5.2 数据合并和重塑
5.2.1 merge合并
merge函数是通过一个或多个键将两个DataFrame按行合并起来,其方式与关系型数据库一样。merge默认为内连接inner,也就是返回交集。通过how参数可以选择连接方法:左连接left、右连接right和外连接outer。- 多对多的连接会产生笛卡尔积。
- 当然,也可以通过多个键进行合并,即传入一个
list即可。
- 在合并时要考虑到重复列名的问题。虽然可以人为进行重复列名的修改,但
merge函数提供了suffixes用于处理该问题。
- 可通过传入
left_index=True或者right_index=True指定将索引作为连接键来使用。
DataFrame中有一个join方法,可以快速完成按索引合并。- 总结
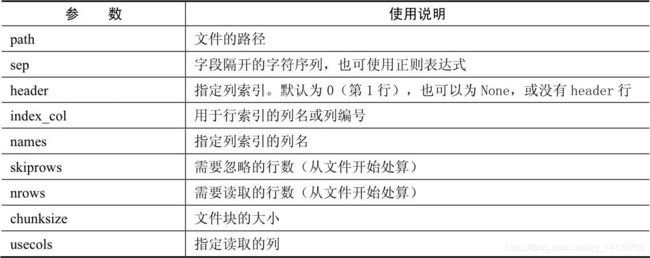
merge使用的常用参数
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
price = DataFrame({
'fruit':['apple','banana','orange'],
'price':[23,32,45]
})
amount = DataFrame({
'fruit':['apple','banana','apple','apple','banana','pear'],
'amount':[5,3,6,3,5,7]
})
price

amount
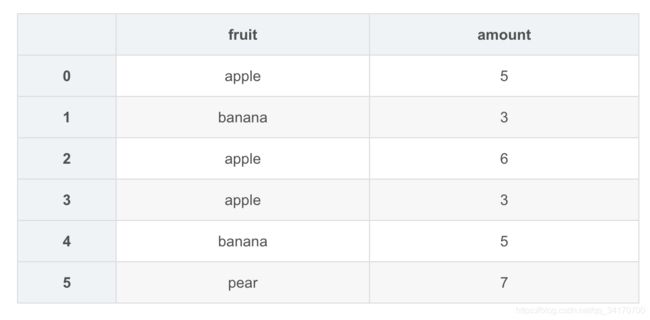
pd.merge(amount,price)
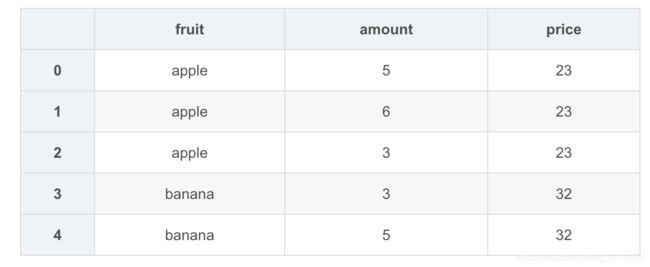
pd.merge(amount,price,on='fruit')
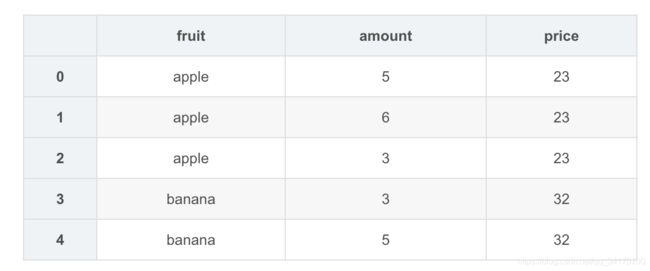
pd.merge(amount,price,left_on='fruit',right_on='fruit')
