DER: Dynamically Expandable Representation for Class Incremental Learning翻译
DER: Dynamically Expandable Representation for Class Incremental Learning (CVPR, 2021)
DER:类增量学习的动态可扩展表示
目录
- 传送门
- Abstract
- 1. Introduction
- 2. Related Work
-
- Representation Learning
- Classifier Learning 分类器的学习
- Discussion
- 3. Methods
-
- 3.1. Problem Setup and Method Overview问题设置和方法概述
- 3.2. Expandable Representation Learning可扩展的代表学习
- 3.3. Dynamical Expansion
- 3.4. Classifier Learning
- 4. Experiments
-
- 4.1. Experiment Setup and Implementation Details 4.1. 实验设置和实现细节
- 4.2. Evaluation on CIFAR100 4.2. 评价CIFAR100
- 4.3. 评价ImageNet
- 4.4. Ablation Study and Analysis 4.4. 消融实验与分析
- 5. Conclusion
传送门
paper
code
Abstract
我们解决了类增量学习的问题,这是实现自适应视觉智能的核心步骤。特别地,我们考虑了有限记忆的增量学习任务设置,目的是实现更好的稳定性-可塑性平衡。为此,我们提出了一种新的两阶段学习方法,该方法利用一种动态可扩展的表示来实现更有效的增量概念建模。具体来说,在每一个增量步骤中,我们冻结之前学习的表示,并从一个新的可学习特征提取器中增加特征维度来扩充它。这使我们能够整合新的视觉概念和保留所学知识。我们通过引入信道级的基于掩码的剪枝策略,根据新概念的复杂性动态扩展表示。此外,我们引入了一个辅助损失来鼓励模型学习多样性和识别新概念的特征。我们在三个类增量学习基准上进行了大量的实验,我们的方法始终以较大的优势优于其他方法。
1. Introduction
人类可以很容易地从过去的经验中积累视觉知识,并逐渐学习新的概念。受此启发,类增量学习问题旨在设计能够循序渐进地学习新概念并最终在所有观察到的类上表现良好的算法。这种能力对于许多现实世界的应用是不可或缺的,如智能机器人[31],人脸识别[19]和自动驾驶[25]。然而,实现人类水平的增量学习仍然是现代视觉识别系统的挑战。
在文献[36,23,27,3,12,33,39]中有很多试图解决增量学习的努力。其中,可能最有效的策略是保留一个内存缓冲区,存储部分观察到的数据,以备将来的回放[28,29]。然而,由于数据存储量有限,这种增量学习方法在一般的持续学习任务中仍然面临着几个典型的挑战。特别是,它需要一个模型在不忘记已有知识的情况下有效地吸收新概念,这也被称为稳定性-可塑性困境[9]。具体而言,过度的可塑性往往会导致旧类别的性能大幅下降,称为灾难性遗忘[8]。相反,过度的稳定阻碍了新概念的适应。
现有的大多数研究都试图通过逐渐更新数据表示和类决策边界来实现稳定性和可塑性之间的平衡,以适应越来越大的标签空间。例如,正则化方法[4]惩罚了之前学习的模型的重要权值的变化,而知识精馏方法[27,3,12,6,34]保留了有可用数据的网络输出,基于结构的方法[26,1]在为新类别分配更多的参数时,保持了旧参数不变。然而,所有这些方法要么牺牲模型的可塑性以获得稳定性,要么由于旧概念的特征退化而容易遗忘。如图1所示,在所有数据上训练的模型(Joint)与以前最先进的模型之间仍然存在很大的性能差距。
在本研究中,我们的目标是解决上述缺点,并在类增量学习中实现更好的稳定性-可塑性权衡。为此,我们采用了两阶段学习策略,将深度网络[15]的特征表示自适应和最终分类器头(简称分类器)解耦。在这个框架内,我们提出了一种新的数据表示,称为超特征,能够增加其维数以适应新的类。我们的主要思想是冻结以前学习过的表示,并在每一个增量步骤中从一个新的可学习提取器中使用额外的特征维度来增加它。这使我们能够保留现有的知识,并提供足够的灵活性来学习新的概念。此外,我们的超特征是根据新概念的复杂性动态扩展的,以保持一个紧凑的表示。
