engine):负责数据和信号在不同模块间的传递
调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象
下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎
爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎
管道(pipeline):处理引擎传递过来的数据,比如存储
下载中间件(downloader middleware):可以自定义的下载扩展,比如设置代理ip
爬虫中间件(spider middleware):可以自定义request请求和进行response过滤,与下载中间件作用重复
scrapy的入门使用
1 安装scrapy
命令:
sudo apt-get install scrapy
或者:
pip/pip3 install scrapy
2 scrapy项目开发流程
- 创建项目:
scrapy startproject mySpider - 生成一个爬虫:
scrapy genspider itcast itcast.cn - 提取数据:
根据网站结构在spider中实现数据采集相关内容 - 保存数据:
使用pipeline进行数据后续处理和保存
3. 创建项目
通过命令将scrapy项目的的文件生成出来,后续步骤都是在项目文件中进行相关操作,下面以抓取传智师资库来学习scrapy的入门使用:http://www.itcast.cn/channel/teacher.shtml
创建scrapy项目的命令:
scrapy startproject <项目名字>
示例:
scrapy startproject myspider
生成的目录和文件结果如下:

4. 创建爬虫
通过命令创建出爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。
命令:
在项目路径下执行:
scrapy genspider <爬虫名字> <允许爬取的域名>
爬虫名字: 作为爬虫运行时的参数
允许爬取的域名: 为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不通则被过滤掉。
示例:
cd myspider
scrapy genspider itcast itcast.cn
生成的目录和文件结果如下:

5. 完善爬虫
在上一步生成出来的爬虫文件中编写指定网站的数据采集操作,实现数据提取
1.修改起始url–start_urls
2.检查修改允许的域名–allowed_domains
3.在parse()中实现爬取逻辑
5.1 在/myspider/myspider/spiders/itcast.py中修改内容如下:
import scrapy
class ItcastSpider(scrapy.Spider): # 继承scrapy.Spider
# 爬虫名字
name = 'itcast'
# 允许爬取的范围
allowed_domains = ['itcast.cn']
# 设置起始的url地址,只需要设置即可,通常框架会自动创建为请求发送
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
# 数据提取的方法,接受下载中间件传过来的response
# 通常用于起始url对应响应的解析
def parse(self, response):
# scrapy的response对象可以直接进行xpath
names = response.xpath('//div[@class="tea_con"]//li/div/h3/text()')
print(names)
# 获取具体数据文本的方式如下
# 分组
li_list = response.xpath('//div[@class="tea_con"]//li')
for li in li_list:
# 创建一个数据字典
item = {}
# 利用scrapy封装好的xpath选择器定位元素,并通过extract()或extract_first()来获取结果
item['name'] = li.xpath('.//h3/text()').extract_first() # 老师的名字
item['level'] = li.xpath('.//h4/text()').extract_first() # 老师的级别
item['text'] = li.xpath('.//p/text()').extract_first() # 老师的介绍
print(item)
补充:
import scrapy
class ItcastSpider(scrapy.Spider):
name = 'itcast'
# 2. 检查域名
allowed_domains = ['itcast.cn']
# 1.修改起始url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
# 3.实现爬取逻辑
def parse(self, response):
# # 定义对于关于网站的相关参数
# with open('./itcast.html', 'wb') as f:
# f.write(response.body)
# 获取所有教师节点
node_list = response.xpath('//div[@class="maincon"]//li')
# 遍历教师节点列表
print(len(node_list))
for node_ in node_list:
temp = {}
# xpath方法返回的是一个选择器对象列表
# temp['pic'] = node_.xpath('./div[1]/img/@src') # [],
# 获取选择器对象
# temp['pic'] = node_.xpath('./div[1]/img/@src')[0] # [] = 'http://www.itcast.cn' + node_.xpath('./div[1]/img/@src')[0].extract() # http://www.itcast.cn/images/teacher/2020382416385000.jpg
temp['name'] = node_.xpath('./div[2]/h2/text()').extract_first()
temp['title'] = node_.xpath('./div[2]/h2/span/text()')[0].extract()
# temp['exp'] = node_.xpath('./div[2]/h3/span[2]/text()')[0].extract() # 部分老师没有该span
temp['info'] = node_.xpath('./div[3]/p/text()').extract_first()
# 爬虫中通常使用yield进行返回,return 处理翻页等情况并不好
yield temp

注意:
- scrapy.Spider爬虫类中必须有名为parse的解析
- 如果网站结构层次比较复杂,也可以自定义其他解析函数
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制,在后续的会学习如何在解析函数中构造发送请求
- 启动爬虫的时候注意启动的位置,是在项目路径下启动
- parse()函数中使用yield返回数据,注意:解析函数中的yield能够传递的对象只能是:BaseItem, Request, dict, None
5.2 定位元素以及提取数据、属性值的方法
解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
- 额外方法extract():返回一个包含有字符串的列表
- 额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None
5.3 response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
print(response.url) # http://www.itcast.cn/channel/teacher.shtml print(response.request.url # http://www.itcast.cn/channel/teacher.shtml#ajavaee - response.headers:响应头
- response.requests.headers:当前响应的请求头
print(response.headers) """ {b'Server': [b'Tengine'], b'Content-Type': [b'text/html'], b'Date': [b'Sat, 19 Jun 2021 14:26:32 GMT'], b'Vary': [b'Accept-Encoding'], b'Access-Control-Allow-Origin': [b'http://www.itheima.com'], b'Access-C ontrol-Allow-Credentials': [b'true'], b'Access-Control-Allow-Methods': [b'GET, POST, PUT, DELETE'], b'Access-Control-Allow-Headers': [b'*'], b'Ali-Swift-Global-Savetime': [b'1624112792'], b'Via': [b'cache20 .l2cn2650[117,117,200-0,M], cache26.l2cn2650[118,0], kunlun9.cn2411[120,119,200-0,M], kunlun7.cn2411[122,0]'], b'X-Cache': [b'MISS TCP_MISS dirn:-2:-2'], b'X-Swift-Savetime': [b'Sat, 19 Jun 2021 14:26:32 GM T'], b'X-Swift-Cachetime': [b'0'], b'Timing-Allow-Origin': [b'*'], b'Eagleid': [b'7013001b16241127922745178e']}""" print(response.request.headers) """ 由于UA中会直接显示Scrapy信息,该部分通常要在中间件或者参数来进行修改 {b'Accept': [b'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'], b'Accept-Language': [b'en'], b'User-Agent': [b'Scrapy/2.5.0 (+https://scrapy.org)'], b'Accept-Encoding': [b'gzip, deflate']} """ - response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
6 保存数据
利用管道pipeline来处理(保存)数据
6.1 在pipelines.py文件中定义对数据的操作
- 定义一个管道类
- 重写管道类的process_item方法
- process_item方法处理完item之后必须返回给引擎
import json
class MyspiderPipeline():
# 爬虫文件中提取数据的方法每yield一次item,就会运行一次
# 该方法为固定名称函数
def process_item(self, item, spider):
print(item)
return item
6.2 在settings.py配置启用管道
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'myspider.pipelines.MyspiderPipeline': 300
}
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。
配置项中值为管道的使用顺序,设置的数值约小越优先执行,该值一般设置为1000以内。如:
ITEM_PIPELINES = {
'Myspider.pipelines.MyspiderPipeline': 300, # 后执行
'Myspider.pipelines.MyspiderPipeline': 299, # 先执行
}
启用成功
[scrapy.middleware] INFO: Enabled item pipelines:
['Myspider.pipelines.MyspiderPipeline']
# pipeline中print
{'pic': 'http://www.itcast.cn/images/teacher/20210531170511422.jpg', 'name': '郝老师', 'title': '课程研究员', 'info': ' 5年软件开发及教学经验,Android、Java方向高
级软件开发工程师,研发项目涉及教育、新闻、娱乐直播等。\r\n对Android、JavaSE、JavaWEB、MySQL、前端等技术深入研究。'}
# pipeline 启用后打印
2021-06-20 15:40:56 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.itcast.cn/channel/teacher.shtml>
{'pic': 'http://www.itcast.cn/images/teacher/20210531170511422.jpg', 'name': '郝老师', 'title': '课程研究员', 'info': ' 5年软件开发及教学经验,Android、Java方向高
级软件开发工程师,研发项目涉及教育、新闻、娱乐直播等。\r\n对Android、JavaSE、JavaWEB、MySQL、前端等技术深入研究。'}
保存到文件中
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class MyspiderPipeline:
def __init__(self):
self.file = open('./itcast.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 默认使用完管道后,需要将数据返回给引擎
# print(item)
# 向文件中保存
# 1.将dict 序列化 , ensure_ascii=False和encoding = 'utf-8'保证中文数据保存
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
# 2.将数据写入文件
self.file.write(json_data)
return item
# open 方式要确保文件写入后关闭,实现__del__方法
def __del__(self):
self.file.close()
itcast.json
{"pic": "http://www.itcast.cn/images/teacher/2020382416385000.jpg", "name": "娄老师", "title": "课程研究员", "info": " 原北京六六八八项目经理,主导大型电商项目E动商网的研发。后曾在多家软件企业担任系统架构师、技术负责人。2014年在大唐高鸿某事业部担任技术总监,主导“敲敲运营平台”的开发。 精通dubbo 、spring cloud等分布式架构技术以及vue.js等前端框架。"},
{"pic": "http://www.itcast.cn/images/teacher/2020192914192000.jpg", "name": "王老师", "title": "课程研究员", "info": " 10多年IT从业经验,北大计算机毕业,曾在中科软从事系统分析与架构工作,精通OOM、PD、DDD建模;对计算机原理、体系结构、常用算法有深入研究;熟练分布式和微服务环境下的主流技术架构。"},
{"pic": "http://www.itcast.cn/images/teacher/2020522416524300.jpg", "name": "王老师", "title": "课程研究员", "info": " 曾经在美国comodo担任技术研究员;参与过创业公司技术合伙人,担任技术经理,负责团队从移动端到后台java平台,硬件,大数据平台搭建,及相关人员管理;\r\n担任过国美电商项目虚拟团队技术架构师,参与电商平台架构优化。拥有丰富的Java教学和培训经验。"},
{"pic": "http://www.itcast.cn/images/teacher/2020202914205400.jpg", "name": "周老师", "title": "课程研究员", "info": " 南开大学计算机毕业,曾在方正国际,车音网等公司任职,历任高级架构师、技术经理等职.精通互联网分布式架构设计和J2EE开发,精通Spring\\SpringMVC\\mybatis\\dubbo\\等主流开发框架及Redis\\MQ\\Solr第三方中间件.主持开发过张家港医疗信息平台,长城车联网等多个大型互联网应用平台。"},
...
7. 运行scrapy
命令:在项目目录下执行scrapy crawl <爬虫名字>
示例:scrapy crawl itcast
命令:关闭日志并在项目目录下执行scrapy crawl <爬虫名字> --nolog
示例:scrapy crawl itcast --nolog
小结
- scrapy的安装:pip install scrapy
- 创建scrapy的项目: scrapy startproject myspider
- 创建scrapy爬虫:在项目目录下执行 scrapy genspider itcast itcast.cn
- 运行scrapy爬虫:在项目目录下执行 scrapy crawl itcast
- 解析并获取scrapy爬虫中的数据:
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
- extract() 返回一个包含有字符串的列表
- extract_first() 返回列表中的第一个字符串,列表为空返回None,不为空返回列表第一个元素
- scrapy管道的基本使用:
- 完善pipelines.py中的process_item函数
- 在settings.py中设置开启pipeline
- response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
scrapy数据建模与请求
1. 数据建模
通常在做项目的过程中,在items.py中进行数据建模
1.1 为什么建模
- 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
- 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
1.2 如何建模
在items.py文件中定义要提取的字段:
class MyspiderItem(scrapy.Item):
name = scrapy.Field() # 讲师的名字
title = scrapy.Field() # 讲师的职称
desc = scrapy.Field() # 讲师的介绍
1.3 如何使用模板类
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
Myspider/Myspider/spiders/itcast.py:
from myspider.items import MyspiderItem # 导入Item,注意路径
...
def parse(self, response)
item = MyspiderItem() # 实例化后可直接使用
item['name'] = node.xpath('./h3/text()').extract_first()
item['title'] = node.xpath('./h4/text()').extract_first()
item['desc'] = node.xpath('./p/text()').extract_first()
print(item)
完整版:
import scrapy
from Myspider.items import MyspiderItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
# 2. 检查域名
allowed_domains = ['itcast.cn']
# 1.修改起始url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee']
# 3.实现爬取逻辑
def parse(self, response):
# # 定义对于关于网站的相关参数
# with open('./itcast.html', 'wb') as f:
# f.write(response.body)
# 获取所有教师节点
node_list = response.xpath('//div[@class="maincon"]//li')
# 遍历教师节点列表
for node_ in node_list:
# 通过item代替原有dict 进行数据保存
# temp = {}
# 实例化item
item = MyspiderItem()
# xpath方法返回的是一个选择器对象列表
# temp['pic'] = node_.xpath('./div[1]/img/@src') # [],
# 获取选择器对象
# temp['pic'] = node_.xpath('./div[1]/img/@src')[0] # [] = 'http://www.itcast.cn' + node_.xpath('./div[1]/img/@src')[0].extract() # http://www.itcast.cn/images/teacher/2020382416385000.jpg
item['name'] = node_.xpath('./div[2]/h2/text()').extract_first()
item['title'] = node_.xpath('./div[2]/h2/span/text()')[0].extract()
# temp['exp'] = node_.xpath('./div[2]/h3/span[2]/text()')[0].extract() # 部分老师没有该span
item['info'] = node_.xpath('./div[3]/p/text()').extract_first()
# 爬虫中通常使用yield进行返回,return 处理翻页等情况并不好
yield item
通过item保存的数据无法像dict进行json序列化,会出现以下错误
TypeError: Object of type 'MyspiderItem' is not JSON serializable
解决办法:在pipelines.py中将item对象转换为dict(scrapy中可以直接将item对象转换为dict)
# 在scrapy中将item对象转换为dict
item = dict(item)
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class MyspiderPipeline:
def __init__(self):
self.file = open('./itcast.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 默认使用完管道后,需要将数据返回给引擎
# print(item)
# 在scrapy中将item对象转换为dict
item = dict(item)
# 向文件中保存
# 1.将dict 序列化 , ensure_ascii=False和encoding = 'utf-8'保证中文数据保存
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
# 2.将数据写入文件
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
注意:
- from myspider.items import MyspiderItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误
- python中的导入路径要诀:从哪里开始运行,就从哪里开始导入
tips: 导入类时

