【Python数据分析及可视化】使用numpy和pandas分析数据及matplotlib实现可视化
numpy是数值计算的标准模块,提供高性能的矩阵运算。数组与列表不同,数组只能存储同一种类型的数据,而列表可以存储任何类型的数据。
pandas提供了读取与存储关系型数据库数据的函数与方法,Pandas主要做数据处理,提供了DataFrame的数据结构,契合统计分析的表结构,是基于numpy的拓展。
文章目录
一、numpy数值计算基础
1.创建数组,分别查看数组大小、类型、数组元素的数据类型
2. 生成数组
3.生成随机数
4.访问数组元素
5.矩阵拼接与运算
6.练习:读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行排序、去重,并求出和、累积和、均值、标准差、方差、最小值、最大值
二、pandas统计分析基础
1.一维Series
2.二维DataFrame
3.使用pandas进行数据预处理
三、matplotlib实现可视化
总结
一、numpy数值计算基础
使用前导入numpy包
import numpy as np1.创建数组,分别查看数组大小、类型、数组元素的数据类型
a = np.array([[1, 2, 3], [1, 2, 4]], dtype=np.float32)
print(a.size)
print(a.shape)
print(a.dtype)


2. 生成数组
没有给定数据类型,默认生成的数组为float64
a=np.zeros(2) #生成一维数组
print(a)
b=np.zeros((2, 3)) #生成二维数组
print(b)
3.生成随机数
a=np.random.random(size=(2, 3)) #随机生成两行三列数组
print(a)
b=np.random.randint(0, 10, size=(2, 3)) #在0-10范围内生成两行三列的数组
print(b)
4.访问数组元素
a = np.arange(10) #生成一个一维数组
print(a)
print(a[2]) #访问单个元素
print(a[2:]) #访问第二个到最后一个元素
print(a[:5]) #访问第0个到第四个,左闭右开
print(a[1:-1:2]) #访问第一个至最后一个,步长为2
5.矩阵拼接与运算
a = np.mat([[1, 2], [3, 4]]) #拼接矩阵
b = np.matrix([[11, 21], [31, 41]])
print(np.bmat('a b; b a'))
a = [[1, 2], [3, 4]]
b = [[1, 1], [1, 1]]
print(np.array(a) * np.array(b)) #矩阵对应位置相乘
print(np.array(a).dot(np.array(b))) #矩阵的乘法


6.练习:读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行排序、去重,并求出和、累积和、均值、标准差、方差、最小值、最大值
导入numpy模块并加载数据
import numpy as np
data = np.loadtxt('./data/iris_sepal_length.csv')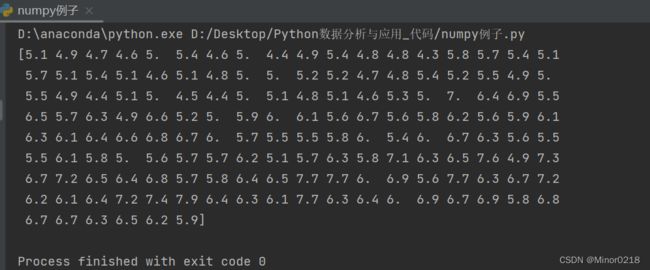
排序:
data.sort()
去重:
data = np.unique(data)
求和:
np.sum(data)

累加求和 :
np.cumsum(data)
求均值、标准差、方差、最小值、最大值:
print(np.mean(data))# 均值、
print(np.std(data))# 标准差、
print(np.var(data))# 方差、
print(np.min(data))# 最小值、
print(np.max(data))# 最大值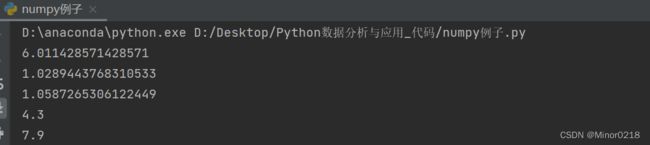
二、pandas统计分析基础
pandas数组结构有一维Series和二维DataFrame。
1.一维Series
Series是一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据标签组成。索引在左边,值在右边。
#定义一维数组
import pandas as pd
a=pd.Series([55,70,98,45,98,23],index=['苹果','香蕉','橘子','桃子','樱桃','火龙果'])
print(a)
2.二维DataFrame
DataFrame是一个表格型的数据结构,DataFrame是由多个Series数据列组成的表格数据类型。 既有行索引,又有列索引。
