yolov5-seg的ort部署
本文主要是简单写了一个yolov5-seg的onnxruntime推理工程,python版本的,分享给大家。验证了预处理和解码过程,并进行了简单地属性和方法封装。
'''
Descripttion:
version:
@Company:
Author:
Date: 2022-09-28 00:07:30
LastEditors:
LastEditTime: 2022-09-29 09:05:01
'''
import onnx
import numpy as np
import onnxruntime as rt
import cv2
import time
import torch
import torchvision
import torch.nn.functional as F
import argparse
import logging
LOGGER = logging.getLogger("v5-seg")
class YOLOV5_SEG:
def __init__(self,
model_path,
conf_thres=0.25,
iou_thres=0.45,
max_det=1000):
self.model_path = model_path
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.max_det = max_det
#初始化模型
self.sess = rt.InferenceSession(
self.model_path,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
#获取网络输入输出名
model_inputs = self.sess.get_inputs()
self.input_names = [
model_inputs[i].name for i in range(len(model_inputs))
]
model_outputs = self.sess.get_outputs()
self.output_names = [
model_outputs[i].name for i in range(len(model_outputs))
]
#获取网络的入口大小
self.net_input_shape = model_inputs[0].shape
self.net_input_height = self.net_input_shape[2]
self.net_input_width = self.net_input_shape[3]
#由模型文件获取类别id
meta = self.sess.get_modelmeta().custom_metadata_map # metadata
self.class_names = eval(meta['names'])
def letterbox(self,
color=(114, 114, 114),
auto=False,
scaleFill=False,
scaleup=True,
stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = self.image0.shape[:2] # current shape [height, width]
new_shape = (self.net_input_height, self.net_input_width)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[
1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[
0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(self.image0,
new_unpad,
interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im,
top,
bottom,
left,
right,
cv2.BORDER_CONSTANT,
value=color) # add border
return im, ratio, (dw, dh)
def from_numpy(self, x):
return torch.from_numpy(x).to("cuda") if isinstance(x,
np.ndarray) else x
def box_area(self, box):
# box = xyxy(4,n)
return (box[2] - box[0]) * (box[3] - box[1])
def box_iou(self, box1, box2, eps=1e-7):
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
(a1, a2), (b1, b2) = box1[:, None].chunk(2, 2), box2.chunk(2, 1)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = inter / (area1 + area2 - inter)
return inter / (self.box_area(box1.T)[:, None] +
self.box_area(box2.T) - inter + eps)
def xywh2xyxy(self, x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def non_max_suppression(self,
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nm=0):
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 0.5 + 0.05 * bs # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
mi = 5 + nc # mask start index
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 5), device=x.device)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box/Mask
box = self.xywh2xyxy(
x[:, :4]
) # center_x, center_y, width, height) to (x1, y1, x2, y2)
mask = x[:, mi:] # zero columns if no masks
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:mi] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat(
(box[i], x[i, 5 + j, None], j[:, None].float(), mask[i]),
1)
else: # best class only
conf, j = x[:, 5:mi].max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask),
1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes,
device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(
descending=True)[:max_nms]] # sort by confidence
else:
x = x[x[:, 4].argsort(descending=True)] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :
4] + c, x[:,
4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n <
3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = self.box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(
1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
LOGGER.warning(
f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
return output
def clip_boxes(self, boxes, shape):
# Clip boxes (xyxy) to image shape (height, width)
if isinstance(boxes, torch.Tensor): # faster individually
boxes[:, 0].clamp_(0, shape[1]) # x1
boxes[:, 1].clamp_(0, shape[0]) # y1
boxes[:, 2].clamp_(0, shape[1]) # x2
boxes[:, 3].clamp_(0, shape[0]) # y2
else: # np.array (faster grouped)
boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
def scale_boxes(self, img1_shape, boxes, img0_shape, ratio_pad=None):
# Rescale boxes (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0],
img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (
img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
boxes[:, [0, 2]] -= pad[0] # x padding
boxes[:, [1, 3]] -= pad[1] # y padding
boxes[:, :4] /= gain
self.clip_boxes(boxes, img0_shape)
return boxes
def crop_mask(self, masks, boxes):
"""
"Crop" predicted masks by zeroing out everything not in the predicted bbox.