from Myspider.items import MyspiderItem
1.4 开发流程总结
- 创建项目
scrapy startproject 项目名 - 明确目标
在items.py文件中进行建模 - 创建爬虫
3.1 创建爬虫
scrapy genspider 爬虫名 允许的域
3.2 完成爬虫
修改start_urls
检查修改allowed_domains
编写解析方法 - 保存数据
在pipelines.py文件中定义对数据处理的管道
在settings.py文件中注册启用管道
2. 翻页请求的思路
对于要提取如下图中所有页面上的数据该怎么办?
![]()
requests模块是实现翻页请求:
- 找到
下一页的URL地址 - 调用requests.get(url)
scrapy实现翻页的思路:
- 找到下一页的url地址
- 构造url地址的请求对象,传递给引擎
3. 构造Request对象,并发送请求
3.1 实现方法
- 确定url地址
- 构造请求,scrapy.Request(url,callback)
- callback:指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
- 把请求交给引擎:yield scrapy.Request(url,callback)
3.2 网易招聘爬虫
实现网易招聘的页面翻页请求的招聘信息爬取
地址:https://hr.163.com/position/list.do
思路分析:
- 获取首页的数据
- 寻找下一页的地址,进行翻页,获取数据
实现流程
-
创建项目
scrapy startproject 项目名scrapy startproject wangyi -
明确目标
在items.py文件中进行建模# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class WangyiItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() # 职位名称 link = scrapy.Field() # 职位链接 department = scrapy.Field() # 职位部门 requirment = scrapy.Field() # 职位要求 category = scrapy.Field() # 职位类别 type = scrapy.Field() # 职位类型 num = scrapy.Field() # 职位人数 address = scrapy.Field() # 工作地点 date = scrapy.Field() # 发布时间 -
创建爬虫
3.1 创建爬虫
scrapy genspider 爬虫名 允许的域cd wangyi scrapy genspider example example.com3.2 完成爬虫
修改start_urls
检查修改allowed_domains
编写解析方法import scrapy from wangyi.items import WangyiItem class ExampleSpider(scrapy.Spider): name = 'example' # 2.检查域名 allowed_domains = ['163.com'] # 1.修改url start_urls = ['https://hr.163.com/position/list.do'] def parse(self, response): # 1.提取数据 # 获取所有职位节点列表 node_list = response.xpath('//*[@class="position-tb"]/tbody/tr') # print(len(node_list)) # 节点列表中每个职位tr后存在一个空tr,在遍历的时候考虑过滤 """ 01 for num, node_ in enumerate(node_list): # 过滤目标节点数据 if num%2 == 0: item = WangyiItem() item['name'] = node_.xpath('./td[1]/a/text()').extract_first() # item['link'] = 'https://hr.163.com/' + node_.xpath('./td[1]/a/@href').extract_first() # response.urljoin() 等同于上面代码,用于拼接相对url item['link'] = response.urljoin(node_.xpath('./td[1]/a/@href').extract_first()) item['department'] = node_.xpath('./td[2]/text()').extract_first() item['category'] = node_.xpath('./td[3]/text()').extract_first() item['type'] = node_.xpath('./td[4]/text()').extract_first() item['address'] = node_.xpath('./td[5]/text()').extract_first() # strip() 目的是去除'\r\n','\t'等 item['num'] = node_.xpath('./td[6]/text()').extract_first().strip() item['date'] = node_.xpath('./td[7]/text()').extract_first() yield item # 2.模拟翻页 # 获取点击下一页'>'标签的url part_url = response.xpath('//a[contains(text(), ">")]/@href').extract_first() # 判断停止条件 # 最后一页中 > 根据href判断 if part_url != 'javascript:void(0)': # 构建下一页url next_url = response.urljoin(part_url) # 构建请求对象并返回给引擎 yield scrapy.Request( # 参数1:下一页url url = next_url, # 参数2:解析方法 # callback不指定,默认是self.parse方法 callback = self.parse )""" -
保存数据
在pipelines.py文件中定义对数据处理的管道# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter import json class WangyiPipeline: def __init__(self): self.file = open('wangyi.json', 'w', encoding='utf-8') def process_item(self, item, spider): item = dict(item) json_data = json.dumps(item, ensure_ascii=False) + ',\n' self.file.write(json_data) return item def __del__(self): self.file.close()在settings.py文件中注册启用管道
ITEM_PIPELINES = { 'wangyi.pipelines.WangyiPipeline': 300, } -
运行结果
{"name": "云商-资深直客销售(东区)-智慧企业事业部002", "link": "https://hr.163.com/position/detail.do?id=13953", "department": null, "category": "销售>销售", "type": "全职", "address": "杭州市", "num": "3人", "date": "2021-06-02"}, {"name": "云商-资深直客销售(北区)- 智慧企业事业部002", "link": "https://hr.163.com/position/detail.do?id=13954", "department": null, "category": "销售>销售", "type": "全职", "address": "北京市", "num": "3人", "date": "2021-06-02"}, {"name": "小说广告投放专员 - 元气事业部005", "link": "https://hr.163.com/position/detail.do?id=31332", "department": "元气事业部", "category": "市场>市场综合", "type": "全职", "address": "杭州市", "num": "1人", "date": "2021-06-20"}, ....
注意:
- 可以在settings中设置ROBOTS协议
# False表示忽略网站的robots.txt协议,默认为True
ROBOTSTXT_OBEY = False
- 可以在settings中设置User-Agent:
# scrapy发送的每一个请求的默认UA都是设置的这个User-Agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
3.3 代码实现
翻页实现–在爬虫文件的parse方法中:
......
# 提取下一页的href
next_url = response.xpath('//a[contains(text(),">")]/@href').extract_first()
# 判断是否是最后一页
if next_url != 'javascript:void(0)':
# 构造完整url
url = 'https://hr.163.com/position/list.do' + next_url
# 构造scrapy.Request对象,并yield给引擎
# 利用callback参数指定该Request对象之后获取的响应用哪个函数进行解析
yield scrapy.Request(url, callback=self.parse)
......
3.4 scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
参数解释
- 中括号[]里的参数为可选参数
- callback:表示当前的url的响应交给哪个函数去处理,若不设置,默认使用parse()解析
- meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等,常用于解析分散在不同页面中的数据
- dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
- method:指定POST或GET请求
- headers:接收一个字典,其中不包括cookies
- cookies:接收一个字典,专门放置cookies
- body:接收json字符串,为POST的数据,发送payload_post请求时使用(在下一章节中会介绍post请求)
4. meta参数的使用
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):
...
yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item})
...
def parse_detail(self,response):
#获取之前传入的item
item = resposne.meta["item"]
对网易招聘的spider中的parse方法进行修改
import scrapy
from wangyi.items import WangyiItem
import re
class ExampleSpider(scrapy.Spider):
name = 'example'
# 2.检查域名
allowed_domains = ['163.com']
# 1.修改url
start_urls = ['https://hr.163.com/position/list.do']
def parse(self, response):
# 1.提取数据
# 获取所有职位节点列表
node_list = response.xpath('//*[@class="position-tb"]/tbody/tr')
# print(len(node_list))
# 节点列表中每个职位tr后存在一个空tr,在遍历的时候考虑过滤
"""
0
1
"""
for num, node_ in enumerate(node_list):
# 过滤目标节点数据
if num%2 == 0:
item = WangyiItem()
item['name'] = node_.xpath('./td[1]/a/text()').extract_first()
# item['link'] = 'https://hr.163.com/' + node_.xpath('./td[1]/a/@href').extract_first()
# response.urljoin() 等同于上面代码,用于拼接相对url
item['link'] = response.urljoin(node_.xpath('./td[1]/a/@href').extract_first())
item['department'] = node_.xpath('./td[2]/text()').extract_first()
item['category'] = node_.xpath('./td[3]/text()').extract_first()
item['type'] = node_.xpath('./td[4]/text()').extract_first()
item['address'] = node_.xpath('./td[5]/text()').extract_first()
# strip() 目的是去除'\r\n','\t'等
item['num'] = node_.xpath('./td[6]/text()').extract_first().strip()
item['date'] = node_.xpath('./td[7]/text()').extract_first()
# yield item
# 构建详情页面请求
yield scrapy.Request(
# 发送详情页面url
url = item['link'],
# 详情页面解析方法
callback = self.parse_detail,
# 通过meta传递数据
meta = {'item' : item}
)
# 2.模拟翻页
# 获取点击下一页'>'标签的url
part_url = response.xpath('//a[contains(text(), ">")]/@href').extract_first()
# 判断停止条件
# 最后一页中 > 根据href判断
if part_url != 'javascript:void(0)':
# 构建下一页url
next_url = response.urljoin(part_url)
# 构建请求对象并返回给引擎
yield scrapy.Request(
# 参数1:下一页url
url = next_url,
# 参数2:解析方法
# callback不指定,默认是self.parse方法
callback = self.parse
)
# 定义详情页面的解析方法
def parse_detail(self, response):
# print(response.meta['item']) # 传递了parse()中的item
item = response.meta['item']
# 由于列表中多个数据,使用extract()
# 使用.join()将列表拼接为str
item['duty'] = '\n'.join([re.sub(' ', '',i) for i in response.xpath('/html/body/div[2]/div[2]/div[1]/div/div/div[2]/div[1]/div/text()').extract()])
item['requirement'] = '\n'.join([re.sub(' ', '',i) for i in response.xpath('//html/body/div[2]/div[2]/div[1]/div/div/div[2]/div[2]/div/text()').extract()])
yield item
对items.py进行修改
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WangyiItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 职位名称
link = scrapy.Field() # 职位链接
department = scrapy.Field() # 职位部门
requirment = scrapy.Field() # 职位要求
category = scrapy.Field() # 职位类别
type = scrapy.Field() # 职位类型
num = scrapy.Field() # 职位人数
address = scrapy.Field() # 工作地点
date = scrapy.Field() # 发布时间
# 详情页面
duty = scrapy.Field() # 岗位描述
# 岗位要求
requirement = scrapy.Field() # 岗位要求
run
{"name": "数据湖研发工程师 - 杭州研究院048", "link": "https://hr.163.com/position/detail.do?id=32748", "department": null, "category": "技术>服务端开发", "type": "全职", "address": "杭州市", "num": "1人", "date": "2021-06-18", "duty": "1.参与网易实时数据湖内核以及平台研发\n2.参与平台的推广与落地", "requirement": "1.本科或以上学历,计算机软件或者相关专业,3年以上Java研发经验;\n2.拥有扎实的计算机和Java语言基础,熟悉大数据生态,熟悉hive,spark,flink,presto,impala等大数据基础组件,精通其中两种或两种以上为宜\n3.有良好的模块设计和架构设计能力,有构建分布式系统的项目经验;\n4.有实时计算内核开发(flink,sparkstreaming)经验,或者对hudi,iceberg有深入了解的同学重点考虑"},
{"name": "云商-资深直客销售(东区)-智慧企业事业部002", "link": "https://hr.163.com/position/detail.do?id=13953", "department": null, "category": "销售>销售", "type": "全职", "address": "杭州市", "num": "3人", "date": "2021-06-02", "duty": "(本岗位杭州、上海、北京、广州、深圳均招人)\n1.负责产品目标行业大客户的销售工作,并达成销售目标;\n2.负责产品目标行业重点客户的客户开发、销售跟进、签单并回款等工作;\n3.负责行业标杆的树立,协助市场运营部门进行标杆客户案例的包装;\n4.负责行业的客户开发、行业需求的挖掘整理,行业竞品的信息收集,并向产品、运营等相关部门输出;\n5.整合公司内部外部资源,为内外部销售渠道提供大客户辅助销售支持;\n6.整理行业销售经验,向电销、区域销售、合作伙伴进行行业销售经验输出。", "requirement": "1.本科以上学历,具有2年以上云计算产品软件产品或项目销售经验;\n2.有政府、汽车、电商、教育等行业客户资源及销售经验,及集成商、渠道资源;\n3.具备超强的需求挖掘和产品引导能力、方案及输出能力,良好的团队协作精神;\n4.非常强的大客户销售开发能力和顾问式销售能力,有优秀的的销售业绩;\n5.认同网易发展未来,热爱并充满信心;\n6.市场意识敏锐,学习能力强,资源整合协调能力,逻辑清晰,抗压并充满激情。"},
{"name": "二次元角色原画设计师-天下事业部", "link": "https://hr.163.com/position/detail.do?id=32051", "department": null, "category": "美术>游戏美术类", "type": "全职", "address": "上海市", "num": "2人", "date": "2021-06-18", "duty": "1.配合主美制定游戏角色风格,输出角色原画设计模版和规范;\n2.组织角色原画和角色制作人员开展工作;\n3.参与具体角色设计任务,审核外包提交的角色设计稿,指导外包制作;\n4.依据角色原画设计流程,参与审核;\n5.积累总结角色设计经验,编写课件并培养新人,分享设计经验。", "requirement": "1.热爱游戏,关注游戏体验,结合本岗位工作配合产品改进游戏体验;\n2.美术相关类专业毕业,深厚的美术功底;\n3.有主导团队开展设计工作经验者尤佳;\n4.有较强的沟通和分析能力,创新能力,准确理解工作需求并高效完成;\n5.有较强的责任心,工作投入度高,配合团队完成目标;\n6.熟练掌握该岗位所需软件,有较强的学习能力,主动研究或学习新的技术运用到工作中。"},
...
特别注意
- meta参数是一个字典
- meta字典中有一个固定的键
proxy,表示代理ip,关于代理ip的使用将在scrapy的下载中间件的中进行介绍
小结
- 完善并使用Item数据类:
- 在items.py中完善要爬取的字段
- 在爬虫文件中先导入Item
- 实力化Item对象后,像字典一样直接使用
- 构造Request对象,并发送请求:
- 导入scrapy.Request类
- 在解析函数中提取url
- yield scrapy.Request(url, callback=self.parse_detail, meta={})
- 利用meta参数在不同的解析函数中传递数据:
- 通过前一个解析函数 yield scrapy.Request(url, callback=self.xxx, meta={}) 来传递meta
- 在self.xxx函数中 response.meta.get(‘key’, ‘’) 或 response.meta[‘key’] 的方式取出传递的数据
scrapy模拟登陆
1. 模拟登陆的方法
1.1 requests模块实现模拟登陆
- 直接携带cookies请求页面
- 找url地址,发送post请求存储cookie
1.2 selenium模拟登陆
- 找到对应的input标签,输入文本点击登陆
1.3 scrapy的模拟登陆
- 直接携带cookies
- 找url地址,发送post请求存储cookie
2. scrapy携带cookies直接获取需要登陆后的页面
应用场景
- cookie过期时间很长,常见于一些不规范的网站
- 能在cookie过期之前把所有的数据拿到
- 配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
2.1 实现:重构scrapy的starte_rquests方法
scrapy中start_url是通过start_requests来进行处理的,其实现代码如下
# 这是源代码
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
所以对应的,如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
2.2 携带cookies登陆github
测试账号 noobpythoner zhoudawei123
import scrapy
import re
class Login1Spider(scrapy.Spider):
name = 'login1'
allowed_domains = ['github.com']
start_urls = ['https://github.com/NoobPythoner'] # 这是一个需要登陆以后才能访问的页面
def start_requests(self): # 重构start_requests方法
# 这个cookies_str是抓包获取的
cookies_str = '...' # 抓包获取
# 将cookies_str转换为cookies_dict
cookies_dict = {i.split('=')[0]:i.split('=')[-1] for i in cookies_str.split(';')}
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies=cookies_dict
)
def parse(self, response): # 通过正则表达式匹配用户名来验证是否登陆成功
# 正则匹配的是github的用户名
result_list = re.findall(r'noobpythoner|NoobPythoner', response.body.decode())
print(result_list)
print(response.xpath('/html/head/title/text()').extract_first())
注意:
- scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
- 若