为此,我们开发了一个由超特征提取器网络和线性分类器组成的模块化深度分类网络。我们的超特征提取器网络由多个大小不同的特征提取器组成,每个增量步骤对应一个特征提取器。具体来说,在一个新的阶段,我们用一个新的特征提取器扩展了超特征提取器网络,同时保持了之前提取器的参数不变。所有提取器生成的特征被连接在一起,并将其输入分类器进行分类预测。
我们对新的特征提取器和分类器进行记忆训练和新输入的数据训练。为了鼓励新的提取器学习新类的多样性和判别性特征,我们设计了一个用于区分新旧类的辅助损失。此外,为了去除模型冗余并学习新类的紧凑特征,我们采用了一种可微分的基于通道级掩码的剪枝方法,该方法根据新概念的难度动态剪枝网络。最后,给定更新后的表示,我们冻结超特征提取器,并在一个平衡的训练子集上对分类器进行细微调整,以解决类不平衡问题[33,39]。
我们在三个常用的基准测试上验证了我们的方法,包括CIFAR-100、ImageNet-100和ImageNet-1000数据集。实验结果和消融研究证明了我们的方法优于先前的先进方法。有趣的是,我们还发现我们的方法可以在步骤之间实现正向的向后和向前转移。
•为了实现更好的稳定性-可塑性权衡,我们开发了一个动态可扩展的表示和一个两阶段的课堂增量学习策略。
•我们提出了一个辅助损失来促进新增的特征模块有效地学习新类,以及一个模型修剪步骤来学习紧凑的特征。
•我们的方法在广泛的模型复杂性下,在所有三个基准上实现了最新的性能状态,如图1所示。

2. Related Work
类增量学习旨在不断学习新类。有些作品[36,23]试图在无法访问之前看到的数据的情况下解决这个问题。然而,目前常用的方法都是基于回放策略的,数据存储量有限,主要从Representation Learning(表示学习)和Classifier Learning(分类器学习)两方面进行分析。
Representation Learning
目前的作品主要可以分为以下三类。
基于正则化的方法[16,37,18,4,2]采用最大后验估计估计重要参数的微小变化,并依次更新模型参数的后验。然而,它的棘手的计算通常需要一个强大的模型假设近似。例如,EWC[16]使用拉普拉斯近似,它假设权值落在上一步最优权值的局部区域。这严重限制了模型适应新概念的能力。
基于蒸馏的方法[27,39,33,12,3,6,34]使用知识蒸馏[11]来保持表示。iCaRL[27]和EE2L[3]计算网络输出的蒸馏损失。UCIR[12]使用归一化特征向量来应用蒸馏损失而不是网络的预测。PODNet[6]采用基于空间的蒸馏损失来限制模型的变化。tcil[34]使模型保持CNN特征空间的拓扑结构。知识蒸馏的性能取决于所保存数据的质量和数量。
基于结构的方法[21,13,30,20,22,7,35,26,1,20]将学习到的与之前的类相关的参数保持不变,并以不同的形式分配新的参数,如未使用的参数、额外的网络等,以学习新的知识。CPG[13]提出了一种压缩和选择/扩展机制,该机制对深层模型进行修剪,并通过选择性权重共享来扩展体系结构。然而,大多数基于结构的方法[21,13,30,20,22,7,35]是针对任务持续学习而设计的,在推理过程中需要任务同一性。
对于类增量学习,RPSNet[26]提出了一种随机路径选择算法,该算法逐步为新类选择最优路径作为子网络。CCGN[1]为每个卷积层配备了特定于任务的门控模块,以选择要应用于给定输入的过滤器,并使用任务预测器在推理中选择门控模块。
Classifier Learning 分类器的学习
由于分类器的内存有限,类的不平衡问题是分类器学习的主要挑战。有些作品像LWF。MC[27], RWalk[4]在一次训练中联合训练提取器和分类器。相比之下,近年来通过引入表征学习后的独立分类器学习阶段来解决分类不平衡问题的研究较多。EEIL[3]在一个平衡的训练子集上微调分类器。BiC[33]增加了一个偏差校正层来校正模型的输出,该层在一个单独的验证集上接受训练。WA[39]通过将新类的权重向量规范与旧类的权重向量规范对齐来纠正有偏差的权重。
Discussion
我们的工作是基于结构的方法,与我们最相似的工作是RPSNet和CCGN。RPSNet不能保留每一个旧概念的内在结构,在每个ConvNet阶段,RPSNet倾向于通过对之前学习到的特征和新学习到的特征进行相加,逐渐忘记所学到的概念。在CCGN中,由于只有部分层的参数被冻结,学习后的表示可能会在步骤中缓慢退化。相比之下,我们保持之前学习的表示不变,并使用新的特征提取器参数化的新特征来扩充它。这使得我们能够在之前学习的表示的子空间中保留旧概念的内在结构,并通过最终的分类器重用该结构以减少遗忘。