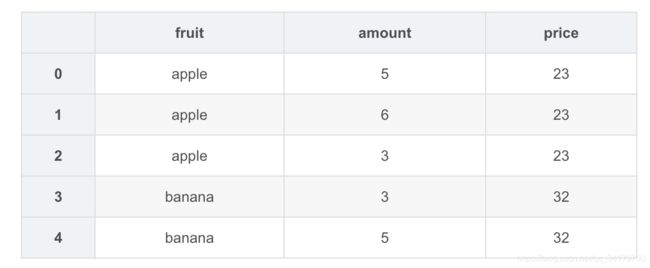
pd.merge(amount,price,how='left')
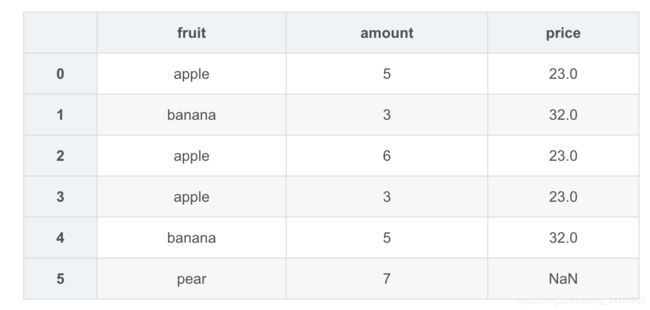
pd.merge(amount,price,how="right")

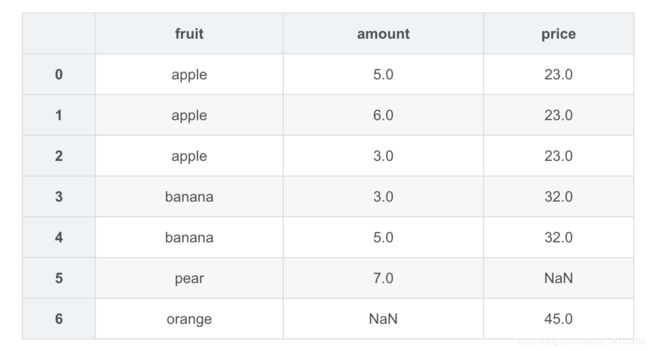
pd.merge(amount,price,how="outer")
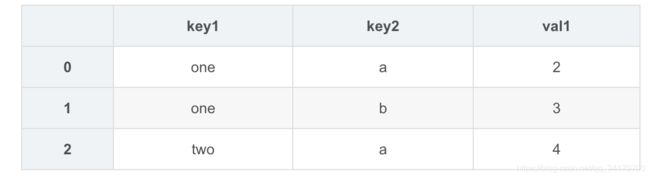
left = DataFrame({
'key1':['one','one','two'],
'key2':['a','b','a'],
'val1':[2,3,4]
})
left
right = DataFrame({
'key1':['one','one','two','two'],
'key2':['a','a','a','b'],
'val2':[5,6,7,8]
})
right
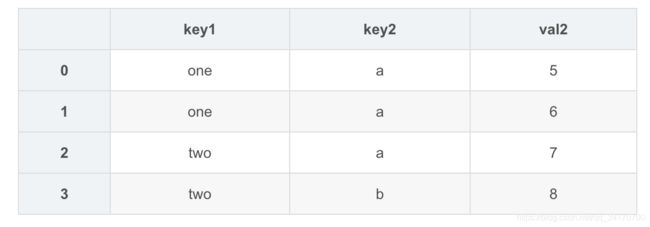
pd.merge(left,right,on=['key1','key2'],how='outer')
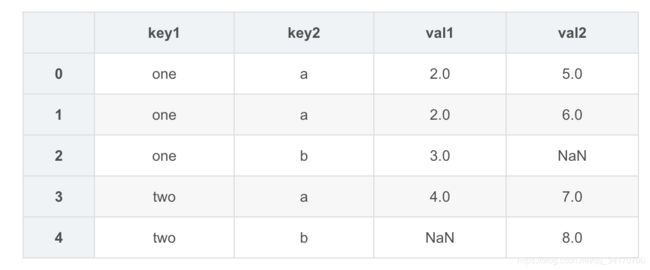
pd.merge(left,right,on="key1")
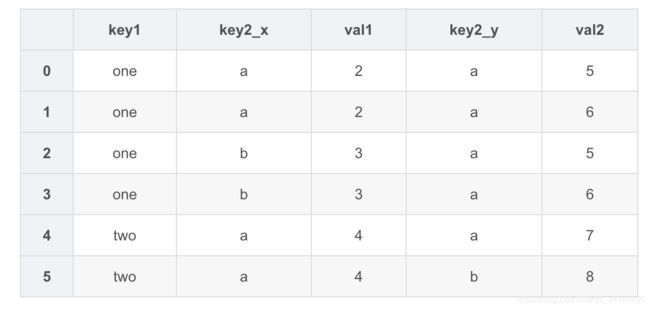
pd.merge(left,right,on="key1",suffixes=('_left','_right'))

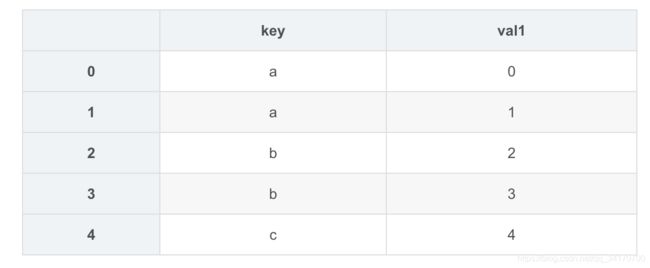
left2 = DataFrame({
'key':['a','a','b','b','c'],
'val1':[0,1,2,3,4]