在settings.py中设置ROBOTS协议、USER_AGENT
USER_AGENT:
修改如下:
ROBOTS协议:

修改如下:

3. scrapy.Request发送post请求
我们知道可以通过scrapy.Request()指定method、body参数来发送post请求;但是通常使用scrapy.FormRequest()来发送post请求
3.1 发送post请求
注意:scrapy.FormRequest()能够发送表单和ajax请求, 参考阅读
3.1.1 思路分析
-
找到post的url地址:点击登录按钮进行抓包,然后定位url地址为https://github.com/session

点击sign in,勾选preserve log,找到session

-
找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
post_data = { "commit": "Sign in", "authenticity_token": token, "login": username, "password": password, "webauthn - support": "supported", "webauthn - iuvpaa - support": "unsupported", "timestamp": "1624282383262", "timestamp_secret": "b6d9215ace34528ca70ab3a3642772edec80ad6cacac7c5c6fe934d7dfba9fe5", }其中token,timestamp,timestamp_secret,是需要在前一次响应中获取的参数,返回login页面

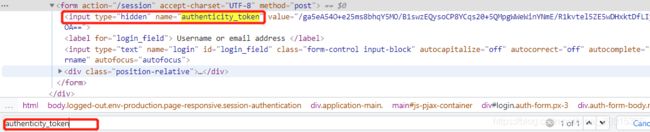

xpath提取value

- 否登录成功:通过请求个人主页,观察是否包含用户名
若出现如下报错,解决方法:import scrapy class GitLogin2Spider(scrapy.Spider): name = 'git_login2' allowed_domains = ['github.com'] start_urls = ['http://github.com/login'] def parse(self, response): # 1.从登陆页面响应中解析post数据 # 这里的response 是 'https://github.com/login' token = response.xpath("//input[contains(@name,'authenticity_token')]/@value").extract_first() # 使用contains会提取出timestamp_secret ,使用[0].extract(),或者重写xpath timestamp = response.xpath("//*[@id='login']/div[4]/form/div/input[10]/@value").extract_first() timestamp_secret = response.xpath("//input[contains(@name, 'timestamp_secret')]/@value").extract_first() post_data = { "commit": "Sign in", "authenticity_token": token, "login": username, "password": password, "webauthn - support": "supported", "webauthn - iuvpaa - support": "unsupported", "timestamp": timestamp, "timestamp_secret": timestamp_secret, } print(post_data) # 2.针对登陆url发送post请求 yield scrapy.FormRequest( # post 响应url是'http://github.com/session' url = 'http://github.com/session', formdata = post_data, callback = self.after_login_parse ) # 登录成功后,向个人页面发起请求 def after_login_parse(self, response): # 再对个人管理窗口发送请求 yield scrapy.Request( url = 'http://github.com/username', callback = self.check_login ) # 打印title,验证登录 def check_login(self, reponse): print(reponse.xpath('/html/head/title').extract_first())<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection t o the other side was lost in a non-clean fashion: Connection lost.>
3.1.2 代码实现如下:
import scrapy
import re
class Login2Spider(scrapy.Spider):
name = 'login2'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
utf8 = response.xpath("//input[@name='utf8']/@value").extract_first()
commit = response.xpath("//input[@name='commit']/@value").extract_first()
#构造POST请求,传递给引擎
yield scrapy.FormRequest(
"https://github.com/session",
formdata={
"authenticity_token":authenticity_token,
"utf8":utf8,
"commit":commit,
"login":"noobpythoner",
"password":"***"
},
callback=self.parse_login
)
def parse_login(self,response):
ret = re.findall(r"noobpythoner|NoobPythoner",response.text)
print(ret)
小技巧
在settings.py中通过设置COOKIES_DEBUG=True 能够在终端看到cookie的传递传递过程
scrapy list 终端中查看当前项目中爬虫
>scrapy list
github_login
github_login2
小结
- start_urls中的url地址是交给start_request处理的,如有必要,可以重写start_request函数
- 直接携带cookie登陆:cookie只能传递给cookies参数接收
- scrapy.Request()发送post请求
scrapy管道的使用
1. pipeline中常用的方法:
- process_item(self,item,spider):
- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
- open_spider(self, spider): 在爬虫开启的时候仅执行一次
- close_spider(self, spider): 在爬虫关闭的时候仅执行一次
2. 管道文件的修改
在wangyi项目中,新建job2爬虫
scrapy genspider job2 163.com
查看当前爬虫
>scrapy list
job
job2
修改items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WangyiItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 职位名称
link = scrapy.Field() # 职位链接
department = scrapy.Field() # 职位部门
requirment = scrapy.Field() # 职位要求
category = scrapy.Field() # 职位类别
type = scrapy.Field() # 职位类型
num = scrapy.Field() # 职位人数
address = scrapy.Field() # 工作地点
date = scrapy.Field() # 发布时间
# 详情页面
duty = scrapy.Field() # 岗位描述
# 岗位要求
requirement = scrapy.Field() # 岗位要求
class WangyiJobItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 职位名称
link = scrapy.Field() # 职位链接
department = scrapy.Field() # 职位部门
requirment = scrapy.Field() # 职位要求
category = scrapy.Field() # 职位类别
type = scrapy.Field() # 职位类型
num = scrapy.Field() # 职位人数
address = scrapy.Field() # 工作地点
date = scrapy.Field() # 发布时间
job.py
import scrapy
from wangyi.items import WangyiItem
import re
class JobSpider(scrapy.Spider):
name = 'job'
# 2.检查域名
allowed_domains = ['163.com']
# 1.修改url
start_urls = ['https://hr.163.com/position/list.do']
def parse(self, response):
# 1.提取数据
# 获取所有职位节点列表
node_list = response.xpath('//*[@class="position-tb"]/tbody/tr')
# print(len(node_list))
# 节点列表中每个职位tr后存在一个空tr,在遍历的时候考虑过滤
"""
0
1
"""
for num, node_ in enumerate(node_list):
# 过滤目标节点数据
if num%2 == 0:
item = WangyiItem()
item['name'] = node_.xpath('./td[1]/a/text()').extract_first()
# item['link'] = 'https://hr.163.com/' + node_.xpath('./td[1]/a/@href').extract_first()
# response.urljoin() 等同于上面代码,用于拼接相对url
item['link'] = response.urljoin(node_.xpath('./td[1]/a/@href').extract_first())
item['department'] = node_.xpath('./td[2]/text()').extract_first()
item['category'] = node_.xpath('./td[3]/text()').extract_first()
item['type'] = node_.xpath('./td[4]/text()').extract_first()
item['address'] = node_.xpath('./td[5]/text()').extract_first()
# strip() 目的是去除'\r\n','\t'等
item['num'] = node_.xpath('./td[6]/text()').extract_first().strip()
item['date'] = node_.xpath('./td[7]/text()').extract_first()
# yield item
# 构建详情页面请求
yield scrapy.Request(
# 发送详情页面url
url = item['link'],
# 详情页面解析方法
callback = self.parse_detail,
# 通过meta传递数据
meta = {'item' : item}
)
# 2.模拟翻页
# 获取点击下一页'>'标签的url
part_url = response.xpath('//a[contains(text(), ">")]/@href').extract_first()
# 判断停止条件
# 最后一页中 > 根据href判断
if part_url != 'javascript:void(0)':
# 构建下一页url
next_url = response.urljoin(part_url)
# 构建请求对象并返回给引擎
yield scrapy.Request(
# 参数1:下一页url
url = next_url,
# 参数2:解析方法
# callback不指定,默认是self.parse方法
callback = self.parse
)
# 定义详情页面的解析方法
def parse_detail(self, response):
# print(response.meta['item']) # 传递了parse()中的item
item = response.meta['item']
# 由于列表中多个数据,使用extract()
# 使用.join()将列表拼接为str
item['duty'] = '\n'.join([re.sub(' ', '',i) for i in response.xpath('/html/body/div[2]/div[2]/div[1]/div/div/div[2]/div[1]/div/text()').extract()])
item['requirement'] = '\n'.join([re.sub(' ', '',i) for i in response.xpath('//html/body/div[2]/div[2]/div[1]/div/div/div[2]/div[2]/div/text()').extract()])
yield item
job2.py
import scrapy
from wangyi.items import WangyiJobItem
import re
class JobSpider(scrapy.Spider):
name = 'job2'
# 2.检查域名
allowed_domains = ['163.com']
# 1.修改url
start_urls = ['https://hr.163.com/position/list.do']
def parse(self, response):
# 1.提取数据
# 获取所有职位节点列表
node_list = response.xpath('//*[@class="position-tb"]/tbody/tr')
# print(len(node_list))
# 节点列表中每个职位tr后存在一个空tr,在遍历的时候考虑过滤
"""
0
1
"""
for num, node_ in enumerate(node_list):
# 过滤目标节点数据
if num%2 == 0:
item = WangyiJobItem()
item['name'] = node_.xpath('./td[1]/a/text()').extract_first()
# item['link'] = 'https://hr.163.com/' + node_.xpath('./td[1]/a/@href').extract_first()
# response.urljoin() 等同于上面代码,用于拼接相对url
item['link'] = response.urljoin(node_.xpath('./td[1]/a/@href').extract_first())
item['department'] = node_.xpath('./td[2]/text()').extract_first()
item['category'] = node_.xpath('./td[3]/text()').extract_first()
item['type'] = node_.xpath('./td[4]/text()').extract_first()
item['address'] = node_.xpath('./td[5]/text()').extract_first()
# strip() 目的是去除'\r\n','\t'等
item['num'] = node_.xpath('./td[6]/text()').extract_first().strip()
item['date'] = node_.xpath('./td[7]/text()').extract_first()
yield item
# 2.模拟翻页
# 获取点击下一页'>'标签的url
part_url = response.xpath('//a[contains(text(), ">")]/@href').extract_first()
# 判断停止条件
# 最后一页中 > 根据href判断
if part_url != 'javascript:void(0)':
# 构建下一页url
next_url = response.urljoin(part_url)
# 构建请求对象并返回给引擎
yield scrapy.Request(
# 参数1:下一页url
url = next_url,
# 参数2:解析方法
# callback不指定,默认是self.parse方法
callback = self.parse
)
多个爬虫存在同一个项目中,会使用同一个管道进行保存,发生文件覆盖
原来 pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class WangyiPipeline:
def __init__(self):
self.file = open('wangyi.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
item = dict(item)
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
修改pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class WangyiPipeline:
def open_spider(self, spider):
self.file = open('wangyi.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
item = dict(item)
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
self.file.write(json_data)
return item
def close_spider(self, spider):
self.file.close()
class WangyiJobPipeline(object):
def open_spider(self, spider):
self.file = open('wangyi_job.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
item = dict(item)
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
self.file.write(json_data)
return item
def close_spider(self, spider):
self.file.close()
修改settings.py
ITEM_PIPELINES = {
'wangyi.pipelines.WangyiPipeline': 300,
'wangyi.pipelines.WangyiJobPipeline' : 301
}
此时运行任何一个爬虫,两个管道均会写入内容,若要不同爬虫运行时,分别输入不同管道中,spider参数就可以派上用场了
修改 pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class WangyiPipeline:
def open_spider(self, spider):
# spider 对象就是spiders目录下的爬虫
# spider.name也就是
"""
class JobSpider(scrapy.Spider):
name = 'job2'
"""
if spider.name == 'job':
self.file = open('wangyi.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
if spider.name == 'job':
item = dict(item)
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
self.file.write(json_data)
# 必须:不return的情况下,另一个权重较低的pipeline将不会获得item
return item
def close_spider(self, spider):
if spider.name == 'job':
self.file.close()
class WangyiJobPipeline(object):
def open_spider(self, spider):
if spider.name == 'job2':
self.file = open('wangyi_job.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
if spider.name == 'job2':
item = dict(item)
json_data = json.dumps(item, ensure_ascii=False) + ',\n'
self.file.write(json_data)
return item
def close_spider(self, spider):
if spider.name == 'job2':
self.file.close()
此时,运行不同爬虫时候,会存入预定义好的对应的管道中
wangyi.json
{"name": "圈子内容运营负责人", "link": "https://hr.163.com/position/detail.do?id=32795", "department": "互动娱乐事业群", "category": "运营>运营类", "type": "全职", "address": "广州市", "num": "1人", "date": "2021-06-21", "duty": "1.全面负责网易游戏内容社区型产品具体游戏圈子业务,基于游戏用户行为数据制定业务方针,对该游戏内容生态目标负责;\n2.整合各部门资源,推动跨部门协作,制定方案实施策略,统筹业务,完成结果增长和业务推进迭代;\n3.围绕业务持续业务创新,迭代运营经验和沉淀业务标准;\n4.持续培养团队人才,提升团队的整体业务能力,围绕业务持续招募优秀人才,完成团队日常管理工作。", "requirement": "1.对游戏及社区运营有自己独到的见解,对内容社区的活动运营、用户运营、工具/功能等全套流程均有涉猎,社区型产品工作经验者优先;\n2.有项目管理经验,善于从执行细节中发现问题并落实改进细则,并能对过往业务进行复盘总结方法论;\n3.有团队管理经验,具备优秀的团队协作能力与跨部门沟通能力;\n4.缜密的思维逻辑,良好的用户需求分析、挖掘能力,有较强的竞品分析和数据分析能力。"},
...
wangyi_job.json
{"name": "云商-资深直客销售(东区)-智慧企业事业部002", "link": "https://hr.163.com/position/detail.do?id=13953", "department": null, "category": "销售>销售", "type": "全职", "address": "杭州市", "num": "3人", "date": "2021-06-02"},
...
写入mongoDB数据库方式,修改pipelines.py代码
import json
from pymongo import MongoClient
class WangyiFilePipeline(object):
def open_spider(self, spider): # 在爬虫开启的时候仅执行一次
if spider.name == 'itcast':
self.f = open('json.txt', 'a', encoding='utf-8')
def close_spider(self, spider): # 在爬虫关闭的时候仅执行一次
if spider.name == 'itcast':
self.f.close()
def process_item(self, item, spider):
if spider.name == 'itcast':
self.f.write(json.dumps(dict(item), ensure_ascii=False, indent=2) + ',\n')
# 不return的情况下,另一个权重较低的pipeline将不会获得item
return item
class WangyiMongoPipeline(object):
def open_spider(self, spider): # 在爬虫开启的时候仅执行一次
if spider.name == 'itcast':
# 也可以使用isinstanc函数来区分爬虫类:
con = MongoClient(host='127.0.0.1', port=27017) # 实例化mongoclient
self.collection = con.itcast.teachers # 创建数据库名为itcast,集合名为teachers的集合操作对象
def process_item(self, item, spider):
if spider.name == 'itcast':
self.collection.insert(item)
# 此时item对象必须是一个字典,再插入
# 如果此时item是BaseItem则需要先转换为字典:dict(BaseItem)
# 不return的情况下,另一个权重较低的pipeline将不会获得item
return item
需要先开启mongodb数据库 sudo service mongodb start
并在mongodb数据库中查看 mongo
pipelines.py
from pymongo import MongoClient
class MongoPipeline(object):
def open_spider(self, spider):
self.client = MongoClient('127.0.0.1', 27017)
# 选择数据库
self.db = self.client['itcast']
# 选择集合
self.col = self.db['wangyi']
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
data = dict(item)
self.col.insert(data)
return item
settings.py
ITEM_PIPELINES = {
'wangyi.pipelines.WangyiPipeline': 300,
'wangyi.pipelines.WangyiJobPipeline' : 301,
'wangyi.pipelines.MongoPipeline' : 302,
}
由于未通过spiders对象进行筛选,因此运行任何一个爬虫都会将数据写入该数据库中