Vectorized by Chong (thanks Chong).
Args:
- masks should be a size [h, w, n] tensor of masks
- boxes should be a size [n, 4] tensor of bbox coords in relative point form
"""
n, h, w = masks.shape
x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4,
1) # x1 shape(1,1,n)
r = torch.arange(w, device=masks.device,
dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
c = torch.arange(h, device=masks.device,
dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
def process_mask(self, protos, masks_in, bboxes, shape, upsample=False):
"""
上采样之前先进行crop裁剪,再上采样(插值法)
proto_out(ie. protos): [mask_dim, mask_h, mask_w],[32,160,160]
out_masks(ie. masks_in): [n, mask_dim], n is number of masks after nms,[7,32]
bboxes: [n, 4], n is number of masks after nms
shape:input_image_size, (h, w)
return: h, w, n
"""
c, mh, mw = protos.shape # CHW
ih, iw = shape
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(
-1, mh, mw) # CHW
downsampled_bboxes = bboxes.clone()
downsampled_bboxes[:, 0] *= mw / iw
downsampled_bboxes[:, 2] *= mw / iw
downsampled_bboxes[:, 3] *= mh / ih
downsampled_bboxes[:, 1] *= mh / ih
masks = self.crop_mask(masks, downsampled_bboxes) # CHW
if upsample:
masks = F.interpolate(masks[None],
shape,
mode='bilinear',
align_corners=False)[0] # CHW
return masks.gt_(0.5) #大于0.5的
def preprocess(self, img_src_bgr):
"""_summary_
Args:
img_src_bgr (numpy array uint8): bgr
"""
self.image0 = img_src_bgr
letterbox_img = self.letterbox()[0] #padded resize
new_img = letterbox_img.transpose(2, 0, 1)[::-1] #hwc->chw,bgr->rgb
new_img = np.ascontiguousarray(new_img)
self.input_data = torch.from_numpy(new_img).to("cuda")
self.input_data = self.input_data.float()
self.input_data /= 255
self.input_data = self.input_data[None]
self.input_data = self.input_data.cpu().numpy() # torch to numpy
return self.input_data
def detect(self, input_src):
net_input_data = self.preprocess(input_src)
output = self.sess.run(self.output_names,
{self.input_names[0]: net_input_data})
return output
def postprocess(self, pred_out):
pred_det, proto = pred_out[0], pred_out[1]
pred_det, proto = self.from_numpy(pred_det), self.from_numpy(proto)
#nms
pred = self.non_max_suppression(pred_det,
self.conf_thres,
self.iou_thres,
classes=None,
agnostic=False,
max_det=self.max_det,
nm=32)
for i, det in enumerate(pred):
if len(det):
masks = self.process_mask(
proto[i],
det[:, 6:],
det[:, :4],
self.input_data.shape[2:],
upsample=True) #CHW,[instances_num, 640, 640]
# Rescale boxes from img_size to im0 size
# 就是将当前在letterbox等处理后的图像上检测的box结果,映射返回原图大小上
det[:, :4] = self.scale_boxes(self.input_data.shape[2:],
det[:, :4],
self.image0.shape).round()
return masks, det[:, :6]
class DRAW_RESULT(YOLOV5_SEG):
def __init__(self, modelpath, conf_thres, iou_thres):
super(DRAW_RESULT, self).__init__(modelpath, conf_thres, iou_thres)
def draw_detections(self, image, boxes, scores, class_ids):
for box, score, class_id in zip(boxes.cpu().numpy(),
scores.cpu().numpy(),
class_ids.cpu().numpy()):
x1, y1, x2, y2 = box.astype(int)
# Draw rectangle
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 0, 255), thickness=2)
label = self.class_names[class_id]
label = f'{label} {int(score * 100)}%'
cv2.putText(image,
label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0),
thickness=2)
def draw_mask(self, masks, colors_, im_src, alpha=0.5):
"""Plot masks at once.
