广告深度学习计算:阿里妈妈智能创意服务优化
✍本文作者:雨行、列宁、阿洛、腾冥、枭骑、无蹄、少奇、持信等
一、阿里妈妈智能创意服务介绍
随着短视频逐渐成为人们表达自我和生活的主流媒介之一,各大短视频平台也得到了迅猛发展,短视频流量已经成长为互联网优质流量阵地之一,短视频的供给和消费都呈现出爆发式增长。在这个背景下,阿里妈妈智能创意服务,借助当前主流的深度学习算法,自动高效的为商品产出创意视频,大大丰富了广告的表现形式,既有视觉美学价值,还能提高用户的点击率,提升投放效果。目前,该服务已经在阿里妈妈各个广告业务场景中得到大量应用,其中包括搜索直通车、淘宝直播、抖音快手外投等。下面就是智能创意广告的部分展示场景。
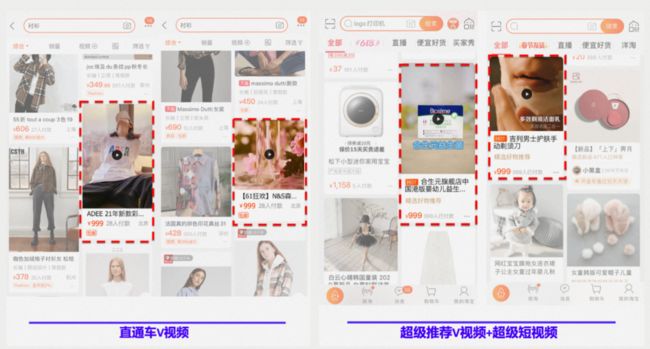
为实现上述功能,需要许多深度学习模型来支持,主要包括视频和文本两大类,具体如下:
1.视频类:
3D Convs Net:单模态视频模型,主要采用三维卷积算子,提取视频前后帧之间的信息。
Visual Transformer:多模态视频处理模型,能够将图片、文本等信息融入视频语义理解中。
2.文本类:
Transformer / GPT-2:文本生成模型。使用场景如商品介绍文案自动生成,"这是一款保暖舒适的被子,选用了轻盈纤维棉,蓬松轻柔且透气性好,有效锁住热量,让被身更加轻盈保暖。加上轻柔的结构,让你的体重轻松达到零负担,更加舒适。"
为淘宝海量的商品自动生成创意视频,是个巨大的工程。而现有的服务性能以及GPU数量,不足以处理全量的商品,因此对智能创意服务的优化需求非常迫切。通过对现有服务架构的分析,我们决定进行两方面的优化:一是从服务流程的角度进行优化,二是对视频和文本两大类模型自身进行优化。下面我们以实时创意短视频生成服务(以下简称短视频生成服务)为例,介绍我们在智能创意服务的优化工作。
短视频生成服务,是从一个商品介绍视频中抽取出5秒的精彩瞬间。该服务根据商品主图、商品描述,从广告主上传的视频中,计算出相似度最高5秒。比如下面这个场景:
商品描述:"316儿童可爱保温杯子吸管幼儿园小学生上学男女高颜值壶宝宝水杯"
商品主图:

选取出的宽高比1:1的5秒精彩短视频如下:
当商家新建一个推广计划时,如果商品中有视频内容,那么系统会自动触发调用一次短视频生成服务,基本流程如下图:
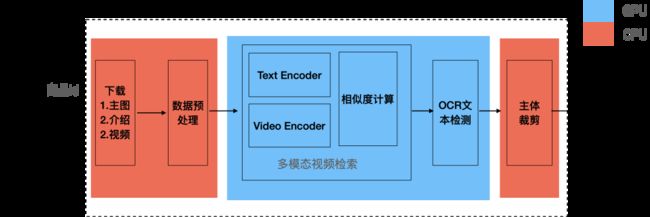
其中,虚线框内部分是短视频生成服务的主体。该服务接收到商品id后,下载商品的创意视频、介绍文案以及商品主图,经过多模态视频检索模型,找出创意视频中与商品主图、介绍文案相似度最高的一个时间片段,再将该片段经过主体位置检测模型后,裁剪出不同宽高比的视频,如1:1, 2:3等以适配不同的终端。如果视频出现了介绍文字,还要经过OCR模型检测出文字的位置,避免文字的部分被裁剪掉。最后生成一个完整的精彩短视频。
在框架语言选择方面,虽然C++比Python更适合服务端开发,但是我们还是决定使用Python作为开发语言,主要考虑以下几个因素:
视频类模型需要对图片进行复杂的预处理和后处理操作,Python相较于C++开发更加便利,有利于算法同学自助开发上线;
目前业务正处于快速迭代期,而学术界最新的研究成果都是通过Pytorch+Python的方式公开,使用Python能够降低迭代周期。
但是直接使用PyTorch+Python进行部署的缺点也很明显,PyTorch的灵活性的代价是性能优化方面的劣势,性能比较差。这就给我们提出了优化PyTorch模型的业务需求,在追求计算性能的同时,还需要兼顾灵活性、易用性。
在服务框架选择方面,我们选取了Tornado V6.0版本,以HTTP接口形式对外提供服务。业务初期采用了Tornado的单线程的模型,每个服务同一时刻只能处理一条请求。但这种使用模式处理能力太低,因此我们首先尝试将单线程的服务升级为多线程服务,在T4显卡的性能如下表所示:
| 单并发 | 4并发 | |
|---|---|---|
| 吞吐:视频/分钟 | 6 | 12 |
| Latency | 9.6秒 | 18.9秒 |
| 模型推理Latency | 3秒 | 9秒 |
| GPU利用率 | 16% | 30% |
从上表可以看出两个问题:
单并发模式下,模型推理(GPU计算)只占全流程的31%,因此至少采用4并发才有可能使GPU利用率达到100%;
采用4并发后,模型推理延时从3秒增长至9秒,几乎是呈线性增长的,而此时GPU Util依然很低,极限压力下仅为30%。
因此,当前使用Python框架直接加载PyTorch模型,存在一个很严重的问题:GPU资源无法充分利用,导致单卡服务能力很低。接下来的章节我们将分析GPU利用率低的原因,并从服务层面、深度学习算子层面给出我们的解决方案。
二、GPU利用率低原因分析
先说结论,有兴趣的同学可以看下面的详细分析过程。
Python GIL全局锁导致kernel launch线程被“频繁”挂起。多线程模式下,CPU逻辑处理线程和kernel launch在同一进程内。由于Python GIL全局锁的存在,导致kernel launch线程的执行时间被“抢占”,无法及时向GPU 提交kernel任务,致使GPU空闲等待。
PyTorch模型没有kernel fusion。大量琐碎的算子导致kernel launch开销太大,同时无法有效利用GPU片上缓存,每次kernel run都需要将数据从GPU显存中加载。
数据传输与计算串行使得GPU SM空闲。PyTorch tensor.cuda()方法,默认使用与kernel launch相同的stream,导致数据传输与计算串行,数据传输的时候GPU SM空闲。
下面我们逐个分析上述三个问题。
2.1 Python GIL全局锁问题
使用Python语言,GIL全局锁是一个绕不开的概念。首先需要明确的是,GIL不是Python的特性,而是Python解释器(CPython)引入的概念。因为CPython是Python默认的执行环境,所以我们一般把CPython的GIL问题也当做是Python的问题。
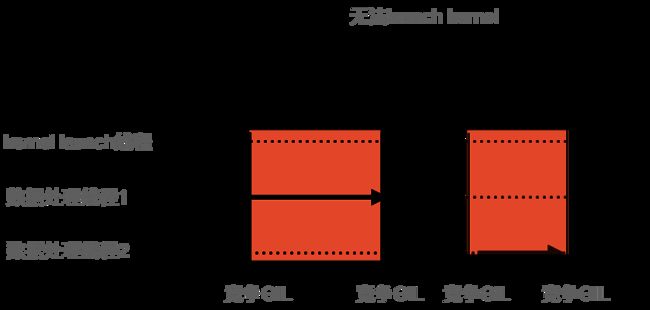