基本操作如下:
data = pd.read_csv('./data/detail.csv', encoding='gbk')
print(data.index) #索引,步长是1
print(data.values) #查看所有值,返回类型是字符串
print(data.columns) #查看列名称
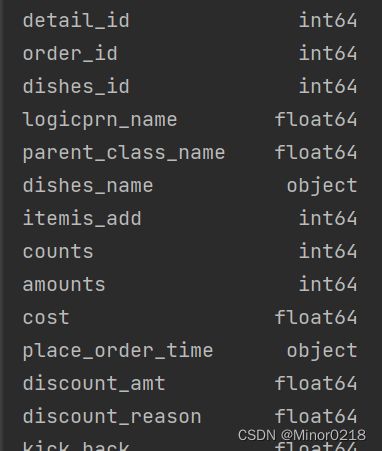
print(data.dtypes) #查看数据类型
print(data.size) #行列乘积
print(data.shape) #行列数目
print(data.ndim) #维度


![]()
![]()
![]()
访问某一列
print(data['dishes_name']) 
访问某一列某几行
print(data['dishes_name'][3:7]) #访问3-7行,左闭右开区间
行列索引
DataFrame.loc[行索引名称或条件, 列索引名称] #前后都是闭区间
DataFrame.iloc[行索引位置, 列索引位置] #前闭后开区间
print(data.iloc[2, 2])
print(data.loc[2, 'dishes_id'])
更新DataFrame中的数据
data['total_price'] = data['counts'] * data['amounts'] #增加总价
print(data.head(3)) #打印前三行
# data2.tail()
删除DataFrame中的数据
data1=data.drop(labels='total_price', axis=1) #删除总价这一列,axis等于1代表纵向删除
print(data1.tail(3)) #把最后三行打印出来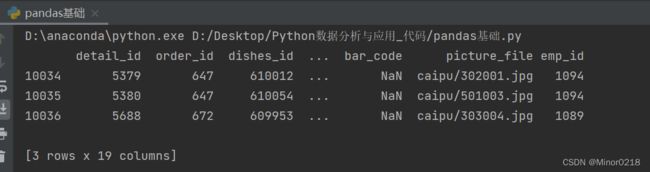
3.使用pandas进行数据预处理
数据标准化,是使数据落入同一范围,是一种常见的数据预处理操作。这种操作是为了把不同比例和维度的数据将其缩放到相同的数据间隔和范围,从而减少比例特征和分布差异对模型的影响。
本次使用的数据是商店的菜品详情订单
导入包,加载数据
import pandas as pd
data = pd.read_csv('./data/detail.csv', encoding='gbk')
print(data.head()) #打印前五行数据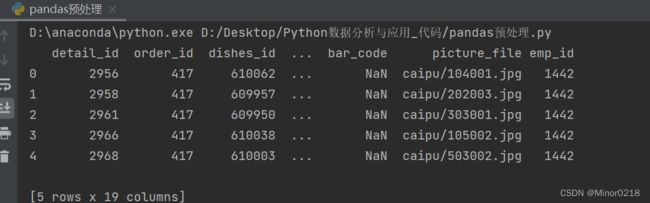
查看数量和单价
print(data[['counts', 'amounts']]) 
1.离差标准化
离差标准化是对原始数据的一种线性变换,结果是将原始数据的数值映射到[0,1]区间之间。
def MinMaxScale(data): #自定义标准化函数
return (data - data.min()) / (data.max()-data.min()) #公式
a = MinMaxScale(data['counts']) #对数量进行标准化
b = MinMaxScale(data['amounts']) #对单价进行标准化
print(pd.concat([a, b], axis=1)) #合并单价和数量
2.标准差标准化数据
也叫零均值标准化或分数标准化,是当前使用最广泛的数据标准化方法。经过该方法处理的数据均值为0,标准差为1。
def StandScale(data): #自定义标准差标准化函数
return (data - data.mean()) / data.std()
a = StandScale(data['counts']) #对数量进行标准化
b = StandScale(data['amounts']) #对单价进行标准化
print(pd.concat([a, b], axis=1)) #合并标准化后的单价和数量
3.小数定标标准化数据
通过移动数据的小数位数,将数据映射到区间[-1,1]之间,移动的小数位数取决于数据绝对值的最大值。
import numpy as np
def DecimalScale(data): #自定义小数定标准化函数
return data / 10**(np.ceil(np.log10(data.abs().max())))
a = DecimalScale(data['counts']) #对数量进行标准化
b = DecimalScale(data['amounts']) #对单价进行标准化
print(pd.concat([a, b], axis=1)) #合并标准化后的单价和数量