Args:
masks (tensor): predicted masks on cuda, shape: [n, h, w]
colors_ (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
"""
# Add multiple masks of shape(h,w,n) with colors list([r,g,b], [r,g,b], ...)
if len(masks) == 0:
return
if isinstance(masks, torch.Tensor):
masks = torch.as_tensor(masks, dtype=torch.uint8)
masks = masks.permute(1, 2, 0).contiguous()
masks = masks.cpu().numpy()
# masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
masks = self.scale_image(masks.shape[:2], masks, im_src.shape)
masks = np.asarray(masks, dtype=np.float32)
colors_ = np.asarray(colors_, dtype=np.float32) # shape(n,3)
s = masks.sum(2, keepdims=True).clip(0, 1) # add all masks together
masks = (masks @ colors_).clip(0, 255) # (h,w,n) @ (n,3) = (h,w,3)
im_src[:] = masks * alpha + im_src * (1 - s * alpha)
def scale_image(self, im1_shape, masks, im0_shape, ratio_pad=None):
"""
img1_shape: model input shape, [h, w]
img0_shape: origin pic shape, [h, w, 3]
masks: [h, w, num]
"""
# Rescale coordinates (xyxy) from im1_shape to im0_shape
if ratio_pad is None: # calculate from im0_shape
gain = min(im1_shape[0] / im0_shape[0],
im1_shape[1] / im0_shape[1]) # gain = old / new
pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (
im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
else:
pad = ratio_pad[1]
top, left = int(pad[1]), int(pad[0]) # y, x
bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
if len(masks.shape) < 2:
raise ValueError(
f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}'
)
masks = masks[top:bottom, left:right]
masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
if len(masks.shape) == 2:
masks = masks[:, :, None]
return masks
class Colors:
def __init__(self):
hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A',
'92CC17', '3DDB86', '1A9334', '00D4BB', '2C99A8', '00C2FF',
'344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF',
'FF95C8', 'FF37C7')
self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
self.n = len(self.palette)
def __call__(self, i, bgr=False):
c = self.palette[int(i) % self.n]
return (c[2], c[1], c[0]) if bgr else c
@staticmethod
def hex2rgb(h): # rgb order (PIL)
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--imgpath',
type=str,
default="./images/zidane.jpg",
help="image path")
parser.add_argument('--modelpath',
type=str,
default="yolov5s-seg.onnx",
help="model path")
parser.add_argument('--confThreshold',
default=0.25,
type=float,
help='class confidence')
parser.add_argument('--nmsThreshold',
default=0.45,
type=float,
help='nms iou thresh')
args = parser.parse_args()
# 验证模型合法性
onnx_model = onnx.load(args.modelpath)
onnx.checker.check_model(onnx_model)
#验证ort是什么版本,能够使用gpu
device = rt.get_device()
print("device is : ", device)
_provider = rt.get_available_providers()
print("provider is : ", _provider)
# 读入图像
image0 = cv2.imread(args.imgpath)
v5_seg_detector = YOLOV5_SEG(args.modelpath,
conf_thres=args.confThreshold,
iou_thres=args.nmsThreshold)
# 进行推理(包含了预处理)
prediction_out = v5_seg_detector.detect(image0)
#后处理解码
final_mask, final_det = v5_seg_detector.postprocess(prediction_out)
print("start plotting")
d_r = DRAW_RESULT(args.modelpath,
conf_thres=args.confThreshold,
iou_thres=args.nmsThreshold)
colors_obj = Colors(
) # create instance for 'from utils.plots import colors'
d_r.draw_mask(final_mask,
colors_=[colors_obj(x, True) for x in final_det[:, 5]],
im_src=image0)
d_r.draw_detections(image0, final_det[:, :4], final_det[:, 4],
final_det[:, 5])
cv2.namedWindow("masks_det", cv2.WINDOW_NORMAL)
#CV_WINDOW_NORMAL就是0
cv2.imshow("masks_det", image0)
cv2.waitKey(0)
cv2.destroyAllWindows()
代码、模型和测试图片如下:
链接:https://pan.baidu.com/s/17KBWuOyrUDt4AEsLIaPCoQ
提取码:1314
创作不易,希望大家能够点赞,收藏,支持我一下,谢谢!