思考:在settings中能够开启多个管道,为什么需要开启多个?
- 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
- 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
- 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
4. pipeline使用注意点
- 使用之前需要在settings中开启
- pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行,该值一般设置为1000以内。
- 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
- pipeline中process_item的方法必须有,否则item没有办法接受和处理
- process_item方法接受item和spider,其中spider表示当前传递item过来的spider
- open_spider(spider) :能够在爬虫开启的时候执行一次
- close_spider(spider) :能够在爬虫关闭的时候执行一次
- 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
小结
- 管道能够实现数据的清洗和保存,能够定义多个管道实现不同的功能,其中有个三个方法
- process_item(self,item,spider):实现对item数据的处理
- open_spider(self, spider): 在爬虫开启的时候仅执行一次
- close_spider(self, spider): 在爬虫关闭的时候仅执行一次
scrapy 爬取腾讯招聘信息
scrapy的crawlspider爬虫
crawlspider类
CrawlSpider规则提取
1 crawlspider是什么
回顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址上面,这个过程能更简单一些么?
scrawlspider经常用于数据在一个页面上进行采集的情况,若数据在多个页面上采集时,通常使用spider类
思路:
- 从response中提取所有的满足规则的url地址
- 自动的构造自己requests请求,发送给引擎
对应的crawlspider就可以实现上述需求,能够匹配满足条件的url地址,组装成Reuqest对象后自动发送给引擎,同时能够指定callback函数
即:crawlspider爬虫可以按照规则自动获取连接
2 创建crawlspider爬虫并观察爬虫内的默认内容
2.1 创建crawlspider爬虫:
scrapy genspider -t crawl job 163.com
2.2 spider中默认生成的内容如下:
class JobSpider(CrawlSpider):
name = 'job'
allowed_domains = ['163.com']
start_urls = ['https://hr.163.com/position/list.do']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
2.3 观察跟普通的scrapy.spider的区别
在crawlspider爬虫中,没有parse函数
重点在rules中:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
3. crawlspider网易招聘爬虫
通过crawlspider爬取网易招聘的详情页的招聘信息
url:https://hr.163.com/position/list.do
思路分析:
- 定义一个规则,来进行列表页翻页,follow需要设置为True
- 定义一个规则,实现从列表页进入详情页,并且指定回调函数
- 在详情页提取数据
注意:连接提取器LinkExtractor中的allow对应的正则表达式匹配的是href属性的值
4 crawlspider使用的注意点:
- 除了用命令
scrapy genspider -t crawl <爬虫名>创建一个crawlspider的模板,页可以手动创建 - crawlspider中不能再有以parse为名的数据提取方法,该方法被crawlspider用来实现基础url提取等功能
- Rule对象中LinkExtractor为固定参数,其他callback、follow为可选参数
- 不指定callback且follow为True的情况下,满足rules中规则的url还会被继续提取和请求
- 如果一个被提取的url满足多个Rule,那么会从rules中选择一个满足匹配条件的Rule执行
5 了解crawlspider其他知识点
-
链接提取器LinkExtractor的更多常见参数
- allow: 满足括号中的’re’表达式的url会被提取,如果为空,则全部匹配
- deny: 满足括号中的’re’表达式的url不会被提取,优先级高于allow
- allow_domains: 会被提取的链接的domains(url范围),如:
['hr.tencent.com', 'baidu.com'] - deny_domains: 不会被提取的链接的domains(url范围)
- restrict_xpaths: 使用xpath规则进行匹配,和allow共同过滤url,即xpath满足的范围内的url地址会被提取,如:
restrict_xpaths='//div[@class="pagenav"]'
-
Rule常见参数
- LinkExtractor: 链接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback: 表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow: 连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,默认True表示会,Flase表示不会
- process_links: 当链接提取器LinkExtractor获取到链接列表的时候调用该参数指定的方法,这个自定义方法可以用来过滤url,且这个方法执行后才会执行callback指定的方法
总结
- crawlspider的作用:crawlspider可以按照规则自动获取连接
- crawlspider爬虫的创建:scrapy genspider -t crawl tencent hr.tencent.com
- crawlspider中rules的使用:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
- 完成网易招聘爬虫crawlspider版本
scrapy中间件的使用
1. scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间的作用:预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用代理ip等
- 对请求进行定制化操作,
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2. 下载中间件的使用方法:
Downloader Middlewares默认的方法:
- 在middleware.py中定义中间件类
- 在中间件类中重写请求或者响应方法
-
process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法。(如果所有下载器中间件都返回为None,则请求最终被交给下载器处理)
- 返回Response对象:不再请求,把response返回给引擎(将响应交给spider进行解析)
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法(如果返回为请求,则将请求交给调度器)
-
process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法(将响应交给spider进行解析)
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法(如果返回为请求,则将请求交给调度器)
- 在settings.py中配置开启中间件,权重值越小越优先执行
爬取豆瓣电影top250信息
https://movie.douban.com/top250
- 创建项目
scrapy startproject douban
- 编写item.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 电影名
info = scrapy.Field() # 导演信息
score = scrapy.Field() # 评分
desc = scrapy.Field() # 描述
- 创建爬虫
cd doubam
scrapy gensipder movie douban.com
定位xpath


编写spiders/movie.py
import scrapy
class MovieSpider(scrapy.Spider):
name = 'movie'
# 检查域名
allowed_domains = ['douban.com']
# 检查start_url
# start_urls = ['http://douban.com/']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
tr_list = response.xpath("//ol[@class='grid_view']/li")
print(len(tr_list))
运行
scrapy crawl movie
![]()
修改settings.py

再次运行
![]()
获取下一页标签xpath

翻至最后一页检查终止条件

翻页并终止逻辑
# 下一页标签xpath
next_url = response.xpath("//span[@class='next']/a/@href").extract_first()
# 当处于最后一页时候,xpath 提取为None
if next_url != None:
url = response.joinurls(next_url)
yield scrapy.Request(
url = url,
callback = self.parse
)
完善数据提取部分
为了导入方便,先mark Sources root

手误点到excluded 解决办法
import scrapy
from douban.items import DoubanItem
class MovieSpider(scrapy.Spider):
name = 'movie'
# 检查域名
allowed_domains = ['douban.com']
# 检查start_url
# start_urls = ['http://douban.com/']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
tr_list = response.xpath("//ol[@class='grid_view']/li")
print(len(tr_list))
for tr in tr_list:
item = DoubanItem()
item['name'] = tr.xpath("./div/div[2]/div[1]/a/span[1]/text()").extract_first()
item['info'] = tr.xpath("./div/div[2]/div[2]/p/text()")[0].extract().split()
item['desc'] = tr.xpath("./div/div[2]/div[2]/p/text()")[1].extract().split()
item['score'] = tr.xpath('./div/div[2]/div[2]/div/span[2]/text()').extract_first()
yield item
# 下一页标签xpath
next_url = response.xpath("//span[@class='next']/a/@href").extract_first()
# 当处于最后一页时候,xpath 提取为None
if next_url != None:
url = response.joinurls(next_url)
yield scrapy.Request(
url = url,
callback = self.parse
)
获取详情页面数据
import scrapy
from douban.items import DoubanItem
import re
class MovieSpider(scrapy.Spider):
name = 'movie'
# 检查域名
allowed_domains = ['douban.com']
# 检查start_url
# start_urls = ['http://douban.com/']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
tr_list = response.xpath("//ol[@class='grid_view']/li")
# print(len(tr_list))
for tr in tr_list:
item = DoubanItem()
item['name'] = tr.xpath("./div/div[2]/div[1]/a/span[1]/text()").extract_first()
item['info'] = ' '.join(tr.xpath("./div/div[2]/div[2]/p/text()")[0].extract().split())
item['desc'] = ' '.join(tr.xpath("./div/div[2]/div[2]/p/text()")[1].extract().split())
item['score'] = tr.xpath('./div/div[2]/div[2]/div/span[2]/text()').extract_first()
item['link'] = response.urljoin(tr.xpath("./div/div[2]/div[1]/a/@href").extract_first())
yield scrapy.Request(
url = item['link'],
callback = self.parse_detail,
meta = {'detail' : item}
)
# 下一页标签xpath
next_url = response.xpath("//span[@class='next']/a/@href").extract_first()
# 当处于最后一页时候,xpath 提取为None
if next_url != None:
url = response.urljoin(next_url)
yield scrapy.Request(
url = url,
callback = self.parse
)
def parse_detail(self, response):
item = response.meta['detail']
item['introduction'] = ''.join([re.sub(r'\n|\u3000| ', '', i).strip() for i in response.xpath('//*[@id="link-report"]/span[1]/text()').extract()])
print(item)
yield item
运行
{'desc': '2001 / 法国 德国 / 剧情 喜剧 爱情',
'info': '导演: 让-皮埃尔·热内 Jean-Pierre Jeunet 主演: 奥黛丽·塔图 Audrey Tau...',
'introduction': '艾米莉(奥黛丽·塔图AudreyTautou饰)有着别人看来不幸的童年——父亲给她做健康检查时,发现她心跳过快,便断定她患上心脏病,从此艾米莉与学校绝缘。随
后因为一桩意外,母亲在她眼前突然死去。这一切都毫不影响艾米莉对生活的豁达乐观。1997年,戴安娜王妃的去世让她倍感人生的孤独脆弱,艾米莉从此开始了一系列助人计划,包括
自闭忧郁的邻居老人,被老板刻薄的菜摊伙计、遗失了童年器物的旧房东、爱情失意的咖啡店同事。但她万万想不到,成人录象带商店店员尼诺(马修·卡索维MathieuKassovitz饰),
竟成为她的棘手对象,艾米莉开始了令人哭笑不得的另类计划……',
'link': 'https://movie.douban.com/subject/1292215/',
'name': '天使爱美丽',
'score': '8.7'}
编写管道piplines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class DoubanPipeline:
def open_spider(self, spider):
if spider.name == 'movie':
self.file = open(spider.name + '.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
if spider.name == 'movie':
self.file.write(json.dumps(dict(item), ensure_ascii=False)+ '\n')
return item
def close_spider(self, spider):
if spider.name == 'movie':
self.file.close()
settings.py开启管道
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
movi.json
{"name": "美丽人生", "info": "导演: 罗伯托·贝尼尼 Roberto Benigni 主演: 罗伯托·贝尼尼 Roberto Beni...", "desc": "1997 / 意大利 / 剧情 喜剧 爱情 战争", "score": "nan", "link": "https://movie.douban.com/subject/1292063/", "introduction": "犹太青年圭多(罗伯托·贝尼尼)邂逅美丽的女教师多拉(尼可莱塔·布拉斯基),他彬彬有礼的向多拉鞠躬:“早安!公主!”。历经诸多令人啼笑皆非的周折后,天遂人愿,两人幸福美满的生活在一起。然而好景不长,法西斯政权下,圭多和儿子被强行送往犹太人集中营。多拉虽没有犹太血统,毅然同行,与丈夫儿子分开关押在一个集中营里。聪明乐天的圭多哄骗儿子这只是一场游戏,奖品就是一辆大坦克,儿子快乐、天真的生活在纳粹的阴霾之中。尽管集中营的生活艰苦寂寞,圭多仍然带给他人很多快乐,他还趁机在纳粹的广播里问候妻子:“早安!公主!”法西斯政权即将倾覆,纳粹的集中营很快就要接受最后的清理,圭多编给儿子的游戏该怎么结束?他们一家能否平安的度过这黑暗的年代呢?"}
{"name": "这个杀手不太冷", "info": "导演: 吕克·贝松 Luc Besson 主演: 让·雷诺 Jean Reno / 娜塔莉·波特曼 ...", "desc": "1994 / 法国 美国 / 剧情 动作 犯罪", "score": "nan", "link": "https://movie.douban.com/subject/1295644/", "introduction": "里昂(让·雷诺饰)是名孤独的职业杀手,受人雇佣。一天,邻居家小姑娘马蒂尔达(纳塔丽·波特曼饰)敲开他的房门,要求在他那里暂避杀身之祸。原来邻居家的主人是警方缉毒组的眼线,只因贪污了一小包毒品而遭恶警(加里·奥德曼饰)杀害全家的惩罚。马蒂尔达得到里昂的留救,幸免于难,并留在里昂那里。里昂教小女孩使枪,她教里昂法文,两人关系日趋亲密,相处融洽。女孩想着去报仇,反倒被抓,里昂及时赶到,将女孩救回。混杂着哀怨情仇的正邪之战渐次升级,更大的冲突在所难免……"}
...
3. 定义实现随机User-Agent的下载中间件
3.1 在settings中添加UA的列表

