怎样用python进行数据清洗?(下)
微信 wusheng9922 欢迎交流!
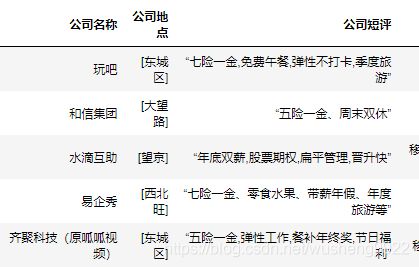
这里我们用某招聘网的案例来 过一遍用python进行数据清洗的流程。接(1)
10 去掉公司地点的中括号
定义一个函数 来去掉记录两端的符号 再传入 .map函数中去,再赋值给原来的公司地点。
def strip_gsdd(x):
return x.strip('[]')
df.公司地点.map(strip_gsdd)
df['公司地点']=df.公司地点.map(strip_gsdd)
11 把字段名工位要求改为公司要求
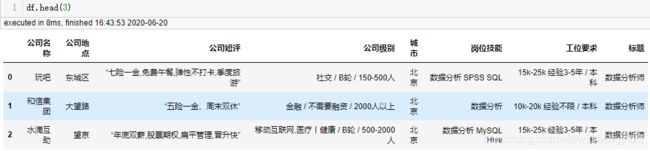
df.rename(columns={'工位要求':'公司要求'},inplace=True)

12 将公司要求这一列拆分成薪资, 经验要求,学历要求
①新增 薪资
定义一个函数,来提取 公司要求中的薪资这一列,为了在拆分提取到**k-**k,做了一些判断,其中有大写K和小写k的区分,避免出现一些奇奇怪怪的东西,如果有奇奇怪怪的东西 我们让他返回 nan。
def xinzi(x):
if ('k' in x) or ('K' in x):
return x.split()[0]
else:
return np.nan
继续用.map函数将字段中的每一个记录都传入到 定义的xinzi函数中 ,使得每一个记录都传入xinzi函数。增加新的 薪资 列,赋值。
df['薪资']=df.薪资.map(xinzi)
检查是否有异常值和缺失值
df.薪资.value_counts()
a=df[df.薪资.isnull()]
df.drop(index=a.index,inplace=True)
df.head(3)
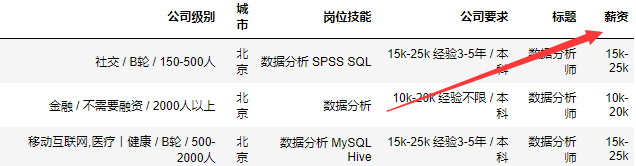
②新增 经验要求
定义一个函数,来提取 公司要求中的经验这一列
def jyyq(x):
return x.split()[1]
新增 经验要求列 并赋值
df['经验要求']=df.公司要求.map(jyyq)
检查异常值和缺失值

③新增 学历要求
预看一下 学历要求 在定义提取函数的时候,函数内是怎么拆分的。

定义一个函数来提取 其中的学历字段
def xlyq(x):
return x.split()[-1]
新增学历要求 并赋值
df['学历要求']= df.公司要求.map(xlyq)
检查并删除异常值

检查缺失值


13 将公司级别拆分成三列
将公司级别 这列拆成表


a=df.公司级别.str.split('/',expand=True)
a.columns = ['行业','阶段','规模']
df[a.columns]=a
df.head()

14 删除 公司要求 字段
del df['公司要求']
df.head()

删除列的方法有很多
这里 多说一点 常用三种:
①del df[要删除的列名]
会直接在原数据上修改
②df.pop(要删除的列名)
直接会在原表上删除该列, 并会以Series返回该列
③df.drop(columns=要删除的列名)
删除多列就给columns传入一个包含列名的列表
inplace=True就会改变原表
15 导出csv文件 完成数据的基本整理和清洗
df.to_csv('lagou20200620.csv',index=False)
index=False 是不要列的索引。