GIL在进行任务调度的时候,所有的线程共享一个全局锁,抢到全局锁的线程执行任务,执行结束后释放全局锁,其他线程再继续竞争全局锁。如下图所示:
这种模型在单核处理器上问题不大,但是发展到多核处理器时,GIL会大大降低多核处理器的优势。我们分析了单线程和4线程情况下,一次完整的GPU 模型推理耗时如下图所示:
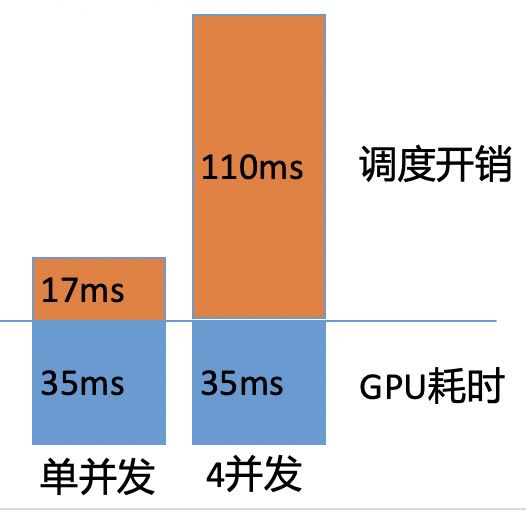
从上表可以看出,从单并发增加至4并发,执行相同数目的kernel,总的GPU kernel的时间相同,但是CPU调度开销增加,导致总的延时增加了。这说明一个问题,GPU并没有到性能瓶颈,只是kernel执行的更加“稀疏”了。
由于全局锁的存在,导致Python的多线程是“假多线程”,而我们的服务主要线程为16(CPU图片预处理线程) +1(kernel launch线程),这17个线程在反复的争夺GIL锁,这就造成了两个问题:
kernel launch线程的执行时间不足;
kernel launch线程反复进入“休眠”->“激活”状态,而这个过程中,会造成线程在过个CPU核上反复切换,造成额外的开销。如下图所示。

上图左右两部分别是4并发和单并发条件下,CPU Core的使用情况。
先看左侧中间红框标出的彩色区域,区域中颜色的变化代表了kernel launch线程所在的CPU Core,可以很明显的看出,4线程工作时,kernel launch线程频繁的在多个CPU Core上切换,导致了kernel launch线程效率低下,无法为GPU“分配”足够的工作,致使GPU大部分时间在空闲等待。该时刻一次模型推理耗时为84~145ms。
右侧是单并发的情况,相对应的中间区域是同一种颜色,表明当前kernel launch在同一CPU Core中进行,没有CPU上下文切换,一次模型推理耗时仅为44ms。
2.2 kernel launch开销
GPU可以做大规模的并行计算,一次计算的基本单位就是“kernel”。我们知道,GPU本身并不能主动执行kernel,需要Host端发起一次kernel调用,也就是一次kernel launch,来触发GPU执行Kernel对应的计算任务。这个过程中设计到三个方面的开销:a) Host 执行kernel launch开销。我们知道,P100/T4/V100每秒分别可以执行11w/34w/24w次kernel launch,这就决定了kernel 数目不宜太多。b) 从GPU显存中加载数据至GPU片上缓存。c) 将计算结果从GPU片上缓存写回GPU显存。
因此,kernel的多少对于模型推理Latency有着非常重要的影响。常见的深度学习框架,如XLA、TVM、TensorRT等,都在kernel fusion上做了很大优化,而PyTorch作为一款流量的深度学习框架,在易用性方面非常优秀,但在kernel fusion方面提供的能力很有限,虽然提供了trace model等功能,但我们在实际测试中发现,trace model的性能并没有明显提升。因此,将PyTorch用于线上服务时,必须进行kernel fusion方面的优化,否则性能很难满足性能要求。