数据转换,数据分析模型中有相当一部分的算法模型都要求输入的特征为数值型,但实际数据中特征的类型不一定只有数值型,还会存在相当一部分的类别型,这部分的特征需要经过哑变量处理才可以放入模型之中,这时候就需要做一个数据类型转换。
print(pd.get_dummies(data['dishes_name'])) #哑变量处理
离散化连续型,某些模型算法,特别是某些分类算法如ID3决策树算法和Apriori算法等,要求数据是离散的,此时就需要将连续型特征(数值型)变换成离散型特征(类别型)。
1.等宽法
将数据的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定或者用户指定,与制作频率分布表类似。pandas提供了cut函数,可以进行连续型数据的等宽离散化。
print(pd.cut(data['amounts'], bins=5).value_counts()) #把单价分为五类
2.等频法
cut函数虽然不能够直接实现等频离散化,但是可以通过定义将相同数量的记录放进每个区间。
def samefreq(data, k): #k表示切分成多少份
w = data.quantile(np.arange(0, 1+1/k, 1/k))
return pd.cut(data, w)
print(samefreq(data['amounts'], k=5).value_counts()) 
三、matplotlib实现可视化
1.绘制散点图
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2*np.pi, 100) #x轴从0到2*pi,等间隔的取100个点
y = np.sin(x) + np.random.rand(100) #y轴随机数生成
plt.rcParams['font.sans-serif'] = 'SimHei' # 中文显示
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize=(9, 5)) #创建自定义图像,指定宽和高
plt.title('sin散点') #题目
plt.scatter(x, y) #散点图
plt.show()
2.绘制折线图
x = np.linspace(0, 2*np.pi, 100) # 线性空间,取值范围为0到2*pi,默认包含100个点
y = np.sin(x) + np.random.rand(100)
plt.rcParams['font.sans-serif'] = 'SimHei' # 中文显示
plt.figure(dpi=60) #分辨率显示
plt.plot(x, y) #折线图
plt.plot(x, np.sin(x))
plt.legend(['折线', 'sin曲线']) #绘制图形的图例
plt.show()
3.绘制箱图
x = range(10) #x轴生成10个数
#np.random.seed(123) #如果使用相同的seed ()值,则每次生成的随机数都相同
y1 = np.random.random(10) #产生10个随机的y值
y2 = np.random.random(10)
plt.bar(x, y1, facecolor='b') #绘制箱图,颜色
plt.bar(x, -y2, facecolor='g')
for i, j in zip(x, y1): #在每个箱图上面中间位置生成对应的值,保留三位小数
plt.text(i, j, '%.3f' % j, ha='center', va='bottom')
for i, j in zip(x, y2):
plt.text(i, -j, '%.3f' % j, ha='center', va='top')
plt.title('$\pi$') #题目
plt.show()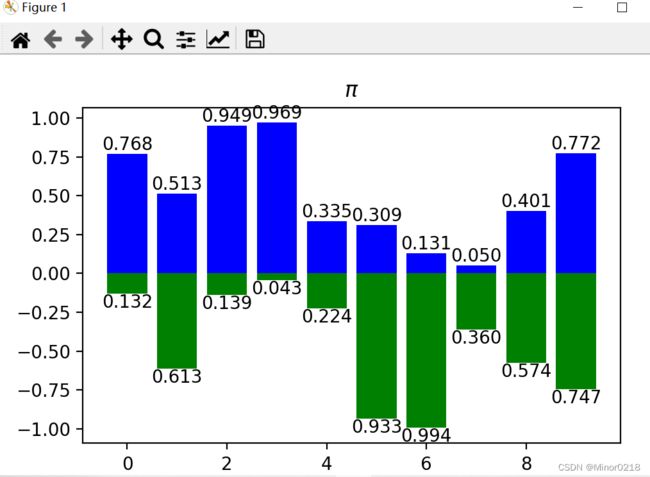
4.绘制饼图
z = np.ones(5) #饼图分为5份
plt.figure(figsize=(5, 5)) #创建自定义图像,指定宽和高
plt.pie(z, autopct='%.2f%%', explode=[0.2]+ [0]*4, labels=list('ABCDE'), labeldistance=1.1)
plt.show() #每一份的值保留两位小数;一份向外扩0.2,其余四份不留空;定义每一份名称及位置
总结
以上就是今天要讲的内容,本文仅仅简单介绍了numpy和pandas的一些基本操作以及matplotlib绘图基础知识,并且给出了简单的例子。总的来说,numpy支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。