3. Methods
在本节中,我们将介绍我们解决类增量学习问题的方法,目的是在稳定性和可塑性之间取得更好的权衡。为此,我们提出了一种动态可扩展表示方法(DER),该方法可以用新特征增量地增强先前学习的表示,并提出了一种两阶段学习策略。
下面我们首先介绍类增量学习的公式,并在3.1节概述我们的方法。然后我们在第3.2节中介绍可扩展表示学习及其损失函数。在此之后,我们在第3.3节描述了我们表示的动态扩展,在第3.4节描述了分类器学习的第二阶段。
3.1. Problem Setup and Method Overview问题设置和方法概述
首先,我们介绍了类增量学习的问题设置。与任务增量学习相比,类增量学习在推理过程中不需要任务id。具体来说,在类增量学习过程中,模型观察了一组类组{Yt}及其对应的训练数据{Dt}。特别地,在步长t处输入的数据集Dt具有(xti, yti)的形式,其中xti是输入图像,yti∈Yt是标签集Yt中的标签。模型的标签空间都是categories ~ Yt =∪ti=1Yi,预计模型在Yt中的所有类上都能很好地预测。
我们的方法采用了回放策略,将部分数据保存为记忆Mt,用于以后的训练。对于步骤t的学习,我们将学习过程分解为以下两个顺序阶段。
1)表征学习阶段。为了在稳定性和可塑性之间取得更好的平衡,我们修正了之前的特征表示,并使用一个新的特征提取器对传入和记忆数据进行训练来扩展它。我们在新的提取器上设计了一个辅助损耗,以促进它学习多样的和有区别的特征。为了提高模型的效率,我们通过引入一种通道级掩码剪枝方法,根据新类的复杂性动态扩展表示。我们提议的表示的概述如图2所示。
2)分类器学习阶段。在学习表示之后,我们在步长t处用当前可用的数据重新训练分类器,通过采用[3]中的平衡微调方法来处理类的不平衡问题。

3.2. Expandable Representation Learning可扩展的代表学习
我们首先介绍我们的可展开表示。在步骤t,我们的模型由一个超特征提取器Φt和分类器Ht组成。超级特征提取器Φt是通过新创建的特征提取器Ft扩展特征提取器Φt−1构建的。具体来说,给定图像x∈~Dt,通过Φt提取的特征u 通过如下拼接得到

在这里,我们重用了以前的F1…Ft - 1,并鼓励新的提取器Ft只学习新类的新方面。然后将特征u输入分类器Ht,进行如下预测

然后预测ˆy = arg max pHt (y|x),ˆy∈Yt。设计分类器匹配步骤t的新输入输出维数,旧特征的Ht参数从Ht−1中继承,保留旧知识,并随机初始化新添加的参数。
为了减少灾难性的遗忘,我们在第t步冻结学习到的functionΦt−1,因为它捕获了之前数据的内在结构。其中,上一步超特性extractorθΦt−1参数和批处理归一化统计信息[14]未更新。
此外,我们以Ft−1为初始化实例化Ft,以便重用之前的知识进行快速适应和向前传输。
我们可以根据之前的数据D1:t−1,从估计先验分布p(θΦt |D1:t−1)的角度来解释这个问题。与以往的正则化方法(如EWC)不同,我们不假设t步的先验分布是单峰的,这限制了模型的灵活性,在实践中通常不是这样。对于我们的方法,通过为输入数据创建单独的特征提取器Ft,模型扩展了新的参数,并采用均匀分布作为先验分布p(θFt |D1:t−1),这为模型适应新概念提供了足够的灵活性。同时,为简便起见,我们将旧参数θΦt−1上的先验分布p(θΦt−1 |D1:t−1)近似为狄拉克分布,该分布保留了从D1:t−1上获得的信息。通过积分p(θΦt−1 |D1:t−1)和p(θFt |D1:t−1)的两个先验分布假设,我们在实现更好的稳定性和塑性权衡方面具有更大的灵活性。
Training Loss
我们学习在记忆和输入数据上有交叉熵损失的模型如下

其中xi是image, yi是对应的标签。
为了加强网络对新概念的多样性和判别性特征的学习,我们进一步发展了一个作用于新特征Ft(x)的辅助损失。具体地说,我们引入了一个辅助分类器Hat,它预测了概率pHat (y|x) = Softmax(Hat (Ft(x))。为了鼓励网络学习特征来区分新旧概念,Hat的标签空间为|Yt|+1,将所有旧概念视为一个类别,其中包含新类别集Yt和其他类别。因此,我们引入辅助损耗,得到可扩展表示损耗如下
![]()
其中,λa是控制辅助分类器效果的超参数。值得注意的是,第一步t = 1时,λa=0。
3.3. Dynamical Expansion
