CLIP论文笔记--《Learning Transferable Visual Models From Natural Language Supervision》
CLIP论文笔记--《Learning Transferable Visual Models From Natural Language Supervision》
- 1、Introduction and Motivating Work
- 2、Approach
-
- 2.1自然语言监督
- 2.2.创建一个足够大的数据集
- 2.3选择一种有效的预训练方法
- 2.4 Choosing and Scaling a Model
- 2.5. Training
- 3. Experiments
-
- 3.1. Zero-Shot Transfer
-
- 3.1.2 USING CLIP FOR ZERO-SHOT TRANSFER
- 3.1.3. INITIAL COMPARISON TO VISUAL N-GRAMS
- 3.1.4. PROMPT ENGINEERING AND ENSEMBLING
- 3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE
- 3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE
- 3.2. Representation Learning
- 3.3. Robustness to Natural Distribution Shift
- 4. Data Overlap Analysis
- 5. Conclusion
参考链接: OpenAI CLIP 论文解读.
主题:多模态理解任务
任务:计算图片和文本的相似度
训练:有监督的对比学习
这是openAI今年(2021)的作品,CLIP将图片和文字联系在一起,目标是得到一个能非常好表达图片和文字的模型。
1、Introduction and Motivating Work

①NLP近年来飞速发展。从网络上爬下一些文本形成数据集,一些NLP模型可以直接在这个数据集上预训练,再到其他数据集做任务时,这个模型可以不使用这个数据集的任何数据(zero-shot)进行参数微调而直接做任务。zero-shot transfer就是零样本迁移到下游任务的意思。GPT-3是更通用化的 NLP 模型,也是openAI的作品。
②计算机视觉,在ImageNet等人工标记的数据集上预训练模型仍然是标准的做法。
“狭窄的视觉概念”是指模型在ImageNet等数据集上训练,只是为了学会区分像“猫”、“狗”这样的类,但不同的猫种类模型是不会区分的,比如“橘猫”和“奶牛猫”,即其他的视觉信息没有被充分利用。
作者想:从网络文本中学习的预训练方法能否应用在计算机视觉方面。
③Visual N-Grams促成CLIP的诞生的最重要的论文。
【Visual N-Grams:用自然语言监督信号来让促成一些现存的CV分类数据集(包含ImageNet数据集)实现zero-shot transfer。】
2、Approach

标准的图像模型训练一个图像特征提取器和一个线性分类器来预测某些标签,而CLIP联合训练一个图像编码器和一个文本编码器来预测一批(图像、文本)正确配对。
在测试时,把label填到“a photo of {object}”里形成一个句子,这个步骤叫Prompt工程,再把句子输入到文本编码器中。
2.1自然语言监督
①这不是一个新想法,然而用来描述这个领域工作的术语是多样的,并且动机是多样的。有很多人都引入了从有图像配对的文本中学习视觉表示的方法,但它们将其方法分别描述为无监督、自监督、弱监督和有监督。
②与大多数无监督或自监督的学习方法相比,从自然语言中学习也有一个重要的优势,因为它不仅“只是”学习一种表示,而且还将该表示与语言联系起来,从而实现灵活的zero-shot transfer。
2.2.创建一个足够大的数据集
作者用4亿对来自网络的图文数据集,将文本作为图像标签,进行训练。这个数据集称为WebImageText(WIT)
2.3选择一种有效的预训练方法

这是一个简单的有监督的contrastive任务。它将图片分类任务转换为图文匹配任务。
CLIP的模型是比较简单的,它的贡献点在于采用了海量图文对数据和超大batch size进行预训练,并不在于其模型结构。
计算模态之间的cosine similarity,让N个匹配的图文对相似度最大,N2-N不匹配的图文对相似度最小
对角线上都是配对的正样本对,而矩阵的其他元素,则是由同个batch内的图片和不配对的文本(相反亦然)组成的负样本。这种策略可以形成N2-N个负样本。
CLIP的模型结构和正负样本组成策略并不复杂,也即是从batch内部去构成负样本。
还有一些CLIP预训练的小细节,如下图所示。