USER_AGENTS_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
3.2 在middlewares.py中完善代码
import random
from Douban.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示
class UserAgentMiddleware(object):
def process_request(self, request, spider):
# print(request.headers)
""" {b'Accept': [b'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'], b'Accept-Language': [b'en'], b'User-Agent': [b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36']}"""
# print(request.headers['User-Agent'])
# [b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36']
# 获取一个随机UA
user_agent = random.choice(USER_AGENTS_LIST)
# 设置UA
request.headers['User-Agent'] = user_agent
# 不写return
class CheckUA:
def process_response(self,request,response,spider):
print(request.headers['User-Agent'])
return response # 不能少!
3.3 在settings中设置开启自定义的下载中间件,设置方法同管道
开启并修改中间件
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
# 根据中间件中的类名,更改名字并注册开启
'Douban.middlewares.UserAgentMiddleware': 543, # 543是权重值
'Douban.middlewares.CheckUA': 600, # 先执行543权重的中间件,再执行600的中间件
}
运行爬虫观察现象
4. 代理ip的使用
4.1 思路分析
- 代理添加的位置:request.meta中增加
proxy字段 - 获取一个代理ip,赋值给
request.meta['proxy']- 代理池中随机选择代理ip
- 代理ip的webapi发送请求获取一个代理ip
4.2 具体实现
settings.py中

免费代理ip:
class ProxyMiddleware(object):
def process_request(self,request,spider):
# proxies可以在settings.py中,也可以来源于代理ip的webapi
# proxy = random.choice(proxies)
# 免费的会失效,报 111 connection refused 信息!重找一个代理ip再试
proxy = 'https://1.71.188.37:3128'
request.meta['proxy'] = proxy
return None # 可以不写return
收费代理ip:
http基本认证1
http基本认证2

# 人民币玩家的代码(使用abuyun提供的代理ip)
import base64
# 代理隧道验证信息 这个是在那个网站上申请的
proxyServer = 'http://proxy.abuyun.com:9010' # 收费的代理ip服务器地址,这里是abuyun
proxyUser = 用户名
proxyPass = 密码
proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass)
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 设置代理
request.meta["proxy"] = proxyServer
# 设置认证
request.headers["Proxy-Authorization"] = proxyAuth
两种同时存在
from douban.settings import PROXY_LIST
import base64
# 定义一个代理类
class RandomProxy(object):
def process_request(self, spider, request):
proxy = random.choice(PROXY_LIST)
# 判断PROXY_LIST中是否存在账号密码来判断是否为收费代理
# {'ip_port':'123.207.53.84:16816', 'user_password':'morganna_mode_g:ggc22qxp'},
# 定义的PROXY_LIST中账号密码key 为user_password
if 'user_password' in proxy:
# 对账号密码进行编码base64
# base64是对bytes类型进行编码,因此proxy['user_password'].encode()
base64_up = base64.b64encode(proxy['user_password'].encode())
# 设置http basic认证 : http请求头中添加Authorization: Basic + base64加密字段
# base64_up为bytes,转化为str 因此base64_up.decode()
# 注意:Basic后面有个空格,认证时将以空格切分方式和账号密码
request.headers['Proxy-Authorization'] = 'Basic ' + base64_up.decode()
# 设置代理
request.meta['proxy'] = proxy['ip_port']
else:
# 免费代理无账号密码,直接设置
request.meta['proxy'] = proxy['ip_port']
settings.py中注册

4.3 检测代理ip是否可用
在使用了代理ip的情况下可以在下载中间件的process_response()方法中处理代理ip的使用情况,如果该代理ip不能使用可以替换其他代理ip
class ProxyMiddleware(object):
......
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True # 重新发送的请求对象能够再次进入队列
return requst
在settings.py中开启该中间件
5. 在中间件中使用selenium
以github登陆为例
5.1 完成爬虫代码
import scrapy
class Login4Spider(scrapy.Spider):
name = 'login4'
allowed_domains = ['github.com']
start_urls = ['https://github.com/1596930226'] # 直接对验证的url发送请求
def parse(self, response):
with open('check.html', 'w') as f:
f.write(response.body.decode())
5.2 在middlewares.py中使用selenium
import time
from selenium import webdriver
def getCookies():
# 使用selenium模拟登陆,获取并返回cookie
username = input('输入github账号:')
password = input('输入github密码:')
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver',
chrome_options=options)
driver.get('https://github.com/login')
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login_field"]').send_keys(username)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="password"]').send_keys(password)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login"]/form/div[3]/input[3]').click()
time.sleep(2)
cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}
driver.quit()
return cookies_dict
class LoginDownloaderMiddleware(object):
def process_request(self, request, spider):
cookies_dict = getCookies()
print(cookies_dict)
request.cookies = cookies_dict # 对请求对象的cookies属性进行替换
配置文件中设置开启该中间件后,运行爬虫可以在日志信息中看到selenium相关内容
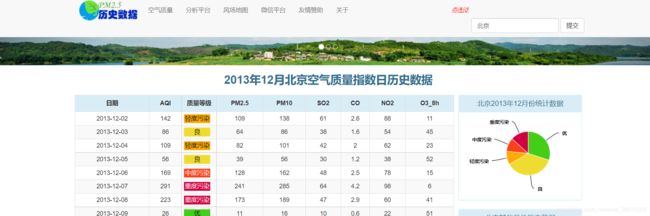
5.3 爬取AQI 天气信息历史数据
https://www.aqistudy.cn/historydata/

选择一个城市,观察会发现该页面数据为动态渲染,scrapy直接发送响应获取不到渲染后的数据,因此需要在中间件中使用selenium进行动态渲染后,获取网页源码作为新响应
https://www.aqistudy.cn/historydata/monthdata.php?city=%E5%8C%97%E4%BA%AC

选择某一个月
https://www.aqistudy.cn/historydata/daydata.php?city=%E5%8C%97%E4%BA%AC&month=2013-12
- 创建项目
scrapy startproject AQI
- items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class AqiItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题
url = scrapy.Field() # url
timestamp = scrapy.Field() # 采集时间
date = scrapy.Field() # 当天日期
AQI = scrapy.Field() # AQI
LEVEL = scrapy.Field() # 质量等级
PM25 = scrapy.Field() # pm2.5
PM10 = scrapy.Field() # pm10
SO2 = scrapy.Field() # so2
CO = scrapy.Field() # CO
NO2 = scrapy.Field() # NO2
O3 = scrapy.Field() # O3
- 创建爬虫
cd AQI
scrapy genspider aqi aiq.cn
获取所有城市url

在城市详情页面获取所有日期对应url

或者通过右侧提取

对所要提取的详情页面进行数据提取

- 解析数据
spiders/aqi.py
import scrapy
from AQI.items import AqiItem
import time
class AqiSpider(scrapy.Spider):
name = 'aqi'
# 检查domain
allowed_domains = ['aqistudy.cn']
# 检查start_urls
start_urls = ['https://www.aqistudy.cn/historydata/']
def parse(self, response):
# 由于要获取每个城市下面具体月份的每天天气信息
# 获取城市对应url相应
city_urls = response.xpath("//div[@class='bottom']/ul/div[2]/li/a/@href").extract()
# print(city_urls)
# 对每个城市详情页面发送请求
for city_url in city_urls[33:35]:
yield scrapy.Request(
url = response.urljoin(city_url),
callback = self.parse_month
)
def parse_month(self, response):
# 获取当前城市所有月对应url
month_urls = response.xpath("//ul[@class='unstyled1']/li/a/@href").extract()
# print(month_urls)
# month_urls = response.xpath("//tbody/tr/td[1]/a/@href").extract()
# 对每个月的详情页面发起相应
for month_url in month_urls[2:3]:
yield scrapy.Request(
url = response.urljoin(month_url),
callback = self.parse_day
)
def parse_day(self, response):
# 对该月的详情页面进行数据解析
node_list = response.xpath("//tbody/tr")
title = response.xpath("//*[@id='title']/text()").extract_first()
# print(len(node_list))
# 获取所有数据节点, 第一个tr为列名,不提取
for node_ in node_list[1:]:
# 实例化item
item = AqiItem()
item['title'] = title
item['url'] = response.url
item['timestamp'] = time.time()
item['date'] = node_.xpath('./td[1]/text()').extract_first()
item['AQI'] = node_.xpath('./td[2]/text()').extract_first()
item['LEVEL'] = node_.xpath('./td[3]/span/text()').extract_first()
item['PM25'] = node_.xpath('./td[4]/text()').extract_first()
item['PM10'] = node_.xpath('./td[5]/text()').extract_first()
item['SO2'] = node_.xpath('./td[6]/text()').extract_first()
item['CO'] = node_.xpath('./td[7]/text()').extract_first()
item['NO2'] = node_.xpath('./td[8]/text()').extract_first()
item['O3'] = node_.xpath('./td[9]/text()').extract_first()
yield item
- 管道 和 中间件
pipelines.py 和 middlewares.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class AqiPipeline:
def open_spider(self, spider):
if spider.name == 'aqi':
self.file = open(spider.name + '.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
if spider.name == 'aqi':
self.file.write(json.dumps(dict(item), ensure_ascii=False)+'\n')
return item
def close_spider(self, spider):
if spider.name == 'aqi':
self.file.close()
middleware.py
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from selenium import webdriver
from scrapy.http import HtmlResponse
import time
class SeleniumMiddlewares(object):
def process_request(self, request, spider):
# 获取url
url = request.url
# 判断是否来到每日详情页面
# https://www.aqistudy.cn/historydata/daydata.php?city=%E9%98%BF%E5%9D%9D%E5%B7%9E&month=2015-01
if 'daydata' in url:
# # 忽略无用日志
# options = webdriver.ChromeOptions()
# options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
# selenium 开启后无数据加载
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("--disable-blink-features=AutomationControlled")
# selenium加载渲染页面
driver = webdriver.Chrome(chrome_options=options)
# Selenium执行cdp命令,再次覆盖window.navigator.webdriver的值
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# driver = webdriver.Chrome()
driver.get(url)
time.sleep(5)
# 获取渲染后网页源码 作为新请求
data = driver.page_source
driver.close()
# 创建响应对象
res = HtmlResponse(url = url, body=data, encoding='utf-8', request = request)
return res
若出现如下错误:
USB: usb_device_handle_win.cc:1049 Failed to read descriptor from node connection: 连到系统上的设备没有发挥作用
Selenium打开后数据不加载解决办法
settings.py
BOT_NAME = 'AQI'
SPIDER_MODULES = ['AQI.spiders']
NEWSPIDER_MODULE = 'AQI.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'AQI.middlewares.SeleniumMiddlewares': 543,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'AQI.pipelines.AqiPipeline': 300,
}
- 运行
{"title": "2014年02月成都空气质量指数日历史数据", "url": "https://www.aqistudy.cn/historydata/daydata.php?city=%E6%88%90%E9%83%BD&month=201402", "timestamp": 1624549483.1534758, "date": "2014-02-01", "AQI": "211", "LEVEL": "重度污染", "PM25": "161", "PM10": "207", "SO2": "14", "CO": "1.6", "NO2": "44", "O3": "73"}
{"title": "2014年02月成都空气质量指数日历史数据", "url": "https://www.aqistudy.cn/historydata/daydata.php?city=%E6%88%90%E9%83%BD&month=201402", "timestamp": 1624549483.1554708, "date": "2014-02-02", "AQI": "193", "LEVEL": "中度污染", "PM25": "145", "PM10": "177", "SO2": "14", "CO": "1.4", "NO2": "34", "O3": "78"}
...
小结
中间件的使用:
- 完善中间件代码:
-
process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
-
process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法+
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
-
需要在settings.py中开启中间件
middlewares.py
DOWNLOADER_MIDDLEWARES = { 'myspider.middlewares.UserAgentMiddleware': 543, }
scrapy_redis概念作用和流程
1. 分布式是什么
简单的说分布式就是不同的节点(服务器,ip不同)共同完成一个任务
特点:
加快运行速度,需要的资源(硬件&网络)依然还是原有的
单个节点的稳定性不影响整个系统的稳定性
2. scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式组件
3. scrapy_redis的作用
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
- 断点续爬
- 分布式快速抓取
4. scrapy_redis的工作流程
4.1 回顾scrapy的流程

4.2 scrapy_redis的流程
-
在scrapy_redis中,所有的待抓取的request对象和去重的request对象指纹都存在所有的服务器公用的redis中
-
所有的服务器中的scrapy进程公用同一个redis中的request对象的队列
-
所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
-
在默认情况下所有的数据会保存在redis中
具体流程如下:

小结
scarpy_redis的分布式工作原理
- 在scrapy_redis中,所有的待抓取的对象和去重的指纹都存在公用的redis中
- 所有的服务器公用同一redis中的请求对象的队列
- 所有的request对象存入redis前,都会通过请求对象的指纹进行判断,之前是否已经存入过
scrapy_redis原理分析并实现断点续爬以及分布式爬虫
1. 下载github的demo代码
-
clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git -
安装scrapy_redis
pip/pip3 install scrapy_redis -
研究项目自带的demo
mv scrapy-redis/example-project ~/scrapyredis-project
2. 观察dmoz文件
在domz爬虫文件中,实现方式就是之前的crawlspider类型的爬虫
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/'] # 这里修改了url
# 定义数据提取规则,使用了css选择器
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
但是在settings.py中多了以下内容,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用RedisPipeline管道类
# 设置重复过滤器的模块
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 设置调度器,scrapy_redis中的调度器具有与redis交互的功能
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 设置当爬虫结束的时候,是否保持redis数据库中的去重集合与任务队列
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 当开启该管道,该管道将会把数据存入redis中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
3. 运行dmoz爬虫,观察现象
- 首先我们需要添加redis的地址,程序才能够使用redis
# 设置redis数据库
REDIS_URL = "redis://127.0.0.1:6379"
#或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379
# 设置是否减慢下载速度,1为1s
DOWNLOAD_DELAY = 1
- 我们执行domz的爬虫,会发现redis中多了一下三个键:

- 中止进程后再次运行dmoz爬虫
继续执行程序,会发现程序在前一次的基础之上继续往后执行,所以domz爬虫是一个基于url地址的增量式的爬虫
4. scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析
分别是:
- RedisPipeline # 管道类
- RFPDupeFilter # 指纹去重类
- Scheduler # 调度器类
- SCHEDULER_PERSIST # 是否持久化请求队列和指纹集合
4.1 Scrapy_redis之RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中

4.2 Scrapy_redis之RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密

from w3lib.url import canonicalize_url
url1 = 'https://www.example.com/query?id=111&cat=222'
url2 = 'https://www.example.com/query?cat=222&id=111'
# 对url的参数顺序进行排序,先按key,再value, 用于去重
result = canonicalize_url(url1)
print(result) # url2 = 'https://www.example.com/query?cat=222&id=111'
print(url2) # url2 = 'https://www.example.com/query?cat=222&id=111'
4.3 Scrapy_redis之Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉

filter(function, iterable)
filter(None, iterable) - 过滤非空数据
filter 在python3中返回一个过滤器对象,python2中返回一个列表

4.4 由此可以总结出request对象入队的条件
- request的指纹不在集合中
- request的dont_filter为True,即不过滤
- start_urls中的url地址会入队,因为他们默认是不过滤
4.5 实现单机断点续爬
改写网易招聘爬虫,该爬虫就是一个经典的基于url地址的增量式爬虫
5. 实现分布式爬虫
5.1 分析demo中代码
打开example-project项目中的myspider_redis.py文件
通过观察代码:
- 继承自父类为RedisSpider
- 增加了一个redis_key的键,没有start_urls,因为分布式中,如果每台电脑都请求一次start_url就会重复
- 多了
__init__方法,该方法不是必须的,可以手动指定allow_domains - 启动方法:
- 在每个节点正确的目录下执行
scrapy crawl 爬虫名,使该节点的scrapy_redis爬虫程序就位 - 在共用的redis中
lpush redis_key 'start_url',使全部节点真正的开始运行
- 在每个节点正确的目录下执行
- settings.py中关键的配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
REDIS_URL = "redis://127.0.0.1:6379"
5.2 动手实现分布式爬虫
> 1.编写普通爬虫
- 创建项目
- 明确目标
- 创建爬虫
- 保存内容
> 2.改造成分布式爬虫
-1.改造爬虫
- 1.导入类
- 2.继承类
- 3.注销start_urls & allowed_domains
- 4.设置redis_key,获取start_urls
- 5. 设置__ init __()获取允许的域
-2.改造配置文件
- 1.copy配置参数
京东图书
页面分析
https://book.jd.com/

# 全部分类
https://book.jd.com/booksort.html

# 某一分类详情页面
https://list.jd.com/list.html?cat=1713,3258,3297

在response的源码分析发现,价格未存在网页中

search后找到mgets接口url


在抓包中查找接口

headers中找到对应url


分析该url,并删除无影响参数,并使用在线工具编解码分析


通过单个id进行查找


价格获取根据data-sku,拼接


编写普通爬虫
1.创建项目
scrapy startproject JD
2.确定爬取数据
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class JdItem(scrapy.Item):
# define the fields for your item here like:
# 分类页面
big_category = scrapy.Field() # 大分类
big_category_link = scrapy.Field() # 大分类链接
small_category = scrapy.Field() # 小分类
small_category_link = scrapy.Field() # 小分类链接
# 某分类详情页面
bookname = scrapy.Field() # 书名
booklink = scrapy.Field() # 链接
storename = scrapy.Field() # 店铺名
storelink = scrapy.Field() # 店铺链接
price = scrapy.Field() # 价格
comment = scrapy.Field() # 评论数量
- 创建并编写爬虫
cd JD
scrapy genspider book jd.com

# 大分类xpath
//*[@id="booksort"]/div[2]/dl/dt
# 小分类xpath
//*[@id="booksort"]/div[2]/dl/dt/../dd
图书详情页面
获取评论comment,同价格方法,找到GetCommentsCount 获取评论方法