})
left2
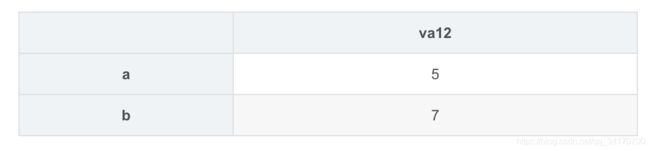
right2 = DataFrame({
'va12':{
'a':5,
'b':7
}
})
right2
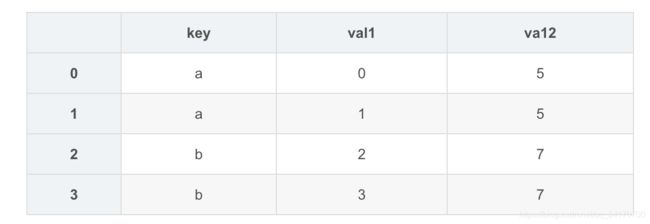
pd.merge(left2,right2,left_on='key',right_index=True)
left3 = DataFrame([0,1,2,3],index=['a','b','a','c'],columns=['val1'])
left3

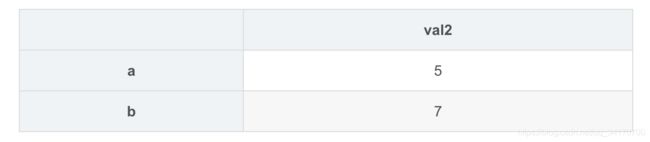
right3 = DataFrame({
'val2':{
'a':5,
'b':7
}
})
right3
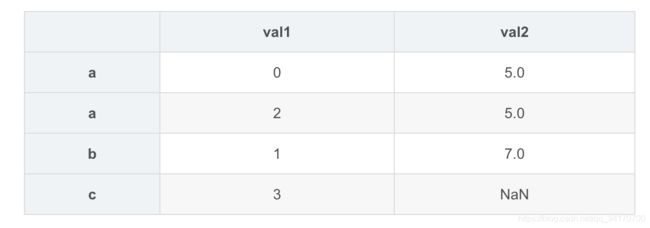
left3.join(right3,how='outer')
5.2.2 concat连接
- 如果需要合并的
DataFrame之间没有连接键,就不能使用merge方法了,这时可通过pandas的concat方法实现。
- 默认情况下,
concat是在axis=0上工作的,当然通过指定轴向也可以按列进行连接。
- 可以通过
join_axes指定使用的索引顺序
- 当行索引类似时,通过默认连接会出现重复行索引。这时可通过
ignore_index='True'忽略索引,以达到重排索引的效果。
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
s1 = Series([0,1],index=['a','b'])
s2 = Series([2,3],index=['c','d'])
s3 = Series([4,5],index=['e','f'])
pd.concat([s1,s2,s3])
a 0
b 1
c 2
d 3
e 4