更新补充6/10/2022:将上面的v5-seg的ort推理从pytorch的tensor全部转到替换为ndarray
代码如下:
'''
Descripttion:
version:
@Company: WT-XM
Author: yang jinyi
Date: 2022-09-28 00:07:30
LastEditors: yang jinyi
LastEditTime: 2022-10-06 17:47:24
'''
from asyncio.log import logger
import onnx
import numpy as np
import onnxruntime as rt
import cv2
import time
import argparse
import logging
from scipy import ndimage
LOGGER = logging.getLogger("v5-seg")
class YOLOV5_SEG:
def __init__(self,
model_path,
conf_thres=0.25,
iou_thres=0.45,
max_det=1000):
self.model_path = model_path
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.max_det = max_det
#初始化模型
self.sess = rt.InferenceSession(
self.model_path,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
#获取网络输入输出名
model_inputs = self.sess.get_inputs()
self.input_names = [
model_inputs[i].name for i in range(len(model_inputs))
]
model_outputs = self.sess.get_outputs()
self.output_names = [
model_outputs[i].name for i in range(len(model_outputs))
]
#获取网络的入口大小
self.net_input_shape = model_inputs[0].shape
self.net_input_height = self.net_input_shape[2]
self.net_input_width = self.net_input_shape[3]
#由模型文件获取类别id
meta = self.sess.get_modelmeta().custom_metadata_map # metadata
self.class_names = eval(meta['names'])
def letterbox(self,
color=(114, 114, 114),
auto=False,
scaleFill=False,
scaleup=True,
stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = self.image0.shape[:2] # current shape [height, width]
new_shape = (self.net_input_height, self.net_input_width)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[
1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[
0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(self.image0,
new_unpad,
interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im,
top,
bottom,
left,
right,
cv2.BORDER_CONSTANT,
value=color) # add border
return im, ratio, (dw, dh)
def box_area(self, box):
# box = xyxy(4,n)
return (box[2] - box[0]) * (box[3] - box[1])
def box_iou(self, box1, box2, eps=1e-7):
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (ndarray[N, 4])
box2 (ndarray[M, 4])
Returns:
iou (ndarray[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
(a1, a2), (b1, b2) = np.split(box1[:, None], 2,
axis=2), np.split(box2, 2, axis=1)
array = np.minimum(a2, b2) - np.maximum(a1, b1)
inter = array.clip(0)
inter = inter.prod(2)
# IoU = inter / (area1 + area2 - inter)
return inter / (self.box_area(box1.T)[:, None] +
self.box_area(box2.T) - inter + eps)
def xywh2xyxy(self, x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def sigmoid(self, x):
s = 1 / (1 + np.exp(-x))
return s
def non_max_suppression(self,
prediction,
conf_thres=0.25,
iou_thres=0.45,
max_det=300,
nm=0):
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
# min_wh = 2 # (pixels) minimum box width and height
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into cv2.dnn.NMSBoxes
time_limit = 0.5 + 0.05 * bs # seconds to quit after
redundant = True # require redundant detections
merge = False # use merge-NMS,False
t = time.time()
mi = 5 + nc # mask start index,117中,前面是85(80类cls score, 4box, 1个obj score),后面是32(mask coeffient)
#numpy array不支持空数组的调用
#https://blog.csdn.net/weixin_31866177/article/details/107380707