过滤url 后找到评论所在 scrapy解决重定向问题

book.py
其中,详情页面和评论页面需要selenium渲染;
comment需要对GetCommentsCount页面发送请求,获取comment;
且会遇到 DEBUG: Redirecting (302) 重定向问题;
注意:extract() ->list,extract_first() ->str 类型
import scrapy
from JD.items import JdItem
import json
class BookSpider(scrapy.Spider):
name = 'book'
# 修改domians
allowed_domains = ['jd.com']
# allowed_domains = ['jd.com', 'p.3.cn'] # 获取价格的域
# 修改start_urls
start_urls = ['https://book.jd.com/booksort.html']
def parse(self, response):
# 获取大分类
big_category_list = response.xpath('//*[@id="booksort"]/div[2]/dl/dt')
# print(len(big_category_list))
for node_ in big_category_list[:1]:
big_category_name = node_.xpath('./a/text()').extract_first()
big_category_link = response.urljoin(node_.xpath('./a/@href').extract_first())
# 获取所有小分类节点列表
small_category_list = node_.xpath('./../dd')
# print(len(small_category_list))
for small_node in small_category_list[0:1]:
temp = {}
temp['big_category_name'] = big_category_name
temp['big_category_link'] = big_category_link
temp['small_category_name'] = small_node.xpath('./em/a/text()').extract_first()
temp['small_category_link'] = response.urljoin(small_node.xpath('./em/a/@href').extract_first())
# {'big_category_name': '小说', 'big_category_link': 'https://channel.jd.com/1713-3258.html', 'small_category_name': '藝術/設計', 'small_category_link': 'https://list.jd.com/1713-6929-6930.html'}
# print(temp)
# 模拟点击小分类链接
yield scrapy.Request(
url = temp['small_category_link'],
callback = self.parse_small_category,
meta ={'categories' : temp}
)
"""
# 2.模拟翻页参考
# 获取点击下一页'>'标签的url
part_url = response.xpath('//a[contains(text(), ">")]/@href').extract_first()
# 判断停止条件
# 最后一页中 > 根据href判断
if part_url != 'javascript:void(0)':
# 构建下一页url
next_url = response.urljoin(part_url)
# 构建请求对象并返回给引擎
yield scrapy.Request(
# 参数1:下一页url
url = next_url,
# 参数2:解析方法
# callback不指定,默认是self.parse方法
callback = self.parse
)
"""
def parse_small_category(self, response):
# 获取meta数据
temp = response.meta['categories']
# 获取详情页面所有图书节点列表
book_list = response.xpath('//*[@id="J_goodsList"]/ul/li/div')
# print(len(book_list))
for book in book_list[:1]:
# 向item中存放数据
item = JdItem()
# 保存分类信息
item['big_category'] = temp['big_category_name']
item['big_category_link'] = temp['big_category_link']
item['small_category'] = temp['small_category_name']
item['small_category_link'] = temp['small_category_link']
# 获取图书详情页数据
item['bookname'] = book.xpath('./div[3]/a/em/text()|./div/div[2]/div[2]/div[3]/a/em/text()').extract_first()
item['booklink'] = response.urljoin(book.xpath('./div[3]/a/@href').extract_first())
item['storename'] = book.xpath('./div[6]/a/@title').extract_first()
item['storelink'] = response.urljoin(book.xpath('./div[6]/a/@href').extract_first())
item['price'] = book.xpath('./div[2]/strong/i/text()').extract_first()
# 获取booksku向评论页面发起请求,获取id,拼接评论页面url
item['booksku'] = book.xpath('../@data-sku').extract_first()
# print(item['booksku'])
# 获取评论页面url,需要动态渲染
comment_url = 'http://club.jd.com/clubservice.aspx?method=GetCommentsCount&referenceIds=' + item['booksku']
# print(comment_url)
yield scrapy.Request(
url = comment_url,
callback = self.parse_comment,
meta = {
'item':item,
# 解决重定向302问题
'dont_redirect': True,
'handle_httpstatus_list': [301,302]
}
)
def parse_comment(self, response):
# 获取评论数量
item = response.meta['item']
# comment_response = json.loads(response.body))
comment_response = json.loads(response.xpath('/html/body/text()').extract_first())
item['comment'] = comment_response['CommentsCount'][0]['CommentCountStr']
yield item
middlewares.py
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from selenium import webdriver
from scrapy.http import HtmlResponse
import time
class SeleniumMiddlewares(object):
def process_request(self, request, spider):
# 获取url
url = request.url
# 判断是否来到每日详情页面
# https://www.aqistudy.cn/historydata/daydata.php?city=%E9%98%BF%E5%9D%9D%E5%B7%9E&month=2015-01
if 'book' or 'GetCommentsCount' in url:
# # 忽略无用日志
# options = webdriver.ChromeOptions()
# options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
# selenium 开启后无数据加载
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("--disable-blink-features=AutomationControlled")
# selenium加载渲染页面
driver = webdriver.Chrome(chrome_options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# driver = webdriver.Chrome()
driver.get(url)
time.sleep(5)
# 获取渲染后网页源码 作为新请求
data = driver.page_source
driver.close()
# 创建响应对象
res = HtmlResponse(url = url, body=data, encoding='utf-8', request = request)
return res
settings.py
BOT_NAME = 'JD'
SPIDER_MODULES = ['JD.spiders']
NEWSPIDER_MODULE = 'JD.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'JD.middlewares.SeleniumMiddlewares': 543,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'JD.pipelines.JdPipeline': 300,
}
- 保存数据
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class JdPipeline:
def open_spider(self, spider):
if spider.name == 'book':
self.file = open(spider.name + '.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
if spider.name == 'book':
self.file.write(json.dumps(dict(item), ensure_ascii=False) + '\n')
return item
def close_spider(self, spider):
if spider.name == 'book':
self.file.close()
- 运行普通scrapy爬虫
scrapy crawl book
```python
# item
{
'big_category': '小说',
'big_category_link': 'https://channel.jd.com/1713-3258.html',
'booklink': 'https://item.jd.com/13103720.html',
'bookname': '余华:文城(余华新书时隔8年重磅归来,《活着》之后又一精彩力作!)',
'booksku': '13103720',
'comment': '20万+',
'price': '39.50',
'small_category': '中国当代小说',
'small_category_link': 'https://list.jd.com/1713-3258-3297.html',
'storelink': 'https://mall.jd.com/index-1000005287.html?from=pc',
'storename': '新经典文化京东自营店'
}
修改为分布式爬虫
- 改造爬虫
1. 导入类
2. 继承类
3. 注销start_urls & allowed_domains
4. 设置redis_key,获取start_urls
5. 设置__ init __()获取允许的域
spiders/books.pyimport scrapy from JD.items import JdItem import json # -----分布式爬虫------ # ----1. 导入分布式爬虫类 from scrapy_redis.spiders import RedisSpider # ----2. 继承分布式爬虫类 # class BookSpider(scrapy.Spider): class BookSpider(RedisSpider): name = 'book' # ----3.注销allowed_domains和start_urls # # 修改domians # allowed_domains = ['jd.com'] # # 修改start_urls # start_urls = ['https://book.jd.com/booksort.html'] # ----4.设置redis_key redis_key = 'jd_book' # ----5.设置__init__() def __init__(self, *args, **kwargs): # pop domain,获取不出则抛出'' domain = kwargs.pop('domain', '') # 可能含有多个允许的域,python3中filter返回filter对象,python2中为list self.allowed_domains = list(filter(None, domain.split(','))) super(BookSpider, self).__init__(*args, **kwargs) def parse(self, response): # 获取大分类 big_category_list = response.xpath('//*[@id="booksort"]/div[2]/dl/dt') ... - 改造配置文件
1. copy配置参数
settings.py
redis中有密码 需要认证
window下使用redisBOT_NAME = 'JD' SPIDER_MODULES = ['JD.spiders'] NEWSPIDER_MODULE = 'JD.spiders' # ----------------------分布式爬虫 settings.py---------------------- # ----修改参数 # 设置redis数据库 # 注意:ValueError: Redis URL must specify one of the following schemes (redis://, rediss://, unix://) # redis中无密码,注意:redis//不能少 # REDIS_URL = 'redis://127.0.0.1:6379' # redis中有密码 REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 # 设置密码 REDIS_PARAMS = { 'password': '123456', } LOG_LEVEL = 'DEBUG' # Introduce an artifical delay to make use of parallelism. to speed up the # crawl. # 设置是否减慢下载速度,1为1s DOWNLOAD_DELAY = 1 # 设置重复过滤器的模块 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 设置调度器,scrapy_redis中的调度器具有与redis交互的功能 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 设置当爬虫结束的时候,是否保持redis数据库中的去重集合与任务队列 SCHEDULER_PERSIST = True #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { # 'JD.pipelines.JdPipeline': 300, 'JD.pipelines.RedisPipeline' : 400, } # ----------------------------------------------------------------- # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36' # Obey robots.txt rules # ROBOTSTXT_OBEY = True # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'JD.middlewares.SeleniumMiddlewares': 543, }先在redis目录下cmd: redis-server.exe redis.windows.conf 启动redis服务 再在redis目录下另开cmd,输入redis-cli -h 127.0.0.1 -p 6379 -a 密码

存入url


- 运行爬虫
# 普通爬虫:scrapy crawl 爬虫名 scrapy runspider 爬虫文件.py

小结
-
scrapy_redis的含义和能够实现的功能
- scrapy是框架
- scrapy_redis是scrapy的组件
- scrapy_redis能够实现断点续爬和分布式爬虫
- 使用场景:数据量大、需求时间紧
-
scrapy_redis流程和实现原理
- 在scrapy框架流程的基础上,把存储request对象放到了redis的有序集合中,利用该有序集合实现了请求队列
- 并对request对象生成指纹对象,也存储到同一redis的集合中,利用request指纹避免发送重复的请求
-
request对象进入队列的条件
- request的指纹不在集合中
- request的dont_filter为True,即不过滤
-
request指纹的实现
- 请求方法
- 排序后的请求地址
- 排序并处理过的请求体或空字符串
- 用hashlib.sha1()对以上内容进行加密
-
scarpy_redis实现增量式爬虫、布式爬虫
- 对setting进行如下设置
- DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
- SCHEDULER = “scrapy_redis.scheduler.Scheduler”
- SCHEDULER_PERSIST = True
- ITEM_PIPELINES = {‘scrapy_redis.pipelines.RedisPipeline’: 400,}
- REDIS_URL = “redis://127.0.0.1:6379” # 请正确配置REDIS_URL
- 爬虫文件中的爬虫类继承RedisSpider类
- 爬虫类中redis_key替代了start_urls
- 启动方式不同
- 通过
scrapy crawl spider启动爬虫后,向redis_key放入一个或多个起始url(lpush或rpush都可以),才能够让scrapy_redis爬虫运行
- 通过
- 除了以上差异点以外,scrapy_redis爬虫和scrapy爬虫的使用方法都是一样的
- 对setting进行如下设置
scrapy_splash组件的使用
1. 什么是scrapy_splash?
scrapy_splash是scrapy的一个组件
- scrapy-splash加载js数据是基于Splash来实现的。
- Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建。
- 使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码。
splash官方文档 https://splash.readthedocs.io/en/stable/
2. scrapy_splash的作用
scrapy-splash能够模拟浏览器加载js,并返回js运行后的数据
3. scrapy_splash的环境安装
3.1 使用splash的docker镜像
splash的dockerfile https://github.com/scrapinghub/splash/blob/master/Dockerfile
观察发现splash依赖环境略微复杂,所以我们可以直接使用splash的docker镜像
如果不使用docker镜像请参考 splash官方文档 安装相应的依赖环境
3.1.1 安装并启动docker服务
linux安装参考 https://blog.csdn.net/sanpic/article/details/81984683
windows splash
如果遇到以下错误下载并安装
next step
docker run -p 8050:8050 scrapinghub/splash



3.1.2 获取splash的镜像
在正确安装docker的基础上pull取splash的镜像
sudo docker pull scrapinghub/splash
3.1.3 验证是否安装成功
运行splash的docker服务,并通过浏览器访问8050端口验证安装是否成功
-
前台运行
sudo docker run -p 8050:8050 scrapinghub/splash -
后台运行
sudo docker run -d -p 8050:8050 scrapinghub/splash
访问 http://127.0.0.1:8050 看到如下截图内容则表示成功

3.1.4 解决获取镜像超时:修改docker的镜像源
以ubuntu18.04为例
- 创建并编辑docker的配置文件
sudo vi /etc/docker/daemon.json
- 写入国内docker-cn.com的镜像地址配置后保存退出
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
-
重启电脑或docker服务后重新获取splash镜像
-
这时如果还慢,请使用手机热点
3.1.5 关闭splash服务
需要先关闭容器后,再删除容器
sudo docker ps -a
sudo docker stop CONTAINER_ID
sudo docker rm CONTAINER_ID
3.2 在python虚拟环境中安装scrapy-splash包
pip install scrapy-splash
4. 在scrapy中使用splash
以baidu为例


4.1 创建项目创建爬虫
scrapy startproject test_splash
cd test_splash
scrapy genspider no_splash baidu.com
scrapy genspider with_splash baidu.com
4.2 完善settings.py配置文件
在settings.py文件中添加splash的配置以及修改robots协议
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
4.3 不使用splash
在spiders/no_splash.py中完善
import scrapy
class NoSplashSpider(scrapy.Spider):
name = 'no_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def parse(self, response):
with open('no_splash.html', 'w') as f:
f.write(response.body.decode())
4.4 使用splash
在spiders/with_splash.py中完善
import scrapy
from scrapy_splash import SplashRequest # 使用scrapy_splash包提供的request对象
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
4.5 分别运行俩个爬虫,并观察现象
4.5.1 分别运行俩个爬虫
scrapy crawl no_splash
scrapy crawl with_splash
4.5.2 观察获取的俩个html文件
不使用splash

使用splash

4.6 结论
- splash类似selenium,能够像浏览器一样访问请求对象中的url地址
- 能够按照该url对应的响应内容依次发送请求
- 并将多次请求对应的多次响应内容进行渲染
- 最终返回渲染后的response响应对象
5. 了解更多
关于splash https://www.cnblogs.com/zhangxinqi/p/9279014.html
关于scrapy_splash(截屏,get_cookies等) https://www.e-learn.cn/content/qita/800748
小结
-
scrapy_splash组件的作用
- splash类似selenium,能够像浏览器一样访问请求对象中的url地址
- 能够按照该url对应的响应内容依次发送请求
- 并将多次请求对应的多次响应内容进行渲染
- 最终返回渲染后的response响应对象
-
scrapy_splash组件的使用
- 需要splash服务作为支撑
- 构造的request对象变为splash.SplashRequest
- 以下载中间件的形式使用
- 需要scrapy_splash特定配置
-
scrapy_splash的特定配置
SPLASH_URL = 'http://127.0.0.1:8050' DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
scrapy的日志信息与配置
1. 了解scrapy的日志信息

2. scrapy的常用配置
-
ROBOTSTXT_OBEY 是否遵守robots协议,默认是遵守
- 关于robots协议
url/robots.txt- 在百度搜索中,不能搜索到淘宝网中某一个具体的商品的详情页面,这就是robots协议在起作用
- Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的一般约定
- 例如:淘宝的robots协议
- 关于robots协议
-
USER_AGENT 设置ua
-
DEFAULT_REQUEST_HEADERS 设置默认请求头,这里加入了USER_AGENT将不起作用
-
ITEM_PIPELINES 管道,左位置右权重:权重值越小,越优先执行
-
SPIDER_MIDDLEWARES 爬虫中间件,设置过程和管道相同
-
DOWNLOADER_MIDDLEWARES 下载中间件,设置过程和管道相同
-
COOKIES_ENABLED 默认为True表示开启cookie传递功能,即每次请求带上前一次的cookie,做状态保持
-
COOKIES_DEBUG 默认为False表示日志中不显示cookie的传递过程
-
LOG_LEVEL 默认为DEBUG,控制日志的等级,无默认设置,需要在settings.py中手动设置(DEBUG,WARINING,INFO,ERROR,CRITICAL,从左至右日志等级逐渐增高,设置WARNING时,WARNING及更高级别日志INFO…CRITICAL将被输出)
- LOG_LEVEL = “WARNING” (一般设置为INFO和WARNING)
-
LOG_FILE 设置log日志文件的保存路径,如果设置该参数,日志信息将写入文件,终端将不再显示,且受到LOG_LEVEL日志等级的限制
- LOG_FILE = “./test.log”
3. scrapy_redis配置
- DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter” # 指纹生成以及去重类
- SCHEDULER = “scrapy_redis.scheduler.Scheduler” # 调度器类
- SCHEDULER_PERSIST = True # 持久化请求队列和指纹集合
- ITEM_PIPELINES = {‘scrapy_redis.pipelines.RedisPipeline’: 400} # 数据存入redis的管道
- redis无密码
REDIS_URL = “redis://host:port” # redis的url - redis 存在密码
REDIS_HOST = redis的url
REDIS_PORT = 6379
REDIS_PARAMS = {
‘password’: ‘123456’,
}
4. scrapy_splash配置