f 5
dtype: int64
pd.concat([s1,s2,s3],axis=1)
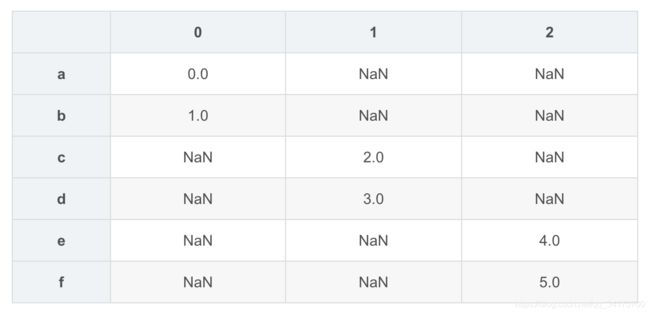
s4 = pd.concat([s1*10,s3])
s4
a 0
b 10
e 4
f 5
dtype: int64
pd.concat([s1,s4],axis=1)
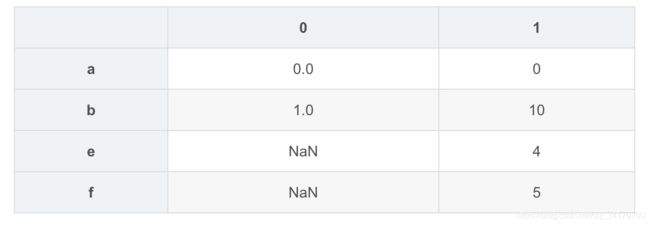
pd.concat([s1,s4],axis=1,join='inner')
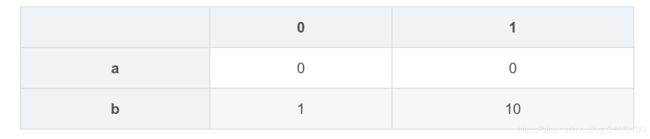
pd.concat([s1,s4],axis=1,join='inner',join_axes=[['b','a']])
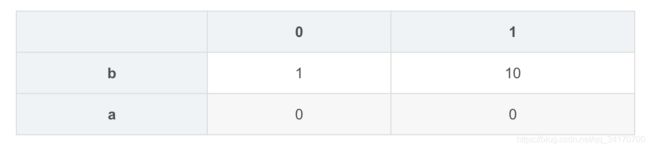
pd.concat([s1,s4])
a 0
b 1
a 0
b 10
e 4
f 5
dtype: int64
pd.concat([s1,s4],keys=['one','two'])
one a 0
b 1
two a 0
b 10
e 4
f 5
dtype: int64
pd.concat([s1,s4],axis=1,keys=['one','two'])
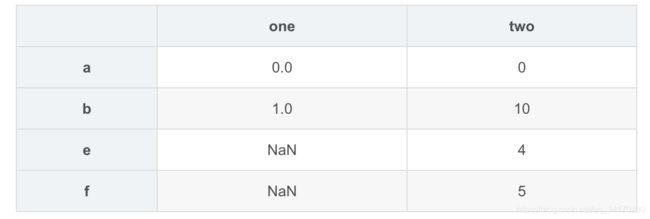
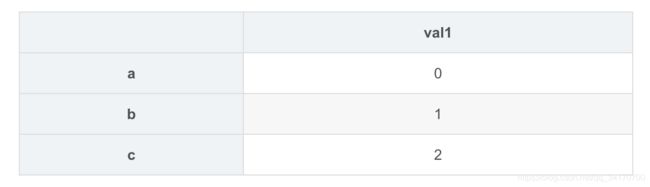
df1=DataFrame([0,1,2],index=['a','b','c'],columns=['val1'])
df1
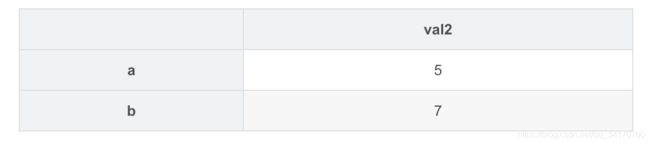
df2 = DataFrame([5,7],index=['a','b'],columns=['val2'])
df2
pd.concat([df1,df2],axis=1,keys=['one','two'])