2.3 数据传输与计算串行
CUDA Stream可以看做是CPU与GPU的“通信管道”,CPU将一系列CUDA指令通过Stream依次发送给GPU,而GPU则顺序执行Stream中的指令。由于同一Stream中的操作是顺序执行的,所以当GPU执行数据传输指令时,GPU SM计算单元闲置,使得GPU利用率为0。这种情况如下图所示:
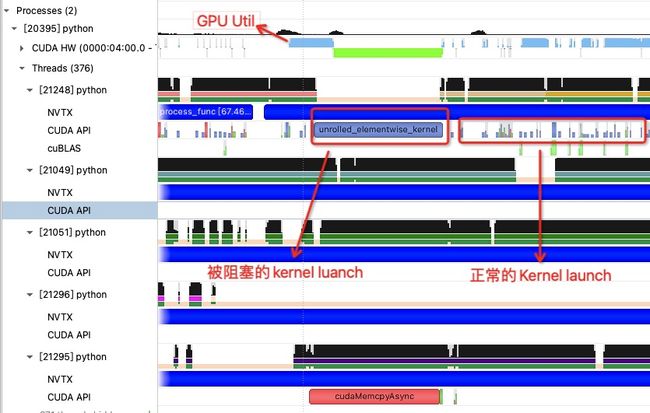
从上图看出,当CPU线程调用cudaMemcpyAsync拷贝数据至GPU时,会阻塞正常的kernel launch(也就是上图中的unrolled_elementwise_kernel,图中第一行的浅蓝色柱子表示GPU利用率,柱子越高代表当前时刻GPU利用率越高)。
短视频服务最主要的多模态视频检索模型采用VisualTransformer, 模型一次输入20张3通道的图片进行处理,输入Tensor为[20, 3, 224, 224],类型为float32,大小为12MB,而PCIe 3.0的标准传输速度为16GB/秒,理论上需要0.75ms的时间,实测发现拷贝时间是2ms。单并发时一次Inference耗时约44ms,数据拷贝占总时长的5%。所以如果不能将数据拷贝与计算并行起来,理论上GPU利用率的天花板只能达到95%。
当服务采用4并发模式时,每个并发又采用4个线程读取视频并将数据拷贝至GPU,因此一次Inferece最多可能会被多次HtoD memcpy阻塞。因此随着并发数的增多,HtoD memcpy对GPU利用率的影响也越大。
三、服务层面优化
3.1 CPU/GPU分离的多进程架构
由于Python GIL全局锁是进程层面的,因此可以通过多进程的方式绕开GIL全局锁。我们将服务kernel launch的部分拆分成独立的GPU进程,同时创建多个CPU进程,每个进程处理一条request请求,整体系统架构如下图所示:
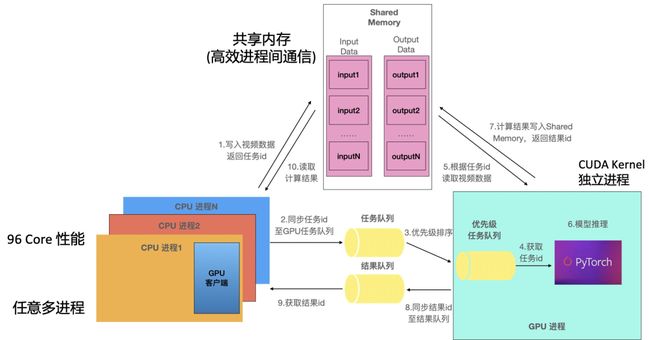
拆分后的CPU进程专注于视频下载、图像预处理等任务,而GPU进程只负责模型推理任务,双方通过共享内存(Shared Memory)交互数据。该过程的主要步骤包括:
CPU进程将处理后的视频数据写入共享内存,获得任务id,该任务id与共享内存名称一一对应
CPU进程将任务id、tensor shape、优先级等信息写入任务队列(torch.multiprocessing.Queue),同步等待结果返回
GPU进程将任务按照优先级排序
GPU进程取出当前优先级最高的任务id
GPU进程根据任务id,从共享内存中读取视频数据
GPU进行模型推理
GPU进程将计算结果写入共享内存Output区,返回结果id
GPU进程将结果id、输出tensor的shape信息写入消息队列
CPU进程被激活,从消息队列中取出结果id
CPU进程根据结果id从共享内存中读出计算结果。
这其中涉及到几个重要问题,接下来一一讨论。
3.1.1 为什么不使用Tornado自带多线程和多进程?