为了消除模型冗余并保持模型的紧凑表示,我们根据新概念的复杂性对超特征进行了动态扩展。具体来说,我们采用了一种可微分的基于通道级掩模的方法来对提取器Ft进行剪枝滤波,其中掩模与表示联合学习。学习掩码后,对掩码进行二值化处理,并对特征提取器Ft进行剪枝,得到剪枝后的网络F Pt。
Channel-level Masks通道级掩码
我们的剪枝方法是基于可微通道级掩码的,它改编自HAT[30]。小说特征提取器英尺,卷积的输入特性映射层给定图像x l表示fl。我们引入通道面具毫升∈Rcl控制层的尺寸l, mil∈[0,1]和cl是渠道的数量层l . fl与面具调制如下
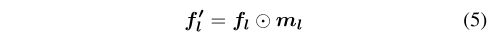
f l是掩码特征图, O意味着通道级乘法。为了使ml值进入区间[0,1],采用如下的选通函数
![]()
其中el表示可学习掩模参数,选通函数σ(·)在本工作中使用了s型函数,s是控制函数锐度的缩放因子。有了这样的掩码机制,步长t的超特征~ u可以重写为
![]()
训练时,φt(x)为带软口罩的Ft(x)。为了进行推理,我们赋予s一个大的值对掩码进行二值化,得到修剪网络F Pt,并且φt(x) = F Pt (x)
Mask Learning
在epoch中,对s应用线性退火程序如下
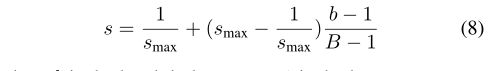
其中b是批量索引,smax?1是控制进度的超参数,B是一个epoch的批次数。训练时代以统一的方式激活所有的通道开始。然后在一个epoch内,随着批量索引的增加,逐步对掩模进行二值化。s型函数的一个问题是,由于s型调度,梯度是不稳定的。为了消除s的影响,我们对el的梯度凝胶进行补偿如下

其中g0el为补偿梯度。
Sparsity Loss稀疏的损失
在每一步中,我们鼓励模型以最小的性能下降最大限度地减少参数的数量。基于此,我们根据使用权重在所有可用权重中的比例添加了稀疏性损失。

式中,L为层数,Kl为卷积层L的核大小,L =0为输入图像,km0k1=3。
加入稀疏损耗后,最终损耗函数为
![]()
其中λs是控制模型尺寸的超参数。
3.4. Classifier Learning
在表征学习阶段,我们重新训练分类器头,以减少不平衡训练引入的分类器权值的偏差。具体来说,我们首先用随机权重重新初始化分类器,然后从当前可用的数据~ Dt采样一个类平衡的子集。在Softmax[38]中,我们只使用带有温度δ的交叉熵损失来训练分类器头。温度控制Softmax功能的平滑度,以改善类间的间隙。
4. Experiments
在本节中,我们进行了大量的实验来验证我们算法的有效性。特别是,我们在CIFAR-100[27]、ImageNet-100[27]和ImageNet-1000[27]数据集上使用两个广泛使用的基准协议评估我们的方法。我们还进行了一系列消融研究,以评估每个部件的重要性,并为我们的方法提供了更多的见解。下面我们首先在第4.1节中介绍实验设置和实现细节,然后在第4.2节中介绍在CIFAR100数据集上的实验结果。然后,我们在第4.3节给出了在ImageNet-100和ImageNet-1000数据集上的评估结果。最后,我们在4.4节介绍了我们方法的消融研究和分析。
4.1. Experiment Setup and Implementation Details 4.1. 实验设置和实现细节
Datasets CIFAR-100[17]由100个类的32x32像素彩色图像组成。它包含50,000张图像用于训练,每类500张图像,以及10,000张图像用于评估,每类100张图像。ImageNet-1000[5]是一个来自1000个类的大型数据集,包括约120万张用于训练的RGB图像和5万张用于验证的图像。ImageNet-100[27,12]是通过从ImageNet-1000数据集中选择100个类来构建的。
Benchmark Protocols 对于CIFAR-100基准,我们在两种流行的协议上测试我们的方法,包括1)CIF AR100-B0:我们遵循[27]中提出的协议,它在多个分割中训练所有100个类,包括5、10、20、50个增量步骤,每批2000个范例的固定内存大小;2)CIF AR100-B50:我们遵循[12]中引入的协议,从一个在50个类上训练的模型开始,剩下的50个类分为2、5、10个步骤,每个类20个示例作为内存。我们比较前1个平均增量精度,它取每一步精度的平均值。