作者不使用表示空间和对比embedding空间之间的非线性投影,因为作者没有注意到这两个版本之间的训练效率的差异,并推测非线性投影只有在自监督表示学习方法中才可能与当前图像的细节共同适应。
2.4 Choosing and Scaling a Model

首先是模型的选择,见上图的右上角。
the antialiased rect-2 blur pooling的示意图在左下角。第一步为max pooling,这一步操作能够保留平移不变性,第二步为降采样subsampling,这一步操作会破坏平移不变性,然后在两者中间插入一个低通滤波器(二维图像就是卷积运算),这是为了尽最大努力保留平移不变性。
然后是模型的放缩。

Image Encoder:使用一个简单的baseline来平均分配额外的算力,以增加模型的宽度、深度和分辨率。
Text Encoder:只缩放模型的宽度,使其与计算出的ResNet宽度的增加成正比,而不缩放深度,因为作者发现CLIP的性能对文本编码器的容量不那么敏感。
2.5. Training
作者训练了5个ResNets和3个 Vision Transformers。
- 对于ResNets,训练一个ResNet-50,一个ResNet-101,然后再训练模型缩放,使用大约是ResNet-50计算量的4x、16x和64倍。分别记为RN50x4、RN50x16和RN50x64。
- 对于 Vision Transformers,训练了ViT-B/32(表示patch size为32的ViT-Base模型)、ViT-B/16和ViT-L/14(ViT-Large)。
更可怕的是,作者设置了超大的minibatch.(真是大力出奇迹
We use a very large minibatch size of 32,768.
下图是ViT-B和ViT-L的模型参数设置。

3. Experiments
3.1. Zero-Shot Transfer
3.1.2 USING CLIP FOR ZERO-SHOT TRANSFER

神经网络将图片转换为一个向量表示,向量表示会经过一个线性映射,转换为我们想要的类别数的维度,这个向量表示就变为3维,经过softmax后,转换为概率分布。 W,可以看成是,每个类别对应的向量表示。 线性映射,可以看成是,类别的向量表示与图像的向量表示做一个相似度计算。
将CLIP用在零样本的分类任务中,就是将这里的W,不再让W是可变的参数,而是将对应的列替换成我们需要的类别它对应的文本的向量表示。CLIP本身就具有比较图像和文本相似度的能力,所以再计算图像的embedding和对应类别文本描述的embedding,它们相似度的时候,自然就把那张图片,对应到与它描述最相似的文本上去。
zero-shot具体操作如下:
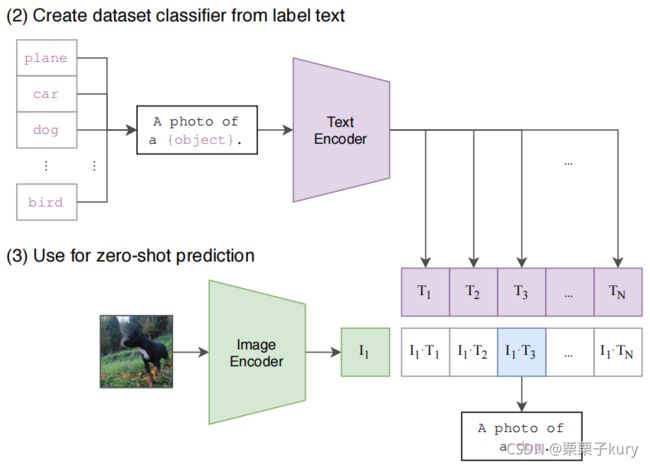
- 输入:一张图片 + 所有类别转换的文本(100个类别就是100个文本描述)。
- 计算图像的特征嵌入和由它们各自的编码器对可能的文本集的特征嵌入。
- 计算这些嵌入的cosine similarity,用温度参数τ进行缩放,并通过softmax归一化为概率分布。
注意:该预测层是一个多项式logistic回归分类器,具有L2归一化输入、L2归一化权值、no bias和temperature scaling。
3.1.3. INITIAL COMPARISON TO VISUAL N-GRAMS

visual N-GRAMS是促成CLIP的诞生的最重要的论文。
visual N-GRAMS受n-gram模型的启发。n-gram模型中每一个字节片段称为gram,对所有gram的出现频度进行统计,进行过滤,形成关键gram列表,也就成了文本的向量特征空间
该模型基于这样一种假设:第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
visual N-GRAMS使用差分版本的Jelinek-Mercer平滑来最大化给定图像的所有文本n-gram的概率。visual N-GRAMS为了进行zero-shot传输,他们首先将每个数据集的类名的文本转换为其n-gram表示,然后根据他们的模型计算其概率,预测得分最高的概率。
从结果可以看出,CLIP在aYahoo、ImageNet、SUN这三个数据集上表现比visual N-GRAMS好得多。
3.1.4. PROMPT ENGINEERING AND ENSEMBLING