#https://bobbyhadz.com/blog/python-indexerror-index-0-is-out-of-bounds-for-axis-0-with-size-0
#https://blog.csdn.net/weixin_38753213/article/details/106754787
#不能对数组的元素赋值,比如 a=np.empty((0,6)),a[0]=1,这样会出错
#output = np.zeros((0, 6 + nm), np.float32) * bs
#因此我们使用列表-》append-》转为numpy array
output = []
output_final = []
for xi, x in enumerate(prediction): # image index, image inference
# confidence, xc的shape:(1, 25200), xi = 0, x的shape:(25200, 117)
#下面这句话就是筛选出obj score > conf_thres的instances
#经过筛选后的x的shape为:(44, 117)
x = x[xc[xi]]
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box/Mask
# center_x, center_y, width, height) to (x1, y1, x2, y2)
box = self.xywh2xyxy(x[:, :4]) #shape[44, 4]
# zero columns if no masks,从第index=85(第86个数)开始至117
mask = x[:, mi:] #mask shape[44, 32]
# Detections matrix nx6 (xyxy, conf, cls)
# best class only
# x[:, 5:mi]是去除了4box + 1obj score的,就是cls score的从5到85
#下面这个max的第一个参数1,表示axis=1,就是按照列进行筛选cls中的最大值,且返回索引。
#keepdim 表示是否需要保持输出的维度与输入一样,keepdim=True表示输出和输入的维度一样,
# keepdim=False表示输出的维度被压缩了,也就是输出会比输入低一个维度。
# j:Get the class with the highest confidence
conf, j = x[:, 5:mi].max(axis=1), x[:, 5:mi].argmax(axis=1)
conf, j = conf.reshape(-1, 1), j.reshape(-1, 1)
# x的shape从[44, 38]经过conf.reshape(-1) > conf_thres筛选后变为
# [43, 38],且:38 = 4box + 1conf + 1类别id + 32coeffients
x = np.concatenate((box, conf, j.astype(float), mask),
axis=1)[conf.reshape(-1) > conf_thres]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[(-x[:, 4]).argsort()[:max_nms]] # sort by confidence
else:
x = x[(-x[:, 4]).argsort()] # sort by confidence
# Batched NMS
c = x[:, 5:6] * max_wh # classes
# boxes (offset by class), scores
boxes, scores = x[:, :4] + c, x[:, 4]
i = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(),
self.conf_thres, self.iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n <
3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = self.box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
#equal tensor.float()
#tt = np.dot(weights, x[:, :4]).astype(np.float32)
x[i, :4] = np.dot(weights, x[:, :4]).astype(
np.float32) / weights.sum(1, keepdims=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
#output[xi] = x[i]
output.append(x[i])
if (time.time() - t) > time_limit:
LOGGER.warning(
f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
output = np.array(output).reshape(-1, 6 + nm)
output_final.append(output)
return output_final
def clip_boxes(self, boxes, shape):
# Clip boxes (xyxy) to image shape (height, width)
if isinstance(boxes, np.ndarray): # faster individually
# np.array (faster grouped)
boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
else:
logger.info("type wont be supported")
def scale_boxes(self, img1_shape, boxes, img0_shape, ratio_pad=None):
# Rescale boxes (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0],
img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (
img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
boxes[:, [0, 2]] -= pad[0] # x padding
boxes[:, [1, 3]] -= pad[1] # y padding
boxes[:, :4] /= gain
self.clip_boxes(boxes, img0_shape)
return boxes
def crop_mask(self, masks, boxes):
"""
"Crop" predicted masks by zeroing out everything not in the predicted bbox.
Vectorized by Chong (thanks Chong).