我们还使用两个协议在ImageNet-100上评估我们的方法:1)ImageNet100-B0:协议[27]以10个类的批次从头开始训练模型,每批固定的内存大小为2000;2)ImageNet100B50:协议[12]从一个在50个类上训练的模型开始,剩下的50个类分为10个步骤,每个类有20个示例作为内存。为了公平起见,我们使用相同的ImageNet子集和类顺序遵循协议[27,12]。对于ImageNet-1000,我们在协议[27]上评估我们的方法,称为ImageNet1000-B0基准,该基准以100个类为批次,总共10个步骤训练模型,并将固定内存大小设置为20,000。详细地说,我们使用与ImageNet-1000的[27]相同的类顺序。此外,我们在ImageNet-100和ImageNet-1000数据集上比较了top-1和top-5的平均增量精度和最后一步精度。
Implementation Details 实现细节
我们的方法是用PyTorch[24]实现的。对于CIFAR-100,我们在RPSNet[26]之后采用ResNet-18作为特征提取器Ft。我们注意到,大多数以前的工作使用一个修改的32层ResNet[27],与标准ResNet-32相比,它有更少的通道和剩余块。我们认为这样一个小的网络是不适合的,因为它不能在CIFAR100上取得与标准的18层ResNet[10]相比的竞争结果,并且可能低估了方法的性能。我们根据这些方法的代码实现,在相同的类顺序上使用标准ResNet-18运行这些方法。对于那些没有发布代码的人,我们会根据我们的实现报告结果。对于RPSNet,我们直接在他们的论文中使用了结果。对于ImageNet-100和ImageNet-1000基准测试,我们使用18层ResNet作为基本网络
在这些实验中,我们遵循前面的工作[27],根据羊群选择策略[32]选择样本作为记忆。此外,我们在三个不同的班序上进行实验,报告结果的平均±标准偏差。在附录中我们也提供了基于改进的32层ResNet[27]的ciremote -100的实验结果,再次证明了我们的方法的优越性。我们遵循[6,30]中的协议,并在通过拿出一部分原始训练数据创建的验证集上调优超参数。超参数的详细信息被添加到附录中。
4.2. Evaluation on CIFAR100 4.2. 评价CIFAR100
Quantitative Results 定量结果
表1总结了CIFAR100-B0基准测试的结果。我们可以看到,在不同的增量分割中,我们的方法始终优于其他方法。随着分割步骤数量的增加,可以观察到我们的方法和其他方法之间的边界不断增加,这表明我们的方法在困难的分割和更长的步骤上表现得更好。特别是在50步增量设置下,在参数较少的情况下,平均增量精度从64.32%提高到72.05%(+7.73%)。值得注意的是,虽然减少了大量的模型参数,但由于剪枝导致的性能下降可以忽略不计,这证明了我们的剪枝方法是成功的

表1:CIFAR100-B0基准测试的结果,这是三次运行的平均值。#Paras表示在步骤推断期间使用的平均参数数量,以百万计。平均值是指在步骤上的平均准确率(%)。我们的(w/o P)是指我们的方法不需要修剪。
如图3的左面板所示,可以观察到我们的方法在不同的拆分步骤中始终优于其他方法。而且,随着新类的不断加入,我们的方法与其他方法的差距越来越大。在50步增量分割的情况下,最后一步的精度从42.75%提高到58.66%(+15.91%),进一步证明了该方法的有效性。
我们还在CIFAR100-B50基准上将我们的方法与表2中以前的方法进行了性能比较,表2显示我们的方法在所有拆分方面都显著提高了性能。特别是在10步增量设置下,我们的方法比PODNet的平均增量精度高出8.41%。如图3的右边面板所示,对于所有拆分,我们的方法在每个步骤上都比其他方法表现得更好。特别是,我们的方法在10步分割中,最后一步的准确率从52.56%提高到65.58%(+13.02%)。此外,与不进行剪枝的方法相比,我们的方法以更少的参数达到了相似的性能。

表2:CIFAR100-B50测试结果(平均超过3次)。#Paras表示在步骤推断期间使用的平均参数数量,以百万计。平均值是指在步骤上的平均准确率(%)。我们的(w/o P)是指我们的方法不需要修剪。
值得注意的是,以前的方法通常只在其中一种协议上表现良好,其中W A是CIFAR100-B0上最先进的协议,而PODNet是CIFAR100-B50上最先进的协议。相比之下,我们的方法在两个协议中始终优于其他方法。
The effects of model size 模型大小的影响
我们进行了大量的实验来研究模型大小对性能的影响。