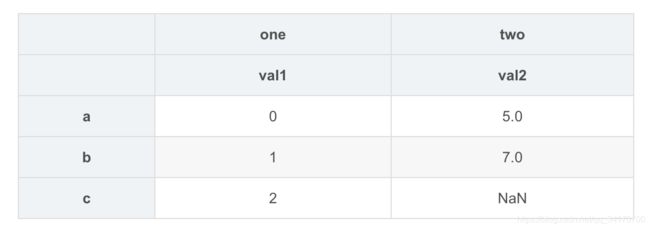
pd.concat({'one':df1,'two':df2},axis=1)
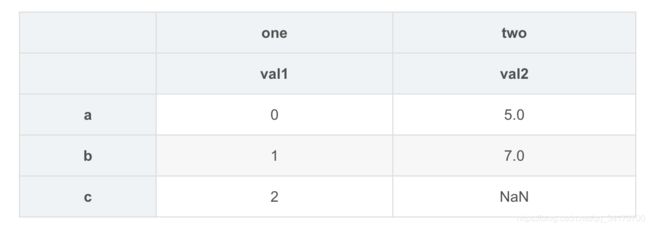
df1 = DataFrame(np.random.randn(3,4),columns=['a','b','c','d'])
df2 = DataFrame(np.random.randn(2,2),columns=['d','c'])
df1
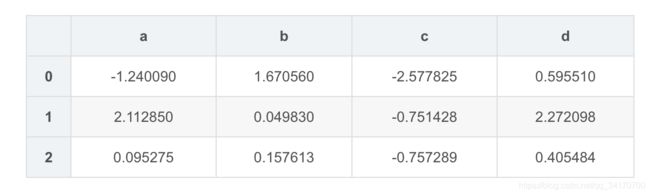
df2

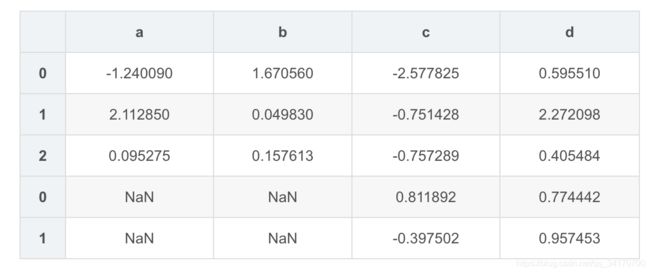
pd.concat([df1,df2])
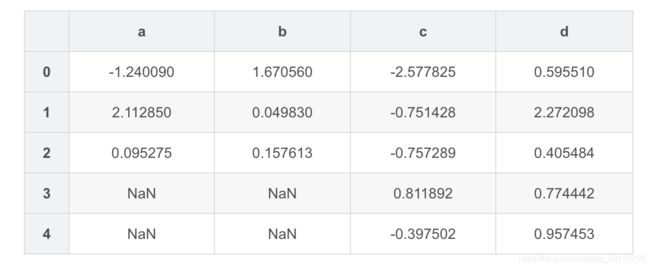
pd.concat([df1,df2],ignore_index=True)
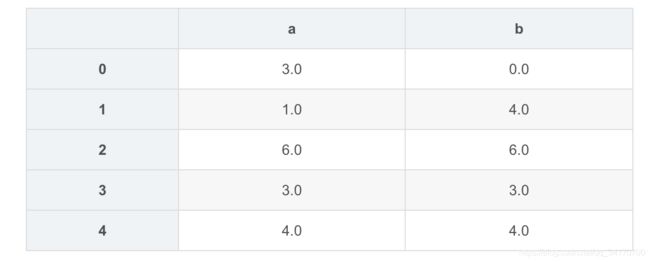
5.2.3 combine_first合并
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
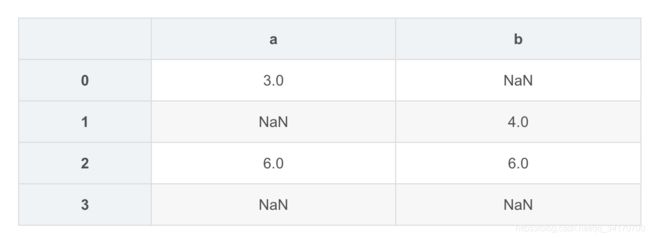
df1 = DataFrame([[3.0,np.nan],[np.nan,4.0],[6.0,6.0],[np.nan,np.nan]],columns=['a','b'])
df1
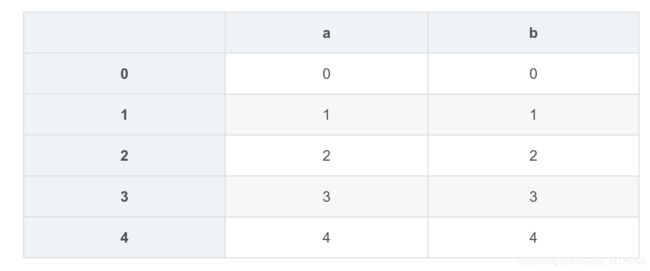
df2 = DataFrame([[0,0],[1,1],[2,2],[3,3],[4,4]],columns=['a','b'])
df2
df1.combine_first(df2)
5.2.4 数据重塑