Args:
- masks should be a size [h, w, n] ndarray of masks
- boxes should be a size [n, 4] ndarray of bbox coords in relative point form
"""
n, h, w = masks.shape
x1, y1, x2, y2 = np.split(boxes[:, :, None], 4,
axis=1) # x1 shape(n,1,1)
r = np.arange(w, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
c = np.arange(h, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
def process_mask(self, protos, masks_in, bboxes, shape, upsample=False):
"""
上采样之前先进行crop裁剪,再上采样(插值法)
proto_out(ie. protos): [mask_dim, mask_h, mask_w],[32,160,160]
out_masks(ie. masks_in): [n, mask_dim], n is number of masks after nms,[7,32]
bboxes: [n, 4], n is number of masks after nms
shape:input_image_size, (h, w)
return: h, w, n
"""
c, mh, mw = protos.shape # CHW
ih, iw = shape
#@就是matmul的另一种写法,torch和numpy都有matmul,
#masks_in:(3,32)、protos:(32,160,160)
#想要的ttt的shape为:[32, 3, 160]
#ttt = np.matmul(masks_in, protos) #错误
ttt = protos.astype(np.float32).reshape(c, -1)
ppp = masks_in @ ttt
masks = self.sigmoid(
(masks_in @ protos.astype(np.float32).reshape(c, -1))).reshape(
-1, mh, mw) # CHW
downsampled_bboxes = bboxes.copy()
downsampled_bboxes[:, 0] *= mw / iw
downsampled_bboxes[:, 2] *= mw / iw
downsampled_bboxes[:, 3] *= mh / ih
downsampled_bboxes[:, 1] *= mh / ih
masks = self.crop_mask(masks, downsampled_bboxes) # CHW
#tt = masks.transpose(2, 1, 0) # CHW->HWC,便于opencv的resize操作(仅可用于hwc)
if upsample:
masks = ndimage.zoom(masks[None], (1, 1, 4, 4),
order=1,
mode="nearest")[0]
#masks = masks.transpose(2, 0, 1) #HWC->CHW
tttt = masks.__gt__(0.5).astype(np.float32)
return tttt #大于0.5的
def preprocess(self, img_src_bgr):
"""_summary_
Args:
img_src_bgr (numpy array uint8): bgr
"""
self.image0 = img_src_bgr
letterbox_img = self.letterbox()[0] #padded resize
new_img = letterbox_img.transpose(2, 0, 1)[::-1] #hwc->chw,bgr->rgb
new_img = np.ascontiguousarray(new_img)
self.input_data = np.copy(new_img)
self.input_data = self.input_data.astype(np.float32)
self.input_data /= 255
self.input_data = self.input_data[None]
return self.input_data
def detect(self, input_src):
net_input_data = self.preprocess(input_src)
output = self.sess.run(self.output_names,
{self.input_names[0]: net_input_data})
return output
def postprocess(self, pred_out):
pred_det, proto = pred_out[0], pred_out[1]
#nms
pred = self.non_max_suppression(pred_det,
self.conf_thres,
self.iou_thres,
max_det=self.max_det,
nm=32)
for i, det in enumerate(pred):
if len(det):
masks = self.process_mask(
proto[i],
det[:, 6:],
det[:, :4],
self.input_data.shape[2:],
upsample=True) #CHW,[instances_num, 640, 640]
# Rescale boxes from img_size to im0 size
# 就是将当前在letterbox等处理后的图像上检测的box结果,映射返回原图大小上
det[:, :4] = self.scale_boxes(self.input_data.shape[2:],
det[:, :4],
self.image0.shape).round()
np.save("numpy_array_masks.npy", masks)
return masks, det[:, :6]
class DRAW_RESULT(YOLOV5_SEG):
def __init__(self, modelpath, conf_thres, iou_thres):
super(DRAW_RESULT, self).__init__(modelpath, conf_thres, iou_thres)
def draw_detections(self, image, boxes, scores, class_ids):
for box, score, class_id in zip(boxes, scores, class_ids):
x1, y1, x2, y2 = box.astype(int)
# Draw rectangle
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 0, 255), thickness=2)
label = self.class_names[class_id]
label = f'{label} {int(score * 100)}%'
cv2.putText(image,
label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0),
thickness=2)
def draw_mask(self, masks, colors_, im_src, alpha=0.5):
"""Plot masks at once.