左图横坐标是算力,纵坐标是平均分数。可以看出算力在75.3时,有prompt工程的分数会比不用prompt的高上近5个百分点。当分数在55%时,不用prompt的模型需要花上近4倍的算力,才能赶上用prompt的效果。
3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE

另:有人问Kinetics 700,UCF 101数据集是时间序列,怎么做这个分类任务的?老师回答说可能是做了平均处理。
Linear Probe on ResNet50的介绍:

3.1.5. ANALYSIS OF ZERO-SHOT CLIP PERFORMANCE


3.2. Representation Learning
可以看出linear probe CLIP很强。但可能是选的数据集有偏向。

3.3. Robustness to Natural Distribution Shift
作者比较了zero-shot transfer与现有ImageNet模型在自然分布偏移上的性能。所有的zero-shot CLIP模型都大大提高了有效的鲁棒性,并将ImageNet精度与分布偏移下的精度之间的差距缩小了75%。
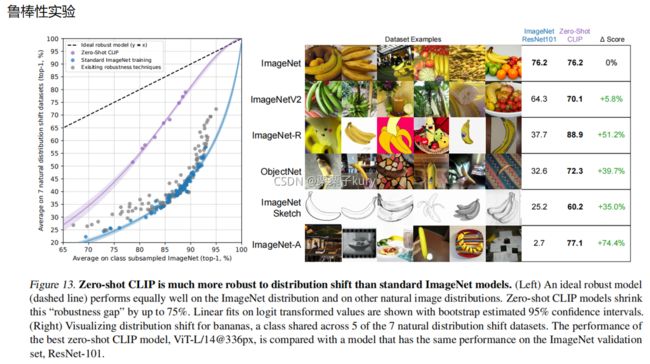
图13的左图:横纵坐标是ImageNet的偏移。黑色虚线是理想的鲁棒模型,可以看到它经过(65,65)这一点,是线性的、正比例的。而普通的模型做不到这样,画出来的曲线只会在黑色虚线的下面。但可以看出zero-shot CLIP的鲁棒性是比ImageNet的标准训练的模型要好的。
下面是对图13的右图的解释:


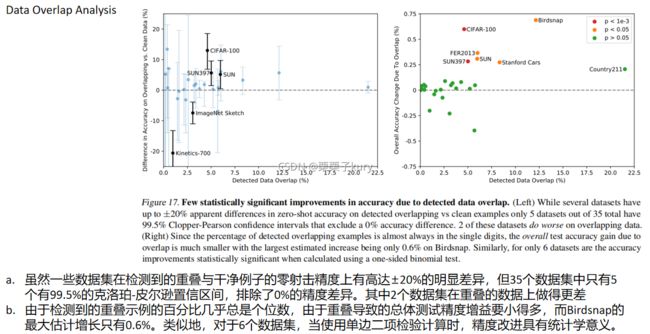
4. Data Overlap Analysis
预训练的数据集是否和下游数据集有重叠?如果有重叠,就会导致数据泄露,下游实验的结果就不可信。结果确实是有重叠的,但作者经过分析得出结论:这样的重叠并不会带来明显的准确率提升。
5. Conclusion
基于双塔结构的CLIP模型,在数据量足够的情况下,可以在预训练阶段学习到很多通用的视觉语义概念,并且给下游任务提供非常大的帮助。
CLIP模型在预训练过程中学习执行各种各样的任务。
这个任务学习可以通过自然语言提示来利用,以实现零镜头转移到许多现有的数据集。在足够的规模下,这种方法的性能可以与特定于任务的监督模型竞争