如图1所示,我们可以看到我们的方法在不同的模型规模下比其他方法持续且显著地表现得更好。我们还注意到,与大多数其他方法相比,我们的方法的改进随着模型大小的增加变得更加显著,这说明我们的方法可以利用大型模型的潜力。
4.3. 评价ImageNet
表3总结了ImageNet-100和ImageNet-1000数据集的实验结果。我们可以看到,在ImageNet-100和ImageNet-1000数据集上,我们的方法始终超过了其他方法,尤其是最后一步的准确性。具体来说,我们的方法在ImageNet100-B0基准上的平均前5位精度上优于最先进的方法,约为1.79%。对于ImageNet100B50基准,最后一步top-1精度从66.91%提高到72.06%(+5.15%)。此外,在ImageNet1000-B0基准测试中,我们的方法将最后一步top-1的准确率从55.6%提高到58.62%(+3.02%)
虽然前5名的准确性差距较小,但我们认为这是因为前5名的准确性对稍微不准确的预测更宽容,因此对遗忘不那么敏感。

表3:ImageNet-100和ImageNet-1000数据集上的结果。左:ImageNet100-B0和ImageNet1000-B0基准测试的结果。右:ImageNet100-B50基准测试的结果。#Paras表示在步骤推断期间的平均参数数,以百万计。平均值是指在步骤上的平均准确率(%)。最后是最后一步的准确率(%)。我们的(w/o P)是指我们的方法不需要修剪。
4.4. Ablation Study and Analysis 4.4. 消融实验与分析
我们进行穷举消融研究来评估每个成分对我们方法的贡献。我们还对附录中的超参数进行了敏感研究。此外,我们还研究了每种方法表示的向后传递和向前传递。
The effect of each component 每个成分的影响
表4总结了我们在CIFAR100-B0上的10步烧蚀实验结果。我们可以看到,通过表示扩展,平均准确率从61.84%显著提高到73.26%。我们还表明,该模型的性能进一步提高了2.10%的增益使用辅助损失。

表4:每个组件的贡献。E.R.意味着可扩展的代表。Aux。意味着使用辅助损耗
Backward Transfer for Representation 表示的向后转移
为了评估表示的质量,我们引入了一个理想的决策边界,该边界是通过使用所有观测数据微调分类器得到的,这使我们能够排除分类器的影响。然后,我们将步长t时的分类精度AtYk定义为对类集Yk的测试图像的精度,其中模型的预测空间限制在Yk。通过观察t上的AtYk曲线,我们可以看到表示质量是如何随着增量而变化的。图4显示了10个增量步骤的CIFAR100-B0的结果。我们还计算了不同方法的向后转移值,如下:


图4:分析。通过观察不同分裂时AtY1的变化来逆向转移表征。
结果如表5所示。我们可以看到,其他的方法有严重的遗忘。相比之下,我们的方法甚至实现了正向的向后转移+1.36%,准确率相对于步长有了提高,进一步证明了我们的方法的优越性。

表5:表示的向后传输和向前传输(FWT)。
Forward Transfer for Representation 代表转让权
我们还通过10个增量步骤(称为forward transfer)来衡量现有知识对CIFAR100-B0上后续概念性能的影响。具体地说,我们定义一个正向传动比表示如下

其中¯AiYi是由在可用数据上训练的模型获得的测试准确性。˜Dt只有在随机初始化时的交叉熵损失。如表5所示,我们观察到大多数方法存在负正向迁移,这表明它们牺牲了适应新概念的灵活性。相比之下,我们的方法实现了+1.49%的FWT,这意味着我们的方法不仅使模型具有高度的灵活性,而且带来正向转移。
5. Conclusion
在这项工作中,我们提出了动态可扩展表示来改进班级增量学习的表示。在每一步,我们冻结之前学习的表示,并用新的参数化特征来扩充它。我们还根据新概念的难易程度引入信道级掩码剪枝来动态扩展表示,并引入辅助损失来更好地学习新识别特征。我们对三个主要的增量分类基准进行了详尽的实验。实验结果表明,我们的方法比其他方法在相当大的范围内始终保持更好的性能。有趣的是,我们还发现我们的方法甚至可以实现正向的向后和向前转移。
References
[1] Davide Abati, Jakub Tomczak, Tijmen Blankevoort, Simone
Calderara, Rita Cucchiara, and Babak Ehteshami Bejnordi.