Args:
masks (ndarray): predicted masks on cuda, shape: [n, h, w]
colors_ (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
"""
# Add multiple masks of shape(h,w,n) with colors list([r,g,b], [r,g,b], ...)
if len(masks) == 0:
return
if isinstance(masks, np.ndarray):
masks = np.asarray(masks, dtype=np.uint8)
masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
# masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
masks = self.scale_image(masks.shape[:2], masks, im_src.shape)
masks = np.asarray(masks, dtype=np.float32)
colors_ = np.asarray(colors_, dtype=np.float32) # shape(n,3)
s = masks.sum(2, keepdims=True).clip(0, 1) # add all masks together
masks = (masks @ colors_).clip(0, 255) # (h,w,n) @ (n,3) = (h,w,3)
im_src[:] = masks * alpha + im_src * (1 - s * alpha)
def scale_image(self, im1_shape, masks, im0_shape, ratio_pad=None):
"""
img1_shape: model input shape, [h, w]
img0_shape: origin pic shape, [h, w, 3]
masks: [h, w, num]
"""
# Rescale coordinates (xyxy) from im1_shape to im0_shape
if ratio_pad is None: # calculate from im0_shape
gain = min(im1_shape[0] / im0_shape[0],
im1_shape[1] / im0_shape[1]) # gain = old / new
pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (
im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
else:
pad = ratio_pad[1]
top, left = int(pad[1]), int(pad[0]) # y, x
bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
if len(masks.shape) < 2:
raise ValueError(
f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}'
)
masks = masks[top:bottom, left:right]
masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
if len(masks.shape) == 2:
masks = masks[:, :, None]
return masks
class Colors:
def __init__(self):
hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A',
'92CC17', '3DDB86', '1A9334', '00D4BB', '2C99A8', '00C2FF',
'344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF',
'FF95C8', 'FF37C7')
self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
self.n = len(self.palette)
def __call__(self, i, bgr=False):
c = self.palette[int(i) % self.n]
return (c[2], c[1], c[0]) if bgr else c
@staticmethod
def hex2rgb(h): # rgb order (PIL)
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--imgpath',
type=str,
default="./images/zidane.jpg",
help="image path")
parser.add_argument('--modelpath',
type=str,
default="yolov5s-seg.onnx",
help="model path")
parser.add_argument('--confThreshold',
default=0.25,
type=float,
help='class confidence')
parser.add_argument('--nmsThreshold',
default=0.45,
type=float,
help='nms iou thresh')
args = parser.parse_args()
# 验证模型合法性
onnx_model = onnx.load(args.modelpath)
onnx.checker.check_model(onnx_model)
#验证ort是什么版本,能够使用gpu
device = rt.get_device()