通过第二章的分析,我们得出提高GPU利用率最重要的措施:GPU kernel launch线程不被其他线程“打断”。通过将kernel launch线程拆成独立进程,保证其能够占有足够的CPU执行时间,提高GPU利用率。
Tornado单进程多线程模式不足很明显,所有的线程抢占Python GIL全局锁,理论上只能使用1个核(实际上由于部分并行计算,也会临时使用多个核),优势是省显存,可以多路并发,如下图左一所示。
Tornado多进程模式能够使用多个核,每个进程各自执行kernel launch,间接提高了GPU利用率。但这个有点“乱枪打鸟”的感觉,哪个进程kernel launch成功了,都会提高GPU利用率。但这种用法存在几个致命的问题:
进程间没有通信,可能导致多个进程同时kernel launch,造成latency变长;
每个进程加载一份模型参数至GPU,会占用过多的显存资源,导致开启的进程数有限。
对于第一个Latency变长的问题,我们后面在 3.1.3任务优先级队列 中详细分析,现在主要看一下第二个显存占用的问题。
我们知道,显存的占用主要包括三部分:1.模型参数;2.中间计算结果;3.Cuda Context占用。在多进程模式下,进程之间是不能共享显存的,所以每个进程必须加载一份模型参数,并且为自己的中间计算结果分配显存空间,以保证计算之间不受影响。如下图所示:
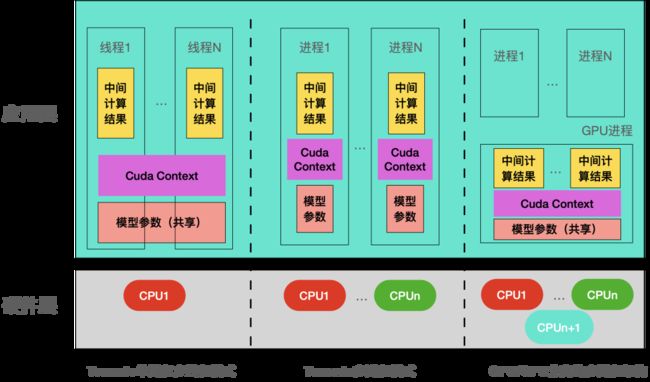
因此在Tornado多进程模式下,每新增一个CPU处理进程,就需要为其分配一块GPU显存用于存储模型参数。这就决定了能够创建的进程数是受限于GPU显存和模型权重大小。
针对Tornado多线程和多进程模式的不足,我们开发了CPU/GPU分离的多进程架构。多个CPU进程用于图片数据预处理操作,之后将计算任务发送给GPU进程。独立的GPU进程只需加载一份模型参数,其职能是将CPU提交的计算任务下发至GPU,从而使得kernel launch不被打断。由于CPU进程不加载模型,因此理论上进程数不受显存的约束。这种架构在充分利用多核CPU计算能力的前提下,大大降低了显存的消耗,并且使得GPU的性能得到充分发挥,尤其适用于V100S、A100等计算能力强的显卡。
3.1.2 进程间通信效率
CPU/GPU分离的多进程架构,必然存在tensor数据的在CPU进程和GPU进程间的传输,而这势必会带来额外的拷贝开销。因此,一个高效的进程间通信方式,就成为系统设计的关键。常见的进程间通信方式包括共享内存、消息队列、管道(pipe)、Socket等多种方式,但是每种方式的传输效率是不同的。在短视频生成场景下,一次模型推理传输的数据量大概为12MB(20张图片 * 3通道 * 高度 224 * 宽度 224 * float32占4Byte),我们选取了以下两种常见的传输方式进行比较:
| 240 Bytes | 12M Bytes | |
|---|---|---|
| 共享内存(Shared Memory) | 8e-4 ms | 1.4 ms |
| 消息队列(torch.multiprocessing.Queue) | 0.02ms | 12ms |
由于共享内存是通过虚拟地址的方式,将同一块物理内存映射到多个进程中,因此使用共享内存传输大块的数据是效率最高的。但是共享内存无法保证进程间读写同步,因此必须配合其他方式使用。从上表中可以看出,在传输字节量比较小的时候,消息队列的开销可以忽略,所以我们使用消息队列在各个进程间同步共享内存的读写信息。
3.1.3 任务优先级队列
在创意短视频生成时,我们会把长视频拆分成若干个5秒短视频,然后将这些5秒短视频依次送入Visual Transformer模型,与商品主图和商品描述进行相似度计算,选取出得分最高的一个,如下图所示:
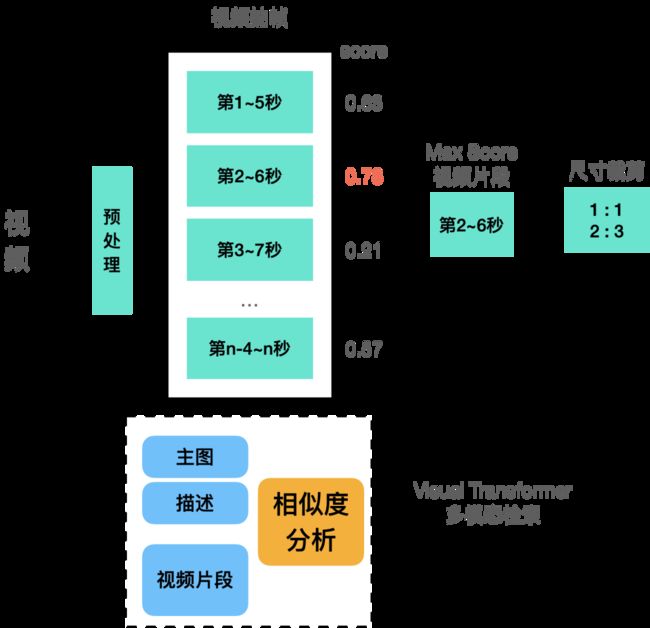
假设视频长度为n秒,实际会进行n-4次模型推理,也就是说,CPU进程会向GPU进行提交n-4次任务,如下图所示:
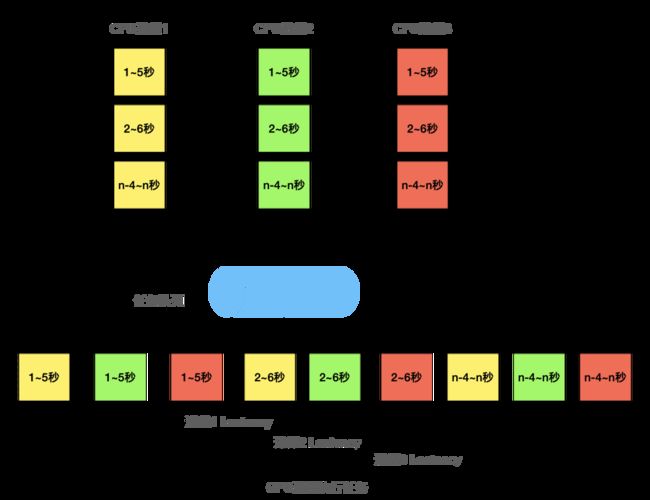
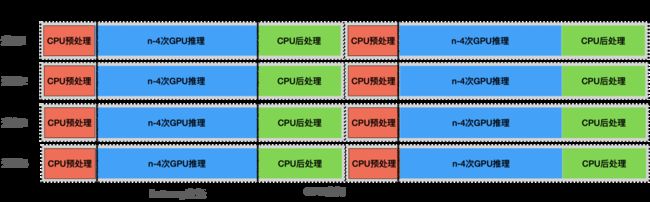
假设n秒视频处理时间为T,则上述情况下,每个进程的时间都会变成 3*T。除了影响Latency之外,还会造成各个进程同时占用GPU、同时占用CPU的情况,不利用硬件资源的均衡使用,最坏的情况如下图所示:
为了达到“First Come First Serve”的效果,我们给GPU进程增加了一个带优先级的消息队列,接收到任务后先按照优先级排序,每个进程以第一次提交任务的时间为优先级,保证了先提交的任务具有最高的优先级。修改后的执行顺序如下图所示:
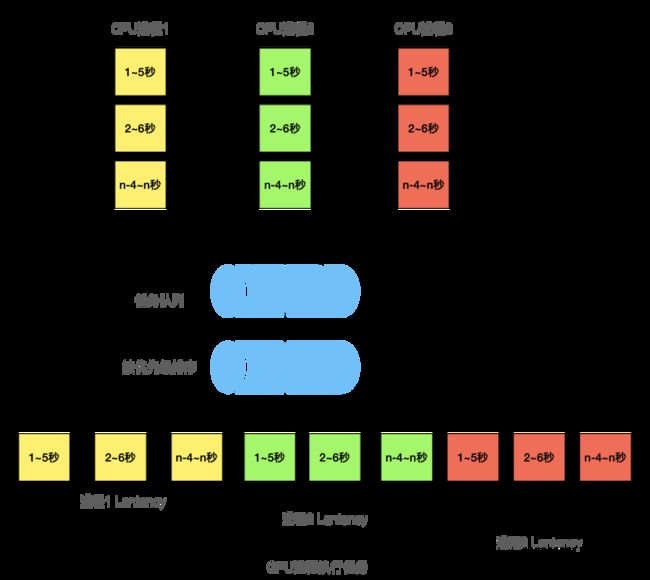
由于CPU进程1在时刻T就完成了GPU任务,因此会先于进程2和进程3开始CPU后处理任务,也会先于进程2和进程3再次提交GPU任务,从而保证了各进程分时复用GPU和CPU资源,提升系统资源利用率和QPS。最理想的情况会达到如下流水线效果:
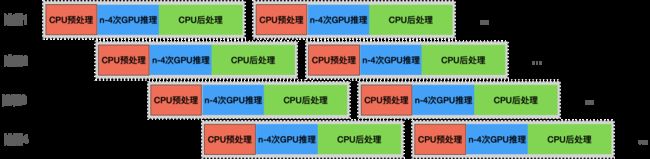
可以看到蓝色区域的GPU推理占满了整个时间线,GPU利用率理论上可以达到100%。
3.2 加速效果
经过上面的优化,我们使用100条线上真实流量数据进行测试,测试显卡为T4,CPU为16核32G内存。