Conditional channel gated networks for task-aware contin-
ual learning. In Proceedings of the IEEE conference on com-
puter vision and pattern recognition (CVPR), 2020. 2, 3
[2] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny,
Marcus Rohrbach, and Tinne Tuytelaars. Memory aware
synapses: Learning what (not) to forget. In Proceedings
of the European Conference on Computer Vision (ECCV),
2018. 2
[3] Francisco M. Castro, Manuel J. Mar´ın-Jiménez, Nicolás
Guil, Cordelia Schmid, and Karteek Alahari. End-to-end in-
cremental learning. In Proceedings of the European Confer-
ence on Computer Vision (ECCV), 2018. 1, 2, 3
[4] Arslan Chaudhry, Puneet K Dokania, Thalaiyasingam Ajan-
than, and Philip HS Torr. Riemannian walk for incremen-
tal learning: Understanding forgetting and intransigence. In
Proceedings of the European Conference on Computer Vi-
sion (ECCV), 2018. 2, 3
[5] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,
and Li Fei-Fei. Imagenet: A large-scale hierarchical image
database. In Proceedings of the IEEE conference on com-
puter vision and pattern recognition (CVPR), 2009. 5
[6] Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas
Robert, and Eduardo V alle. Podnet: Pooled outputs distil-
lation for small-tasks incremental learning. In Proceedings
of the European Conference on Computer Vision (ECCV),
2020. 1, 2, 6, 7, 12
[7] Chrisantha Fernando, Dylan Banarse, Charles Blundell, Y ori
Zwols, David Ha, Andrei A Rusu, Alexander Pritzel, and
Daan Wierstra. Pathnet: Evolution channels gradient descent
in super neural networks. arXiv preprint arXiv:1701.08734,
2017. 2
[8] Robert M. French and Nick Chater. Using noise to compute
error surfaces in connectionist networks: A novel means of
reducing catastrophic forgetting. Neural Comput., 2002. 1
[9] Stephen Grossberg. Adaptive resonance theory: How a brain
learns to consciously attend, learn, and recognize a changing
world. Neural Networks, 2013. 1
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In Proceed-
ings of the IEEE conference on computer vision and pattern
recognition (CVPR), 2016. 6
[11] Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling
the knowledge in a neural network. In Advances in Neural
Information Processing Systems (NeurIPS) Workshop, 2015.
2
[12] Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and
Dahua Lin. Learning a unified classifier incrementally via
rebalancing. In Proceedings of the IEEE conference on com-
puter vision and pattern recognition (CVPR), 2019. 1, 2, 5,
6, 7, 12
[13] Steven C. Y . Hung, Cheng-Hao Tu, Cheng-En Wu, Chien-
Hung Chen, Yi-Ming Chan, and Chu-Song Chen. Compact-
ing, picking and growing for unforgetting continual learn-
ing. In Advances in Neural Information Processing Systems
(NeurIPS), 2019. 2
[14] Sergey Ioffe and Christian Szegedy. Batch normalization:
Accelerating deep network training by reducing internal co-
variate shift. In International Conference on Machine Learn-
ing (ICML), 2015. 3
[15] Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan,
Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decou-
pling representation and classifier for long-tailed recogni-
tion. In International Conference on Learning Representa-
tions (ICLR), 2020. 2
[16] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel
V eness, Guillaume Desjardins, Andrei A Rusu, Kieran
Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-
Barwinska, et al. Overcoming catastrophic forgetting in neu-
ral networks. Proceedings of the national academy of sci-
ences (PNAS), 2017. 2
[17] Alex Krizhevsky and Geoffrey Hinton. Learning multiple
layers of features from tiny images. Technical report, Uni-
versity of Toronto, 2009. 5
[18] Sang-Woo Lee, Jin-Hwa Kim, Jaehyun Jun, Jung-Woo Ha,
and Byoung-Tak Zhang. Overcoming catastrophic forgetting
by incremental moment matching. In Advances in neural
information processing systems (NeurIPS), 2017. 2
[19] Lufan Li, Zhang Jun, Jiawei Fei, and Shuohao Li. An in-
cremental face recognition system based on deep learning.
In International Conference on Machine Vision Applications
(MVA), 2017. 1
[20] Xilai Li, Yingbo Zhou, Tianfu Wu, Richard Socher, and
Caiming Xiong. Learn to grow: A continual structure learn-
ing framework for overcoming catastrophic forgetting. In In-
ternational Conference on Machine Learning(ICML), 2019.