print("device is : ", device)
_provider = rt.get_available_providers()
print("provider is : ", _provider)
# 读入图像
image0 = cv2.imread(args.imgpath)
v5_seg_detector = YOLOV5_SEG(args.modelpath,
conf_thres=args.confThreshold,
iou_thres=args.nmsThreshold)
# 进行推理(包含了预处理)
prediction_out = v5_seg_detector.detect(image0)
#后处理解码
final_mask, final_det = v5_seg_detector.postprocess(prediction_out)
print("start plotting")
d_r = DRAW_RESULT(args.modelpath,
conf_thres=args.confThreshold,
iou_thres=args.nmsThreshold)
colors_obj = Colors(
) # create instance for 'from utils.plots import colors'
d_r.draw_mask(final_mask,
colors_=[colors_obj(x, True) for x in final_det[:, 5]],
im_src=image0)
d_r.draw_detections(image0, final_det[:, :4], final_det[:, 4],
final_det[:, 5])
cv2.namedWindow("masks_det", cv2.WINDOW_NORMAL)
#CV_WINDOW_NORMAL就是0
cv2.imshow("masks_det", image0)
cv2.waitKey(0)
cv2.destroyAllWindows()
注意:
1)
我对比了F.inerpolate函数以及cipy.ndimage.interpolation.zoom函数,发现两个函数无法完全对齐
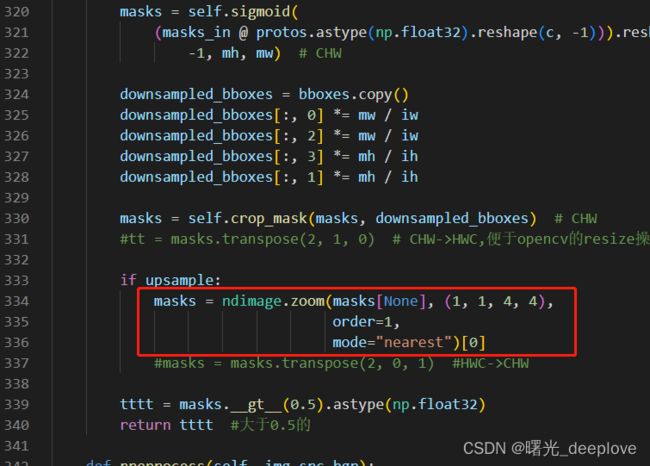
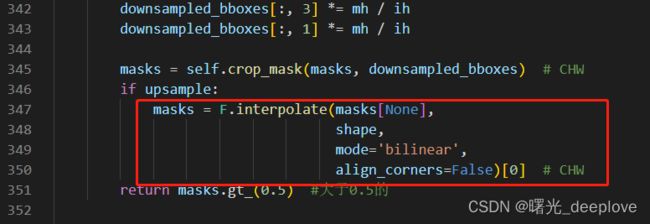
分别保存完masks,进行对比代码如下:
'''
Descripttion:
version:
@Company: WT-XM
Author: yang jinyi
Date: 2022-10-06 11:20:38
LastEditors: yang jinyi
LastEditTime: 2022-10-06 22:55:17
'''
# -*- coding:UTF-8 -*-
import os
import numpy as np
# def to_numpy(input_img):
# print(11111)
# np_input = input_img.cuda().data.cpu().numpy()
# return np_input
if __name__ == "__main__":
torch_file = "torch_array_masks.npy"
numpy_file = "numpy_array_masks.npy"
get_pytorch_result = np.load(torch_file)
get_numpy_result = np.load(numpy_file)
# mse = np.mean((get_onnx_result - get_pytorch_result) ** 2)
# print('MSE Error = {}'.format(mse))
np.testing.assert_almost_equal(get_pytorch_result,
get_numpy_result,
decimal=3) # 精确到小数点后5位,验证是否正确,不正确会自动打印信息
print(
"恭喜你 ^^ ,onnx 和 pytorch 结果一致 , "
"Exported model has been executed decimal=3 and the result looks good!"
)
print('All completed!')
结果如下:
Exception has occurred: AssertionError
Arrays are not almost equal to 3 decimals Mismatched elements: 1607 / 1228800 (0.131%) Max absolute difference: 1. Max relative difference: 1. x: array([[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.],... y: array([[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.],...
可以看出两种插值结果出来的masks依然存在0.131%的差异。
2)
我试了opencv的resize发现更加无法对齐
首先cv2的resize无法进行4d的array上采样。因为我只能使用3d的。其次:
masks.transpose(2, 1, 0) # CHW->HWC,便于opencv的resize操作(仅可用于hwc)
再其次插值上采样:
masks = cv2.resize(masks, shape, interpolation=cv2.INTER_NEAREST)
最后在从HWC->CHW:masks = masks.transpose(2, 0, 1) #HWC->CHW
3)展示一下效果图啊:

参考:
yolov7-opencv-onnxrun-cpp-py/main.py at main · hpc203/yolov7-opencv-onnxrun-cpp-py · GitHub