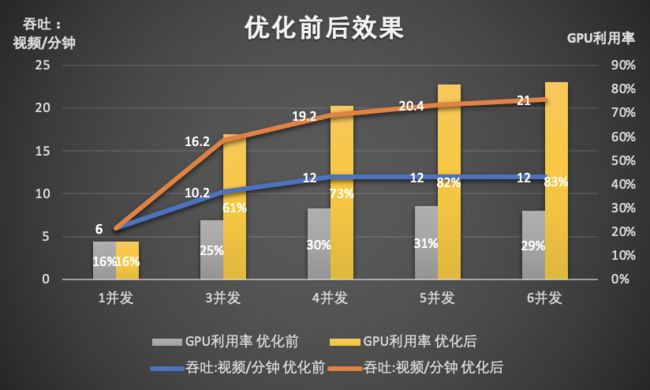
可以看出:
在单并发时,优化前和优化后效果相差并大,说明使用“共享内存+消息队列”的方式,并没有造成太大的系统开销。
随着并发数的增多,优化后的CPU/GPU分离的多进程架构,性能明显优于Tornado自带的多线程模式,最终吞吐了提升75%,GPU利用率提升了41%。
四、深度学习算子层面优化
深度学习算子优化的核心就是进行kernel fusion,通过减少kernel的数目来减少kernel launch的开销,同时使得中间计算结果尽量的复用GPU Cache,降低GPU内存带宽的压力。
4.1 三维卷积(Conv3D)优化
在视频模型里面,Conv3D+BN+MaxPool3D是一个很重要的算子组合,其性能直接影响整个模型的性能。
由于Conv3D为计算密集型算子,因此我们尝试使用TensorCore来加速,但是实际发现性能并没有明显的提升。经过分析,问题出现在图片通道转换上。PyTorch的Conv3D和BN算子仅支持Channels First格式输入,而TencorCore的Conv3D必须是Channels Last格式,这就是造成了如果使用TensorCore加速Conv3D,就会自动插入Channels First到Channels Last通道转算算子,如下图所示:

中间的kernel就是Conv3D,在其前后分别插入两个通道转换算子,使得TensorCore加速的收益被通道转换抵消掉了。
为了兼容TensorCore的Channels Last格式,我们需要把整个模型都改成该格式,才能保证模型从头至尾不需要通道转换。因此我们修改了PyTorch的Conv3D和BN算子,使其支持Channels Last格式,但是PyTorch自带的MaxPool3D算子在Channels Last格式下性能很低,直接使用的话会抵消掉前面的优化。
经过调研,发现Cudnn的MaxPool3D算子性能满足要求,但是功能不满足,该算子只能输出最大值,却不输出最大值的Index信息。而Index信息在接下来的MaxUnpool3D使用。
经过反复分析,我们发现MaxUnpool的过程,其实和Pooling的backward过程是相同的,因此我们采用了CudnnPoolingBackward方法来代替MaxUnpool3D,同时给backward方法传入Pooling前后的值,以使其推算Index信息,替换后的效果如下:
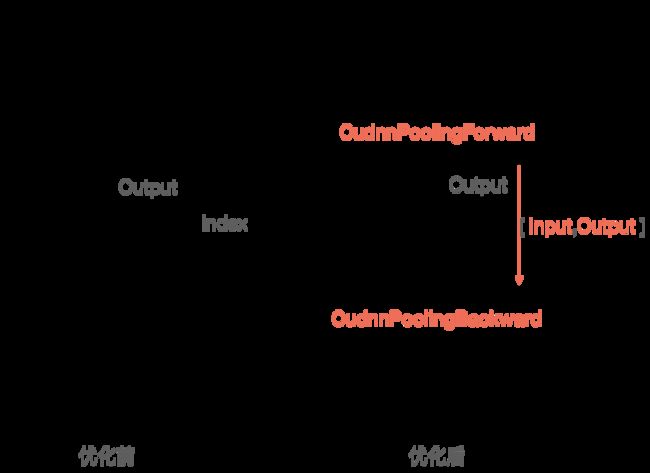
经过上述优化,在TASED-Net模型上Latency降低了15%。
4.2 TensorRT