2
[21] Arun Mallya, Dillon Davis, and Svetlana Lazebnik. Piggy-
back: Adapting a single network to multiple tasks by learn-
ing to mask weights. In Proceedings of the European Con-
ference on Computer Vision (ECCV), 2018. 2
[22] Arun Mallya and Svetlana Lazebnik. Packnet: Adding multi-
ple tasks to a single network by iterative pruning. In Proceed-
ings of the IEEE conference on computer vision and pattern
recognition (CVPR), 2018. 2
[23] Oleksiy Ostapenko, Mihai Puscas, Tassilo Klein, Patrick Jah-
nichen, and Moin Nabi. Learning to remember: A synaptic
plasticity driven framework for continual learning. In Pro-
ceedings of the IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), 2019. 1, 2
[24] Adam Paszke, Sam Gross, Soumith Chintala, Gregory
Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Al-
ban Desmaison, Luca Antiga, and Adam Lerer. Automatic
differentiation in pytorch. 2017. 6
[25] John M Pierre. Incremental lifelong deep learning for au-
tonomous vehicles. In International Conference on Intelli-
gent Transportation Systems (ITSC), 2018. 1
[26] Jathushan Rajasegaran, Munawar Hayat, Salman H Khan,
Fahad Shahbaz Khan, and Ling Shao. Random path selection
for continual learning. In Advances in Neural Information
Processing Systems (NeurIPS), 2019. 1, 2, 6, 7
[27] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg
Sperl, and Christoph H Lampert. icarl: Incremental classifier
and representation learning. In Proceedings of the IEEE con-
ference on computer vision and pattern recognition (CVPR),
2017. 1, 2, 3, 5, 6, 7, 11, 12
[28] Anthony V . Robins. Catastrophic forgetting in neural net-
works: the role of rehearsal mechanisms. In International
Two-Stream Conference on Artificial Neural Networks and
Expert Systems, ANNES, 1993. 1
[29] Anthony V . Robins. Catastrophic forgetting, rehearsal and
pseudorehearsal. Connect. Sci., 1995. 1
[30] Joan Serra, Didac Suris, Marius Miron, and Alexandros
Karatzoglou. Overcoming catastrophic forgetting with hard
attention to the task. In International Conference on Machine
Learning (ICML), 2018. 2, 4, 6
[31] Sebastian Thrun and Tom M Mitchell. Lifelong robot learn-
ing. Robotics and autonomous systems, 1995. 1
[32] Max Welling. Herding dynamical weights to learn. In In-
ternational Conference on Machine Learning (ICML), 2009.
6
[33] Y ue Wu, Yinpeng Chen, Lijuan Wang, Y uancheng Ye,
Zicheng Liu, Yandong Guo, and Y un Fu. Large scale in-
cremental learning. In Proceedings of the IEEE conference
on computer vision and pattern recognition (CVPR), 2019.
1, 2, 3
[34] Tao Xiaoyu, Chang Xinyuan, Hong Xiaopeng, Wei Xing,
and Gong Yihong. Topology-preserving class-incremental
learning. In Proceedings of the European Conference on
Computer Vision (ECCV), 2020. 2, 7, 12
[35] Jaehong Y oon, Eunho Yang, Jeongtae Lee, and Sung Ju
Hwang. Lifelong learning with dynamically expandable net-
works. In International Conference on Learning Represen-
tations (ICLR), 2018. 2
[36] Lu Y u, Bartlomiej Twardowski, Xialei Liu, Luis Herranz,
Kai Wang, Y ongmei Cheng, Shangling Jui, and Joost van de
Weijer. Semantic drift compensation for class-incremental
learning. In Proceedings of the IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), 2020. 1, 2
[37] Friedemann Zenke, Ben Poole, and Surya Ganguli. Contin-
ual learning through synaptic intelligence. In International
Conference on Machine Learning (ICML), 2017. 2
[38] Xu Zhang, Felix Xinnan Y u, Svebor Karaman, Wei Zhang,
and Shih-Fu Chang. Heated-up softmax embedding. arXiv
preprint arXiv:1809.04157, 2018. 5
[39] Bowen Zhao, Xi Xiao, Guojun Gan, Bin Zhang, and Shu-
Tao Xia. Maintaining discrimination and fairness in class
incremental learning. In Proceedings of the IEEE conference
on computer vision and pattern recognition (CVPR), 2020. 1,
2, 3, 6, 7, 12