- 数据重塑用于重排DataFrame,有两个常用的方法:stack方法用于将DataFrame的列“旋转”为行;unstack方法用于将DataFrame的行“旋转”为列。
- 将列转换为行后,则生成了一个Series数据,通过unstack又会将其重排为原始数据的形式。
- 不仅数据重塑的操作是最内层的,操作的结果也会使旋转轴位于最低级别。
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
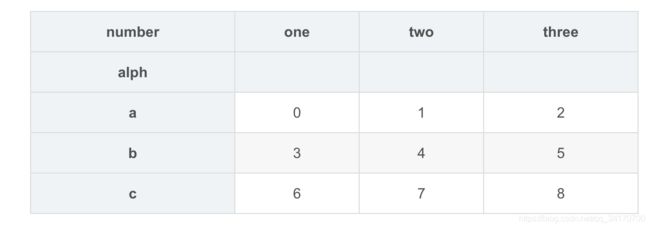
df = DataFrame(np.arange(9).reshape(3,3),
index=['a','b','c'],
columns=['one','two','three'])
df.index.name = 'alph'
df.columns.name='number'
df

result = df.stack()
result
alph number
a one 0
two 1
three 2
b one 3
two 4
three 5
c one 6
two 7
three 8
dtype: int64
result.unstack()
result.unstack(0)
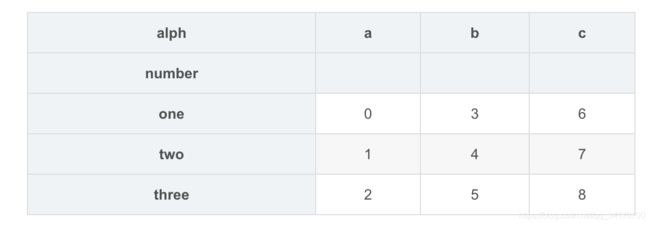
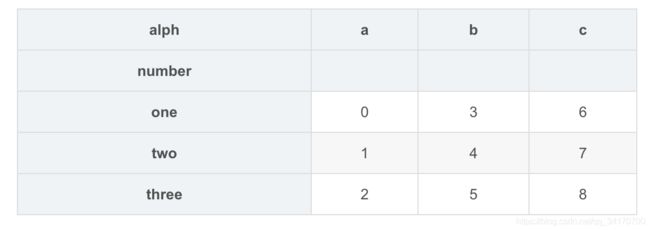
result.unstack('alph')
df = DataFrame(np.arange(16).reshape(4,4),
index=[['one','one','two','two'],['a','b','a','b']],
columns=[['apple','apple','orange','orange'],['red','green','red','green']])
df
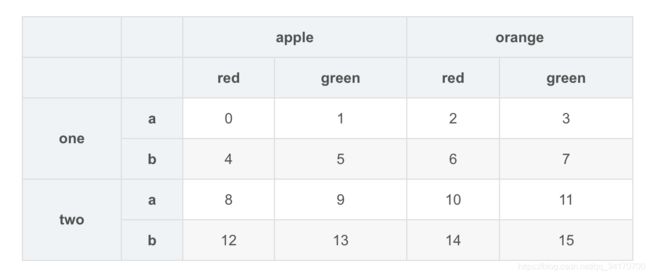