TensorRT是英伟达提供的高性能推理引擎,在性能方面表现出色,但是支持的算子有限,制约了其大范围的应用。我们在实际应用中,解决了大量算子不兼容的问题,使其能够在GPT-2场景下使用。
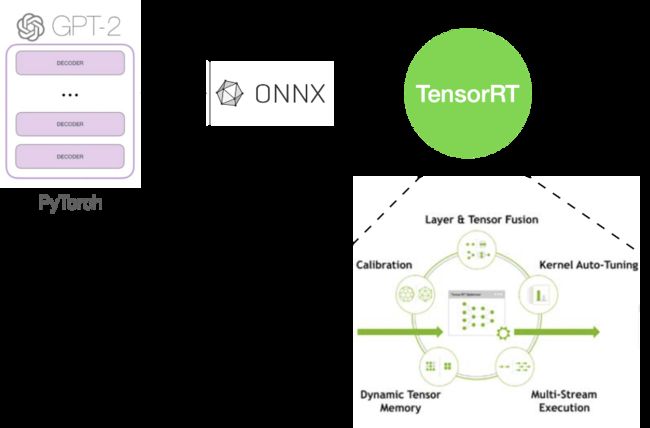
通过将PyTorch模型转换成TensorRT,GPT-2模型一次推理的时间从1秒降低到了0.5秒,获得了1倍的性能提升。
五、其他优化
5.1 视频读取加速
分析视频的第一步是读取视频,但是在分析视频时,并不需要每一帧都分析,而是按照一定频率采样,比如1/5。如果使用OpenCV提供的read接口读入每一帧,会造成80%的读取是无意义的,浪费宝贵的内存并造成延时增大。
经过分析OpenCV的文档,发现read方法其实是分两步来实现的,1.移动指针至下一帧位置;2.对视频内容进行解析。如下图:
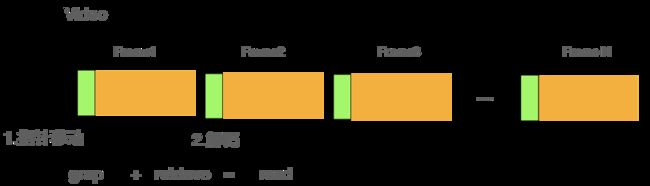
而步骤1指针移动的速度非常快,耗时几乎可以忽略,而步骤2视频解析才是大头。因此,我们可以使用OpenCV的一对组合函数, grab和retrieve来加速视频读取,对于未采样的帧只grap,对于采样的帧才进行retrieve解码。如下图所示:

经过测试,在1/5采样率的情况下,grab + retrieve方法读取一个视频的时间是read的 1/5。
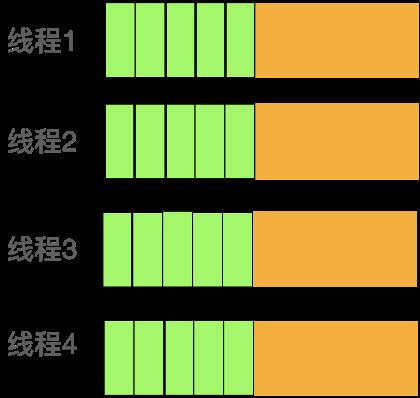
除了上述方面,对于超大时长的视频,还可以使用多线程同时读取。每个线程设置各自读取的起始帧,就可以达到把1个视频拆分成N个视频同时读取的效果。如下图所示:
六、展望与总结
易用性与高性能,一直是多媒体服务优化领域的难题。一方面,我们要保留PyTorch在动态图的易用性优势;另一方面,为了满足在线服务对低延时的严苛要求,还要对模型进行类似静态图的高效优化。目前业界已经进行了一些尝试,比如Pytorch-XLA等Lazy Tensor的技术,后续我们也会在这方面进行深入研究,形成适用于多媒体服务的高性能框架。
另外,针对视频、NLP等创意模型的编译优化,也是我们接下来工作的重点之一。我们之前针对展示广告模型常用的MatMul、Attention等结构,在GPU上做了比较深入的研究,但是针对智能创意模型中常用的Conv3D,Transformer等结构的研究还比较少。同时新的硬件如A10,NPU等,也为我们优化工作提供了新的平台,后续我们会持续投入优化。
END

也许你还想看
丨广告深度学习计算:异构硬件加速实践
丨广告深度学习计算:召回算法和工程协同优化的若干经验
丨新时期的阿里妈妈广告引擎
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