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
5. scrapy_redis和scrapy_splash配合使用的配置
5.1 原理
- scrapy-redis中配置了”DUPEFILTER_CLASS” : “scrapy_redis.dupefilter.RFPDupeFilter”,与scrapy-splash配置的DUPEFILTER_CLASS = ‘scrapy_splash.SplashAwareDupeFilter’ 相冲突!
- 查看了scrapy_splash.SplashAwareDupeFilter源码后,发现他继承了scrapy.dupefilter.RFPDupeFilter,并重写了request_fingerprint()方法。
- 比较scrapy.dupefilter.RFPDupeFilter和scrapy_redis.dupefilter.RFPDupeFilter中的request_fingerprint()方法后,发现是一样的,因此重写了一个SplashAwareDupeFilter,继承scrapy_redis.dupefilter.RFPDupeFilter,其他代码不变。
5.2 重写dupefilter去重类,并在settings.py中使用
5.2.1 重写去重类
from __future__ import absolute_import
from copy import deepcopy
from scrapy.utils.request import request_fingerprint
from scrapy.utils.url import canonicalize_url
from scrapy_splash.utils import dict_hash
from scrapy_redis.dupefilter import RFPDupeFilter
def splash_request_fingerprint(request, include_headers=None):
""" Request fingerprint which takes 'splash' meta key into account """
fp = request_fingerprint(request, include_headers=include_headers)
if 'splash' not in request.meta:
return fp
splash_options = deepcopy(request.meta['splash'])
args = splash_options.setdefault('args', {})
if 'url' in args:
args['url'] = canonicalize_url(args['url'], keep_fragments=True)
return dict_hash(splash_options, fp)
class SplashAwareDupeFilter(RFPDupeFilter):
"""
DupeFilter that takes 'splash' meta key in account.
It should be used with SplashMiddleware.
"""
def request_fingerprint(self, request):
return splash_request_fingerprint(request)
"""以上为重写的去重类,下边为爬虫代码"""
from scrapy_redis.spiders import RedisSpider
from scrapy_splash import SplashRequest
class SplashAndRedisSpider(RedisSpider):
name = 'splash_and_redis'
allowed_domains = ['baidu.com']
# start_urls = ['https://www.baidu.com/s?wd=13161933309']
redis_key = 'splash_and_redis'
# lpush splash_and_redis 'https://www.baidu.com'
# 分布式的起始的url不能使用splash服务!
# 需要重写dupefilter去重类!
def parse(self, response):
yield SplashRequest('https://www.baidu.com/s?wd=13161933309',
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('splash_and_redis.html', 'w') as f:
f.write(response.body.decode())
5.2.2 scrapy_redis和scrapy_splash配合使用的配置
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# 去重过滤器
# DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 指纹生成以及去重类
DUPEFILTER_CLASS = 'test_splash.spiders.splash_and_redis.SplashAwareDupeFilter' # 混合去重类的位置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器类
SCHEDULER_PERSIST = True # 持久化请求队列和指纹集合, scrapy_redis和scrapy_splash混用使用splash的DupeFilter!
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400} # 数据存入redis的管道
REDIS_URL = "redis://127.0.0.1:6379" # redis的url
注意:
- scrapy_redis分布式爬虫在业务逻辑结束后并不能够自动退出
- 重写的dupefilter去重类可以自定义位置,也须在配置文件中写入相应的路径
6. 了解scrapy的其他配置
- CONCURRENT_REQUESTS 设置并发请求的数量,默认是16个
- DOWNLOAD_DELAY 下载延迟,默认无延迟,单位为秒
- 其他设置参考:https://www.jianshu.com/p/df9c0d1e9087
小结
- 了解scrapy的日志信息
- 掌握scrapy的常用配置
- 掌握scrapy_redis配置
- 了解scrapy_splash配置
- 了解scrapy_redis和scrapy_splash配合使用的配置
scrapyd部署scrapy项目
1. scrapyd的介绍
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
所谓json api本质就是post请求的webapi
2. scrapyd的安装
scrapyd服务:
pip install scrapyd
scrapyd客户端:
pip install scrapyd-client
3. 启动scrapyd服务
-
在scrapy项目路径下 启动scrapyd的命令:
sudo scrapyd或scrapyd -
启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面


- 点击job可以查看任务监控界面

4. scrapy项目部署
4.1 配置需要部署的项目
编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)
[deploy:部署名(部署名可以自行定义)]
url = http://localhost:6800/
project = 项目名(创建爬虫项目时使用的名称)
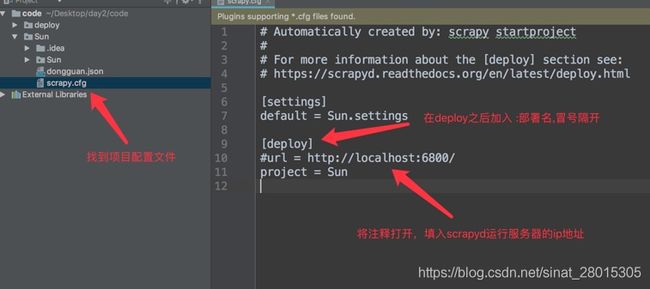
4.2 部署项目到scrapyd
同样在scrapy项目路径下执行:
scrapyd-deploy 部署名(配置文件中设置的名称) -p 项目名称

部署成功之后就可以看到部署的项目

4.3 管理scrapy项目
- 启动项目:
curl http://localhost:6800/schedule.json -d project=项目名 -d spider=项目下的爬虫名

- 关闭爬虫:
curl http://localhost:6800/cancel.json -d project=项目名 -d job=jobid
注意;curl是命令行工具,如果没有则需要额外安装
4.4 使用requests模块控制scrapy项目
import requests
# 启动和关闭命令实际是对JSON API发送post请求
# 启动爬虫
url = 'http://localhost:6800/schedule.json'
data = {
'project': 项目名,
'spider': 爬虫名,
}
resp = requests.post(url, data=data)
# 停止爬虫
url = 'http://localhost:6800/cancel.json'
data = {
'project': 项目名,
'job': 启动爬虫时返回的jobid,
}
resp = requests.post(url, data=data)
5. 了解scrapyd的其他webapi
- curl http://localhost:6800/listprojects.json (列出项目)
- curl http://localhost:6800/listspiders.json?project=myspider (列出爬虫)
- curl http://localhost:6800/listjobs.json?project=myspider (列出job)
- curl http://localhost:6800/cancel.json -d project=myspider -d job=tencent (终止爬虫,该功能会有延时或不能终止爬虫的情况,此时可用kill -9杀进程的方式中止)
- scrapyd还有其他webapi,百度搜索了解更多
小结
- 在scrapy项目路径下执行
sudo scrapyd或scrapyd,启动scrapyd服务;或以后台进程方式启动nohup scrapyd > scrapyd.log 2>&1 & - 部署scrapy爬虫项目
scrapyd-deploy -p myspider - 启动爬虫项目中的一个爬虫
curl http://localhost:6800/schedule.json -d project=myspider -d spider=tencent
13.Gerapy
1.Gerapy介绍:
Gerapy 是一款 分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
2.Gerapy的安装
1.执行如下命令,等待安装完毕
pip3 install gerapy
2.验证gerapy是否安装成功
在终端中执行 gerapy 会出现如下信息
“”"
Usage:
gerapy init [–folder=]
gerapy migrate
gerapy createsuperuser
gerapy runserver [host:port]
“”"
3.Gerapy配置启动
1.新建一个项目
gerapy init
执行完该命令之后会在当前目录下生成一个gerapy文件夹,进入该文件夹,会找到一个名为projects的文件夹

2.对数据库进行初始化(在gerapy目录中操作),执行如下命令
gerapy migrate
对数据库初始化之后会生成一个SQLite数据库,数据库保存主机配置信息和部署版本等

3.启动 gerapy服务
gerapy runserver
此时启动gerapy服务的这台机器的8000端口上开启了Gerapy服务,在浏览器中输入http://localhost:8000就能进入Gerapy管理界面,在管理界面就可以进行主机管理和界面管理

4.通过Gerapy配置管理scrapy项目
-
配置主机
1.添加scrapyd主机


需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,创建成功后,我们可以在列表中查看已经添加的服务
2.执行爬虫,就点击调度.然后运行. (前提是: 我们配置的scrapyd中,已经发布了爬虫.)


-
配置Projects
1.我们可以将scarpy项目直接放到 /gerapy/projects下.

2.可以在gerapy后台看到有个项目

3.点击部署点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称。


4.选择一个站点,点击右侧部署,将该项目部署到该站点上

5.成功部署之后会显示描述和部署时间

6.来到clients界面,找到部署该项目的节点,点击调度

7.在该节点中的项目列表中找到项目,点击右侧run运行项目

补充:
1.Gerapy 与 scrapyd 有什么关联吗?
我们仅仅使用scrapyd是可以调用scrapy进行爬虫. 只是需要使用命令行开启爬虫
curl http://127.0.0.1:6800/schedule.json -d project=工程名 -d spider=爬虫名
使用Greapy就是为了将使用命令行开启爬虫变成 “小手一点”. 我们在gerapy中配置了scrapyd后,不需要使用命令行,可以通过图形化界面直接开启爬虫.
小结
- 了解 什么是Gerapy
- 掌握 Gerapy的安装
- 掌握 Gerapy配置启动
- 掌握 通过Gerapy配置管理scrapy项目
appium环境安装
2.1 环境安装
以win10为例
2.1.1 安装node.js
- 点击进入 https://nodejs.org/zh-cn/
- 点击下载安装包

- 双击安装包,然后同样一路狂点下一步
- 安装完成后在cmd终端中输入
node -v,显示版本号则表示安装成功
2.1.2 安装java JDK
- 点击进入官网下载页面 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- 注意下载位置,点击同意协议,下载相应的版本

- 双击安装包,然后同样一路狂点下一步

!!!注意安装位置,默认是C:\Program Files\Java,尽量不要修改。
-
添加环境变量
-
CLASSPATH
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;注意上边最开始有个点
-
JAVA_HOME
C:\Program Files\Java\jdk1.8.0_191 -
Path
%JAVA_HOME%\bin%JAVA_HOME%\jre\bin
在cmd终端中输入java和javac不报异常,说明安装成功
-




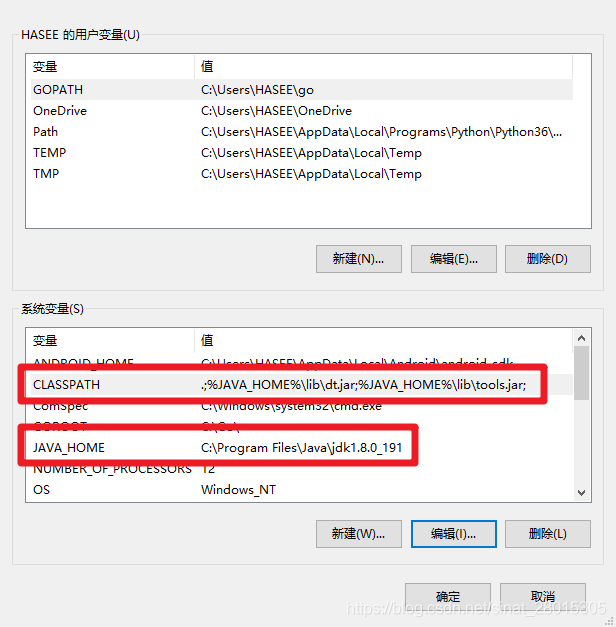

2.1.3 安装android SDK
- 进入网站 https://www.androiddevtools.cn/
地址2 - 依次点击AndroidSDK工具>>SDK Tools>>会跳转到以下界面,Windows建议选择.exe后缀

- 下载后安装

注意此处,点击第一项,为所有用户安装




如果不小心关闭了,或者没有自动打开上边的界面,点击安装目录下的SDK Mansger.exe文件,同样可以打开,已经自动打开的忽略此步。





下载完成后,你的sdk文件夹下,应该是这样的

-
安装环境变量
-
ANDROID_HOME
C:\...\Android\android-sdk -
Path
%ANDROID_HOME%\tools
%ANDROID_HOME%\platform-tools
-


2.1.4 安装Appium
- 需要科学上网 http://appium.io/(chrome)
- 点击下载并安装



2.1.5 安装夜神模拟器
- 下载并安装夜神模拟器 https://www.yeshen.com/
- 首先,下载完成后不要忙着打开夜神模拟器,先确保你的电脑Hyper-V是关闭的,否则启动模拟器时部分电脑会蓝屏重启。

- 把安卓sdk中的adb.exe复制两份,其中一个改名为nox_adb.exe后,放到夜神模拟器安装目录的bin目录下覆盖原文件



2.2 联调测试环境
2.2.1 开启并设置夜神安卓模拟器


2.2.2 adb命令建立连接
-
在夜神模拟器安装路径下的bin目录下执行cmd进入终端
-
输入
adb devices后,出现提示List of devices attached * daemon not running; starting now at tcp:5037 * daemon started successfully -
再输入
nox_adb.exe connect 127.0.0.1:62001后,出现提示connected to 127.0.0.1:62001 -
最后再次输入
adb devices后,出现提示List of devices attached 127.0.0.1:62001 device

2.2.3 开启Appium并配置运行
-
获取app包名和进程名
-
打开夜神模拟器中的浏览器
-
在adb连接正确的情况下,在夜神模拟器安装目录的bin目录下的cmd中输入
adb shell -
进入adb shell后输入
dumpsys activity | grep mFocusedActivity -
com.android.browser就是app包名 -
.BrowserActivity就是进程名
-

- 启动Appium,点击start server

- 点击放大镜进入并输入测试配置


-
配置参数的来源
-
platformName 系统名
Android -
platformVersion 系统版本
4.4.2 -
deviceName 手机型号
SM-G955F -
appPackage app的包名
com.android.browser -
appActivity app的进程名
.BrowserActivity
-

- 关闭夜神模拟器中的浏览器,点击右下角的start session查看运行结果

2.2.4 干的漂亮!环境搭建成功
利用appium自动控制移动设备并提取数据
以控制抖音app滑动并获取抖音短视频发布者昵称和点赞数等信息为例
2.1 安装appium-python-client模块并启动已安装好的环境
2.1.1 安装appium-python-client模块
在window的虚拟环境下执行pip install appium-python-client
2.1.2 启动夜神模拟器,进入夜神模拟器所在的安装路径的bin目录下,进入cmd终端,使用adb命令建立adb server和模拟器的连接
adb devices
C:\Program Files (x86)\Nox\bin>adb devices
List of devices attached
* daemon not running; starting now at tcp:5037
* daemon started successfully
nox_adb.exe connect 127.0.0.1:62001
C:\Program Files (x86)\Nox\bin>nox_adb.exe connect 127.0.0.1:62001
already connected to 127.0.0.1:62001
adb devices
C:\Program Files (x86)\Nox\bin>adb devices
List of devices attached
127.0.0.1:62001 device
2.1.3 启动appium-desktop,点击start server启动appium服务
[Appium] Welcome to Appium v1.10.0
[Appium] Appium REST http interface listener started on 0.0.0.0:4723
2.1.4 利用上一小节所学习的内容获取Desired Capabilities参数
- 获取模拟设备的型号
- 打开设置——关于平板电脑
- 查看型号,获取模拟设备的型号
- 获取app包名称 以及 app进程名
- 打开模拟器中的抖音短视频app
- 在adb连接正确的情况下,在夜神模拟器安装目录的bin目录下的cmd中输入
adb shell - 进入adb shell后输入
dumpsys activity | grep mFocusedActivity - ``com.ss.android.ugc.aweme`就是app包名
.main.MainActivity就是进程名 注意前边有个点.
2.2 初始化以及获取移动设备分辨率
完成代码如下,并运行代码查看效果:如果模拟器中抖音app被启动,并打印出模拟设备的分辨率则成功
from appium import webdriver
# 初始化配置,设置Desired Capabilities参数
desired_caps = {
'platformName': 'Android',
'deviceName': 'SM-G955F',
'appPackage': 'com.ss.android.ugc.aweme',
'appActivity': '.main.MainActivity'
}
# 指定Appium Server
server = 'http://localhost:4723/wd/hub'
# 新建一个driver
driver = webdriver.Remote(server, desired_caps)
# 获取模拟器/手机的分辨率(px)
width = driver.get_window_size()['width']
height = driver.get_window_size()['height']
print(width, height)
-
移动设备分辨率
-
driver.get_window_size()[‘width’]
-
driver.get_window_size()[‘height’]
-
2.3 定位元素以及提取文本的方法
2.3.1 点击appium desktop右上角的放大镜图标
如图填写配置,并点击start session

2.3.2 定位界面的使用方法如下图所示

2.3.3 点击短视频的作者名字,查看并获取该元素的id
2.3.4 在python使用代码通过元素id获取该元素的文本内容
实例化appium driver对象后添加如下代码,运行并查看效果
# 获取视频的各种信息:使用appium desktop定位元素
print(driver.find_element_by_id('bc').text) # 发布者名字
print(driver.find_element_by_id('al9').text) # 点赞数
print(driver.find_element_by_id('al_').text) # 留言数
print(driver.find_element_by_id('a23').text) # 视频名字,可能不存在,报错
-
定位元素及获取其文本内容的方法
- driver.find_element_by_id(元素的id).text
- driver.find_element_by_xpath(定位元素的xpath规则).text
2.4 控制抖音app滑动
2.4.1 appium滑动的函数
从(start_x, start_y)滑动到(end_x, end_y)
- driver.swipe(start_x, start_y, end_x, end_y)
2.4.2 控制抖音app滑动的代码实现
start_x = width // 2 # 滑动的起始点的x坐标,屏幕宽度中心点
start_y = height // 3 * 2 # 滑动的起始点的y坐标,屏幕高度从上开始到下三分之二处
distance = height // 2 # y轴滑动距离:屏幕高度一半的距离
end_x = start_x # 滑动的终点的x坐标
end_y = start_y-distance # 滑动的终点的y坐标
# 滑动
driver.swipe(start_x, start_y, end_x, end_y)
2.5 整理并完成自动滑动的代码
import time
from appium import webdriver
class DouyinAction():
"""自动滑动,并获取抖音短视频发布者的id"""
def __init__(self, nums:int=None):
# 初始化配置,设置Desired Capabilities参数
self.desired_caps = {
'platformName': 'Android',
'deviceName': 'SM-G955F',
'appPackage': 'com.ss.android.ugc.aweme',
'appActivity': '.main.MainActivity'
}
# 指定Appium Server
self.server = 'http://localhost:4723/wd/hub'
# 新建一个driver
self.driver = webdriver.Remote(self.server, self.desired_caps)
# 获取模拟器/手机的分辨率(px)
width = self.driver.get_window_size()['width']
height = self.driver.get_window_size()['height']
print(width, height)
# 设置滑动初始坐标和滑动距离
self.start_x = width//2 # 屏幕宽度中心点
self.start_y = height//3*2 # 屏幕高度从上开始到下三分之二处
self.distance = height//2 # 滑动距离:屏幕高度一半的距离
# 设置滑动次数
self.nums = nums
def comments(self):
# app开启之后点击一次屏幕,确保页面的展示
time.sleep(2)
self.driver.tap([(500, 1200)], 500)
def scroll(self):
# 无限滑动
i = 0
while True:
# 模拟滑动
print('滑动ing...')
self.driver.swipe(self.start_x, self.start_y,
self.start_x, self.start_y-self.distance)
time.sleep(1)
self.get_infos() # 获取视频发布者的名字
# 设置延时等待
time.sleep(4)
# 判断是否退出
if self.nums is not None and self.nums == i:
break
i += 1
def get_infos(self):
# 获取视频的各种信息:使用appium desktop定位元素
print(self.driver.find_element_by_id('bc').text) # 发布者名字
print(self.driver.find_element_by_id('al9').text) # 点赞数
print(self.driver.find_element_by_id('al_').text) # 留言数
print(self.driver.find_element_by_id('a23').text) # 视频名字,可能不存在,报错
# # 点击【分享】坐标位置 671,1058
# self.driver.tap([(671, 1058)])
# time.sleep(2)
# # 向左滑动露出 【复制链接】 580,1100 --> 200, 1100
# self.driver.swipe(580,1100, 20, 200, 1100)
# # self.driver.get_screenshot_as_file('./a.png') # 截图
# # 点击【复制链接】 距离右边60 距离底边170 720-60,1280-170
# self.driver.tap([(660, 1110)])
# # self.driver.get_screenshot_as_file('./b.png') # 截图
def main(self):
self.comments() # 点击一次屏幕,确保页面的展示
time.sleep(2)
self.scroll() # 滑动
if __name__ == '__main__':
action = DouyinAction(nums=5)
action.main()
至此,可以参考爬虫5.0课程项目库,使用fiddler等抓包工具,利用appium+mitmproxy+wget等python模块自动获取抖音视频文件
2.6 关于模拟式移动端爬虫的参考阅读
-
https://zhuanlan.zhihu.com/appium
-
https://github.com/butomo1989/docker-android
-
https://blog.csdn.net/weixin_42620645/article/details/83828863
-
https://blog.csdn.net/weixin_39211232/article/details/83410130#Android_16
-
https://www.jianshu.com/p/bf1ca3d4ac76
-
http://www.testclass.net/appium/