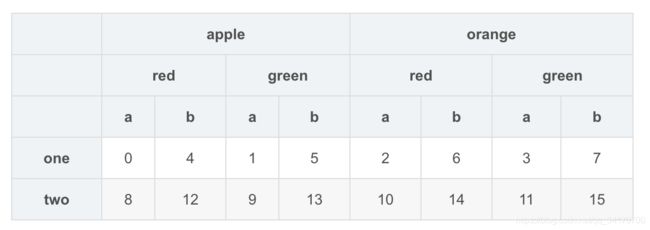
df.stack()

df.unstack()
5.3 字符串处理
5.3.1 字符串方法
- pandas中字段的str属性可以轻松调用字符串的方法,并运用到整个字段中。
5.3.2 正则表达式
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data = {
'data':['张三|男','李四|女','王五|女','小明|男']
}
df = DataFrame(data)
df

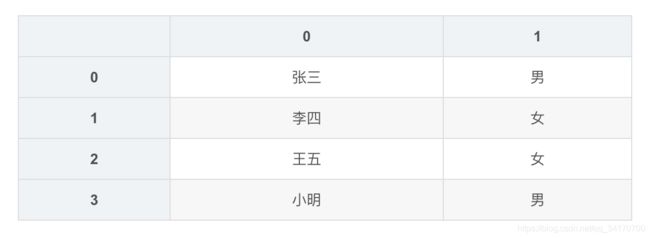
result = df['data'].apply(lambda x:Series(x.split('|')))
result
new_df = df['data'].str.split('|')
new_df
0 [张三, 男]
1 [李四, 女]
2 [王五, 女]
3 [小明, 男]
Name: data, dtype: object
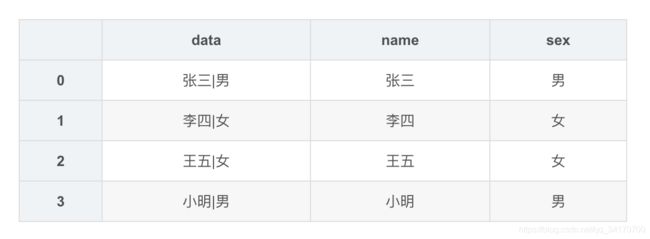
df['name'] = new_df.str[0]
df['sex']=new_df.str[1]
df
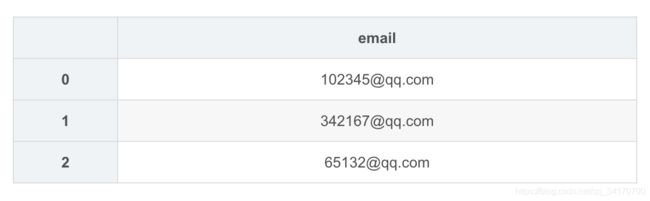
df2 = DataFrame({
'email':[
'[email protected]',
'[email protected]',
'[email protected]'
]
})
df2
df2['email'].str.findall('(.*?)@')
0 [102345]
1 [342167]
2 [65132]
Name: email, dtype: object
df2['QQ']=df2['email'].str.findall('(.*?)@').str.get(0)
df2
